はじめに
次のように基準マーカー付きの平面(机)に置いた任意物体の位置を、実座標系で求めることを目標にします。
実装は Python で行ない、OpenCV の ArUco というモジュールを利用します。

- OpenCV/ArUcoライブラリで物体位置計測 @ inoblog を参考にさせていただきました。
実行環境
GoogleColab.(Python 3.6.9)を利用します。使用したモジュールのバージョンは次のようになります。
%pip list | grep -e opencv -e numpy
numpy 1.17.5
opencv-contrib-python 4.1.2.30
opencv-python 4.1.2.30
ArUcoによるマーカーの作成
はじめに、処理に必要なモジュールを読み込みます。
GoogleColab. 環境では、cv2.imshow(...) が利用できないのですが、次のようにすることで、 cv2_imshow(...) で画像(np.ndarray)を実行結果セルに出力することができます。
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
ArUco には、あらかじめ定義されてるマーカー群が用意されています。今回は、それを利用します。aruco.getPredefinedDictionary(...) により、事前定義されたマーカーが格納されている辞書を取得します。引数 aruco.DICT_4X4_50 により、正方形の内部に $4\times 4$ の塗りつぶしパターンを持ったマーカーが最大 $50$ 個まで利用可能な辞書を選択しています。
aruco = cv2.aruco
p_dict = aruco.getPredefinedDictionary(aruco.DICT_4X4_50)
marker = [0] * 4 # 初期化
for i in range(len(marker)):
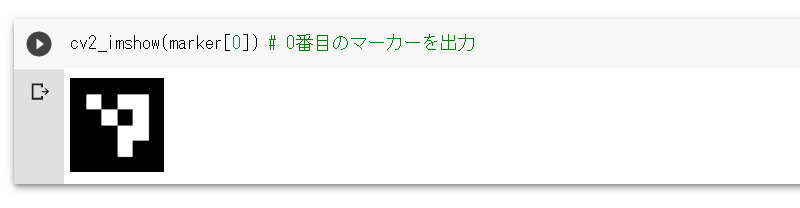
marker[i] = aruco.drawMarker(p_dict, i, 75) # 75x75 px
cv2.imwrite(f'marker{i}.png', marker[i])
上記を実行すると「marker0.png」から「marker3.png」までの $4$ つのファイル($75\times 75$ピクセルサイズ)が出力されます。
GoogleColab.環境であれば、作成されたマーカーは cv2_imshow(...) で出力セルに表示して確認できます。正方形のなかに $4\times 4$ の塗りつぶしパターンを持ったマーカーが作成されていることが分かります。
もし、aruco.getPredefinedDictionary(...) の引数に DICT_5X5_100 を与えれば、$5\times 5$ のパターンで最大 $100$ 個までのマーカーが定義された辞書を取得できます。

ArUcoによるマーカーの検出
「marker0.png」つまり aruco.DICT_4X4_50 の 0番目のマーカーを出力したものを紙に印刷します。そして、それをカメラで撮影したものを「m0-photo.jpg」とします。これを対象にマーカー検出し、その検出結果をオーバーレイした画像 img_marked を出力します。
img = cv2.imread('m0-photo.jpg')
corners, ids, rejectedImgPoints = aruco.detectMarkers(img, p_dict) # 検出
img_marked = aruco.drawDetectedMarkers(img.copy(), corners, ids) # 検出結果をオーバーレイ
cv2_imshow(img_marked) # 表示

マーカー全体が**緑色の四角形**、マーカー左上が**赤色の四角形**、マーカーID(番号)が**青色の文字**で元画像に重ねて描画されています。これより、マーカー検出が適切にできていることが分かります。
aruco.detectMarkers(...) の戻値について詳しく見ていきます。
corners には、画像から検出された各マーカーのコーナー(四隅)の画像座標が、np.ndarray のリストで格納されます。
# ■ 戻値 corners
# print(type(corners)) # -> <class 'list'>
# print(len(corners)) # -> 1
# print(type(corners[0])) # -> <class 'numpy.ndarray'>
# print(corners[0].shape) # -> (1, 4, 2)
print(corners)
[array([[[265., 258.],
[348., 231.],
[383., 308.],
[297., 339.]]], dtype=float32)]
コーナーの座標は、マーカーの左上、右上、右下、左下の順番で反時計周りで格納されています。つまり、次のようになります。

