個人開発というと大袈裟ですが、簡単なWeb APIを開発し公開しました。
AWS Lamda + API Gatewayを使ったサーバレス構成で、DBにDynamoDBを採用しました。
実務ではPostgreSQLとSQL Serverを使っており、NoSQLの利用経験がありません。
当然ですが、RDBの知識ではNoSQLのDB設計で苦労する点が多くありました。
実際の設計の過程を交えながら、こちらのサーバーレスアプリケーション向きの DB 設計ベストプラクティスを見ていきたいと思います。
開発するAPIは日本の主な山岳一覧を提供するAPI。
詳細は、以下をご確認いただけますと幸いです!
API ドキュメントを完成イメージとして
自分ならこう設計する!と考えならがら、読んでいただくと面白いかと思います。
サーバーレスアプリケーション向きの DB 設計ベストプラクティス
以下の順序で設計をおこなう例が紹介されています。
- 業務分析とデータのモデリング
- アクセスとパターン設計
- TableとIndex設計
- クエリ操作設計
業務分析とデータのモデリング → ER図
- 対象ドメインのデータをモデリング
- RDB設計と同じく、ER図による概念と論理レベルの整理は有効
メモ程度のER図ですが、RDBだったらこんな感じの設計かなというものを書き起こしました。
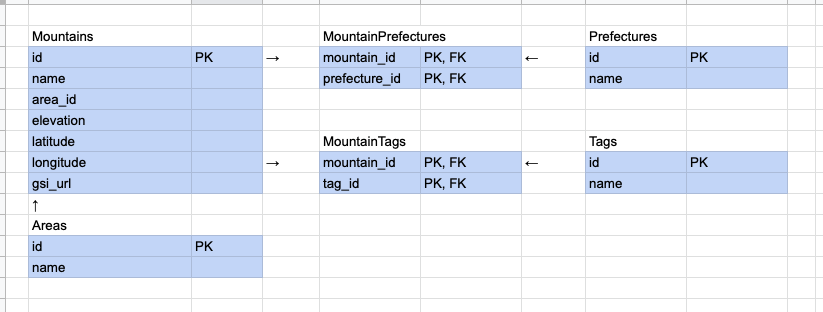
ここでやったこと・考えたこと
RDBで設計するなら... とサクッと設計した。
- 山は都道府県をまたぐ = 山と都道府県は1対多の関係だから別テーブルで管理するかな
- タグも「百名山」「二百名山」など複数を想定しているし、上と同じだな
- 同じエリアに複数の山が存在するから、別テーブルでエリアを管理してIDを山に持たせるべきかな
アクセスとパターン設計 → ユースケースリスト
| # | Entity | Use Case | Remarks |
|---|---|---|---|
| 1 | Mountains | getMountains | 山一覧の全件取得 |
| 2 | Mountains | getMountainByMountainID | 山ID一致での情報取得 |
| 3 | Mountains | getMountainByMountainName | 山岳名での検索(部分一致) |
| 4 | Mountains | getMountainByPrefectureID | 都道府県IDでの検索 |
| 5 | Mountains | getMountainByTag | 百名山検索 |
ここでやったこと・考えたこと
ユースケースを洗い出した。
- REST APIで考えているし、全件取得とIDでの絞り込みはいるな
- 実装中に「あぁ、offsetとlimitが欲しいかも」と思う
- 検索は①山岳名、②都道府県、③タグ(百名山)
- 初回リリース時は百名山のみでいくことにし、後で機能拡張する
- エリアID検索も欲しいかなと思ったけど、一旦保留
- 実装中に「山岳名のかなで検索できると親切だな」と思う
テーブル・インデックス設計 → テーブル定義書
まず、シンプルに考えてみる

- Partition Keyは
IdでNumber型 - DynamoDBだし、リレーションはなしで実装したい → 都道府県やタグは値をカンマ区切りで保持する
- RDBならこの設計にはしないな...
