1.DASH/コールバック概要
コールバックはレイアウトで指定したIDを指定してコールバック処理に紐づけを行います。プログラムで同じ出力処理を複数回上書で処理することがあると思いますが、DASH上では悲しいことに同一コンポーネントへの出力は一回までとなっており、重複すると全てのコールバックが停止します。以下レイアウトとコールバックの関係です。
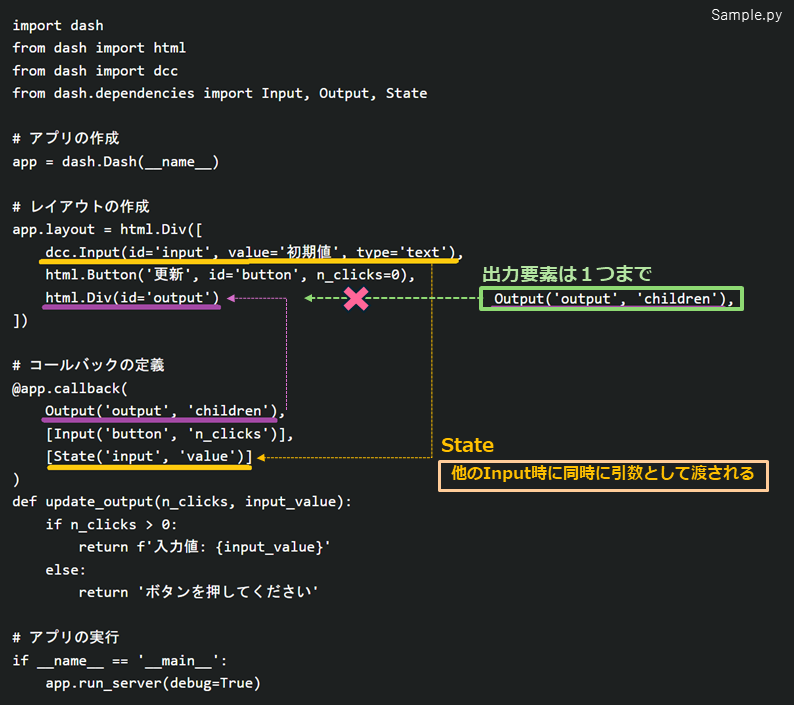
Stateに関してはInputと似ていますが、Stateがない場合は入力欄に文字入力するたびにコールバックが呼び出されるため、Stateとして渡してButtunを押下した場合に初めて処理を行うコードになります。
2.リアルタイム処理
【レイアウト側】
次にDASHでのリアルタイム処理はdcc.Intervalで今回は5秒で指定します。
main.py
dcc.Interval(id='interval-component', interval=5*1000, n_intervals=0),
【コールバック側】
以下はIPアドレスのデータテーブルとCPU/MEM使用率グラフのコールバック部分のコードになります。ここではそれぞれのコールバック引数にInput('interval-component', 'n_intervals') とすることで各コールバックを起動させています。今回は判りやすく各コールバックを記載していますが、最終的には処理毎にファイルを分けています。そこについても順次説明します。
######################### コールバック処理
######################### データテーブル更新
@app.callback(
Output('all-data-store', 'data'),
Output('live-update-table', 'data'),
Input("status-filter", "value"),
Input('all-data-store', 'data'),
Input('interval-component', 'n_intervals')
)
def update_layout(filter_val, all_data, n_intervals):
# データテーブル更新処理
all_df = get_ipconnections(pd.DataFrame(all_data))
# フィルタリング該当行を削除
filter_df = all_df[all_df.isin(filter_val).any(axis=1)]
return all_df.to_dict('records'), filter_df.to_dict('records')
########################### CPU memory 使用率
@app.callback(
Output("cpu-graph", "figure"),
Output("memory-graph", "figure"),
Input("interval-component", "n_intervals"),
)
def update_memory_graph(n_intervals):
# CPU/MEMグラフ更新処理
cpu_fig , mem_fig = update_pigraph()
return cpu_fig,mem_fig
3.コールバックのデータ保持
上記のデータテーブル更新処理は5秒毎に呼び出されるので前回のデータを保持する必要があります。そこで同一出力の一回制限があるので、ここではその対処としてdcc.Storeを使用してPandasデータフレームを使用して保持しています。またデータのフィルタリングを行って表示しているためデータテーブルに渡すdfはフィルタリング後のデータ、それとは別に全データを以下のdcc.Storeに保持して再利用しています。
layout.py
topbar = html.Div(
[
html.H4("TITLE_name SAMPLE"),
dcc.Store(id="all-data-store"), # 全dfデータ保持用
]
)
【Pandasデータフレームの流れ】
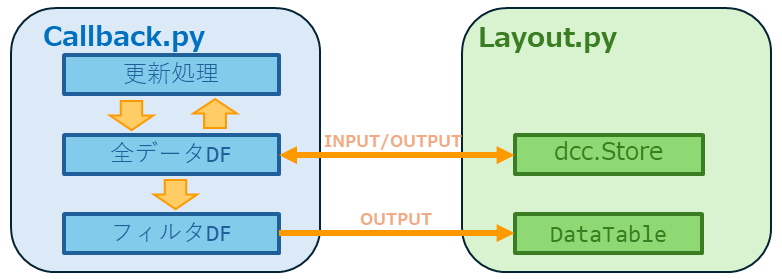
- Output('all-data-store', 'data') ⇒全データフレーム保持
- Output('live-update-table', 'data') ⇒フィルタ後フレーム保持
- Input('all-data-store', 'data') ⇒全データフレーム取得
4.CPU/メモリグラフ
ちなみにCPUとメモリの使用率のコードは以下になります。
def update_pigraph():
# CPU使用率を取得
cpu = psutil.cpu_percent(interval=1)
print("CPU",cpu)
# メモリ使用率を取得
memory_percent = psutil.virtual_memory().percent
# CPUグラフの更新
cpu_distros = ['CPU', 'Free']
cpu_values = [cpu, 100 - cpu]
cpu_fig = go.Figure(
data=go.Pie(
labels=cpu_distros,
values=cpu_values,
hole=.4,
marker=dict(colors=['#a4cceb', '#257aba'])))
cpu_fig.update_layout(
width=330,
height=250,
margin=dict(l=20, r=10, t=10, b=10),
paper_bgcolor='rgba(0,0,0,0)')
# グラフの更新
mem_distros = ['Memory', 'Free']
mem_values = [memory_percent, 100 - memory_percent]
mem_fig = go.Figure(
data=go.Pie(
labels=mem_distros,
values=mem_values,
hole=.4,
marker=dict(colors=['#a4cceb', '#257aba'])))
mem_fig.update_layout(
width=330,
height=250,
margin=dict(l=20, r=10, t=10, b=10),
paper_bgcolor='rgba(0,0,0,0)')
return cpu_fig , mem_fig
plotlyのグラフも主に以下の種類があります。
ここではgoを使用しています。
go.Figureとupdate_layoutで内部処理とレイアウトを分けてます。
plotly.express(px)の特徴
- データフレームからのグラフの作成がラク
- コード量がgoと比較して少ない
- グラフが比較的カラフル
plotly.graph_object(go)の特徴
- グラフの種類が多い
- コード量がpxと比較して多い
- グラフが比較的地味