【Pandas concat 完全入門】複数のCSVやDataFrameを縦横に結合する方法まとめ
この記事では、pandas.concat() を使って複数のデータフレームを縦や横に結合する方法を、実行例つきでわかりやすく解説します。
📘 図解やエラー対処を含むさらに詳しい解説はブログに掲載中:
👉 Pandas concat関数の完全解説|Python Data Lab
Pandas concat でデータフレームを効率的に結合する方法を徹底解説!
「複数の Excel ファイルを一つにまとめたい」「異なるデータセットを横に並べて分析したい」...
データ分析や前処理において、データフレームの結合は避けて通れない重要な作業です。
Python のデータ分析ライブラリ「Pandas」のconcat関数を使った、データフレーム(Pandas における表形式のデータ構造)の縦結合・横結合の方法を、初心者の方にも分かりやすいように実例を交えて丁寧に解説します。
この記事を読むことで、以下のことを習得できます。
- 実務での応用: 実際のデータ前処理で役立つ、効率的なデータ結合のテクニック(特定のフォルダ内の複数のCSVファイルを一気に結合)を身につけられます。
-
Pandas concat関数の基本的な使い方: 縦方向(行)と横方向(列)への結合方法を理解できます。 - インデックス処理の重要性: 結合時のインデックス(データフレームの各行を識別するためのラベルや番号)の扱いの違い(維持 vs. 振り直し)を理解し、意図しないデータの重複やずれを防ぐ方法を学べます。
Pandas を使ったデータ分析を始めたばかりの方や、データ結合の方法でつまずいた経験のある方に特におすすめの内容です。
▶️ Pandas concat の公式ドキュメントも参考にしてください:
pandas DataFrame sort_index Documentation
▶️ 他の結合方法である Pandas merge の記事も参考にしてください。merge や concat と merge の違いについても解説しています。
Pandas merge 関数でデータフレームを結合する方法【完全解説】【第12回】
Pandas concat と Pandas merge、使い分けのポイント
Pandas でデータフレームを結合する方法には concat の他に merge もあります。どちらを使うべきか迷うこともあるかもしれません。ここでは、それぞれの関数がどのようなケースに適しているかの判断基準を簡単に解説します。
pd.concat が適しているケース:
- 単純な縦結合 (行方向への結合): 複数のデータフレームを単に上下に結合したい場合。例えば、月ごとの売上データをまとめて年間のデータを作成する場合など。
- 単純な横結合 (列方向への結合): 同じインデックスを持つデータフレームを横に並べたい場合。例えば、既存のデータフレームに新しい計算結果の列を追加する場合など。
- インデックスをキーとした結合: インデックスが結合のキーとなる場合。
pd.merge が適しているケース:
- 特定のキー列に基づいた結合: SQLのJOINのように、一つ以上の共通する列(キー)の値に基づいてデータフレームを結合したい場合。例えば、顧客情報データと購入履歴データを顧客IDをキーとして結合する場合など。
- 異なるインデックスを持つデータフレームの結合: インデックスが揃っていないデータフレームを、特定の列を基準に結合したい場合。
- 多様な結合方法(内部結合、外部結合など)を使いたい: キーに基づいて、データの欠損をどのように扱うか(どちらかのデータにしかない行を含めるかなど)を細かく制御したい場合。
簡単に言うと、「単に積み上げたり横に並べたりするなら concat、特定の関係性(キー)で結びつけるなら merge」 と考えると分かりやすいことが多いです。
より詳細な merge の使い方や concat と merge の違いについては、別途記事で詳しく解説していますので、そちらも合わせてご覧ください。
サンプルデータの作成(結合前データ)
まずは、結合の元となるサンプルデータを作成しましょう。これは、この記事全体を通して使用する基本的なデータフレームです。
以下のコードで、架空の個人情報を含むデータフレーム df を作成します。このデータフレームを基に、concat による様々な結合方法を試していきます。
