概要
kaggleで初めによく利用されるタイタニックデータを用いて、
因子分析をしてみました。
但し、今回は、予測することを目的として行ったのではなく、
単に統計分析手法を用いて、データの特徴などを観察することを目的として行いました。
なので、train/testデータをまとめて因子分析した次第です。
※本記事と同様のデータを用いた主成分分析の記事を書いております。
本記事はその続編的な感じで書きました。
下記[分析_詳細]における前処理までのプログラム(1.〜4.)は"ほぼ"同じです。
(下記[分析_概要]をご確認ください。)
https://qiita.com/cleeeear/items/67210d977a901ebf9b4f
前提
- 因子分析とは?
説明変数を"共通因子と独自因子の線型結合"で表すことを考える。
$X=FA+UB$
$X : データ(データ数(N) × 説明変数の数(n))$
$F : 共通因子行列(N × 因子数(m))$
※各説明変数が共通して関与する共通因子(列ベクトル)から成る。
$A : (共通因子の)因子負荷量(m × n)$
※下記で「因子負荷量」と記す時はこちらを指す。
$U : 固有因子行列(N × n)$
※各説明変数それぞれが別々の固有因子(列ベクトル)から成る。
$B : 固有因子の因子負荷量(N × n)$
※対角行列
(因子負荷量 A の各要素$a_{ij}$は、
本記事の分析でもある以下の分析条件①②において、
共通因子$F_{i}$と説明変数$X_{i}$の相関値となる。
① 共通因子:直交因子
② 説明変数:標準化して使用(平均0 分散1)
)
因子分析では、この因子負荷量Aを求める。
求めた因子負荷量から共通因子の特徴を捉え、
共通因子をデータの要約として利用することが多い。
分析_概要
- 分析データ
タイタニックデータ(train + test)。
下記(kaggle)よりダウンロードできます。
(但し、kaggleへのサインインが必要。)
https://www.kaggle.com/c/titanic/data - 本分析での設定
- 共通因子:2つ & 直交因子
- 説明変数:標準化して使用(平均0 分散1)
- 確認ポイント
- 因子負荷量
- 分析にて除外する変数
今回は、簡易分析のため、前処理が難しい下記変数は除外して分析します。 - Cabin
- Ticket
- Name
- Embarked_C
- Embarked_Q
- Embarked_S
分析_詳細
1. ライブラリインポート
import os
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import display
from sklearn.decomposition import PCA
2. 変数定義 (タイタニックデータcsv格納先など)
※フォルダ「data」にタイタニックデータcsv(train.csv , test.csv)を格納している前提のコード。
# カレントフォルダ
forlder_cur = os.getcwd()
print(" forlder_cur : {}".format(forlder_cur))
print(" isdir:{}".format(os.path.isdir(forlder_cur)))
# data格納先
folder_data = os.path.join(forlder_cur , "data")
print(" folder_data : {}".format(folder_data))
print(" isdir:{}".format(os.path.isdir(folder_data)))
# dataファイル
## train.csv
fpath_train = os.path.join(folder_data , "train.csv")
print(" fpath_train : {}".format(fpath_train))
print(" isdir:{}".format(os.path.isfile(fpath_train)))
## test.csv
fpath_test = os.path.join(folder_data , "test.csv")
print(" fpath_test : {}".format(fpath_test))
print(" isdir:{}".format(os.path.isfile(fpath_test)))
# id
id_col = "PassengerId"
# 目的変数
target_col = "Survived"
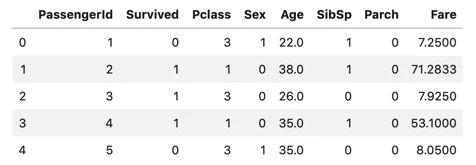
3. タイタニックデータ取り込み
下記コードで作成するデータ「all_data」(train + test)を後続で使用します。
# train.csv
train_data = pd.read_csv(fpath_train)
print("train_data :")
print("n = {}".format(len(train_data)))
display(train_data.head())
# test.csv
test_data = pd.read_csv(fpath_test)
print("test_data :")
print("n = {}".format(len(test_data)))
display(test_data.head())
# train_and_test
col_list = list(train_data.columns)
