コロナウイルスの一年となった2020年に、私たちは音楽に何を求めたかを知るためにSpotify APIを使って2020年最も聴かれた曲50から特徴を見てみました。
私は邦楽はあまり聴かないのですが、聴く方にはこの曲を聴いたときはこう思ったなぁなどがあるかも知れないのでプレイリストと照らし合わせて自分は音楽に何を求めていたか考えながら読んでみてください。
出力結果からは曲毎の特徴ではなく全体の特徴を見ていきます。ちょっと気になっただけなので深く分析や説明はしません。先に結果から、技術的な事は簡単なので後半に置いておきます。
結果
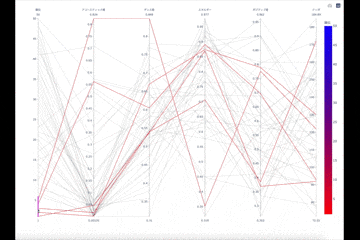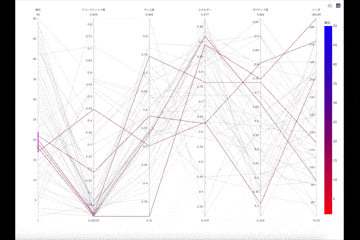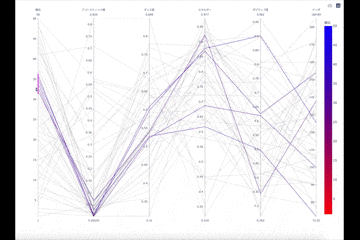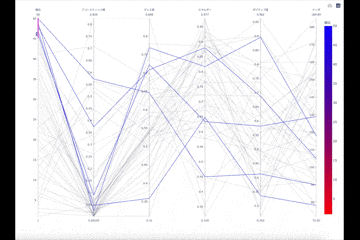
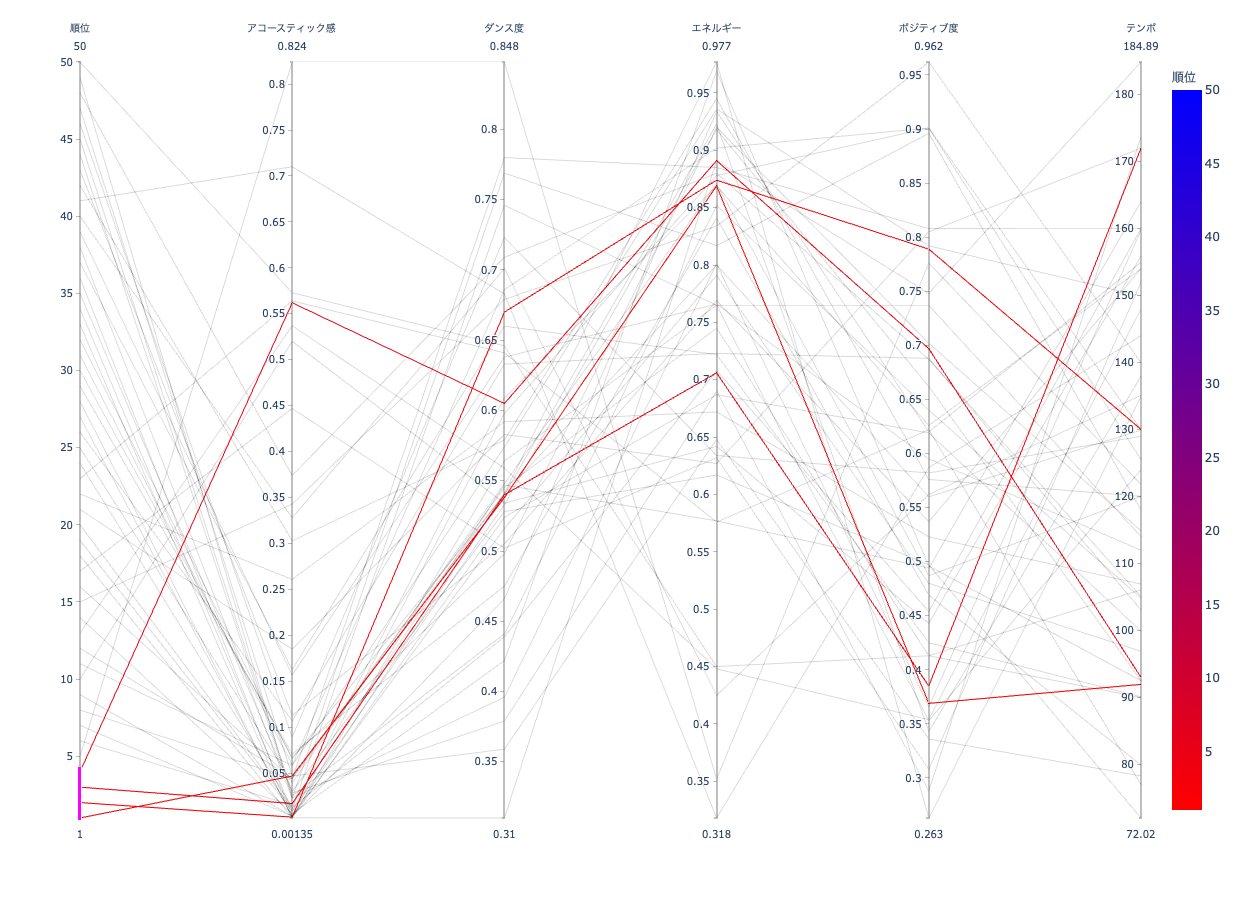
順位、アコースティック、ダンス、エネルギー、ポジティブ、テンポの特徴を軸にグラフ化しています。
順位とテンポ以外は0.0~1.0で1.0に近ければその特徴が「強い」となります。
それぞれの結果から簡単に考察する形で見ていきます。勝手な憶測でしかないので鵜呑みにしないでください。
全体図
