概要
機械学習を最近勉強はじめたのですが、やはり「何かに役立てたい!」と思いました。まあはっきり言ってしまえば、お財布に貢献するようなことがしたいと。

そこで、いろいろ検討してみたのですが、分析しやすそうな競馬の順位予想をやってみようと思いました!ちなみに僕は競馬を一切やったことがありません。どういうルールかさえよく分かってないです。スティール・ボール・ランで得た知識しかないです。
予想方針
予想は、一般的な方法ではなくて違うアプローチをとりました。
一般的には、体重、勝率、騎手、オッズ などなど馬の情報やレースに関する情報をもとに順位を予想することが多いのですが、僕が利用した方法は予想屋(tipster)の予想をもとに順位を当てるというものです。
僕は競馬ドシロウトなのでよくわからないのですが、競馬には予想屋という人たちがいて、レースごとにどの馬が勝つか、どの馬が負けるかなどを予想しているようです。変な世界です。
今回のアプローチですが、実は僕が考えた方法ではなくて、Kaggle で公開されているものです。

今回の記事は Kaggle にアップロードされているデータとコードを元に自分なりに分析した内容を紹介していきます。
コードはすべて以下で公開しています
hourse_racing - cohki0305
データセット
Kaggle に用意されているデータ(csv ファイル)のカラムには、Tipster(予想屋), Date(日付), Track(レース場), Horse(馬名), Bet Type(予想), Odds(掛け率), Result(結果), Tipster Active(予想屋が現役か否か)があります。レース場に York とあるのでおそらくイギリスのデータですね。
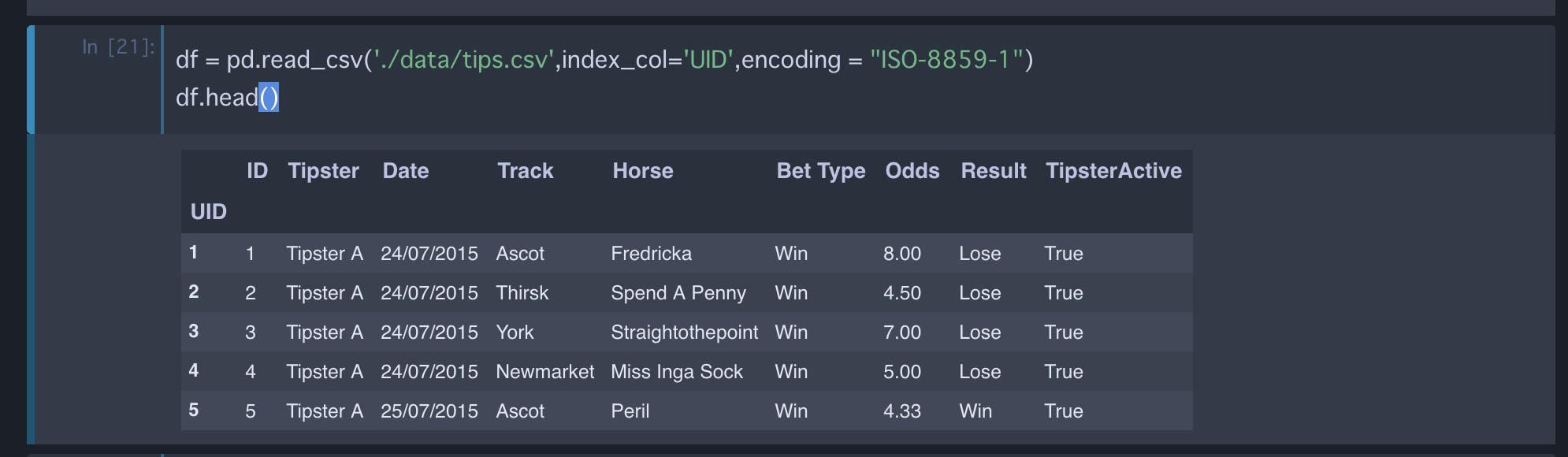
約 39,000 のデータがあり、31 人の予想屋を元にデータが集められています。まあこれくらいあれば十分な気がします。
ライブラリを読み込む
はじめに今回必要なライブラリを読み込んでおきます
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Dense
前処理
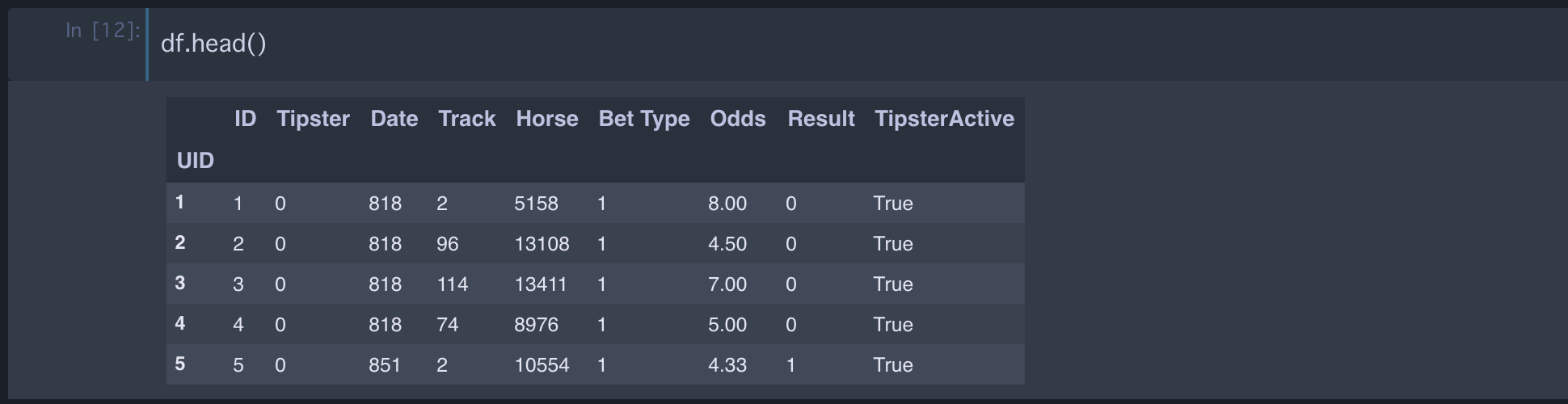
はじめに前処理を行っていきます!文字列のままでは分析できないので、以下のようにしてカテゴリー分けします。sklearn の LabelEncoder を使うと簡単にできます。
cat_var = df.dtypes.loc[df.dtypes=='object'].index
le = LabelEncoder()
for var in cat_var:
df[var] = le.fit_transform(df[var])
DataFrame を確認すると以下のようにいい感じに前処理できていることが確認できます。
学習用のデータとテスト用のデータを用意する
前処理したデータを学習用のデータとテスト用のデータに分けておきます。学習用のデータは文字通りモデルを学習させる際に使います。そして、テスト用のデータは学習させたモデルがどれくらい正しい精度が出るのかを確かめるためのデータです。
X = df[['Tipster', 'Track', 'Horse', 'Bet Type', 'Odds']].values
y = df.Result.values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
Keras を使い学習を行う
Keras というフレームワークを使い学習させていきます。Google のエンジニアが開発した tensorflow のフレームワークです。

