若干釣りタイトルです。深層学習による画像認識をAIと呼ぶか否か問題。
背景
五等分の花嫁の原作の方がだいぶ佳境ですね。
この前12巻が発売されましたが、作者によると14巻で完結とのこと。
だらだら続けるよりは良いんでしょう。名残惜しいけど。
さて、五等分の花嫁と言えば可愛い五つ子ちゃんたちを終始眺めるのも乙なもんですが、一応本作のテーマは「未来の花嫁は誰になるのか?」です。
劇中にも花嫁が何回か出てきてはいるけどもそこは五つ子、ウェディングドレスじゃ誰か分からないわけです。
人の目には誰か分からなくてもAIならば誰か当てられるのでは…?と言うのがこの記事の主題になっています。
実はアニメから入っていて、アニメを観ていた当初そんなネタで記事書いたらバズらないかなーとか何とか思ってたのですが、アイデアを温め、もといめんどくさがってたらいつの間にか師走に入ってました。アニメが今年の初めだったことを考えるとなんたる怠惰。アドベントカレンダーのおかげで無理やりネタ作り始められたよありがとうQiita!というわけでもなく、単に物語も佳境でそろそろ花嫁が誰か確定してしまいそうなので、割と焦りつつこの記事を認めている次第です。(したためるって漢字で認めると書くらしい。)花嫁が確定しちゃったらAIで花嫁を予想する!って言うこの記事のテーマが興醒めなので!!!
余談
ちなみに自分は当初
31452の順で好きでした。