2020年に最も聴かれた曲の特徴をざっくりみると、電子楽器を多く使ったエネルギッシュな曲が多く聴かれていたようです。しかし、エネルギッシュであるのに曲調はポジティブには寄らずテンポが高い訳でもありません。これは、音だけで元気になるような曲ではなく、歌詞を主体として曲はそれを支えるような曲が多く聴かれていたのではないかと思います。コロナ禍では、楽しい気持ちをさらに楽しくする「音」ではなく、ネガティブな気持ちに寄り添う「言葉」が音楽に求められたのかも知れません。
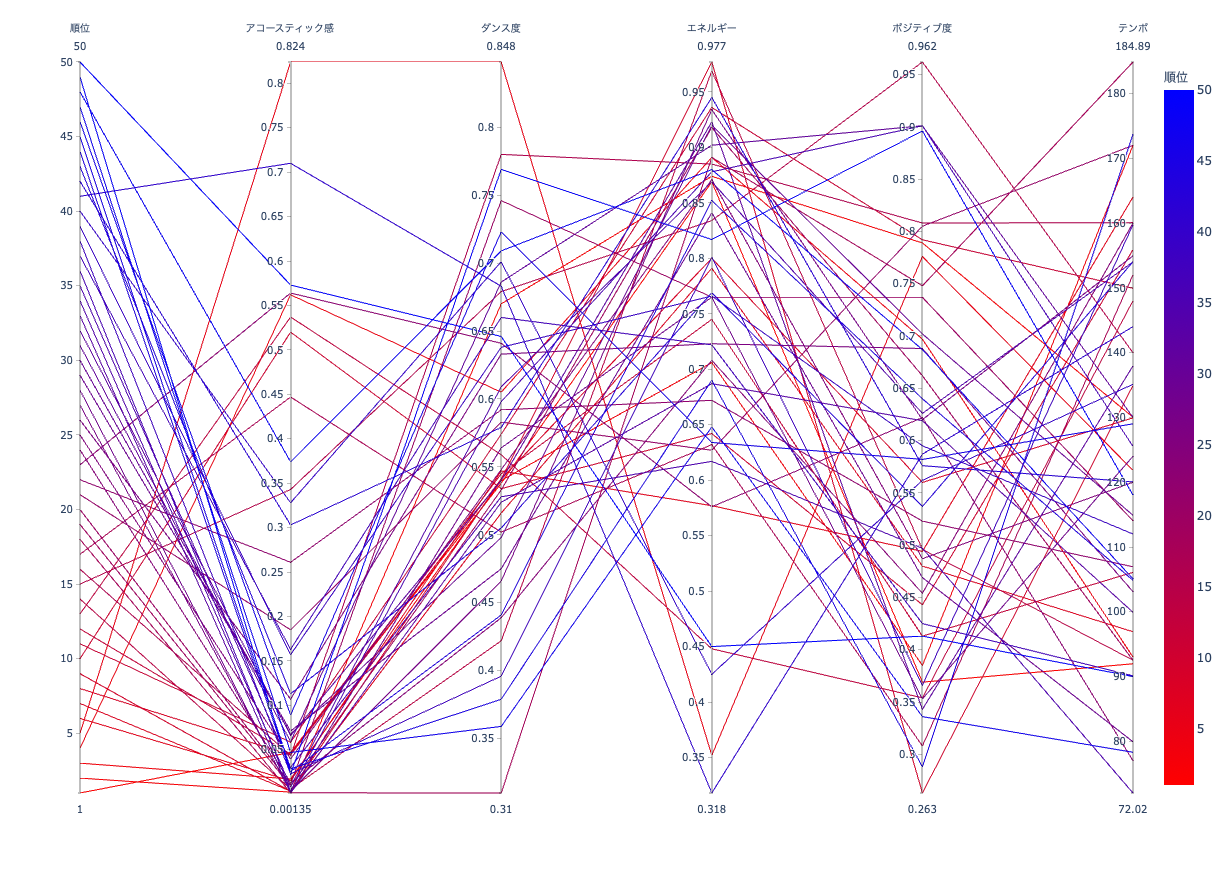
下位
