はじめに
本投稿はAWS Hands-on for Beginnersの「手を動かしながら学ぶAnalyticsサービス入門」で実施した内容のアウトプットになります。
次月から業務でRedshiftを利用するかもしれなかったので、実施してみました。
とりあえずRedshiftを触ってみたかったので、QuickSightのハンズオンは省略しています。
※ハンズオン資料が公開されたのは2021年なので古い箇所があります。
★AWS Hands-on for Beginners資料リンク
Redshiftってなに?
Redshiftとは、AWSが提供するフルマネージド型のデータウェアハウスサービスです。
RDBMSなどの行指向データベースと異なり、列指向のデータベースという特徴があります。
これは、効率的に分析や集計処理がしやすい仕組みであり、データを分析することに特化したサービスであるということがわかります。
Redshiftは「ノード」と呼ばれるコンピューティングリソースの集合で、「クラスター」というグループを構成します。
さらにクラスター内部では、リーダーノードと1つ以上のコンピューティングノードを持ちます。
リーダーノードがクライアントアプリケーションからクエリを受け取り、コンピューティングノードで処理します。
2022年には、クラスターまたはノードの概念がなく、自動的にスケーリングを行ってくれるAmazon Redshift Serverlessというサービスがリリースされています。
★参考
ざっくりの実施内容
- ハンズオンで利用するIAMロールを作成する
- Redshiftクラスターを作成する
- S3バケットを作成してデータを格納する