そこから単行本の範囲を全て読み終わったタイミングで
34512
2019年12月現在単行本化していない範囲で
35412
と変遷してます。
結果
五つ子の検出結果
何枚か検出結果を抜粋表示してみます。
1
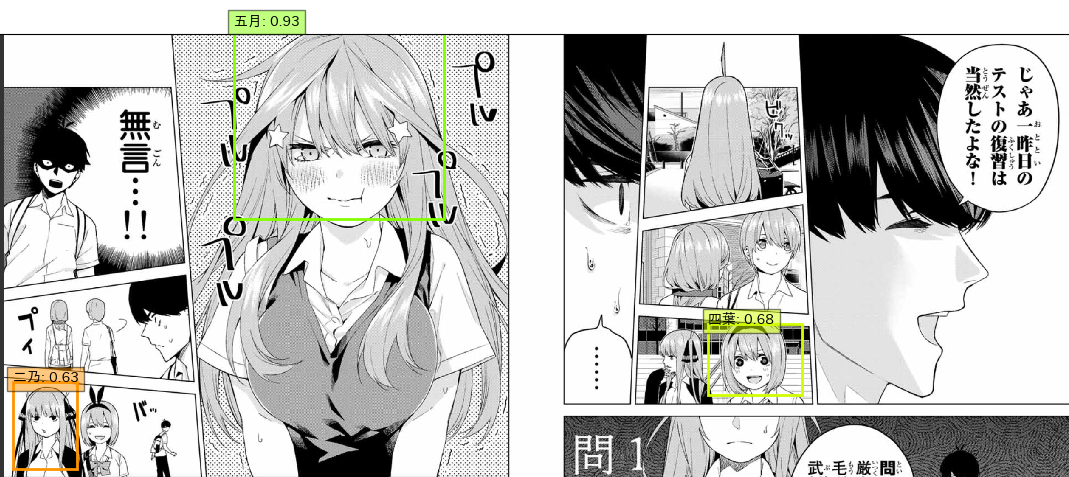
五月が高い精度で検出できてる一方、二乃と四葉が低いです。ですが、二乃はともかく四葉に関してはむしろうさみみがほとんど出ていないにもかかわらず検出できていることに驚きです。うさみみだけで判断しているわけではないようです。一花と四葉が一箇所検出されていませんが、あまり劇中に出てこない表情なので仕方ないでしょう。横を向いている二乃と後ろを向いている三玖と五月はもともと学習データにしていないのでこれで大丈夫です。
2
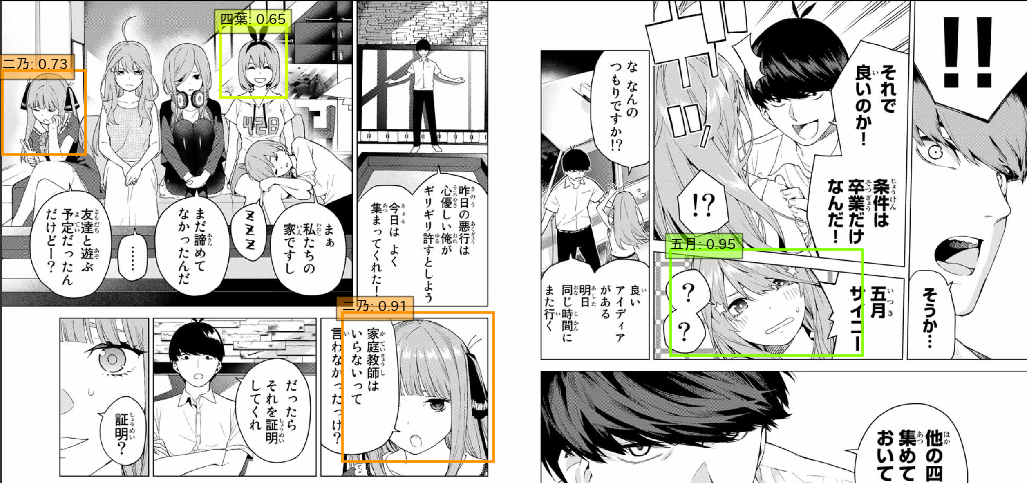
ある程度アップの顔であれば検出率が高そうです。左側に関しては一花はともかく三玖と五月は検出されてほしかったですね...
ただ、吹き出しがかぶっててもちゃんと二乃が検出されているのは予想外でした。
3

何故か検出されなかったシリーズ
4
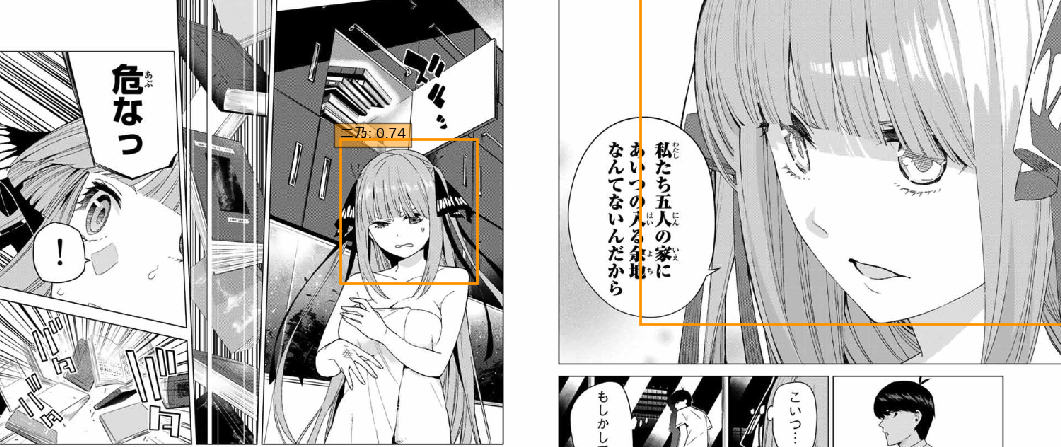
意外と検出できたシリーズ
5
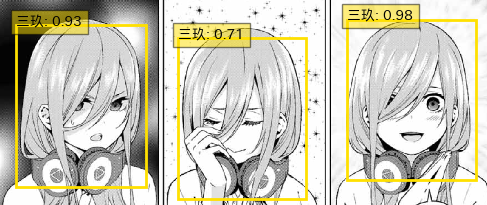