全体図から受けられた特徴の偏りは、26位以下の曲によって構成されていたようです。アコースティック感が高いものが多少は見受けられるものの大半は低い方に偏っています。しかし、その他の特徴はバランスよく持っていて、いずれかの特徴が強い曲は少ないようにも見えます。曲に求める特徴をバランスよく持っているので、聴く人を選ばないと説明できれば順位に入ったのも納得がいきます。
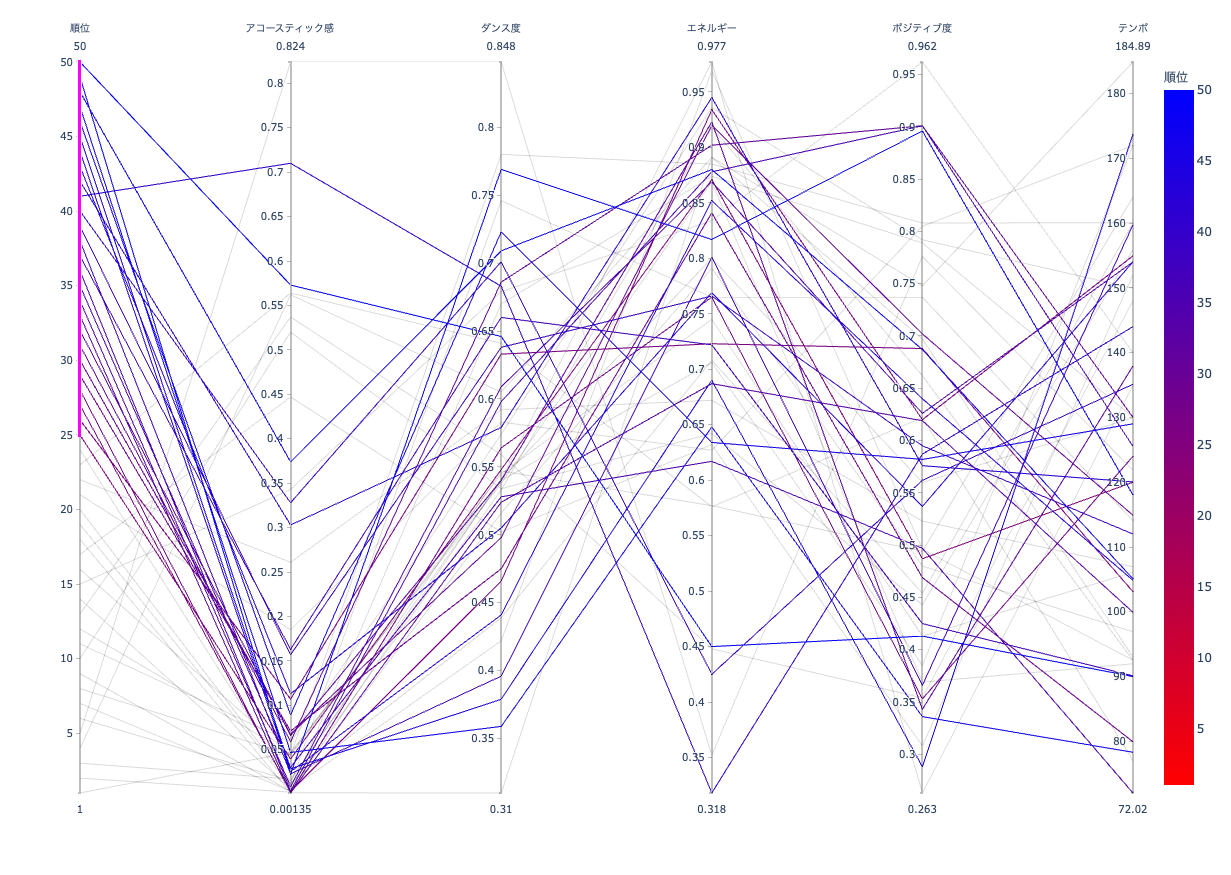
上位
上位では下位に比べ、特徴に対して極端な数値のものが多いように見えます。しかし、ダンス度は0か1に偏るのではなく0.55に集まっています。初見で聴いて、「これいい!」と思う特徴はダンス度にあるのかも知れないですね。