問題点
GetItemやQueryがIdにしか使えない。
その他の属性で検索したい時にScanとFilterが使う必要があり、高コストになってしまう。
RDBにはない制約があり、実際にDynamoDBの操作をおこなって徐々に理解できた。
GSIを追加してみる

GSIを追加したが... たぶんダメだ、あかんやつだと気づく。
-
Nameは部分一致で検索したいが、GSIのパーティションキーにしたら部分一致で検索できない -
PrefectureもTagもカンマ区切りで値を保持していると部分一致する必要が出てくる
もし完全一致でのデータ取得であれば、GSIが追加されたことでQueryが可能になるはず。
例えば、山岳名Nameの完全一致で検索であればOKだが、
クエリパラメータでnameを渡すことをなるので、完全一致では不便だ。
そして、資料では以下の問題点が挙げられています。
問題点
- GSIが増えることで金銭コスト増、管理コスト増
- 多くのGSIをアプリケーションを意識する必要がある
DynamoDBらしいテクニック「GSI オーバーローディング」を使ってみる
重要ポイント
- データを縦に持つ設計にする
- 1つのGSIに複数の検索要件を持たせる(= GSI オーバーローディング)
- 検索条件として指定したい属性をキーとするGSIを定義
- GSIの数が少なくなり、コストやクエリを最適化できる
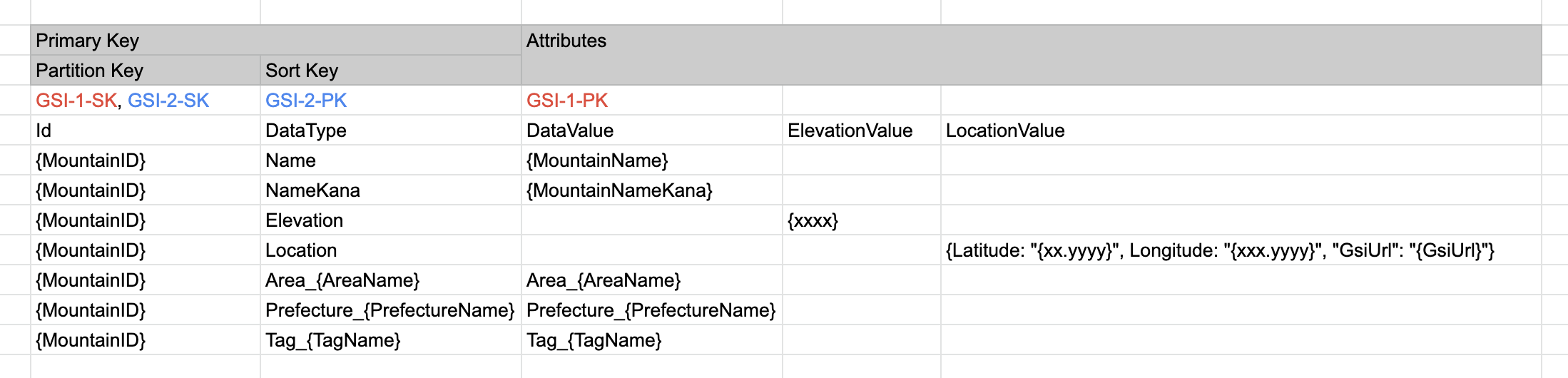
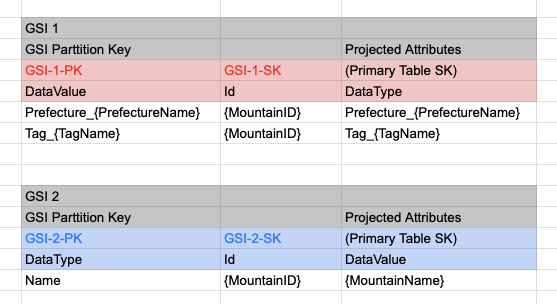
データを縦に持つ... 本当に!?という感じで設計を開始しました。
実務で縦にデータを持つ設計をされたDBで良い印象がなかったので、半信半疑でした笑
- 忠実にデータを縦に持つように設計
- GSIは2つ作成
- DataValue_Id_Index:都道府県とタグを指定し、Idを取得
- DataType_Id_Index:
DataTypeにNameを指定し、DataValueに山岳名を含むかをFilterしてIdを取得(Scan+Filterでなくなる)
-
Elevation(標高)をNumber型で扱うため、DataValueではなくElevationValueに格納する- 設計後、
String型でDataValueに格納しても問題ないと思ったが、標高が文字列はやはり解せんと思いそのままにした
- 設計後、
-
Locationを構造体で持つようにした- 特に検索でも使用しないので、レコード数削減を狙った
設計後に思ったこと
- Area_のプレフィックスは不要では?
