sht47です。ツイッターで画像、動画認識の記事などを紹介していますので、画像、動画認識のことをもっと知りたい方などは @sht_47をご覧ください!
期待の自己教師あり学習「Temporal Cycle-Consistent Learning」を解説!
2019年の8月にGoogleからすごい論文が出ました。Temporal Cycle-Consistent Learningというタイトルで下のGif動画のように投球動作において、足をあげるタイミング、リリースのタイミング、蹴り上げた足を着地するタイミングを教師なしで揃えることが可能です。他にもゴルフのスイングやベンチプレス、懸垂といった他の動作においても同様のことが可能です。
今後データセットが充実してくると、スポーツのハイライト動画や指導などの実応用が期待されます。それでは期待の自己教師あり学習手法Temporal Cycle-Consistent Learningを見ていきましょう。

本記事の流れ:
- 忙しい方へ
- TCCの解説
- TCCの実験結果
- まとめと所感
- 参考
原論文: "Temporal Cycle-Consistency Learning" (2019 Aug)
公式実装 : Tensorflow
0. 忙しい方へ
- 2つの異なる動画に対して、**「時間方向で同じActionを一致させる」**新たな自己教師あり学習を提案したよ
- 教師なしで、動画の中から同じイベントを時間方向で一致させることができるようになったよ
- ほぼ全てのタスクでSOTAを出したよ
- 従来の自己教師あり学習の手法TCNと組み合わせることで、さらに性能向上が見込めるよ
1. TCCの解説
Tempooral Cycle-Consistent Learning(TCC)で重要な箇所は以下の3つです。
- Cycle-Consistent Representation Learningとは
- Cycle-Back Classification LossとCycle-Back Regression Loss
- モデルの学習の流れ
それぞれについて、見ていきましょう。
1.0 背景
動画の理解は近年注目されている分野です。しかし、動画は状態が絶え間なく変わることや1フレームごとにアノテーションが必要なため、まだまだできないことが多いです。
しかし、ビデオの理解のために、大量の画像とラベルのセットが必要かどうかは分かっていません。そこで、今回の論文では2020年に注目された自己教師あり学習の枠組みで、時間方向の理解につながる特徴量を取得することに成功しています。
また、動画の理解には同じ動作をするフレーム同士を推測することが重要です。これができると、同じ動作が割り当てられているフレームを同じ特徴量空間に持っていくだけで済む為、問題が簡単になります。
ただ、上記の実現には、データセットの大量のラベル付けが難しく、同じ物体を複数のカメラから同時に撮ることで仮想的に実現していますが、全ての動作を複数のカメラで取得することは難しく、現状Actionのバリエーションが少なく、現実世界と離れており、実用的でありません。
この問題を解決するために、この論文は画像ごとのラベルがない(教師なし)データセットに対して、Cycle Consistentという考え方を導入し、自己教師あり学習の枠組みでフレーム同士のこの問題を解決しています。
1.1 モデルの入力
1.1.1 入力画像(Pouring Dataset)
この論文では、2つのデータセットを用いて実験しています! まず、Pouring Datasetについて紹介します。
あるコップをの中の液体を別のコップに移すという作業の動画が、70個含まれています。

1.1.2 入力画像(Penn Action Dataset)
もう一つのデータセットはPenn Action Datasetです。
こちらは、Pennsylvania 大学によって2013年に公開された動画のAction Calssificationのデータセットです。
データセットの中には、約2300個のVideoがあり、1つのVideoに平均70枚のImageが含まれています。
その入力に対して、下に示す15個のActionクラス、Pose EstimationやObject Detection用の13個の関節の位置やbouding boxがラベルとなっています。
15個のAction一覧
- (1) 野球のピッチング (167)
- (2) 野球のバッティング (173)
- (3) ベンチプレス (140)
- (4) ボウリング (220)
- (5) クリーン・アンド・ジャーク(ウエイトトレーニングの一つ) (88)
- (6) ゴルフのスイング (166)
- (7) 縄跳び (82)
- (8) スタージャンプ (112)
- (9) 懸垂 (199)
- (10) 腕立て伏せ (211)
- (11) 腹筋 (100)
- (12) スクワット (231)
- (13) ギターをジャンと弾く (94)
- (14) テニスのフォアハンド (157)
- (15) テニスのサーブ (186)
actionの後の()はvideo数を表しています。
15個のAction一覧
- (1) 野球のピッチング (167)
- (2) 野球のバッティング (173)
- (3) ベンチプレス (140)
- (4) ボウリング (220)
- (5) クリーン・アンド・ジャーク(ウエイトトレーニングの一つ) (88)
- (6) ゴルフのスイング (166)
- (7) 縄跳び (82)
- (8) スタージャンプ (112)
- (9) 懸垂 (199)
- (10) 腕立て伏せ (211)
- (11) 腹筋 (100)
- (12) スクワット (231)
- (13) ギターをジャンと弾く (94)
- (14) テニスのフォアハンド (157)
- (15) テニスのサーブ (186)
actionの後の()はvideo数を表しています。
下にデータセットの一例を示します。(Actionは「baseball_pitching」で、ちなみに投手はWashington Nationalsのストラスバーグ投手です!!!)