また、ポジティブ度は比較的低めに寄っているようですが、これは曲調と自分のメンタルを合わせているのでしょうか。
一点、上位ではアコースティック感を持つ曲が下位に比べ多くあることが気になります。
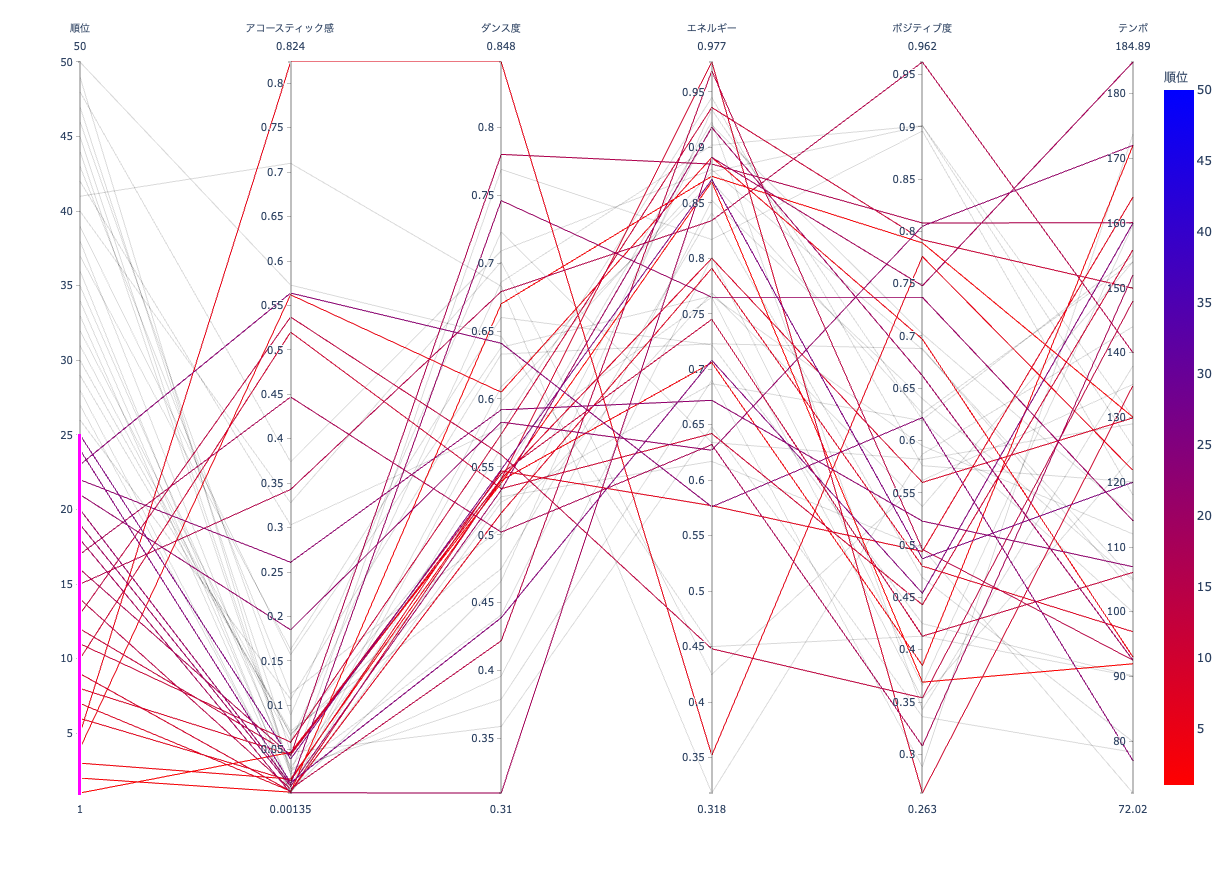
アコースティック感が強い15位~
アコースティック感を強く持つ曲は15位以上に入っているようです。ダンス度,エネルギー,ポジティブ度は上位で見られた傾向と似ているのでそこにアコースティック感が強くあるものでも順位にはさほど影響しないのかも知れません。最近の曲はどれも電子楽器が使われてますし聴かれる曲にアコースティック感がない方に偏るのは理解できます。