import pandas as pd
df = pd.DataFrame({
"名前": ["太郎", "花子", "次郎", "美香", "健一", "恵子", "翔", "茜", "隆", "葵"],
"年齢": [23, 29, 35, 42, 18, 33, 27, 24, 31, 30],
"職業": ["エンジニア", "デザイナー", "教師", "医師", "学生", "看護師", "プログラマー", "販売員", "弁護士", "研究者"],
"年収(円)": [4500000, 5500000, 4900000, 7300000, 0, 4000000, 6000000, 3200000, 8000000, 5800000],
"居住地": ["東京", "大阪", "名古屋", "札幌", "福岡", "東京", "神戸", "仙台", "横浜", "千葉"],
"勤続年数": [2, 4, 10, 15, 1, 5, 3, 1, 12, 8]
})
print("出力結果")
df
出力結果
名前 年齢 職業 年収(円) 居住地 勤続年数
0 太郎 23 エンジニア 4500000 東京 2
1 花子 29 デザイナー 5500000 大阪 4
2 次郎 35 教師 4900000 名古屋 10
3 美香 42 医師 7300000 札幌 15
4 健一 18 学生 0 福岡 1
5 恵子 33 看護師 4000000 東京 5
6 翔 27 プログラマー 6000000 神戸 3
7 茜 24 販売員 3200000 仙台 1
8 隆 31 弁護士 8000000 横浜 12
9 葵 30 研究者 5800000 千葉 8
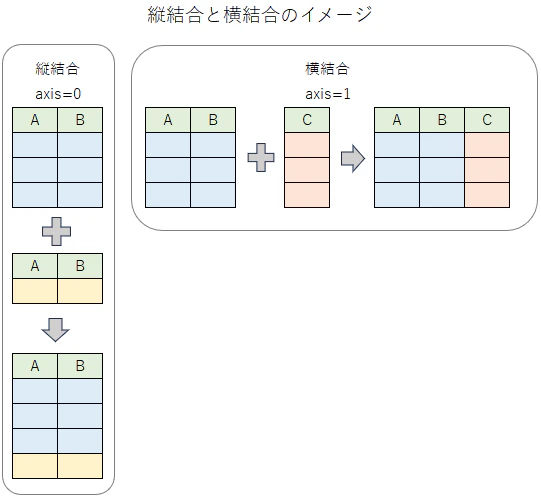
縦結合・横結合のイメージ
pd.concat関数を使うことで、複数のデータフレームを縦方向(行方向)または横方向(列方向)に結合できます。この結合の方向は axis 引数で指定します。
以下の図は、縦結合 (axis=0) と横結合 (axis=1) のイメージを示しています。縦結合ではデータが下に追加され、横結合ではデータが右に追加されることが視覚的に理解できます。
次のセクションから、それぞれの具体的な方法を見ていきましょう。
Pandas concatで縦結合する (axis=0)
まずは、データフレームを縦方向(行方向)に結合する方法を見ていきましょう。これは、新しい行を既存のデータフレームに追加するイメージです。pd.concat() 関数のデフォルトの動作であり、axis=0 を明示的に指定することもできます。
【例】既存のデータフレーム df に、新しいデータを含む1行のデータフレーム df1 を縦(行方向)に結合します。
追加データの作成
以下のコードで、既存のデータフレームに追加するための新しい1行データを含むデータフレーム df1 を作成します。
df1 = pd.DataFrame({
"名前": ["三郎"],
"年齢": [18],
"職業": ["学生"],
"年収(円)": [0],
"居住地": ["東京"],
"勤続年数": [0]
})
df1
名前 年齢 職業 年収(円) 居住地 勤続年数
0 三郎 18 学生 0 東京 0
縦に結合(追加データの「インデックス番号」を維持したまま結合:ignore_index=False)
pd.concat() 関数で ignore_index=False(デフォルト設定)の場合、結合元のデータフレームのインデックス(行を識別する番号やラベル)がそのまま引き継がれます。元のデータフレームと追加データの両方にインデックス 0 が存在するため、結合後もインデックス 0 が重複していることがわかります。
df2 = pd.concat([df, df1])
df2
名前 年齢 職業 年収(円) 居住地 勤続年数
0 太郎 23 エンジニア 4500000 東京 2
1 花子 29 デザイナー 5500000 大阪 4
2 次郎 35 教師 4900000 名古屋 10
3 美香 42 医師 7300000 札幌 15
4 健一 18 学生 0 福岡 1
5 恵子 33 看護師 4000000 東京 5
6 翔 27 プログラマー 6000000 神戸 3
7 茜 24 販売員 3200000 仙台 1
8 隆 31 弁護士 8000000 横浜 12