ids には、画像から検出されたマーカーのIDが numpy.ndarray 形式で格納されます。
# ■ 戻値 ids
# print(type(ids)) # -> <class 'numpy.ndarray'>
# print(ids.shape) # -> (1, 1)
print(ids)
実行結果は [[0]] のようになります([0] ではない点に注意してください)。
rejectedImgPoints には、画像内に検出された正方形のうち、その内部に適切なパターンを含まない正方形の座標が格納されます(原文 contains the imgPoints of those squares whose inner code has not a correct codification. Useful for debugging purposes.)。
これについては、具体例を見てもらったほうが分かりやすいと思います。rejectedImgPoints には、図内の矢印で指しているような正方形の座標が格納されます。

ArUcoによるマーカーの検出(マーカーが複数ある場合)
次のように画像内に複数のマーカーが存在する場合(同じマーカーが2つ以上存在する場合を含む)の結果について確認しておきます。

検出のためのコードは先と同じです。検出結果をオーバーレイすると次のようになります。同じマーカーが2つ以上存在しても問題ありません。

aruco.detectMarkers(...) の戻値 ids と corners は次のようになります。ID順にはソートされていない点に注意します。
[[1]
[1]
[0]
[2]]
[array([[[443., 288.],
[520., 270.],
[542., 345.],
[464., 363.]]], dtype=float32), array([[[237., 272.],
[313., 255.],
[331., 328.],
[254., 346.]]], dtype=float32), array([[[ 64., 235.],
[140., 218.],
[154., 290.],
[ 75., 307.]]], dtype=float32), array([[[333., 113.],
[404., 98.],
[424., 163.],
[351., 180.]]], dtype=float32)]
実座標系における位置計測
最初に作成した4つのマーカー「marker0.png」~「marker3.png」を、次のように時計まわりに配置した紙を用意します。ここでは、マーカー間の距離を $150\mathrm{mm}$ としました(この用紙作成は、厳密に行なわないと精度が悪くなります)。

この紙の上に、位置検出したい対象物「イヌ」を配置して、上方の適当な位置から撮影します(このときの撮影位置や角度は厳密である必要はありません)。目的は、この「イヌ」の位置をマーカーを基準とした実座標系で求めることです。

真上から見た画像に変換
上方の適当な位置・角度から撮影したカメラ画像を、真上から見た画像に変換していきます。ここでは、変換後の画像が $500\times 500, \mathrm{px}$ になるようにしました。
aruco = cv2.aruco
p_dict = aruco.getPredefinedDictionary(aruco.DICT_4X4_50)
img = cv2.imread('inu.jpg')
corners, ids, rejectedImgPoints = aruco.detectMarkers(img, p_dict) # 検出
# 時計回りで左上から順にマーカーの「中心座標」を m に格納
m = np.empty((4,2))
for i,c in zip(ids.ravel(), corners):
m[i] = c[0].mean(axis=0)
width, height = (500,500) # 変形後画像サイズ
marker_coordinates = np.float32(m)
true_coordinates = np.float32([[0,0],[width,0],[width,height],[0,height]])
trans_mat = cv2.getPerspectiveTransform(marker_coordinates,true_coordinates)
img_trans = cv2.warpPerspective(img,trans_mat,(width, height))
cv2_imshow(img_trans)
実行結果は、次のようになります。各マーカの中心が画像の四隅になるように変形されていることが分かります。