だからと言ってギター持ったシンガーソングライターの曲が人気になることもあるのでアコースティック感が順位に強い関係を持たない事はなんとなくイメージがつきます。
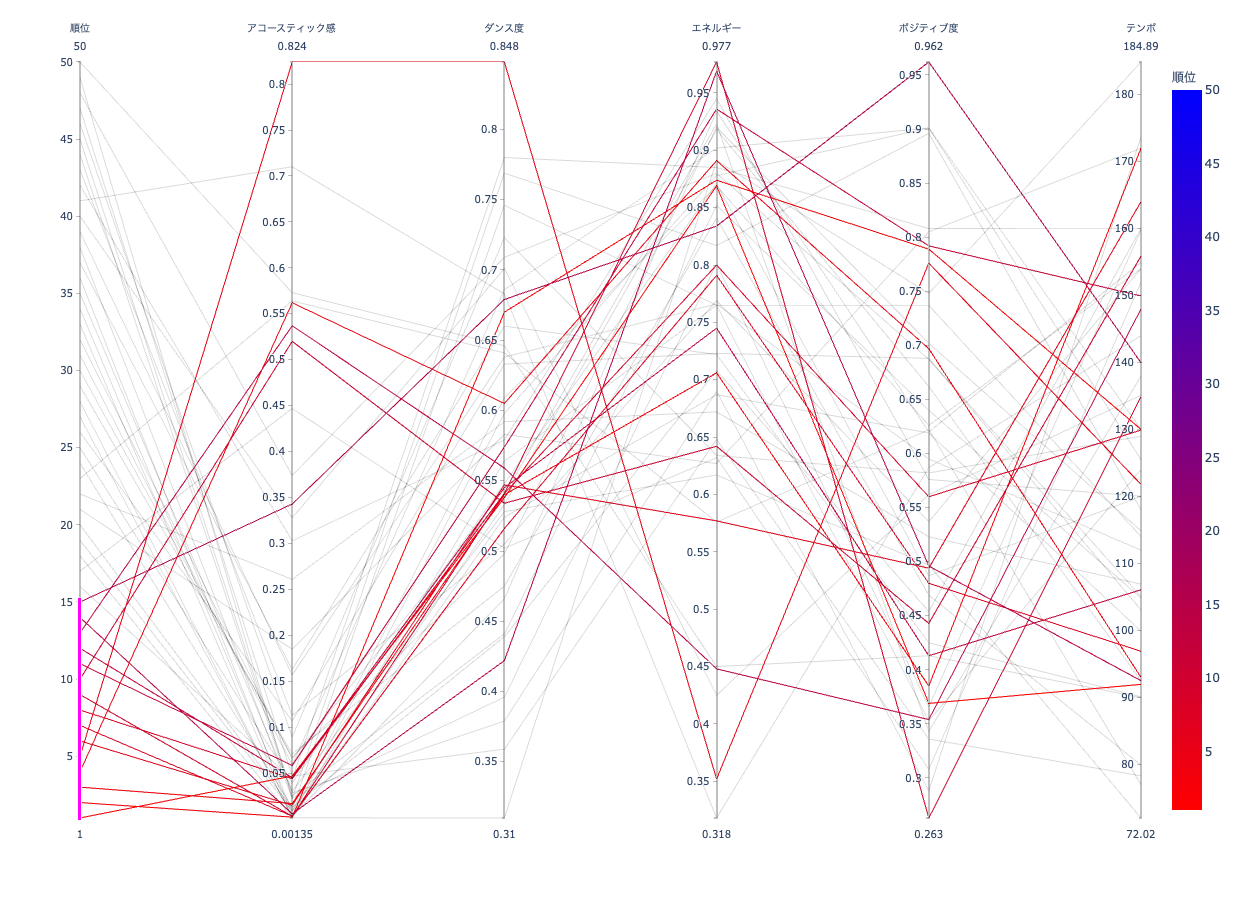
しかし!!
5位に圧倒的なアコースティック感とダンス度!そしてほぼエネルギーを持たない無気力さ!
プレイリストをみると曲名には「香水/瑛人」。
なるほどね!あんまり聴いた事ないけど無気力にギター弾いて歌ってるところ見たことあるなぁ!確かにネガティブな感じだった気がする!うん!思わず踊り出したくなっちゃうよね!
ならねぇよ()香水で踊ってる人見たことねぇよ...