- RedshiftクラスターにS3のデータをロードする
- Redshiftに対してクエリを実行する
実際やったこと
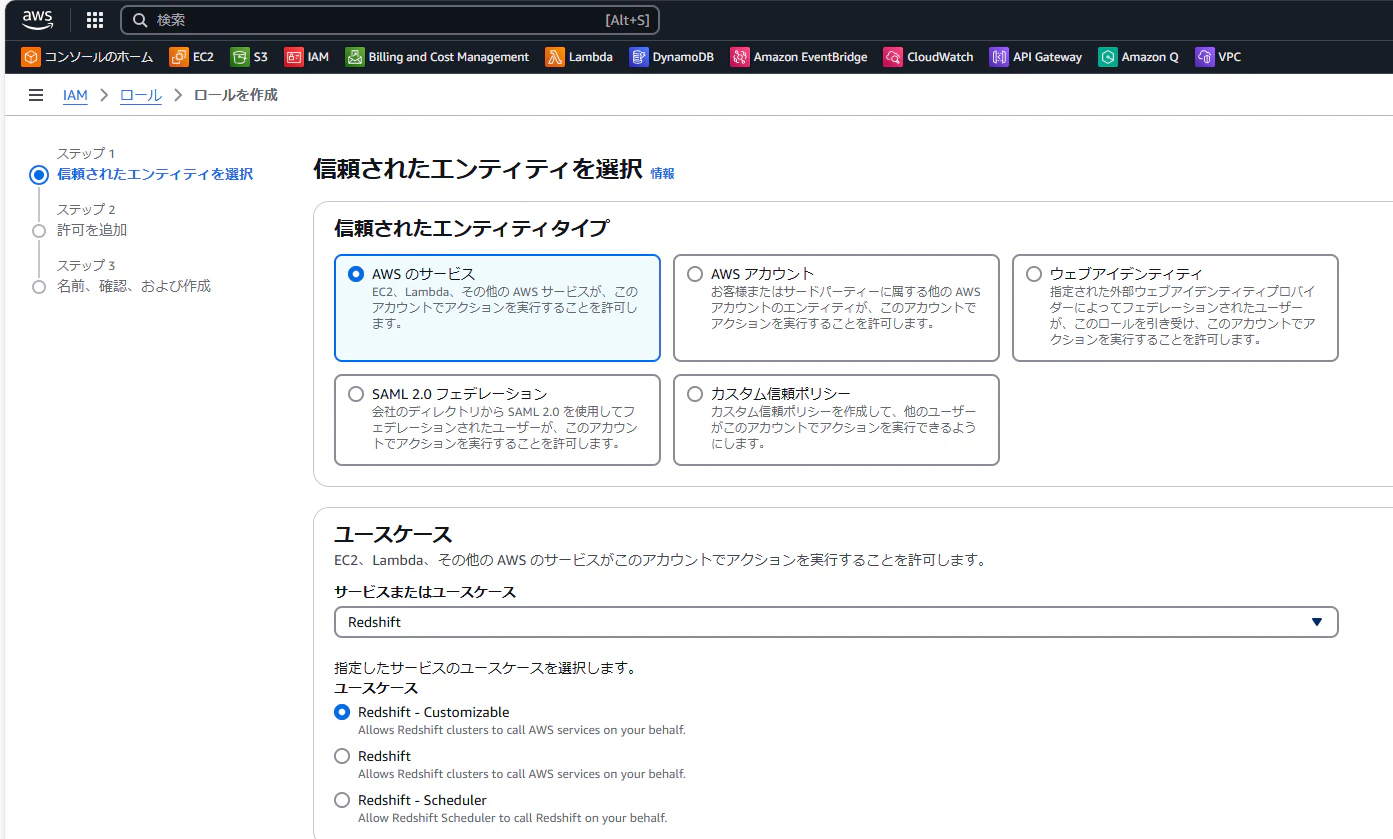
①IAMロールの作成
Redshiftクラスターにロールを関連付けることができ、ロールの権限に基づいてデータのロードやアンロードを行うことができます。
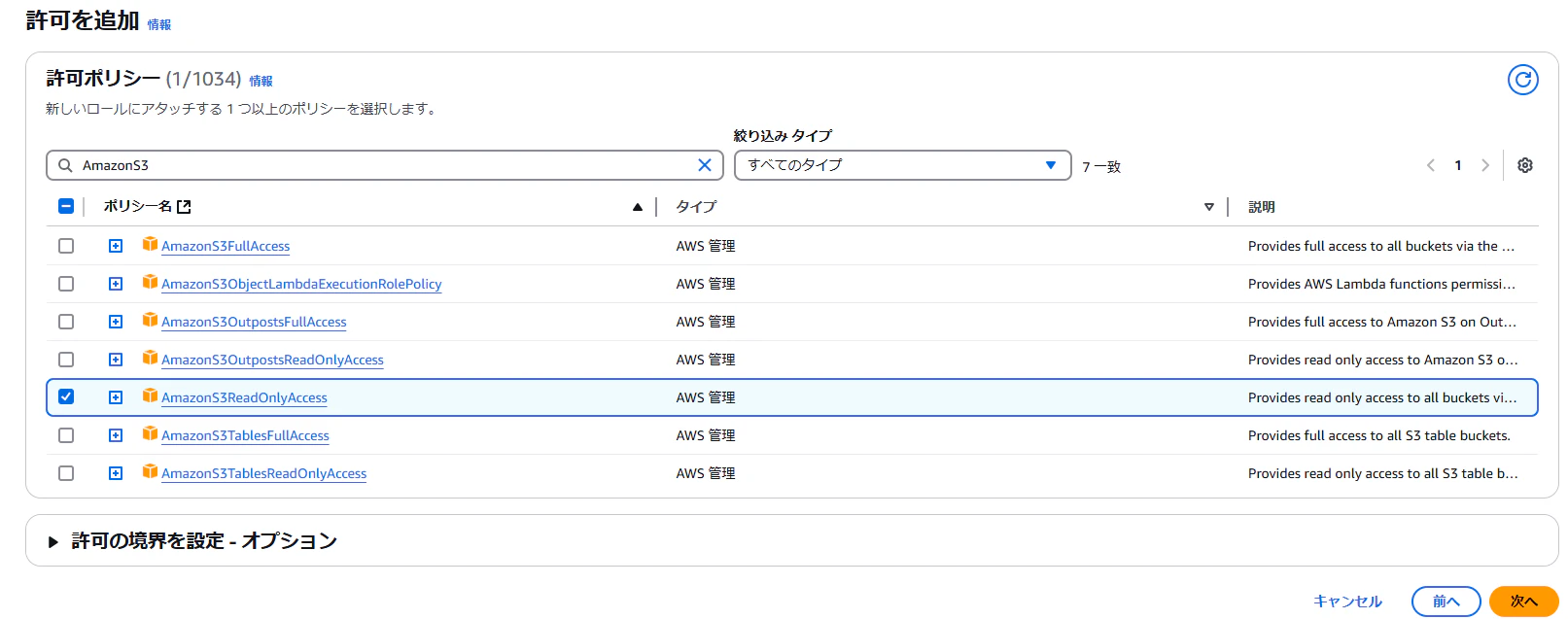
本ハンズオンでは、S3からRedshiftにデータをロードするため、S3ReadOnlyAccessの権限を持ったロールを作成します。
ユースケースからRedshiftを選択し、ポリシーを直接アタッチします。
②Redshiftクラスターの作成
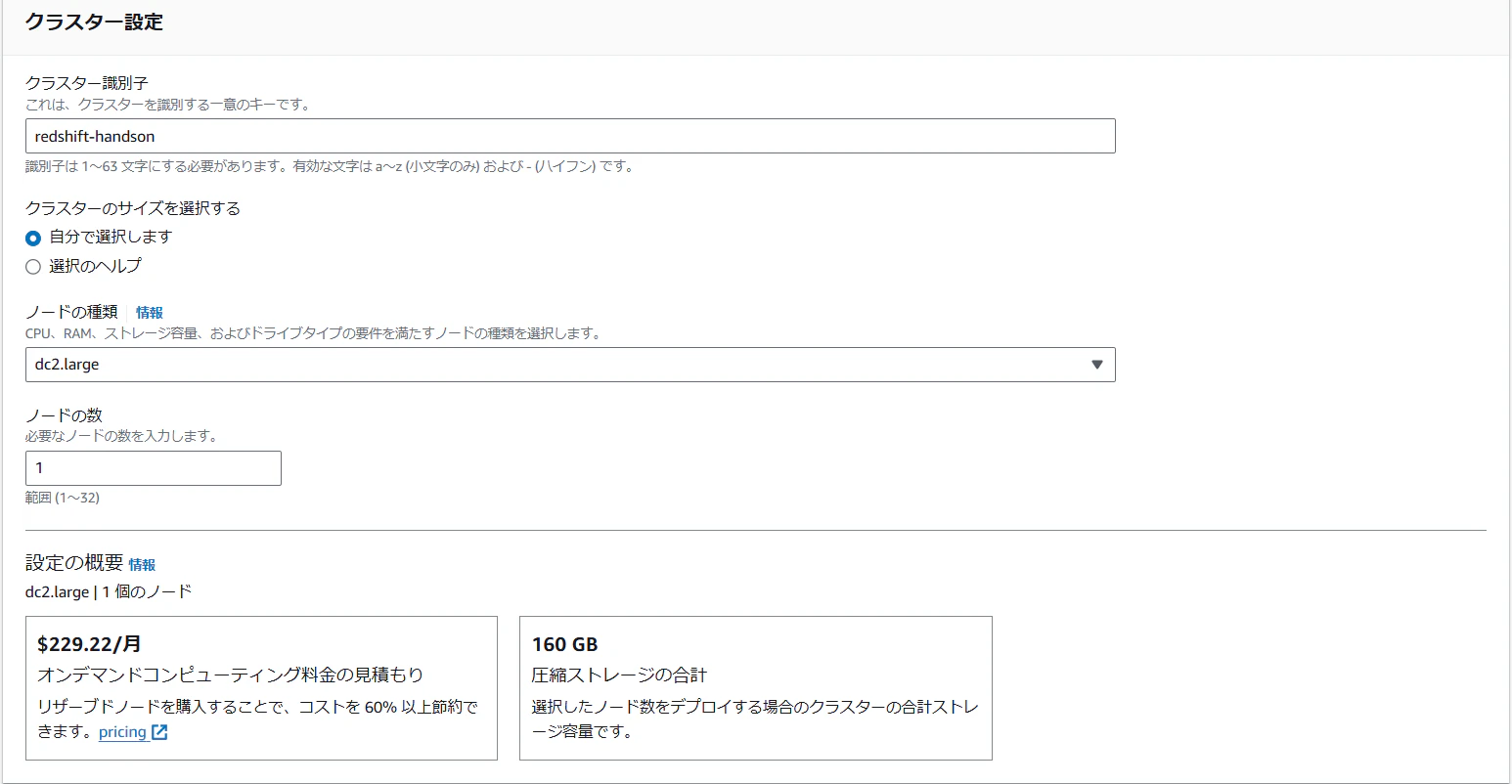