もっと斜めの位置から撮影した画像を使っても、次のように真上から見たような画像に変換することができます。

ここでは分かりやすいように、各マーカーの中心が変換後画像の四隅になるようにしました。しかし「イヌ」の位置を計算するためには何かと都合が悪いです(四隅にマーカーの断片が写り込んでいることも・・・)。
そこで、紙上の $150\times 150\mathrm{mm}$ の四角形に接している各マーカーの角が、変換後画像の四隅になるようにプログラムに手を加えます。
aruco = cv2.aruco
p_dict = aruco.getPredefinedDictionary(aruco.DICT_4X4_50)
img = cv2.imread('inu.jpg')
corners, ids, rejectedImgPoints = aruco.detectMarkers(img, p_dict) # 検出
# ここを変更
corners2 = [np.empty((1,4,2))]*4
for i,c in zip(ids.ravel(), corners):
corners2[i] = c.copy()
m[0] = corners2[0][0][2]
m[1] = corners2[1][0][3]
m[2] = corners2[2][0][0]
m[3] = corners2[3][0][1]
width, height = (500,500) # 変形後画像サイズ
marker_coordinates = np.float32(m)
true_coordinates = np.float32([[0,0],[width,0],[width,height],[0,height]])
trans_mat = cv2.getPerspectiveTransform(marker_coordinates,true_coordinates)
img_trans = cv2.warpPerspective(img,trans_mat,(width, height))
cv2_imshow(img_trans)
実行結果は、次のようになります。

この画像の大きさは $500\times 500, \mathrm{px}$ で、それに対応する紙上の大きさは $150\times 150, \mathrm{mm}$ です。よって、画像上の座標が $(160\mathrm{px},,200\mathrm{px})$ であれば、対応する実座標は $(160\times\frac{150}{500}=48\mathrm{mm} ,, 200\times\frac{150}{500}=60\mathrm{mm})$ のように求めることがでます。
画像からの物体検出
OpenCV で用意されている各種関数を使って、上記画像からイヌの位置を求めていきます。特にポイントとなるのは cv2.connectedComponentsWithStats(...) です。
tmp = img_trans.copy()
# (1) グレースケール変換
tmp = cv2.cvtColor(tmp, cv2.COLOR_BGR2GRAY)
# cv2_imshow(tmp)
# (2) ぼかし処理
tmp = cv2.GaussianBlur(tmp, (11, 11), 0)
# cv2_imshow(tmp)
# (3) 二値化処理
th = 130 # 二値化の閾値(要調整)
_,tmp = cv2.threshold(tmp,th,255,cv2.THRESH_BINARY_INV)
# cv2_imshow(tmp)
# (4) ブロブ(=塊)検出
n, img_label, data, center = cv2.connectedComponentsWithStats(tmp)
# (5) 検出結果の整理
detected_obj = list() # 検出結果の格納先
tr_x = lambda x : x * 150 / 500 # X軸 画像座標→実座標
tr_y = lambda y : y * 150 / 500 # Y軸 〃
img_trans_marked = img_trans.copy()
for i in range(1,n):
x, y, w, h, size = data[i]
if size < 300 : # 面積300px未満は無視
continue
detected_obj.append( dict( x = tr_x(x),
y = tr_y(y),
w = tr_x(w),
h = tr_y(h),
cx = tr_x(center[i][0]),
cy = tr_y(center[i][1])))
# 確認
cv2.rectangle(img_trans_marked, (x,y), (x+w,y+h),(0,255,0),2)
cv2.circle(img_trans_marked, (int(center[i][0]),int(center[i][1])),5,(0,0,255),-1)
# (6) 結果の表示
cv2_imshow(img_trans_marked)
for i, obj in enumerate(detected_obj,1) :
print(f'■ 検出物体 {i} の中心位置 X={obj["cx"]:>3.0f}mm Y={obj["cy"]:>3.0f}mm ')
実行結果は次のようになります。

■ 検出物体 1 の中心位置 X=121mm Y= 34mm
定規を置いて、上記結果が適切であるかを確認してみます。ちゃんと求まっているようです。

追加実験
もっとたくさんの物体を置いて確認してみます。

二値化の際の「閾値の調整」が必要でしたが、うまくいきました。
検出物体1が「犬(茶色)」、検出物体2が「犬(灰色)」、検出物体3が「うさぎ」、検出物体4が「クマ」になります。

次のステップ
- 機械学習(画像分類)と組み合わせてみる(画像内の各物体を「イヌ」「ウサギ」「クマ」に分類)。
- ロボットアームと組み合わせたデモを作成してみる。