- DataTypeがAreaでも問題ないと思う
- ただ、Area_があることの弊害も少ないのでそのままにした
- APIでレスポンスを返す際にArea_を置換する必要やデータ量もArea_をなくすことで削減できると思われる
-
ElevationもString型でDataValueに格納しても問題ないのでは?- 流石に標高が文字列はキモいので、そのままにした
実装中に思ったこと
- GetItemが使えない?
- Id=1の山岳情報を取得する際、データを縦に持っているのでQueryでId=1のもの全てを取得する必要がある
- データを縦に持つため、APIのレスポンスの形と異なり、サーバーサイドで成形する必要がある
- これが結構面倒くさかった
- RDBだと、割とDBから取得した結果をそのまま返すような実装にすることが多い(もちろん複雑なデータではないからだが)
実際のデータイメージ
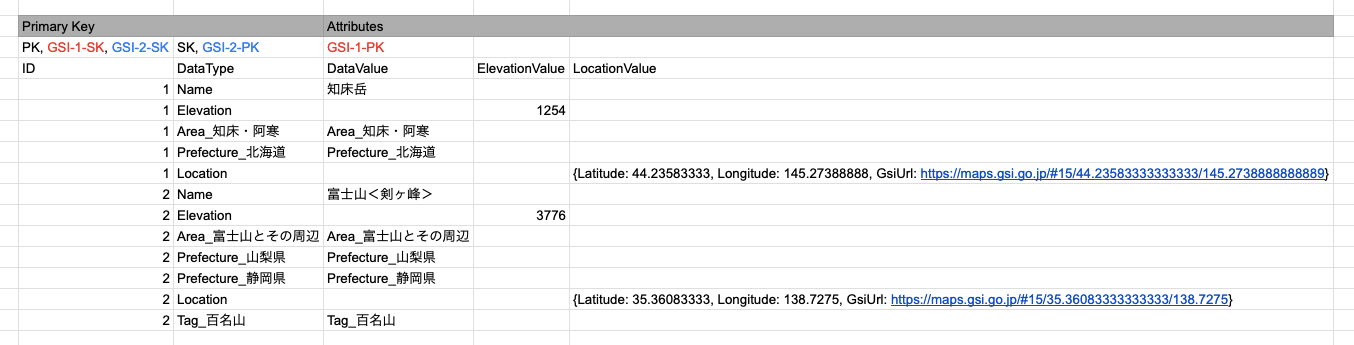
- 特定のIdのデータを取得したい場合、Query(Id = :mountainId)が使用できる
- 例)Query(Id = 777)
- 特定の都道府県のIdを取得したい場合、Query(DataValue = :prefectureName)が使用できる
- 例)Query(DataValue = "Prefecture_長野県")
クエリ条件定義

これまでの設計をふまえ、クエリ条件を定義した。
Scan+Filetrで負荷をかけることなく、データを取得することができそう。
また、GSIも2つに抑えられている。
まとめ
リレーションが不要で、初回のデータ登録以外ではデータの取得のみのためDynamoDBを採用した。
(お勉強駆動開発であるにはあるが)
SQLがなく、高度な検索や、取ったデータをこねくりまわすのはアプリケーション側の役割になる。
高速にI/Oを行えるのがDynamoDBのメリットではあるので、
高度な検索が不要で、高速にデータを取得できるという点では、理にかなった選択であると思っています。