Redshiftのクラスターを作成します。
Severlessは無料トライアル枠があるので、そちらを利用したほうがいいかもしれません…。
ゴリゴリ検証するわけではないので、クラスターのサイズは一番格安のノードタイプと最小のノード数にしました。
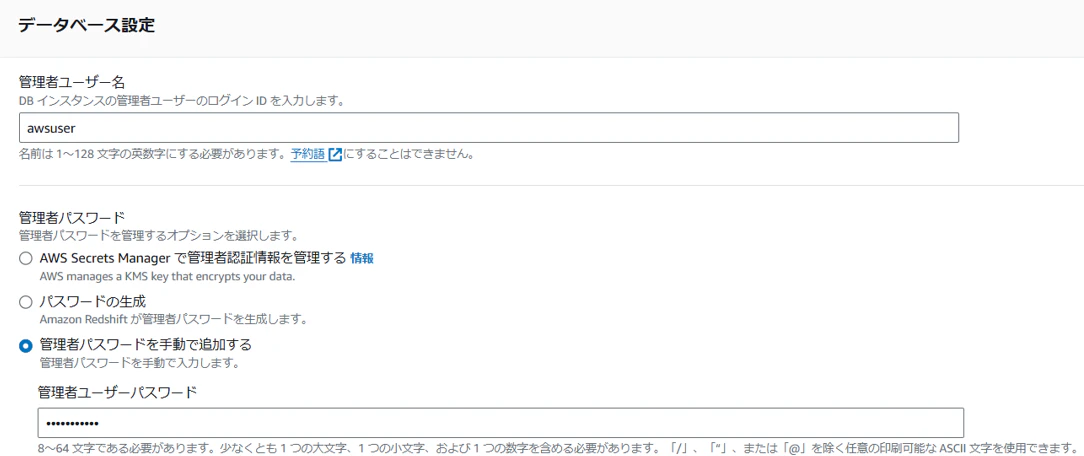
データベース設定では、接続に利用する管理ユーザとパスワードを設定します。
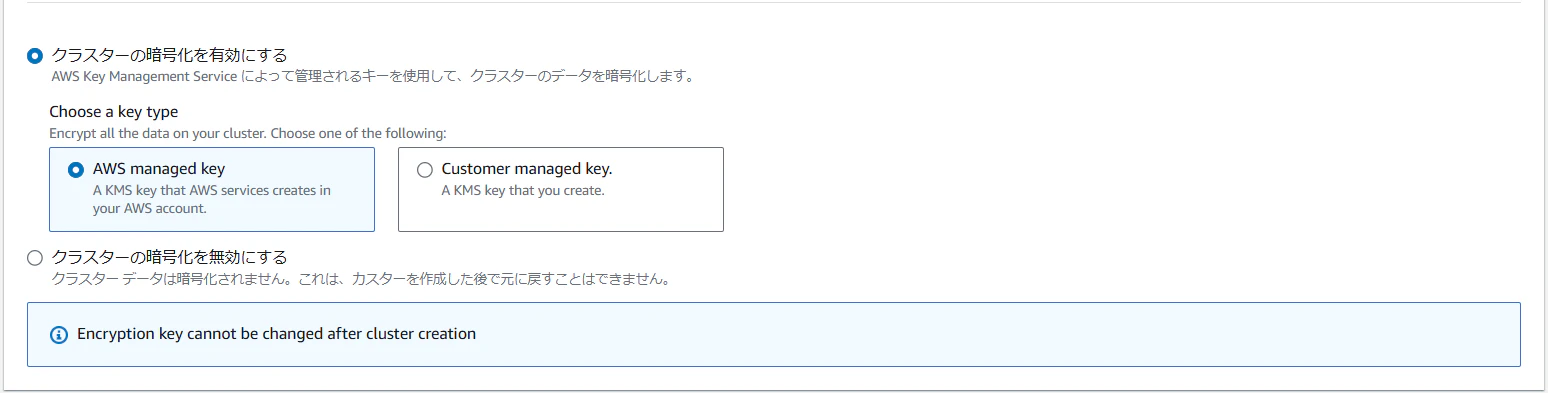
暗号化設定は、クラスターの暗号化有無を指定します。
今回は、AWS KMSのAWS管理キーを利用した暗号化を利用する設定にしておきました。
カスタマー管理キーの利用があればそちらにしてください。
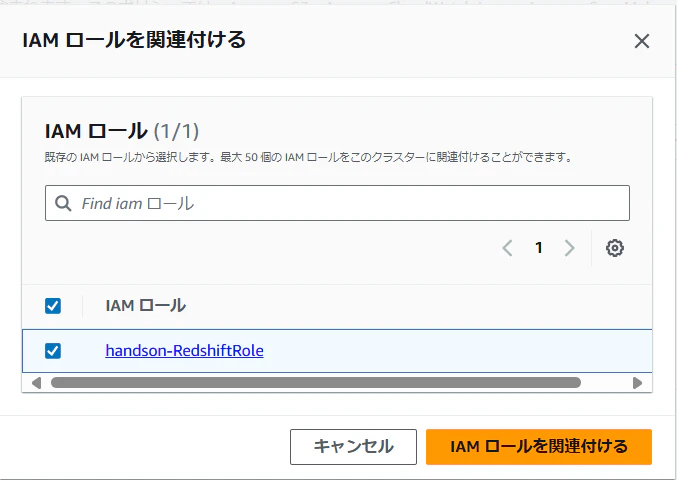
