はじめに
スマブラー(本業はシステムエンジニア)がスマブラの動画からキャラクターが受けたダメージを認識させ、それをグラフに描画するものを作りました。スマブラのレート対戦ではVIP(上位3%)ですが、システムエンジニアとしては逆VIP(下位3%)です。(特に機械学習は最近勉強し始めました)
短くまとめるのが難しそうなので、前編、後編(もしかしたら中編も)で分けました。
前編ではTesseract OCRを使ったキャラクター名とダメージの認識の実装について
後編ではOpenCVを使ったダメージ(数字)の輪郭抽出と、機械学習を使ったダメージ認識の実装について書く予定です。
Qiita初投稿なので、至らない点があると思います。
なにかありましたらコメントをお願いします(厳しいご指摘もお待ちしてます!!:D)
作ったもの
下記のような画面(動画ファイル)の下部に表示されているダメージを認識させてグラフに描画させました。
Input
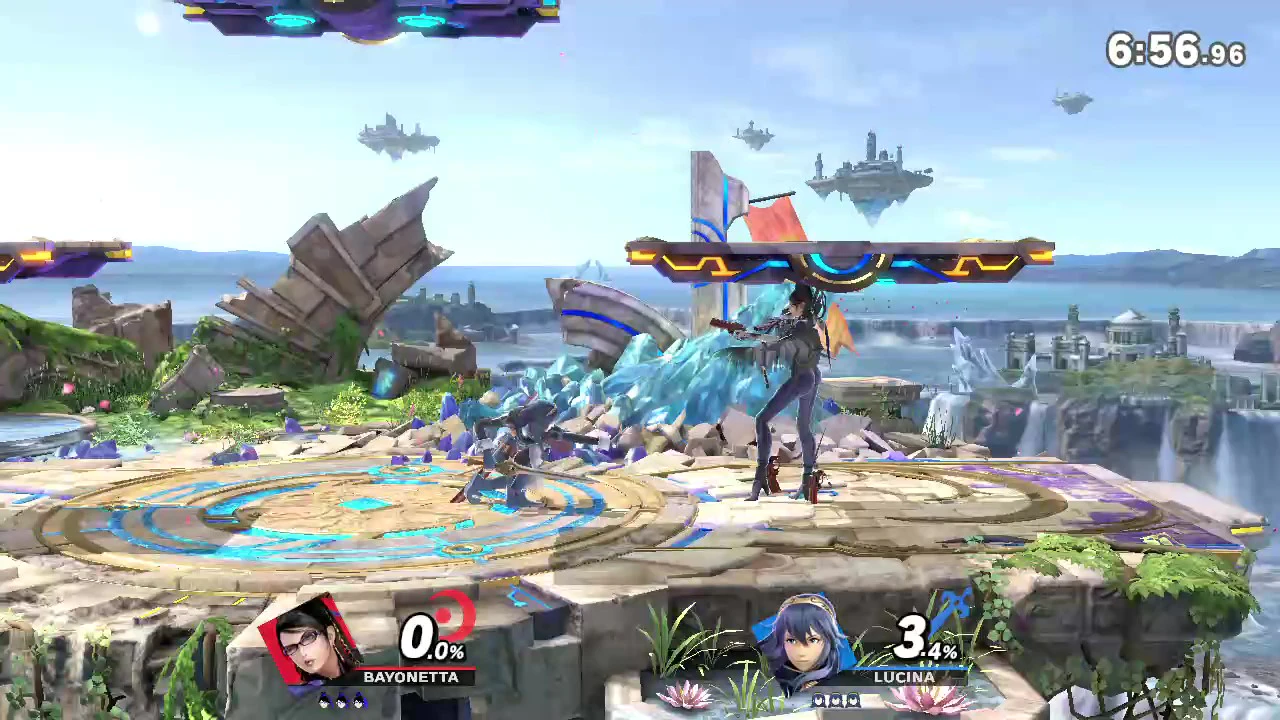
Output

開発環境
OS :Windows10 Home 64 bit
言語 :Python 3.7.4
エディタ :Atom 1.40.0
ソース管理:Github
実装
車輪の再発明はするな by えらいひと
という有り難いお言葉をどこかでQiitaことがあるので、まずはオープンソースで画像から文字を認識してくれるものを探してみて、一番最初に見つけた、『Tesseract OCR』というものを使ってみました。
tesseract
私はWindowsを使用しているので、下記の記事を参考にインストールしました。
Tesseract OCRの始め方
pyocr
Tesseract OCR自体は、画像を入力として与えると文字列を返してくれるツール(OCR)のようで、そのままではPython上では動かせません。
そのため、OCRをpython上で動かすためのpyocrをインストールします。
インストールは簡単で、下記のようにpipコマンドを打つだけです。
pip install pyocr
インストールが終わったら実際にpython上で動かしてみます。
※私の環境では環境変数をいじらないと上手くpyocrがTesseractを認識してくれなかったので、下記の記事を参考に環境変数を追加しました。
tesseractでOCR@Windows7
キャラクター名(アルファベット)の認識
import pyocr
import cv2
import os
import sys
from PIL import Image
# read OCR tools
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# select pyocr.tesseract
tool = tools[0]
# input image file
root_dir = os.path.split(__file__)[0]
image_luci = os.path.join(root_dir, 'data/lucina.png')
image_bayo = os.path.join(root_dir, 'data/bayonetta.png')
image = cv2.imread(image_luci, 0)
lucina = tool.image_to_string(
Image.fromarray(image),
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
image = cv2.imread(image_bayo, 0)
bayonetta = tool.image_to_string(
Image.fromarray(image),
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
# output
print('期待値:BAYONETTA 実行結果:{}'.format(bayonetta))
print('期待値:LUCINA 実行結果:{}'.format(lucina))
Input


Output
期待値:BAYONETTA 実行結果:BAYONETTA
期待値:LUCINA 実行結果:LUCINA
[Finished in 0.714s]
キャラクター名を認識するには実用できそうです。
では肝心なダメージの認識はどうでしょうか。
ダメージ(数値)の認識
import pyocr
import cv2
import os
import sys
from PIL import Image
# read OCR tools
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# select pyocr.tesseract
tool = tools[0]
# read image file
root_dir = os.path.split(__file__)[0]
image_135_5 = os.path.join(root_dir, 'data/135_5.png')
image_6 = os.path.join(root_dir, 'data/6.png')
image = cv2.imread(image_135_5, 0)
damage_135_5 = tool.image_to_string(
Image.fromarray(image),
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
image = cv2.imread(image_6, 0)
damage_6 = tool.image_to_string(
Image.fromarray(image),
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
# output
print('期待値:135.5 実行結果:{}'.format(damage_135_5))
print('期待値:135.5 実行結果:{}'.format(damage_6))
Input


Output
期待値:135.5 実行結果:
期待値:6 実行結果:GB
[Finished in 0.712s]
結論
キャラクター名の認識では、背景がグレーになっているため、Tesseractが有用でしたが
ダメージの認識では背景がゲームのバックグラウンドの影響をかなり受けるため、難しそうです。
詳しい内容は次回の記事で書きますが、まずは背景の情報量を落とす必要がありそうです。
(いろいろ試した結果、機械学習させました...)