tmp_test = test_data.assign(Survived=None)
tmp_test = tmp_test[col_list].copy()
print("tmp_test :")
print("n = {}".format(len(tmp_test)))
display(tmp_test.head())
all_data = pd.concat([train_data , tmp_test] , axis=0)
print("all_data :")
print("n = {}".format(len(all_data)))
display(all_data.head())

4. 前処理
変数毎にダミー変数化や欠損補完、変数削除をして、作成するデータ「proc_all_data」を後続で使用します。
# コピー
proc_all_data = all_data.copy()
# Sex -------------------------------------------------------------------------
col = "Sex"
def app_sex(x):
if x == "male":
return 1
elif x == 'female':
return 0
# 欠損
else:
return 0.5
proc_all_data[col] = proc_all_data[col].apply(app_sex)
print("columns:{}".format(col) , "-" * 40)
display(all_data[col].value_counts())
display(proc_all_data[col].value_counts())
print("n of missing :" , len(proc_all_data.query("{0} != {0}".format(col))))
# Age -------------------------------------------------------------------------
col = "Age"
medi = proc_all_data[col].median()
proc_all_data[col] = proc_all_data[col].fillna(medi)
print("columns:{}".format(col) , "-" * 40)
display(all_data[col].value_counts())
display(proc_all_data[col].value_counts())
print("n of missing :" , len(proc_all_data.query("{0} != {0}".format(col))))
print("median :" , medi)
# Fare -------------------------------------------------------------------------
col = "Fare"
medi = proc_all_data[col].median()
proc_all_data[col] = proc_all_data[col].fillna(medi)
print("columns:{}".format(col) , "-" * 40)
display(all_data[col].value_counts())
display(proc_all_data[col].value_counts())
print("n of missing :" , len(proc_all_data.query("{0} != {0}".format(col))))
print("median :" , medi)
# Embarked -------------------------------------------------------------------------
col = "Embarked"
proc_all_data = pd.get_dummies(proc_all_data , columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
# Cabin -------------------------------------------------------------------------
col = "Cabin"
proc_all_data = proc_all_data.drop(columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
# Ticket -------------------------------------------------------------------------
col = "Ticket"
proc_all_data = proc_all_data.drop(columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
# Name -------------------------------------------------------------------------
col = "Name"
proc_all_data = proc_all_data.drop(columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
