この文章のターゲット
この記事は、コンピュータサイエンスにおける理解必須な概念、データ構造、およびアルゴリズムについて復習するためのメモです。
はじめに
COVID-19
晴耕雨読という言葉がありますが、晴れても降っても畑を耕せないのがこのご時世です。当然、本を読むわけですが、最近コミットしている Cracking the Coding Interview では、絶対に確実に 100% 欠かせない知識として以下の表が載っていました。
| Data Structures | Algorithms | Concepts |
|---|---|---|
| Linked Lists | Breadth-First Search | Bit Manipulation |
| Trees, Tries, & Graphs | Depth-First Search | Memory (Stack vs. Heap) |
| Stacks & Queues | Binary Search | Recursion |
| Heaps | Merge Sort | Dynamic Programming |
| Vectors / ArrayLists | Quick Sort | Big O Time & Space |
| Hash Tables |
アルゴリズムといえば1年ほど前にそんな講義があったのですが、残念ながら当時は大学2年生で飲み会に次ぐ飲み会により脳みそを溶かしていました。この表を見ても全く何の話かわかりません。そんなわけで、この表に載っている内容についてまとめます。
どれほど重要か
表を見ても全く何の話かわからないというのは嘘なのですが、 Cracking the Coding Interview では、以下のようなことが書かれています。
Did you miss that paragraph above? It's important. If you don't feel very, very comfortable with each of the data structures listed, practice implementing them from scratch.
In particular, hash tables are an extremely important topic. Make sure you are very comfortable with this dta structure.
そこまで言うかという感じですが、自信満々にしておいたほうが良さそうです。スクラッチからやっていきましょう。
以下、画像は Wikipedia からの引用です。まずは軽くイメージをおさらいします。
Data Structures
Linked Lists
- 線形にデータが並んでおり、最もシンプルで一般的なデータ構造
- 要素の追加や削除が容易
- ランダムアクセスが出来ず、アクセス時間も線形
- 簡単に「リスト」とも呼ぶ

Trees, Tries, & Graphs
- いわゆる「木構造」。根があり親があり、連結されている
- linked list のより一般的な形といえる
- 頂点のことを vertex とか node とか言う
- 枝をポインタで表すのが普通
- trie は tree とはまた別のもの
- ノードが値をもつことはない
- ルートノードが空の文字列で、各エッジが char であるイメージ
- 各ノードは文字列を表す
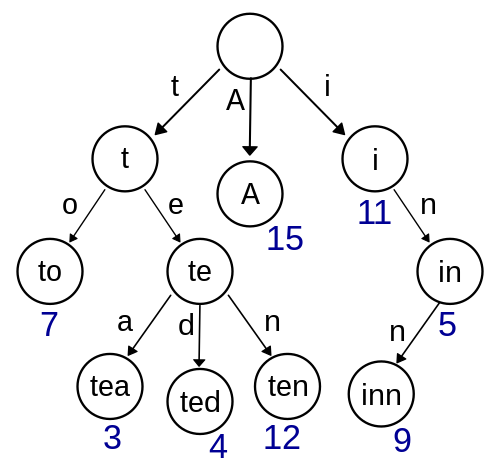
- Graph は木のより一般的な形といえる
- 閉路を含むものは木ではなくなる
Stacks & Queues
- スタックは LIFO
- push と pop
- キューは FIFO
- enqueue と dequeue
Heaps
- 特殊な木構造
- max-heap と min-heap とがある
- max-heap なら、親ノードのキーは子ノードのそれ以上になる
- heap property
- 左にある方が小さい、みたいなルールはない
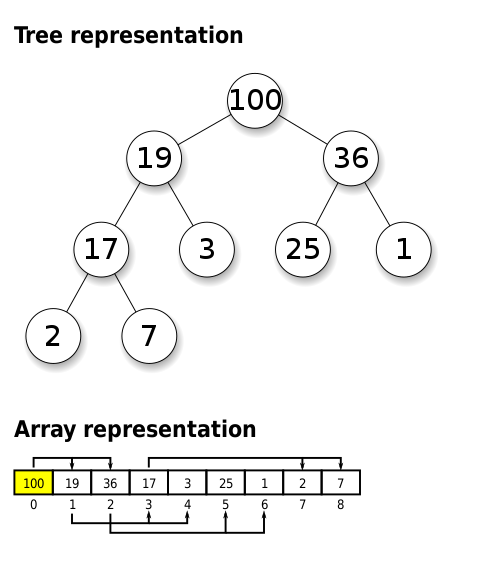
- 優先度付きキューの最も効率的な実装のひとつ
- 普通のキューの性質に加えて「優先度」の概念をもつ
- 「優先度」はなんらかの比較可能なものによって表現される必要がある(たとえば数値の大小やアルファベット順など)
- あるあるとしては、値の大小がそのまま優先度になる
- 配列やリストよりも好まれる傾向にある
- ダイクストラ法なんかで使われがち
Vectors / ArrayLists
- 双方とも似ていて、サイズが可変な配列
- 一般的には、配列が満タンに使われたら、サイズを二倍にした配列を新しく用意して全部コピーする
- Java の ArrayList では成長速度が1.5倍、C 系では2倍、Python の PyListObject では約1.125倍
- 一般的には、配列が満タンに使われたら、サイズを二倍にした配列を新しく用意して全部コピーする