1.1.3 モデルの入力
モデルに入力する際には、動画からFPSを設定し切り出した画像列に対して、20フレームをRandomにサンプリングし、また、224x224にResizeして、入力としています。このようにして、入力のTensor **(B, 20, 3, 224, 224)**が得られます。
1.2 Cycle-Consistent Representation Learningとは
次にこの論文の核となる、Cycle Consistent Representation Learningについて説明します。この手法は自己教師あり(Self-Supervised)学習なので、正解データは必要としていません。
それでは、どうやって動画におけるActionの表現を学習するのでしょうか?
上の図で説明すると分かりやすいのですが、まずResNet等のImageNetで学習済みのCNNに画像のSequenceを入れます。その中間層を取り出してGAPをする(実際はもう少し複雑)と、高次元のFeatureのSequence(実際には128次元)を得ることができます。
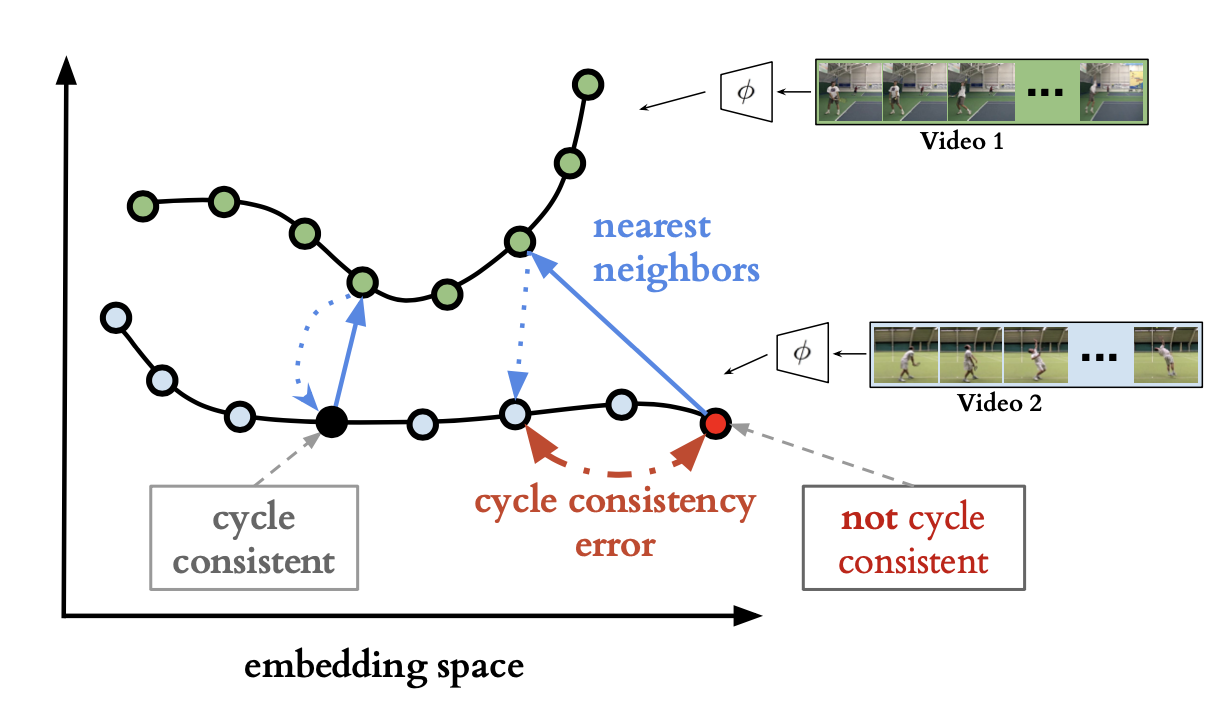
まず、下側の青色の時系列の中の、黒色のFeatureに注目します。
今回黒色のFeatureと最近傍のFeatureを、緑色の時系列から探します。
そうして見つけた緑色のFeatureに対して、もう一度最近傍のFeatureを青色の時系列から探します。 そうすると、元の黒色のFeatureと一致しました。これをCycle Consistentと筆者は名付けています。
次に、下側の青色の時系列からある赤色のFeatureに注目します。
今回赤色のFeatureと最近傍のFeatureを、緑色の時系列から探します。