ネタみたいな曲だなぁ。というよりネタにされてる曲だなと思っていましたが最も聴かれた曲5位に入るほどだとは思っていませんでした。流行りの曲調や歌詞をガン無視して面白がられる曲を作って売れたというのは純粋に凄いなとは思います。でも別に君を求めてないですけどね()
Best4
上位4位の曲は以下です。
- Pretender - Official髭男dism
- 夜に駆ける - YOASOBI
- I LOVE... - Official髭男dism
- 白日 - King Gnu
- (5位の香水は数値がイレギュラーで見難いので省きましたすいません瑛人さん)
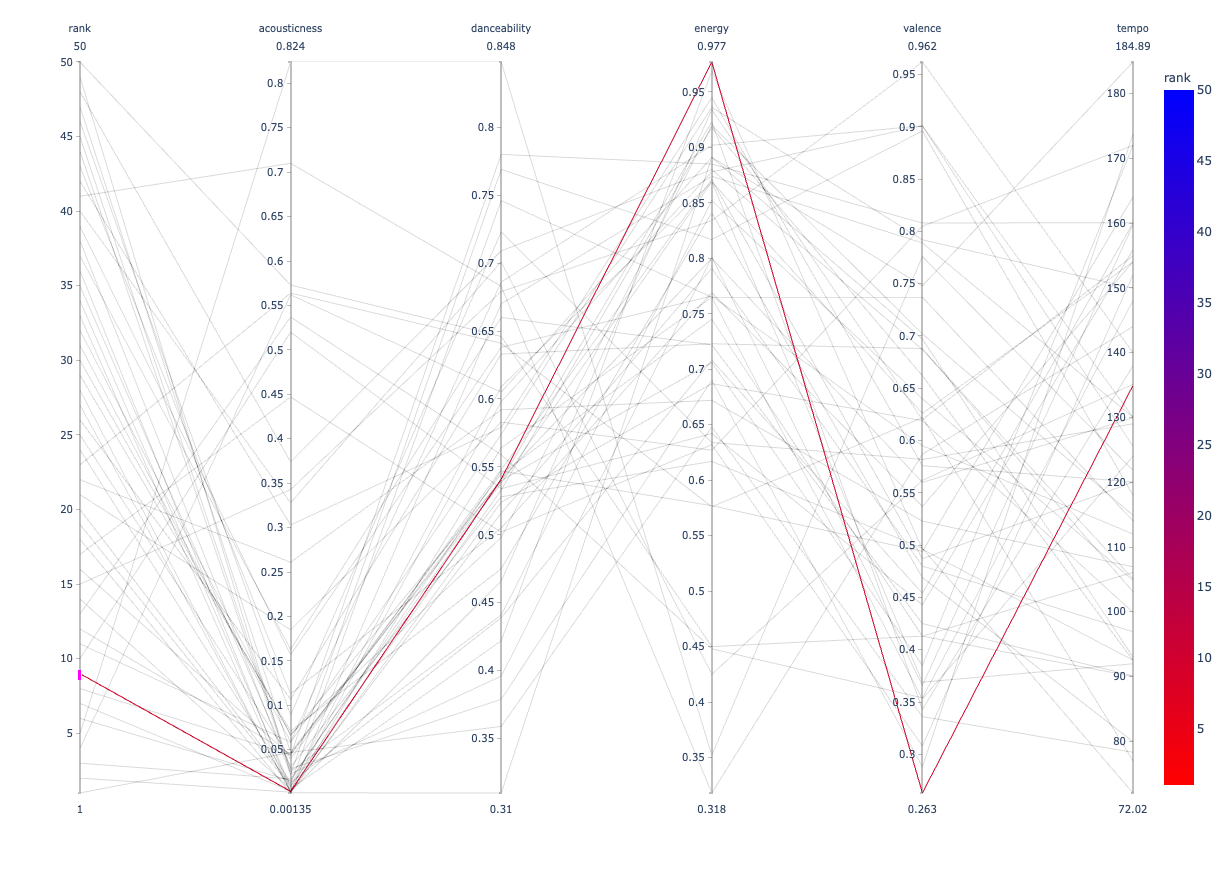
髭男はPretenderで圧倒的人気を誇っていました。I LOVE...や白日はドラマで起用されたこともあり、ランキングに入ったのではないでしょうか。売れたドラマの主題歌というのは影響力が大きいのでしょうか、それとも曲が良かったからドラマが売れたのかはわかりませんが曲の良さ、ドラマの良さ、毎週聴かされることの3点がお互いに影響しているのはありそうですね。その中でもドラマに起用されることなくデビューで売れた上位2曲はすごいなと思います(小並感)。
香水を含めたBest5は、全体の傾向に似たものはあるとはいえ完全にそぐう特徴ではないことがわかります。今までの考察を裏切る特徴が出て面白いですね。しかし、Pretenderがダンス度の偏っている部分の中央にいるのでダンス度が人気の何かを担っているとは考えられるのかなと思います。アコースティック感は人気に問われる事はないのはなんとなくわかりますが、エネルギーとポジティブ度の相関性は強く無いように思えてきました。
余談
紅蓮華は9位でした。
超電子音!人気の数値ダンス度0.55!超エネルギッシュ!超ネガティブ!テンポど真ん中!って感じでした。
技術的な
プレイリストの曲の特徴をまとめたcsvは、こちらからダウンロードできます。
APIの取得方法などは説明しません。
環境
Python 3.7.6
pipenv 2018.11.26
spotipy 2.16.1
pandas 0.24.2
plotly 4.14.3
コード
from module import config
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import pandas as pd
import plotly.express as px
class Spotify:
def __init__(self):
self.sp = spotipy.Spotify(auth_manager=SpotifyClientCredentials(client_id=config.ClientID,
client_secret=config.ClientSecret))
def get_playlist(self, ID):
playlist = self.sp.playlist(ID)
return playlist
def get_song_ids(self, playlist):
return [song_id['track']['id'] for song_id in playlist['tracks']['items']]
def get_playlist_info(self, IDs):
data = list()
trucks_info = self.sp.tracks(IDs)['tracks']
for i, id in enumerate(IDs):
features = self.sp.audio_features(id)[0]
rank = i + 1
artist = trucks_info[i]['artists'][0]['name']
album = trucks_info[i]['album']['name']
name = trucks_info[i]['name']
length = trucks_info[i]['duration_ms']
popularity = trucks_info[i]['popularity']
acousticness = features['acousticness']
danceability = features['danceability']