# Embarked_C -------------------------------------------------------------------------
col = "Embarked_C"
proc_all_data = proc_all_data.drop(columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
# Embarked_Q -------------------------------------------------------------------------
col = "Embarked_Q"
proc_all_data = proc_all_data.drop(columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
# Embarked_S -------------------------------------------------------------------------
col = "Embarked_S"
proc_all_data = proc_all_data.drop(columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
proc_all_data :
5. 因子分析
5−1. 標準化、fit
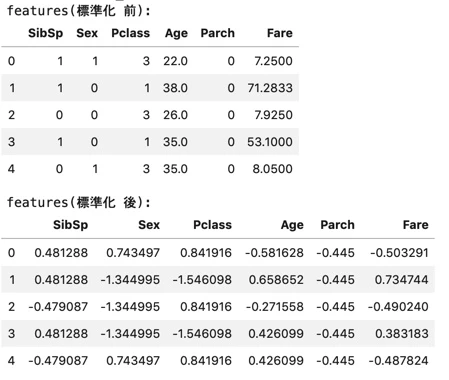
説明変数を標準化した上で、因子分析を行います。
# 説明変数
feature_cols = list(set(proc_all_data.columns) - set([target_col]) - set([id_col]))
print("feature_cols :" , feature_cols)
print("len of feature_cols :" , len(feature_cols))
features_tmp = proc_all_data[feature_cols]
print("features(標準化 前):")
display(features_tmp.head())
# 標準化
ss = StandardScaler()
features = pd.DataFrame(
ss.fit_transform(features_tmp)
, columns=feature_cols
)
print("features(標準化 後):")
display(features.head())
features (標準化前後):
5-2. 因子負荷行列
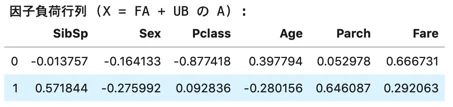
# 因子分析
n_components = 2
fact_analysis = FactorAnalysis(n_components=n_components)
fact_analysis.fit(features)
# 因子負荷行列 (X = FA + UB の A)
print("因子負荷行列 (X = FA + UB の A) :")
components_df = pd.DataFrame(
fact_analysis.components_
,columns=feature_cols
)
display(components_df)
components_df:
5-3. [参考]①因子行列 ②因子間の相関 ③"因子負荷行列(A) - 因子(F)と説明変数(X)の相関"
こちらは、参考までに出力しました。
②について、直交因子であることを確認。
③について、
今回、説明変数は標準化し且つ直交因子であるため、
(近似解なので誤差があれど)その差は0になることを確認。
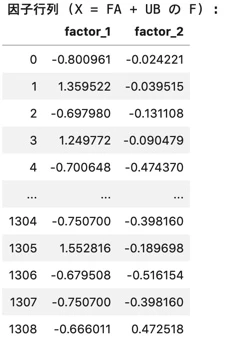
# 因子
print("因子行列 (X = FA + UB の F) :")
fact_columns = ["factor_{}".format(i+1) for i in range(n_components)]
factor_df = pd.DataFrame(
fact_analysis.transform(features)
, columns=fact_columns
)
display(factor_df)
# 因子間の相関
corr_fact_df = factor_df.corr()
print("因子間の相関:")
display(corr_fact_df)
# 因子間の相関(小数表記)
def show_float(x):
return "{:.5f}".format(x)
print("※小数表記:")
display(corr_fact_df.applymap(show_float))
# [因子負荷行列(A)] - [因子(F)と説明変数(X)の相関]
## 因子(F)と説明変数(X)の相関
fact_exp_corr_df = pd.DataFrame()
for exp_col in feature_cols:
data = list()
for fact_col in fact_columns:
x = features[exp_col]
f = factor_df[fact_col]
data.append(x.corr(f))
fact_exp_corr_df[exp_col] = data
print("因子(F)と説明変数(X)の相関:")
display(fact_exp_corr_df)
print("[因子負荷行列(A)] - [因子(F)と説明変数(X)の相関]:")