表情豊かな三女かわいい
6
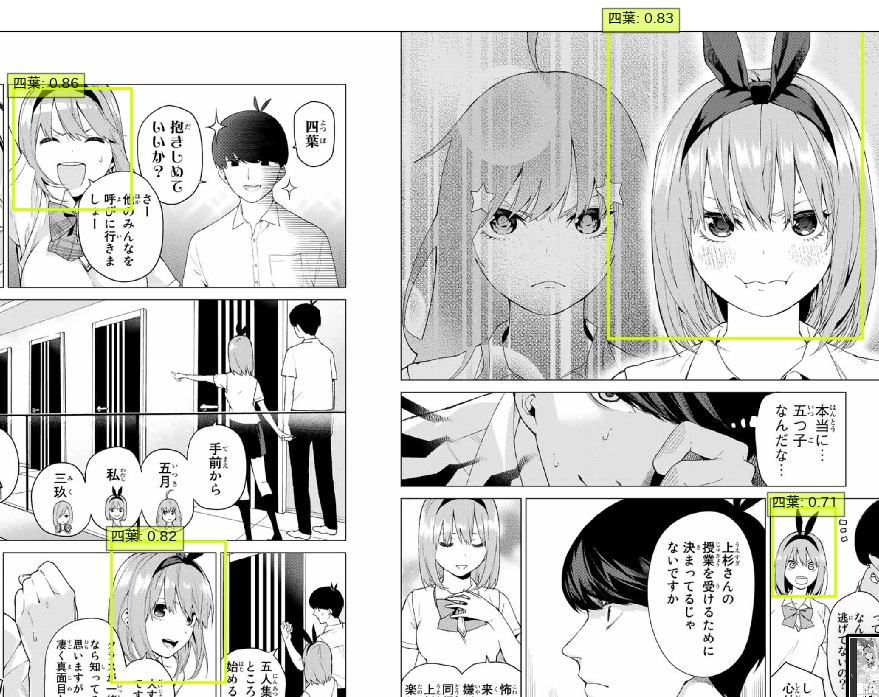
予想に反してうさみみが出てなくても検出率の高い四女かわいい
7
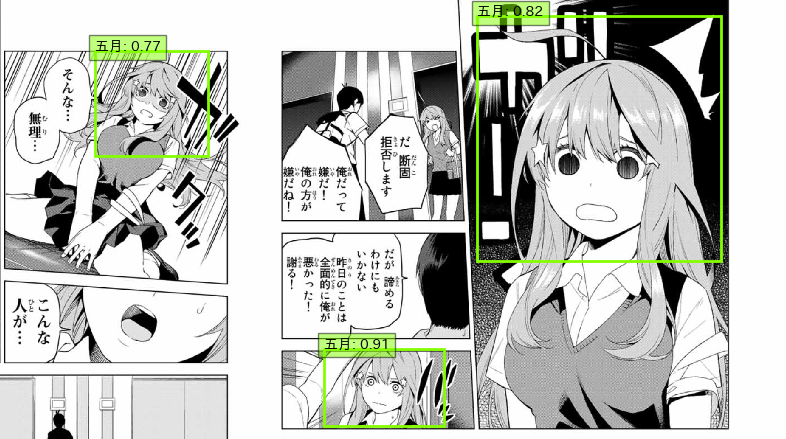

コミカルな顔もいける五女かわいい
8

綺麗に検出できました👏👏👏
本題
今までのはあくまで前置き、AIは五つ子を見分けられるのか?が一応のテーマでした。ここからこの記事の本題、AIは誰が花嫁と予想するのか!?になります。
使用するのは一巻のラストに出てくるこちらのコマです。

五つ子に関しては学習済みデータから誰なのかを推論してきましたが、花嫁についてはもちろん学習済みデータがないのでそのままでは誰も検出されません。なのでちょっとだけコードを弄って一番誰っぽいのか、を出してみます。
詳しくは後述しますが、SSDでは様々な領域に渡ってどこに何があるっぽいのかを0~1の範囲でスコアリングしていきます。このとき、たまに誤検知してしまうのですが、そういったものは理想的には低いスコアになります。(例えば何もない背景を一花として間違って検出してしまった場合は一花0.05のような感じ。)そういった誤検知、スコアの低い検出結果をすべて表示してしまうと下図のように大量の検出結果が出てくることになってしまいます。
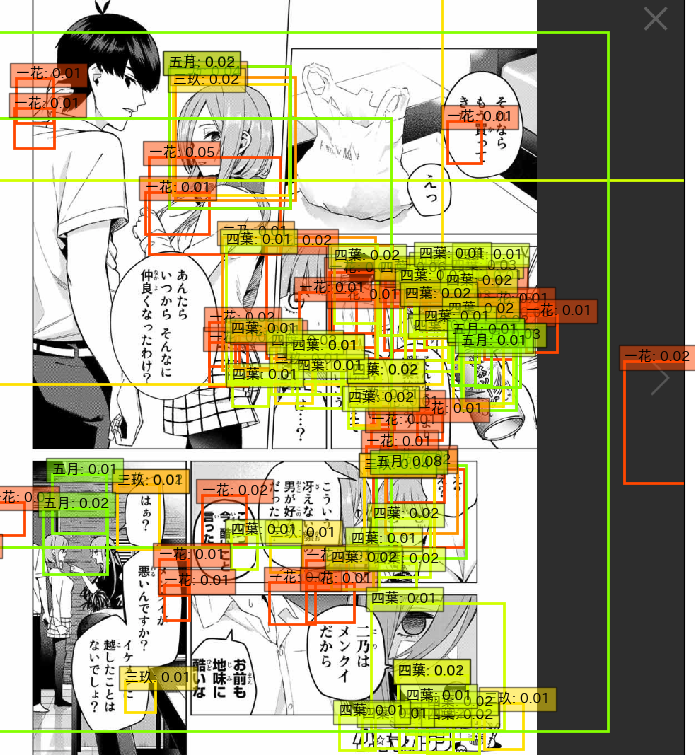