energy = features['energy']
instrumentalness = features['instrumentalness']
key = features['key']
liveness = features['liveness']
loudness = features['loudness']
mode = features['mode']
speechiness = features['speechiness']
tempo = features['tempo']
time_signature = features['time_signature']
valence = features['valence']
data.append([rank, artist, album, name, length, popularity, acousticness, danceability, energy,
instrumentalness, key, liveness, loudness, mode, speechiness, tempo, time_signature, valence])
return data
def get_df(self, two_dimensional_array):
dataframe = pd.DataFrame(two_dimensional_array,
columns=['rank', 'artist', 'album', 'name', 'length', 'popularity', 'acousticness',
'danceability', 'energy', 'instrumentalness', 'key', 'liveness', 'loudness',
'mode', 'speechiness', 'tempo', 'time_signature', 'valence'])
return dataframe
def draw(self, dataframe):
fig = px.parallel_coordinates(dataframe,
dimensions=['rank', 'acousticness', 'danceability', 'energy', 'valence', 'tempo'],
labels={'rank': '順位',
'acousticness': 'アコースティック感',
'danceability': 'ダンス度',
'energy': 'エネルギー',
'valence': 'ポジティブ度',
'tempo': 'テンポ'},
color='rank',
range_color=[1, 50],
color_continuous_scale='Bluered_r',
color_continuous_midpoint=2)
fig.show()
if __name__ == '__main__':
spotify = Spotify()
playlist = spotify.get_playlist('37i9dQZF1DWYYQb2mqFd5I')
IDs = spotify.get_song_ids(playlist)
data = spotify.get_playlist_info(IDs)
df = spotify.get_df(data)
spotify.draw(df)
spotify APIでプレイリストに入っている曲を取得して、曲毎に特徴を取得して、forで回してデータフレーム作って、plotlyでグラフにしただけです。走り書きなので雑で汎用性低いです。ほぼ一年ぶりにコードを書いたので許してください()
あとがき
技術は目的のためにあるので目的にフォーカスした記事を書きますが、そうすると技術記事にはそぐわないように見えてしまいます。ですが、技術はやはり目的のためにあるので...の堂々巡りで結果とコードどっちを先頭に描くか迷いましたがタイトル的に結果が先に来る方が自然だと思ったのでコードは後にさせていただきました。
私はどんなに難しいコードが書けるようになっても技術内容メインではなく、コードを書けない人がこの記事を読んだとき、こんなこともできるだ!面白そう!と思える記事が書きたいです。(技術的なことも書かないと消されるのでもちろん書きますが)
読んでいただきありがとうございました。