はじめに
pandasにおいて「男/女」や「晴/曇/雨」などの文字列で表現されるカテゴリ変数(属性変数/質的変数)の列を、0-1変数で構成される複数列による情報表現(ダミー変数)に変換するためのメモです。
データ分析や機械学習をする際、よく利用されるテクニックになります(One-hotエンコーディングとも呼ばれるようです)。
pandas.get_dummies 関数を利用します。
準備
性別に関するカテゴリ変数として male(男性)、female(女性)、np.nan(欠損値)を含む列 Sex を準備します。
import numpy as np
import pandas as pd
name = pd.Series(['岡部 倫太郎','漆原 るか','椎名 まゆり','橋田 至'])
sex = pd.Series(['male',np.nan,'female','male'])
df = pd.DataFrame({ 'Name':name, 'Sex':sex})
display(df)

基本
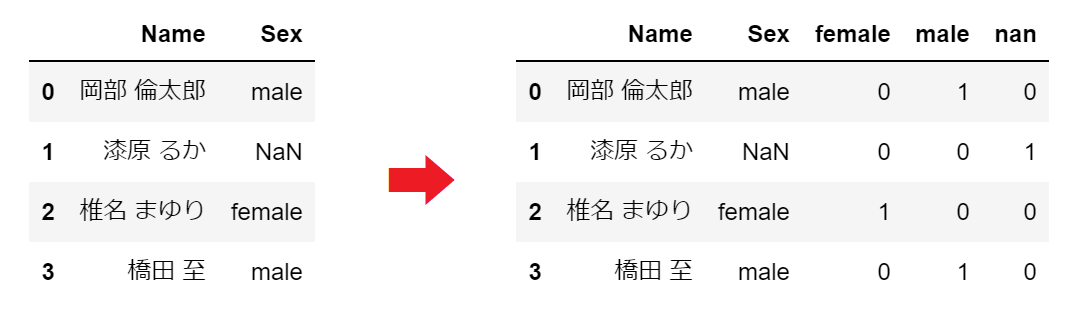
ダミー変数に変換したい列を引数として pd.get_dummies 関数を呼び出します。ダミー変数に変換されたデータフレームが戻値になります。
もともとのデータフレームに結合するためには pd.concat を使用します。
カテゴリ変数の内容が NaN の場合、female、male ともに 0 になります。
df1 = pd.get_dummies(df.Sex)
df1 = pd.concat([df, df1], axis=1)
display(df1)
欠損値についても独立したダミー変数の列を生成
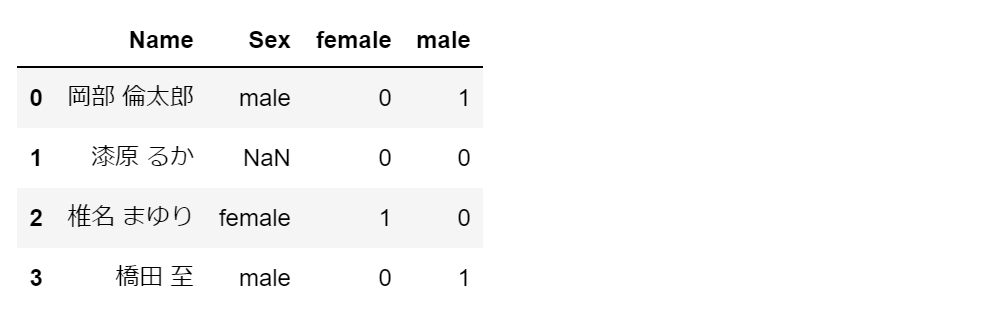
pd.get_dummies に dummy_na=True のオプションをつけると、欠損値についても独立したダミー変数の列が生成されます。
f1 = pd.get_dummies(df.Sex, dummy_na=True)
df1 = pd.concat([df, df1], axis=1)
display(df1)
生成される列のプレフィックス(接頭辞)を指定
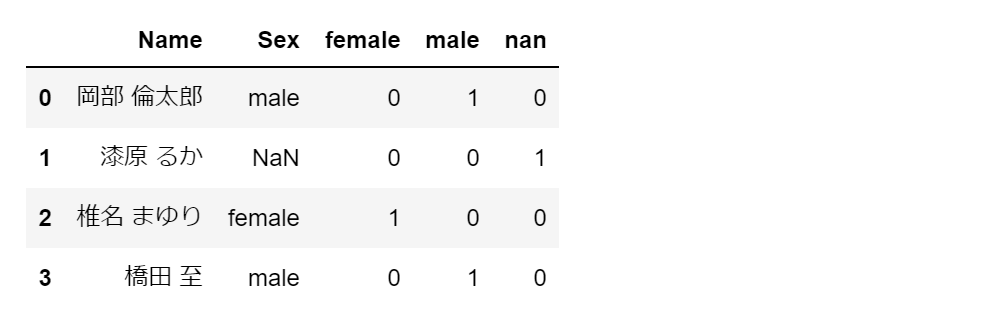
pd.get_dummies に prefix='HOGEHOGE' のオプションをつけると、生成される列名のプレフィックス(接頭辞・接頭語)を指定できます。