Keras を使うには、input の次元を調べる必要があるので、まず X の shape を確認します。
print(X_train.shape)
=> (30598, 5)
5 つのカラムがあって、列が約 3 万あることが確認できました。
Keras を使うと非常に簡単にニューラルネットワークの層を構築することが可能になりますよ。以下のように model に Dense を add していくだけです。
model = Sequential()
model.add(Dense(10, input_dim=5, kernel_initializer='normal', activation='relu'))
以下は、出力するニューロンを 10 個、input が 5 の 活性化関数が relu の layer という意味です。
Dense(10, input_dim=5, kernel_initializer='normal', activation='relu')
今回は予想屋が正解しているか否かを調べる Binary Classification なので、output 層は以下のようにしておきます。
model.add(Dense(1, kernel_initializer='normal', activation='sigmoid'))
そして最後に以下のように、loss function, optimizer, metrics を指定して、学習させます。学習は fit メソッドを使うだけなのでめっちゃ簡単です。
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train)

loss がめっちゃ大きいですが...accuracy が 0.8 つまり正答率が 80 % くらいになりました!
80 % の確率で予想屋の予想を当てられるということです。結構良さそうですよね。
モデルの精度を確認する
最後にこのモデルが未知のデータに対しても有効なものか確認していきます。今のところは学習用のデータでいい結果が出ただけなので、こいつが知らないデータを与えてもちゃんと正解できるのかを確かめていきます。
Keras では evaluate を使います。
score = model.evaluate(X_test, y_test)
score[1]
=> 0.80143790849673202
こちらも 0.8 くらいなので過学習が起こらず、未知のデータに対してもちゃんとした結果を出せることがわかりました!80 % なら全然金儲けできるよねw
課題
80% と結構いい結果でしたが、とはいえ、まだまだ課題があります....
- 日本の予想屋のデータでチャレンジする
- パラメータのチューニング
- モデルの比較
などなどがあるかなーと思っています。今回は Kaggle で楽しましたが、日本の競馬情報と予想屋の予想データを集めてくるのが結構大変そうだなという印象です。
(あとは僕が機械学習にそんなに詳しくないので、他にも課題があってもよくわからないという課題もありますね)
余談
今回は競馬の予想でしたが、予想屋の予想を行うアプローチは他の分野においても利用できそうだなと思いました。たとえば、株や FX など。本来これらの予想は変数が多くて分析するのが大変ですが、予想屋の予想であれば、今回のように数カラムで信用できる結果を得られるので、有効的なアプローチだと思う。
またこういう手法が一般的になれば、正しい予想を行う人なのかどうか機械学習によって厳しく評価される日が来るでしょうね。