IAMロールを関連付けるという項目から先ほど作成したIAMロールを選択して関連付けます。
追加設定の箇所は、今回はそのままにします。
デフォルト以外の特定VPC/サブネットに配置する場合や、セキュリティグループを作成したい場合、バックアップの設定など、カスタマイズしたい場合は設定を行います。
「クラスターを作成」を押下してしばらくするとクラスターの状態がAvailableになって作成が完了します。

③S3バケットを作成してデータを格納する
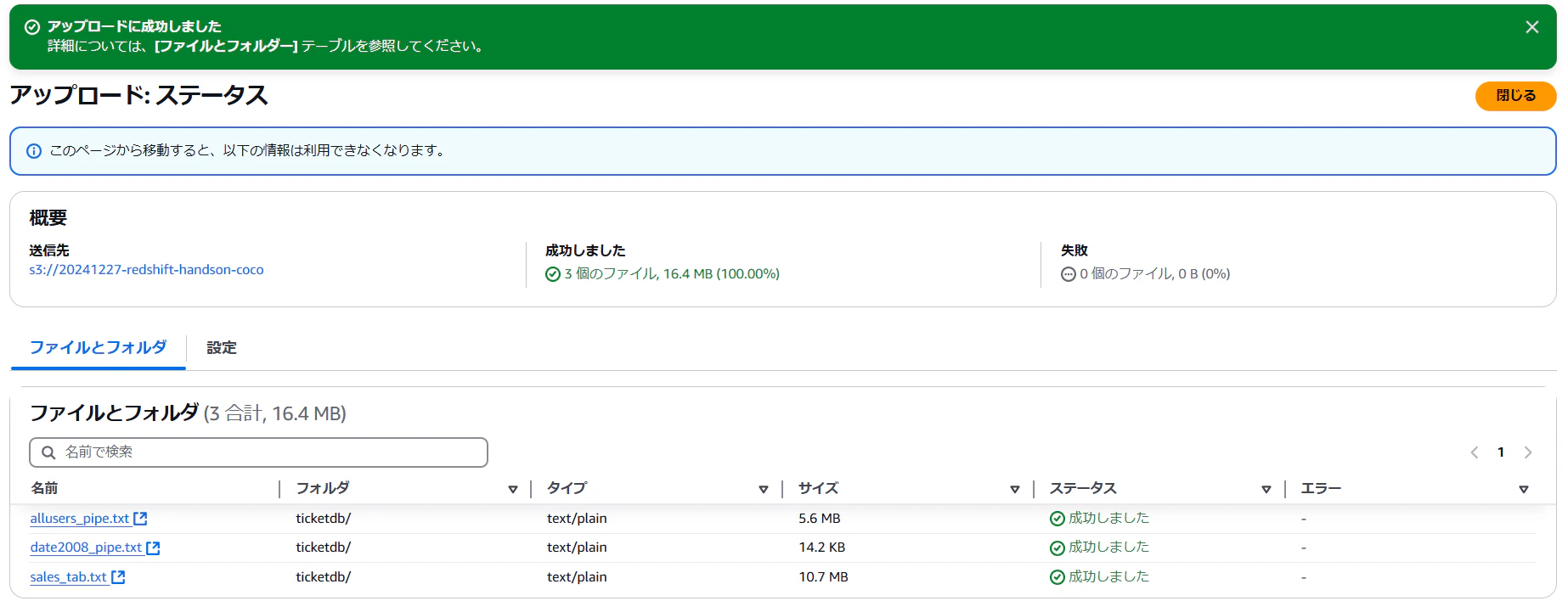
S3バケットを作成してサンプルデータをアップロードします。
バケット名はグローバルで一意の名称にする必要があるのでご注意ください。

④RedshiftクラスターにS3のデータをロードする