9 葵 30 研究者 5800000 千葉 8
0 三郎 18 学生 0 東京 0
縦に結合(追加データも含めて「インデックス番号」を振り直して結合:ignore_index=True)
pd.concat() 関数で ignore_index=True を指定すると、結合元のデータフレームのインデックスは無視され、結合された新しいデータフレーム全体に対してゼロから始まる連番のインデックスが自動的に割り当てられます。これにより、インデックスの重複を防ぎ、すっきりとしたデータフレームになります。
df3 = pd.concat([df, df1], ignore_index=True)
df3
名前 年齢 職業 年収(円) 居住地 勤続年数
0 太郎 23 エンジニア 4500000 東京 2
1 花子 29 デザイナー 5500000 大阪 4
2 次郎 35 教師 4900000 名古屋 10
3 美香 42 医師 7300000 札幌 15
4 健一 18 学生 0 福岡 1
5 恵子 33 看護師 4000000 東京 5
6 翔 27 プログラマー 6000000 神戸 3
7 茜 24 販売員 3200000 仙台 1
8 隆 31 弁護士 8000000 横浜 12
9 葵 30 研究者 5800000 千葉 8
10 三郎 18 学生 0 東京 0
Pandas concatで横結合する (axis=1)
次に、データフレームを横方向(列方向)に結合する方法を見ていきましょう。これは、既存のデータフレームに新しい列を追加するイメージです。pd.concat() 関数で axis=1 を指定します。
【例】インデックスを振り直して縦結合したデータフレーム df3 に、新しい列「兄弟数」を含むデータフレーム df4 を横(列方向)に結合します。
追加データの作成
以下のコードで、横結合するための新しい列データを含むデータフレーム df4 を作成します。このデータフレームの行数は、結合元の df3 と同じになるように作成しています。
df4 = pd.DataFrame({
'兄弟数': [0,2,1,0,3,1,1,1,0,2,0]
})
df4
兄弟数
0 0
1 2
2 1
3 0
4 3
5 1
6 1
7 1
8 0
9 2
10 0
横に結合
pd.concat() 関数で axis=1 と指定することで、データフレームを横方向(列方向)に結合します。このとき、デフォルトではインデックス(行を識別するラベルや番号)が一致する行同士が結合されます。今回の例では、df3 と df4 は ignore_index=True で作成された新しい連番インデックスを持っており、行数も一致しているため、それぞれのインデックスが一致する行が正しく結合され、新しい列「兄弟数」が追加されていることがわかります。
もし、結合するデータフレーム間でインデックスが一致しない行や、一方にしか存在しない行がある場合、対応する場所に NaN が挿入されます。横結合では、結合元のデータフレームのインデックスが揃っていることが重要です。
df5 = pd.concat([df3, df4], axis=1)
df5
名前 年齢 職業 年収(円) 居住地 勤続年数 兄弟数
0 太郎 23 エンジニア 4500000 東京 2 0
1 花子 29 デザイナー 5500000 大阪 4 2
2 次郎 35 教師 4900000 名古屋 10 1
3 美香 42 医師 7300000 札幌 15 0
4 健一 18 学生 0 福岡 1 3
5 恵子 33 看護師 4000000 東京 5 1
6 翔 27 プログラマー 6000000 神戸 3 1
7 茜 24 販売員 3200000 仙台 1 1
8 隆 31 弁護士 8000000 横浜 12 0
9 葵 30 研究者 5800000 千葉 8 2
10 三郎 18 学生 0 東京 0 0
筆者の体験談:Pandas concatでやってしまった失敗
はじめてPndas concatを使ったとき、「縦結合と横結合の切り替えにはaxisの指定が必要」というのを見逃してしまい、横に結合したつもりが縦にずれてしまったということがありました。
さらに、インデックスを意識せずに結合してしまい、同じインデックス番号が混在して重複データのように見えたり、後の処理でindexを使うときにバグを引き起こした経験があります。
改善策:結合時には必ず次の2点を確認しています:
axis=0(縦)かaxis=1(横)か
ignore_index=Trueをつけるべきかどうか
また、出力結果をdf(データフレーム名).head()で直後に確認する癖をつけるようになってから、トラブルは激減しました。
Pndas concat 実行時によく発生するエラーとその対処法
pd.concat は便利な関数ですが、使い方によっては予期せぬエラーや問題が発生することがあります。ここでは、よく遭遇するケースとその対処法をいくつか紹介します。
1. 列の不一致による問題
縦方向に結合(axis=0)する場合、結合するデータフレーム間で列名が一致しない場合、concat はエラーとはせず、一致しない列をそのまま結合し、対応する行に NaN(欠損値)を挿入します。これはエラーではありませんが、意図しない結果になる可能性があります。
例:
df_missing には存在するが df には存在しない列があった場合など。
対処法:
- 結合前に列を揃える: 結合する前に、不要な列を削除したり、必要な列を追加して名前を一致させたりします。
- 必要な列のみを選択して結合する: 結合したい列だけを選択して結合し、後で必要に応じて他の列を結合します。
2. インデックスの重複による問題 (axis=0, ignore_index=False の場合)
縦方向に結合(axis=0)し、ignore_index=False(デフォルト)の場合、結合元のデータフレームのインデックスがそのまま引き継がれます。元のデータフレームで同じインデックスがある場合、結合後もインデックスが重複します。これはエラーにはなりませんが、後の処理でインデックスをキーとしてデータを操作する際に問題を引き起こす可能性があります。
例:
df と df1 を ignore_index=False で結合した df2 では、インデックス 0 が重複しています。
対処法:
-
ignore_index=Trueを指定する: 結合後に新しい連番のインデックスを振り直すことで、インデックスの重複を防ぎます。これが最も一般的な対処法です。 -
結合前にインデックスをリセットする:
reset_index()メソッドを使って、結合前に各データフレームのインデックスをリセットします。 -
インデックスに名前をつける:
df.index.name = '元のインデックス'のようにインデックスに名前をつけ、結合後にその列を利用することもできます。
3. 横結合 (axis=1) 時の行数の不一致
横方向に結合(axis=1)する場合、デフォルトではインデックスが一致する行同士が結合されます。結合するデータフレーム間でインデックスが一致しない行や、一方にしか存在しない行がある場合、対応する場所に NaN が挿入されます。行数が完全に一致しない場合も、不足している部分に NaN が発生します。
例:
df3 (11行) と df4 (11行) は行数が一致していたため NaN は発生しませんでしたが、もし df4 が10行しかなかった場合、最後の行に NaN が発生します。
対処法:
- 結合前に行数を揃える: 結合するデータフレームの行数やインデックスを事前に確認し、必要に応じてフィルタリングやパディングを行います。
-
インデックスをキーとして
mergeを使う: インデックスをキーとして厳密に結合したい場合は、concatの代わりにmerge関数をleft_index=True, right_index=Trueと指定して使用することを検討します。mergeなら、how引数で結合方法(内部結合、外部結合など)を細かく制御できます。
これらのエラーや問題は、concat 関数の axis と ignore_index 引数の挙動、そして結合するデータフレームの構造(列名、インデックス、行数)を理解することで、適切に対処・回避できます。結合後は必ず head() などで結果を確認する習慣をつけることが重要です。
実務シナリオ:複数の CSV ファイルをまとめて結合する
実際のデータ分析では、複数のファイルに分割されたデータを一つにまとめてから分析を始めるケースがよくあります。例えば、月ごとに保存された売上データや、日ごとのログデータなどです。
このような場合、一つずつファイルを読み込んで concat するのは大変です。Pandas と Python の pathlib ライブラリを組み合わせることで、指定したフォルダ内の複数の CSV ファイルを効率的に読み込み、一気に縦方向に結合することができます。