こういった大量の役に立たないデータを、閾値を設定して一定以上のスコアでフィルタリングすることで上にあるような特定の人物が検出されている画像ができます。そして今回行う花嫁検出では、花嫁の顔付近では五つ子に似た特徴量が取れてはいるが、スコアが低いために誰にも該当しないとして処理されていると予想できます。なので、閾値をうまく邪魔なデータが入らないような値に設定することでうまい具合に誰に似ているのかだけ抽出できるという仮説に基づき実験しました。
とまぁ、いきなりいろいろ書いてみましたが、スクロールしてすぐ結果が見えたら面白くないだろうからというだけの理由です笑
↓コード改修してAIで検出してみた結果がこちら↓
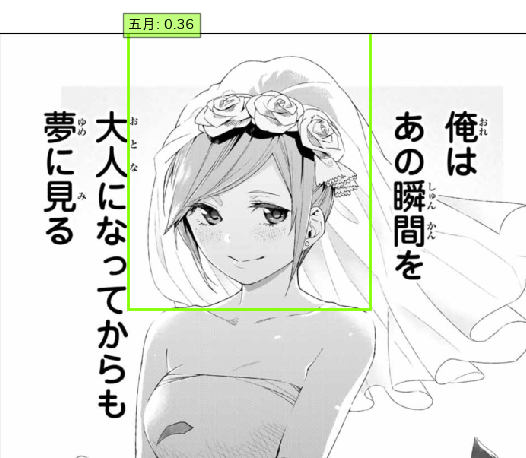
AIの判断として、精度が低いながらも五等分の花嫁のヒロイン、将来の風太郎の花嫁は五月っぽいとのことでした!
当初から五月がヒロインぽい?っていう声が多かった気がするので、この結果には納得です。三玖じゃなかった...
とはいえ劇中から結婚までに数年経っていることを考えると容姿もある程度変わっているでしょうし、そもそもが顔のそっくりな五人なので他の子が花嫁になる可能性は十分あります。なのでAI的には花嫁の顔?は五月っぽい結果が出たってのも一つの判断材料としてみなさんも花嫁予想してみてください!