- C++ や Rust では Vecotr、Java では ArrayList と呼んで、まぁ同じものを指してる、みたいなイメージ
- ArrayList は非同期、Vector は同期
- thread レベルの話
- ArrayList は速いけど thread safe ではない、Vector は遅いけれど thread safe ということ
- Vector の方が扱いやすい
- 要素の追加は $O(1)$ 、アクセスも $O(1)$ (ランダムアクセスが可能)
- Amortized Time
Hash Tables
- かなり重要らしい
- 配列のランダムアクセスのように、"highly efficient lookup" がウリ
- ハッシュ関数を使ったもの
- space 的な効率は非常に悪い。疎。Sparse。
- でも次のような非常に効果的な使い方がある
たとえば、以下のような問題があったとします。
Print all positive integer solutions to the equation $a^3 + b^3 = c^3 + d^3$ where a, b, c, and d are integers between 1 and 1000.
brute-force 的なやり方でいくと
n = 1000
for a from 1 to n
for b from 1 to n
for c from 1 to n
for d from 1 to n
if a^3 + b^3 == c^3 + d^3
print a, b, c, d
のような目も当てられない解法が思いつきます。 break を加えようとか a と b の大小を決めようとかそういう次元の話ではないです。堂々たる $O(n^4)$ ですから。もうちょっと頑張ると $O(n^3)$ にでき、非常に大きな進化ではあるのですが、それは5000兆円のはずが500兆円へのコストダウンになったようなもので、解決したかしないかのブーリアンで言ったら値は変わっていません。
ここでハッシュを使った方法が以下です。
n = 1000
for c from 1 to n
for d from 1 to n
result = c^3 + d^3
append (c, d) to list value map[result]
for each result, list in map
for each pair1 in list
for each pair2 in list
print pair1, pair2
すごい。$O(n^2)$ になりました。データ構造として疎ですが、こうして計算量の次元を下げ、現実的な方法を実現します。
Algorithms
Breadth-First Search
- じわりじわりと横に探索の範囲を広げていく感じ
- とりあえずもうガンガン進む
- 幅優先探索という名前でおなじみ
- 命名センスが神すぎて好き
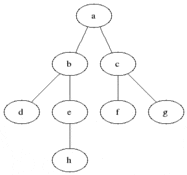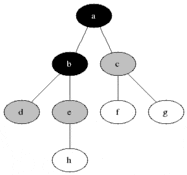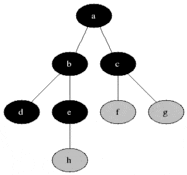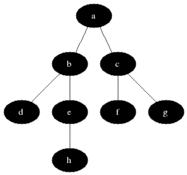
Depth-First Search
- 洞窟で分かれ道があったら、全部左行ってみる!ダメだったら一個戻って右行く!みたいな話
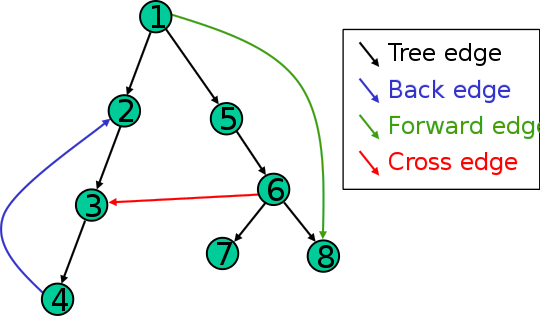
Binary Search
- ソートされた配列を対象として、ある値を見つける作業
- $O(\mathrm{log} n)$ なのでバリ速い
- 普通の配列では $O(n)$
- $O(n)$ と $O(\mathrm{log} n)$ とはエグいほど違います。たとえば、n が 1,267,650,600,228,229,401,496,703,205,376 だとしたら $\mathrm{log}_2 n$ はたったの100です。定数項にも迫るほどの安心感を与えてくれます。
Merge Sort
- 実用的なソーティングアルゴリズム
- Divide and Conquer なやつ
- 計算量的には $O(n\mathrm{log} n)$ である
- 最悪計算量も $O(n\mathrm{log} n)$ で保証されているため安全
- ヒープソートよりも速いとされるが、空間コストが大きいためあまり使われないとは言われる
- ジョン・フォン・ノイマン発明らしい
- すべての要素を一つずつに分け、次に1ペアの中で大小を決定する。次にペア同士をまとめるためにそれぞれを比較していき、その中での大小の比較を効率よく行う
- たしかにマージするって感じがする
- 団体戦における勝ち抜き戦みたいなもの
- サークルの飲み会で「将軍じゃんけんゲーム」というのがあったんですが、マージソートやん!!!て酔った勢いで叫んだら場が凍てついたことがあります。学科内だったら大爆笑なんですが
- 明日実装する!