プレフィックス文字列につづいて、アンダーバーがつづき、カテゴリ変数が、新たに生成される列の列名になります。prefix_sep オプションを使えば、アンダーバー以外の文字列を指定可能です。
以下では、プレフィックスとして「Sex」という文字列を指定しています。
df1 = pd.get_dummies(df.Sex, dummy_na=True, prefix='Sex',drop_first=True)
df1 = pd.concat([df, df1], axis=1)
display(df1)
drop_first オプション(冗長な情報を削除)を指定
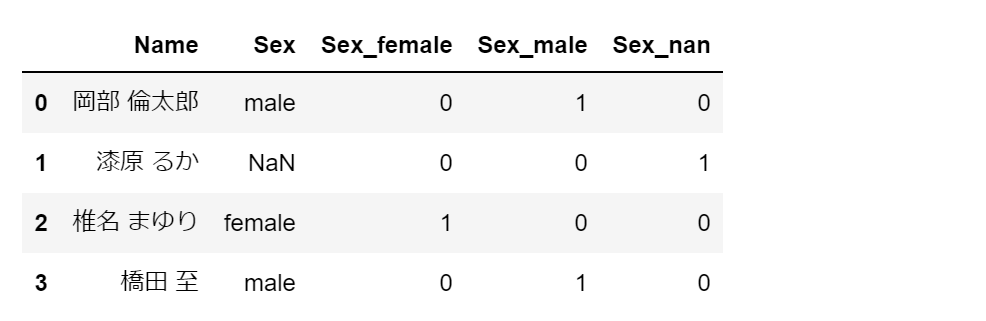
pd.get_dummies に drop_first=True のオプションをつけると、生成される列がひとつ減ります。
Sex_female という列が存在しなくても、Sex_male が 0 で、Sex_nan も 0 なら、Sex_female が 1 であることは導けるためです。言い換えれば、Sex_female は冗長な情報ともいえます。
df1 = pd.get_dummies(df.Sex, dummy_na=True, prefix='Sex',drop_first=True)
df1 = pd.concat([df, df1], axis=1)
display(df1)
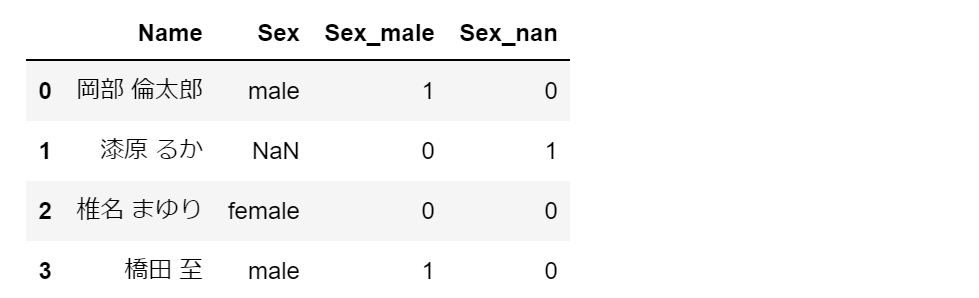
なお、次のように dummy_na=True を指定せずに、drop_first=True だけを指定すると「漆原 るか」の性別が「女性」なのか「欠損値」なのか判断できなくなってしまうので注意します。pd.get_dummies を適用する列に欠損値を含む場合は注意します。
df1 = pd.get_dummies(df.Sex, prefix='Sex',drop_first=True)

カテゴリ変数の列を削除
del df1['Sex'] のようにして、もともとのカテゴリ変数の列を削除します。
df1 = pd.get_dummies(df.Sex, dummy_na=True, prefix='Sex',drop_first=True)
df1 = pd.concat([df, df1], axis=1)
del df1['Sex']
display(df1)