学習
学習対象
アニメを観ている時に思いついたアイデアなので、アニメの映像を学習させようと思っていましたが、アニメ映像では髪の毛の色の情報を学習してしまいそうなのと、動画のデータを静止画に変換してアノテーションするのはだいぶ面倒なので今回は原作漫画の方をデータセットにしています。それでも各自身につけているアイテム(三玖のヘッドホンとか、四葉のウサミミとか)やアホ毛などを判別の材料にしてしまう可能性は高いですが、まぁそもそも学習データに入れざるを得ないので気にしないことにします。動画の方でも静止画に変換させてさえしまえばやり方は変わりません。通常深層学習で一から学習させるには多量のデータを用意する必要がありますが、後述の通り転移学習を行うので比較的少ないデータで学習ができます。学習セットには一巻分のデータを用意し、漫画見開きの二ページ分を一枚の画像として後述のアノテーションを行いました。
一巻には5話入っていて、得られた画像は100枚弱、五つ子が出てこないページもあるので実際にはそれよりも少なくなっています。
学習モデル
五つ子の誰かが映っている画像を一枚一枚学習させて、ある画像が誰の画像かを当てさせるのは深層学習フレームワークのチュートリアルでよく扱われるmnistに代表されるような典型的なタスクです。しかしせっかくの漫画ですし、どこに誰がいるのか、またサイズが異なっていてもしっかり検知してくれるような物体検出のタスクとして扱ってみようと思います。
物体検出にはいくつかモデルが存在しますが、ここではSSD(Single shot multibox detection)を使用しました。他にもYOLOやR-CNNがあります。
SSD
SSDについてググれば日本語の記事が出てきますし、記事が無駄に長くなるのとそして何より本題から逸れるので詳細については他に任せます。
論文:SSD: Single Shot MultiBox Detector
解説記事:Deep Learningによる一般物体検出アルゴリズムの紹介
解説記事:SSD (Single Shot Multibox Detector):ディープラーニングによる一般物体検出手法
軽く原理を説明すると、VGG16をベースとして得られた特徴量マップについて、繰り返し畳み込みを行いながら大小様々な大きさの特徴量マップ群を作ります。それらの特徴量マップ群それぞれに対してどの領域に何があるのかを、学習させるというプロセスを辿ります。大小様々な大きさの特徴量マップを用いることで、画像及び対象の大きさに関わらずに高い精度で検出することが可能なのがこのSSDの画期的な要素の一つです。詳しくは元論文もしくは解説ブログを参照してください。
実装については元論文のものはcaffeですが、他のフレームワークに移植したものが存在します。今回の学習にはpytorchで実装されたものを使用しました。
https://github.com/amdegroot/ssd.pytorch
ただしpytorchのバージョンアップによりそのままでは動かないため動くように修正したものがこちらです。
https://github.com/coil398/ssd.pytorch
変更点については下記おまけにまとめてあります。
転移学習
前述のSSDは以下のようなネットワークとなっています。
Liu, Wei, et al. "SSD: Single Shot MultiBox Detector." arXiv preprint arXiv:1512.02325 (2015).