先ほどS3に格納したデータをRedshiftクラスターにロードします。
今回は、「Redshift query editor v2」を利用してデータのロードを行いました。
v2の利点の一つとして、複数ステートメントのクエリ実行を行えることが挙げられます。
テーブルの作成と、データのロード、ロードの確認で複数のクエリを一度に実行したかったのでv2側を利用しました。
開くとこんな画面になります。
左側のペインには作成したRedshiftのクラスターが表示されているため、選択して接続します。
今回は、ユーザ名とパスワードを使って接続します。
ここで利用するユーザ名とパスワードはRedshiftクラスター作成時に指定したものです。
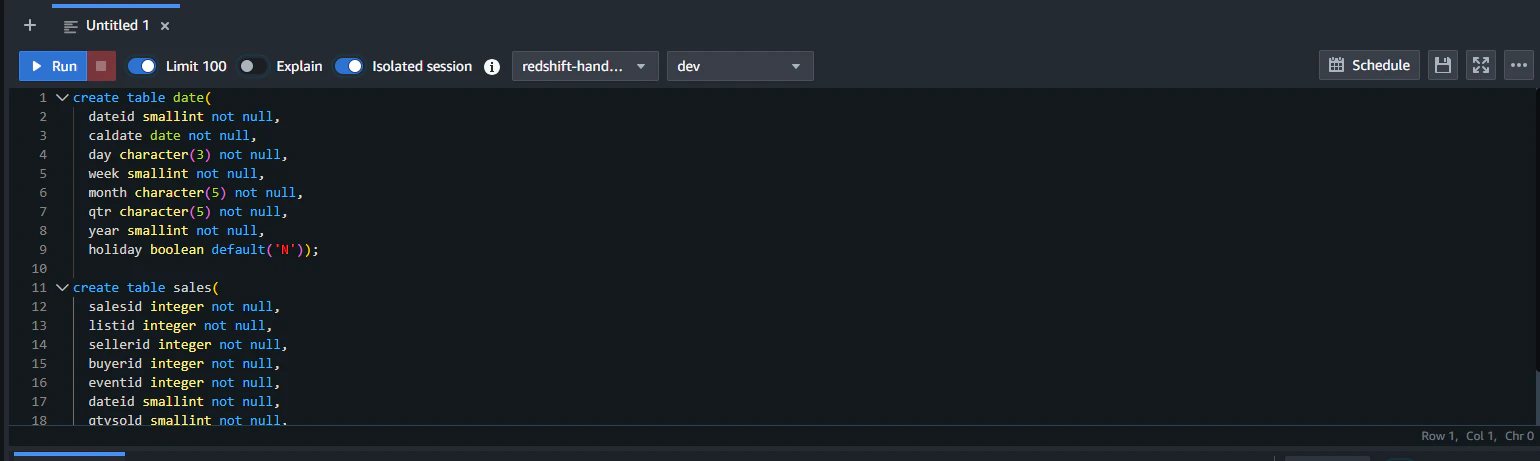
接続ができたら、データをロードする前にテーブルの作成を行います。