ここでは、「Google Drive の特定のフォルダ(例: My Drive/データ)」にある全ての CSV ファイルを読み込み、一つのデータフレームに結合するシナリオを想定します。
以下のコードを実行すると、まず Google Drive に接続し、指定したフォルダ内の CSV ファイルをリストアップします。その後、それぞれのファイルを読み込み、pd.concat を使ってまとめて縦方向に結合します。ignore_index=True を指定することで、結合後のデータフレームのインデックスを振り直します。
# ①googleドライブに接続する
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
import pandas as pd
from pathlib import Path
# ① フォルダパスを設定(「My Drive/データ」フォルダ内の CSV 全て)
folder = Path('/content/drive/My Drive/')
# ② glob で拡張子 .csv のファイル一覧を取得
csv_files = list(folder.glob('*.csv'))
# ③ 各ファイルを DataFrame に読み込み→リスト化
dfs = [pd.read_csv(fp) for fp in csv_files]
# ④ concat で縦方向に一気に結合
df_all = pd.concat(dfs, ignore_index=True)
# 確認
df_all.head()
Product Sales Date
0 C 200 2023-02-10
1 D 250 2023-02-25
2 A 100 2023-01-15
3 B 150 2023-01-20
▶️ googleドライブへの接続方法や、csvファイルの読み込み等については下記で解説しています。
Pandas CSV入門|Google Colabでread_csvを使ったファイル読み込み&保存を徹底解説【第2回】
まとめ
この記事では、Pandas のconcat関数を使ったデータフレームの縦結合・横結合の方法を解説しました。結合時にはaxis引数とignore_index引数を適切に使うことが重要です。
また、実務で役立つテクニックとして、pathlibライブラリと組み合わせて特定のフォルダ内の複数のCSVファイルを一気に読み込み、pd.concatでまとめて縦方向に結合する方法も紹介しました。
それぞれの結合方法について、改めてまとめましょう。
| 方法 | 関数 | メリット | デメリット・注意点 |
|---|---|---|---|
| 縦結合(インデックス維持) | pd.concat([df, df1]) |
元データのインデックス情報を保持できる。 | 結合元でインデックスが重複していると、結合後も重複し、後の処理で混乱を招く可能性がある。 |
| 縦結合(インデックス振り直し) | pd.concat([df, df1], ignore_index=True) |
新しい連番インデックスになり、データ管理が容易。 | 元データのインデックス情報が失われる。 |
| 横結合 | pd.concat([df3, df4], axis=1) |
異なる特徴量を持つデータを結合できる。 | 結合するデータフレームの行数が一致しない場合、不足部分にNaNが発生する。インデックス(行を識別するラベルや番号)が一致しないと意図しない結合になる可能性がある。 |
| 複数CSVの縦結合 | pd.concat(dfs, ignore_index=True) |
複数のファイルを効率的にまとめて処理できる。 | ファイルの形式や列構造が一致しないと、NaNが発生したり予期せぬ結果になる可能性がある。 |
データ結合はデータ分析の基礎となる重要なステップです。今回学んだconcat関数と、axisやignore_indexといった引数の使い方、そして複数のファイル結合テクニックをマスターして、効率的なデータ前処理を進めましょう!
✅ 本記事の内容をさらに深掘りしたい方へ:
📘 図解・FAQ・よくあるエラー対処などはブログ版にて解説しています:
👉 Pandas concat関数の完全解説|Python Data Lab