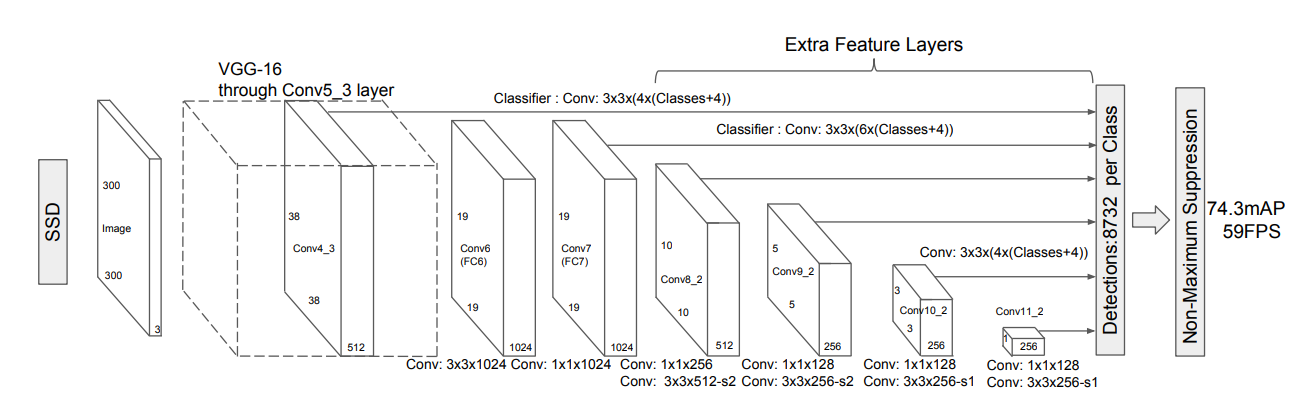
前述した通り前半部分がVGG16ベースのネットワーク、後半部分が大小様々な大きさの特徴量マップを作るネットワーク(Extra Feature Layers)です。
もちろんこれを一から学習させたのでは大量のデータが必要となりますし、何より計算資源が足りません。AWSのGPUインスタンスを借りるお金なんてないのです。
なのでここはVGG16の学習済みデータを用いて後半部分のみを学習させる転移学習を行います。SSDを他のフレームワークに移植したものはどれも学習済みVGG16のデータを扱う前提になっていると思いますので、READMEか何かに方法が書かれていると思います。
visualize
pytorchではvisdomを使用することで学習の経過を可視化することができます。今回使用したスクリプトではいくつか修正点がありますが、実際に使用すると以下のようなグラフが描かれます。
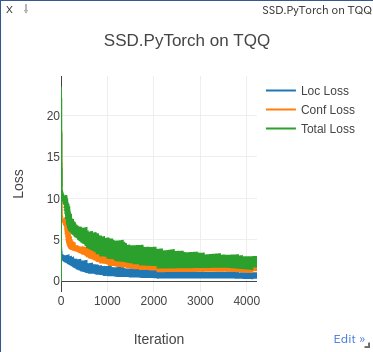
学習途中のグラフですが、順当に各種lossが下がっているのが分かります。場合によってはグラフが荒ぶってとんでもない値が出たりしますが、その場合はパラメータを弄るとどうにかなるかもしれません。実際今回グラフが荒ぶったので学習率を小さくしました。
アノテーション
よくある画像分類のタスクでは各画像がどのラベルに該当するかを正解データとして用意するだけですが、今回のような物体検出のタスクでは一枚の画像のどこに何があるのかを正解データとして渡す必要があります。SSDではPaccal VOCと言うデータでモデルの性能を評価しているので、そちらのフォーマットに従うことにしました。
Pascal VOCとは人間や動物、乗り物などの20種類のクラスに分類された画像が含まれるデータセットです。これを学習させて安いウェブカメラで遊ぶだけでも十分楽しいです。
こちらのフォーマットでは画像一枚ごとに、どこに何があるのかがXMLで記述されます。これについてはツールが存在するのでありがたく使わせてもらいましょう。自分はこちらを使用しました。
https://github.com/tzutalin/labelImg
インストール方法はREADMEに書かれています。環境に合わせてご用意ください。
アノテーションの様子は以下のような感じです。本来は見開きの画像に対して行っていますが、まるまる載せるのはアレなので五人が集合したコマについてのデモです。
元画像:五等分の花嫁一巻の最後のところ


アノテーションは以下のルールに基づき行いました。
・極端に横、もしくは上下を向いていない。
・顔がおよそ8割以上見えている。
・極端に小さくないもの
・身につけているものを含め大体首辺りまですべて含む
・変装しているものは変装先として扱う(四葉に変装している三玖は四葉として扱う)
・吹き出しや別のキャラで隠れている場合も、顔が8割以上程度見えていれば顔が存在するであろう領域全体についてアノテーションを行う(分かりにくいですが、ふきだしや他のキャラが居ても関係なしに枠で囲います。)
これだとアホ毛やうさみみリボン、ヘッドホンのある三玖、四葉、五月が有利な気もしますが、顔だけだとさすがにうまく行かない気がするのでこうしました。
体全体を対象にもしてみたいですが、漫画だとどうしても体全体のコマが少ないので顔全体を対象としています。
フォルダ構成
大体のSSD用のスクリプトはVOC pascalを使用することを前提にしているため、独自のデータセットを用いる場合はいくつか修正が必要です。変更点を最小限に抑えるためVOC pascalのフォーマットに従いつつ、今回使用するssd.pytorchでは以下のようなフォルダ構成としました。(一部省略しています。)
.