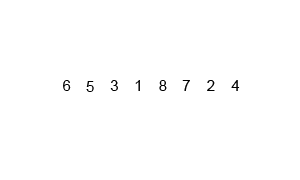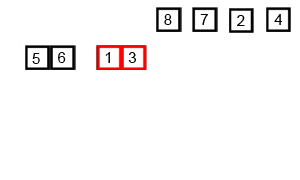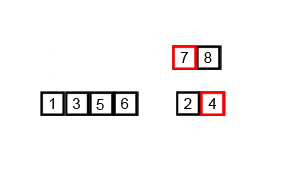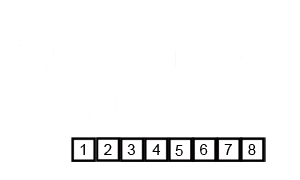
Quick Sort
- 泣く子も黙る qsort()
- pivot と呼ばれる比較用のサンプルを使う
- 実用的には最も速いとされるが、最悪実行時間は $O(n^2)$
- 何度か実装してみたけど一度もサクッとは終えられなかった気がする
- OBOE 絡みのデバグに労力がかかる
- 明日実装する!笑
Concepts
Bit Manipulation
- Bitwise Operators 的な、細かいところの操作を指す言葉
- AND, OR, NOT, NAND とか Left Shift のようなやつのこと
Memory (Stack vs. Heap)
- スタックはローカル変数が割当てられるところ
- ヒープは C で言えば
malloc()で動的に割り当てられる領域- ヒープソートとか、データ構造という文脈におけるヒープとは意味が違う
- Java ではインスタンスがあったとして、その参照 (reference) はローカル変数だからスタックに、インスタンスや配列の実体はヒープにある
Recursion
- while や for、 each などの iteration の対抗馬
- この間まで LISP の授業取っていたんですが、再帰を極めさせられました
- でも再帰ってなんか遅いイメージ
Dynamic Programming
- recursion に対して、より効率よく事を済まそうっていう考えのものを総称してこう呼ぶ
- たとえば以下
フィボナッチ数列の第 N 項を計算したいとしたとき、再帰を使って書くと以下のような感じになります。
void allFib(int n) {
for (int i = 0; i < n; i++) {
System.out.println(i + ": " + fib(i));
}
}
int fib(int n) {
if (n <= 0) reutrn 0;
else if (n == 1) return 1;
return fib(n - 1) + fib(n - 2);
}
これのオーダーは、 $O(2^n)$ です。再帰ではこうなりがちです。一方で、Dynamic Programming では、$O(n)$ になります。
void allFib(int n) {
int[] memo = new int[n + 1];
for (int i = 0; i < n; i++) {
System.out.println(i + ": " + fib(i, memo));n
}
}
int fib(int n, int[] memo) {
if (n <= 0) reutrn 0;
else if (n == 1) return 1;
else if (memo[n] > 0) return memo[n];
memo[n] = fib(n - 1, memo) + fib(n - 2, memo);
return memo[n];
}
どこがどう dynamic なのかというと、フィボナッチ数列のある項を計算するのに、前の結果があるかないかによってそのはじき出し方を変えている、ということです。そういう意味でいうと、先述したハッシュテーブルを使用した解法もこれの一つということになります。
Big O Time & Space
- いわずもがな
まとめ
自分が理解していく過程をメモに残しただけの内容ですが、私の中ではある程度理解が深まったし、これらの語の定義をズバッと述べられるようになりました。一度時間をとって、自分のなかで再び復習する時間、というのを取ってみるのもいいのではないでしょうか。