こんな感じで複数クエリを実行します。
結果は、クエリごとにタブが分かれて表示されます。
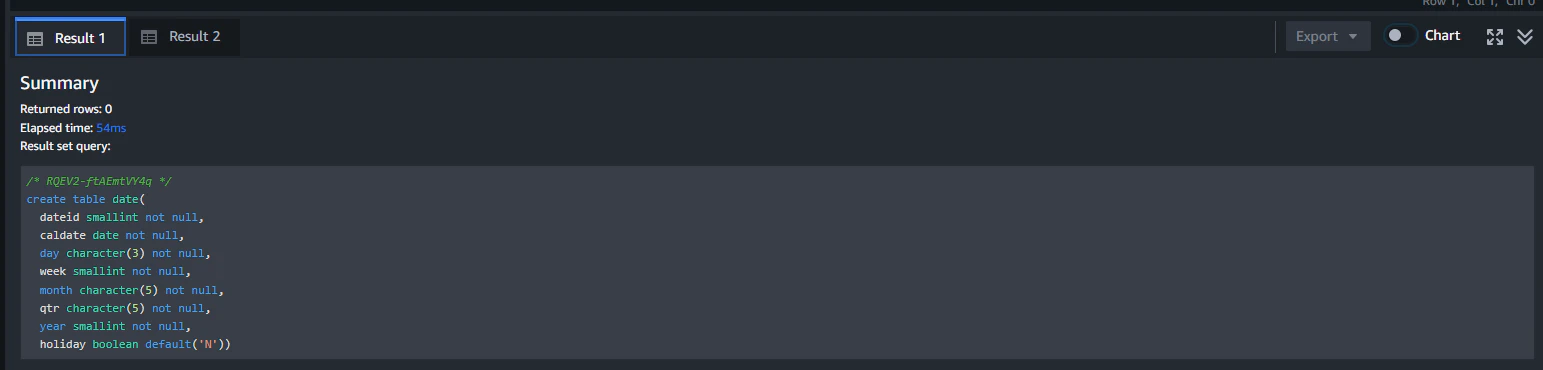
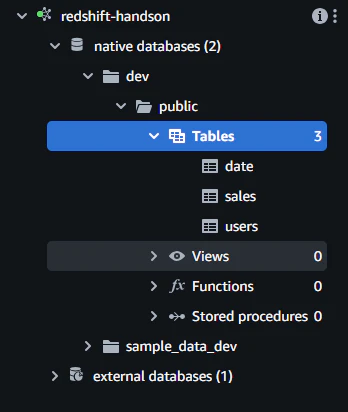
左側のペインのRedshiftクラスター名を開いていくと作成したテーブルが表示されていることがわかります。
特段指定がないとテーブルはpublicというデフォルトスキーマに作成されます。
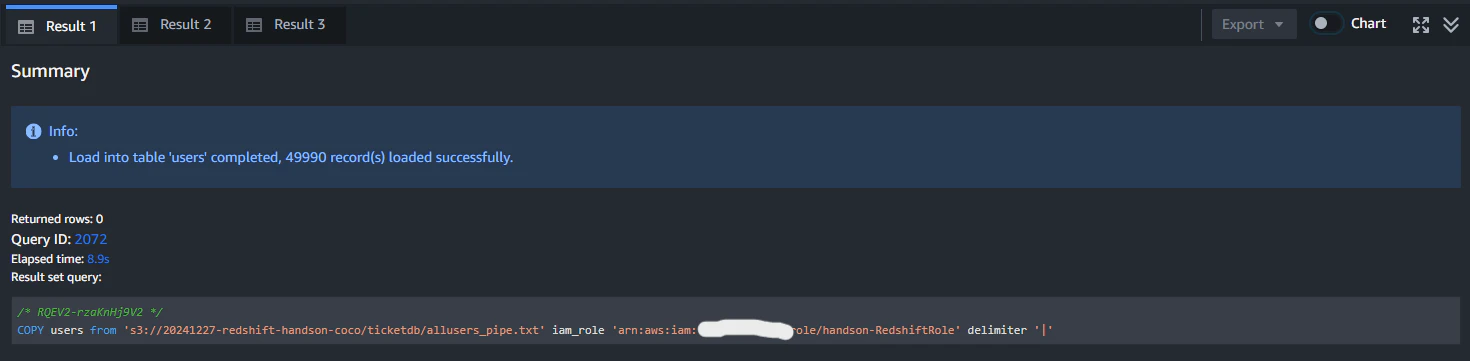
テーブルの作成が完了したらS3のデータをRedshiftクラスターにロードします。
ここでは先ほど作成したS3ReadOnlyAccessのポリシーをアタッチしたIAMロールのARNを指定してください。