├── LICENSE
├── README.md
├── __pycache__
│ └── ssd.cpython-37.pyc
├── data
│ ├── VOCdevkit
│ ├── __init__.py
│ ├── __pycache__
│ ├── coco.py
│ ├── coco_labels.txt
│ ├── config.py
│ ├── example.jpg
│ ├── scripts
│ ├── tags
│ ├── tqq.py
│ └── voc0712.py
├── ssd.py
├── test.py
├── train.py
├── inference.py
└── weights
└── vgg16_reducedfc.pth
14 directories, 29 files
data/VOCdevkitがデータセットの入っているフォルダです。
VOCdevkitの中身がこんな感じです。
.
├── TQQ
│ ├── Annotations
│ ├── ImageSets
│ └── PNGImages
└── VOC2012
├── Annotations
├── ImageSets
├── JPEGImages
├── SegmentationClass
└── SegmentationObject
10 directories, 0 files
必要になるのはAnnotations, ImageSets, [PNG|JPG]Imagesです。
それぞれアノテーションしたxmlファイル群を入れるフォルダ
アノテーションしたx使用する画像を指定するファイル群を入れるフォルダ
画像群を入れるフォルダです。
ちなみにですが、Pascal VOCはjpgで自前のデータセットTQQはpngです。なので名前をPNGImagesとしています。読み込むときにpngを指定すれば問題なく学習可能です。ちなみにTQQは五等分の花嫁の英題の略です。
推論
今回コードを借りたレポジトリには推論用のスクリプトが入っていなかったため別途用意しました。。SSDの推論では画像を入力すると、どこに何があるのかを枠で囲った画像が出力されます。これをバウンディングボックスと呼びます。
検証方法
タイトル回収として花嫁の画像について推論を行いたいのですが、このままだともちろんどのキャラにも該当しないためにバウンディングボックスが出ません。なので閾値を下げてスコアが低くても姉妹の誰かの推論が出てくるようにしています。
これは前述した通り、花嫁の顔付近で五つ子と似た特徴量が取れているだろうという仮説に基づいています。
おまけ
変更点
pytorchのバージョンアップに従い、元のスクリプトが動かなくなっています。issueをいろいろ見ればわかりますがまとめておきます。
size_average=Falseをreduction='sum'に変更
loss_cのテンソルの次元を変更loss_c = loss_c.view(pos.size()[0], pos.size()[1])を追加
visualize用の変数vizをグローバルに宣言するためにglobal vizを追加
lossがnanになるので、学習率を下げる
vizがエラーを吐くのでupdate_vis_plotの引数を追加None->iter_plot(workaround)
batch_iteratorがエラーを吐くのでエラー処理try except StopIterationの追加
loss.data[0]をloss.item()に変更
宣伝
マガポケで五等分の花嫁が読めるので読もう(ステマ)
ちなみに漫画は紙派なので原作を全部紙で集めましたが、今回の実験のためにウェブ版にも課金しました。懐かしいシーンが多かったです。初期はやはり三玖無双ですね。
最後に
2日前に見切り発車で始めましたがなんとなくそれっぽい結果が出たので一安心です。
日曜日の夜ABC147後に徹夜でアノテーションをしてくれた研究室の後輩のつっちーに感謝👐