display(components_df - fact_exp_corr_df)
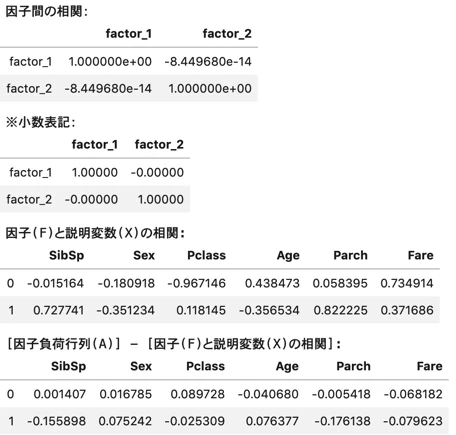
5-4. グラフ作成_1/2 (因子毎に因子負荷量を確認)
# グラフ化 (棒・折れ線グラフ_各因子の因子負荷量)
for i in range(len(fact_columns)):
# 対象因子の負荷量
fact_col = fact_columns[i]
component = components_df.iloc[i]
# 負荷量とその絶対値、絶対値のランク
df = pd.DataFrame({
"component":component
, "abs_component":component.abs()
})
df["rank_component"] = df["abs_component"].rank(ascending=False)
df.sort_values(by="rank_component" , inplace=True)
print("[{}]".format(fact_col) , "-" * 80)
display(df)
# グラフ化 (棒グラフ:因子負荷量 、 折れ線:その絶対値)
x_ticks = df.index.tolist()
x_ticks_num = [i for i in range(len(x_ticks))]
fig = plt.figure(figsize=(12 , 5))
plt.bar(x_ticks_num , df["component"] , label="factor loadings" , color="c")
plt.plot(x_ticks_num , df["abs_component"] , label="[abs] factor loadings" , color="r" , marker="o")
plt.legend()
plt.xticks(x_ticks_num , labels=x_ticks)
plt.xlabel("features")
plt.ylabel("factor loadings")
plt.show()
fig.savefig("bar_{}.png".format(fact_col))
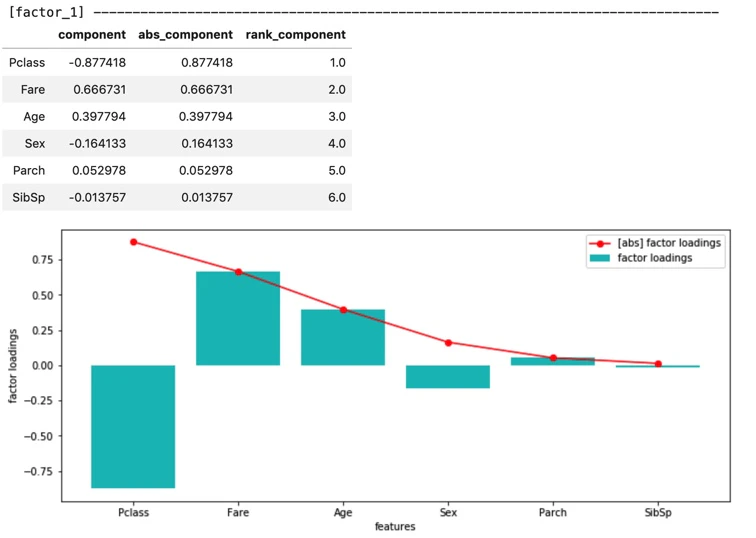
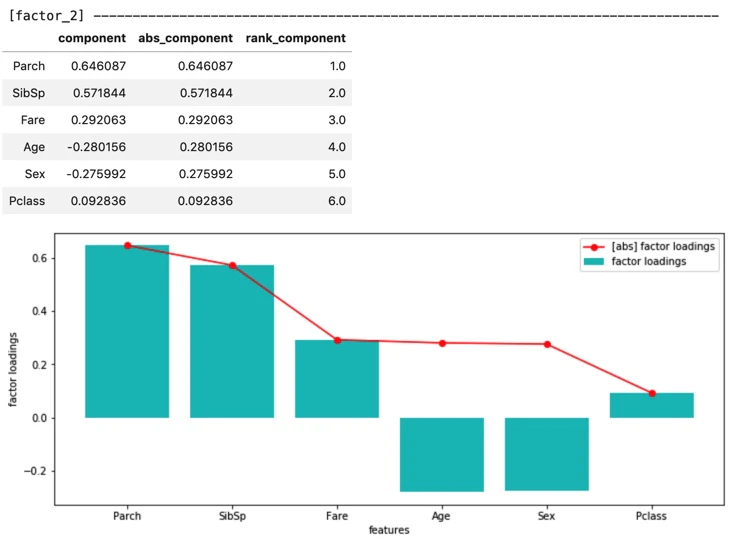
5-5. グラフ作成_2/2 (両因子からなる2軸に対して、因子負荷量をプロット)
# グラフ化 (2つの因子の因子負荷量)
# グラフ表示用関数
def plotting_fact_load_of_2_fact(x_fact , y_fact):
# グラフ用データフレーム
df = pd.DataFrame({
x_fact : components_df.iloc[0].tolist()
, y_fact : components_df.iloc[1].tolist()
}
,index = components_df.columns
)
fig = plt.figure(figsize=(10 , 10))
for exp_col in df.index.tolist():
data = df.loc[exp_col]
x_label = df.columns.tolist()[0]
y_label = df.columns.tolist()[1]
x = data[x_label]
y = data[y_label]
plt.plot(x
, y
, label=exp_col
, marker="o"
, color="r")
plt.annotate(exp_col , xy=(x , y))
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.grid()
print("x = [{x_fact}] , y = [{y_fact}]".format(
x_fact=x_fact
, y_fact=y_fact
) , "-" * 80)
display(df)
plt.show()
fig.savefig("plot_{x_fact}_{y_fact}.png".format(
x_fact=x_fact
, y_fact=y_fact
))
# グラフ表示
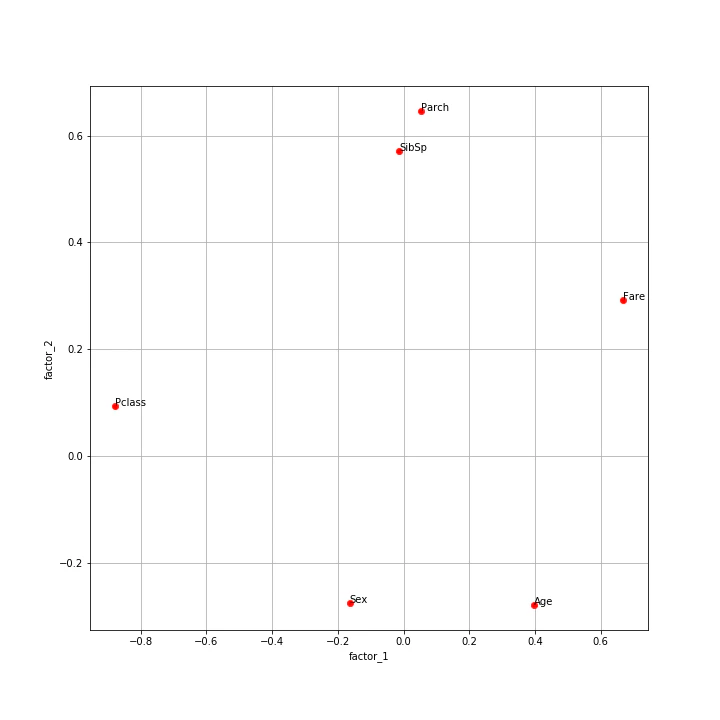
plotting_fact_load_of_2_fact("factor_1" , "factor_2")
前提として、Pclass(乗客の階級)の値域は1~3であり、小さい方が階級が高いらしい。
第1因子について、
Fare(乗船料金)の因子負荷が大きく、Pclass(乗客の階級)が小さい。
(つまり階級が高い方が因子負荷が大きい)
なので、第1因子は
"裕福度を評価する指標"
と考えることができそうだ。
※前記事での主成分分析における第一主成分と同じような指標である。
第2因子について、
絶対値として、Parch(両親、子供の数) と SibSp(兄弟、配偶者の数)が大きく共に正である。
なので、第2因子は
"家族の多さを表す指標"
と考えることができそうだ。

まとめ
2因子で因子分析をした結果、
第1因子として、 "裕福度を評価する指標"
そして、第2因子として、 "家族の多さを表す指標"
が得られた。
また、第1因子は、
"前回主成分分析を行った時の第1主成分"
と同じような指標となった。
多変量解析の書籍にて、
主成分分析と因子分析の本質は同じという旨が記載されていたが、
それを如実に表す結果となった感じである。