しばらくするとロードが完了します。
★[参考]COPY構文
★[参考]データのロードにおけるベストプラクティス
⑤Redshiftに対してクエリを実行する
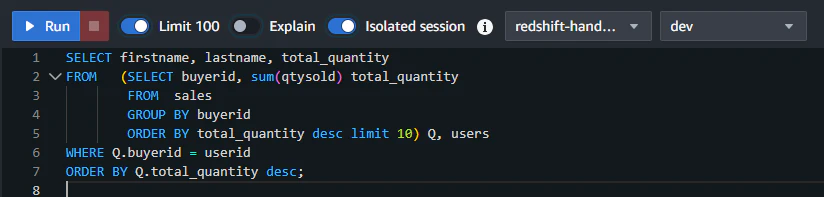
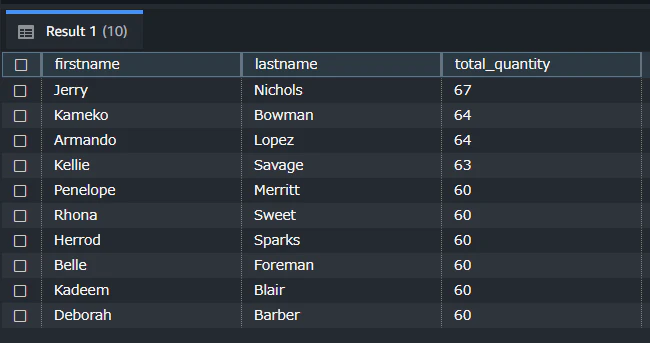
データがロードできたので、クエリを実行してみます。
無事、サンプルデータをもとにデータが集計できました。
おわりに
今回はクラスターの作成からクエリエディタを利用してデータのロードとクエリの実行を行うことができました。
クラスターやノードの概念があるプロビジョニングタイプの利用だったのですが、その概念がないServerlessも試してみたいなと思いました。
Glueを使ってETLの部分も今後チャレンジしてみたいと思います。