そうして見つけた緑色のFeatureに対して、もう一度最近傍のFeatureを青色の時系列から探します。 そうすると、今回は元の赤色のFeatureと一致しません。これをCycle Consistentでないと言います。
今回、このCycle Consistentを用いて、全てのSequenceにおいて、Cycle Consistentになる画像数を最大化するように、パラメタを更新するのがCycle-Consistent Representation Learningです。
一言でまとめると、二つの類似した画像列の同じ動作を、時間方向に一致させるように学習しています。
1.3 2つのLoss関数(Cycle-Back Classification LossとCycle-Back Regression Loss)
1.3.1 Cycle-Back Classification Loss
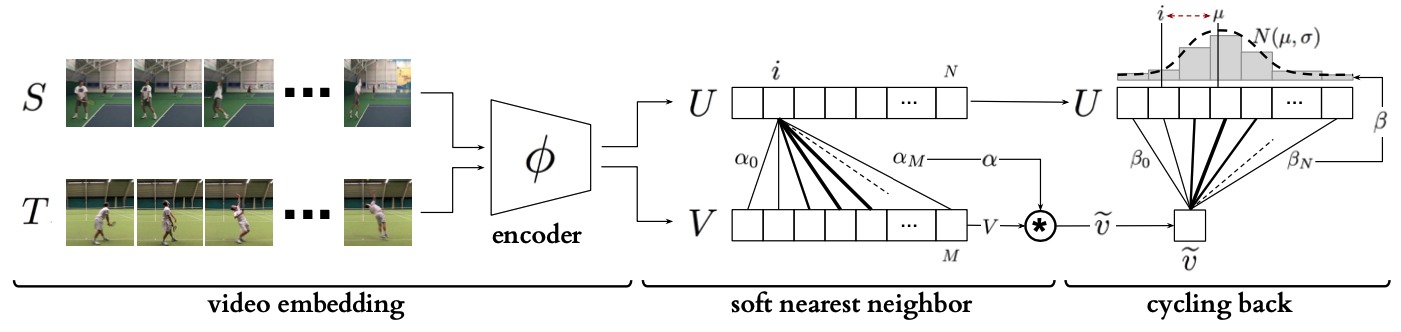
まず、2つの動画を用意します。
そのうち、それぞれの画像列(N枚の画像列S, M枚の画像列T)を以下のように表します
S = s_1, ..., s_N \\
T = t_1, ..., t_M
次に、 今回Encoderを使って高次元の特徴量ベクトルに持っていくので、 Encoderを$\phi$で表します。
u_i = \phi(s_i; \theta) \\
v_i = \phi(t_i; \theta)
ここで、Sのi番目の高次元特徴量ベクトル$u_i$の最近傍の点$\tilde{v}$は$v_1$から$v_M$までの足し合わせで書くと
\tilde{v_i} =\sum_j^M*\alpha_j v_j \\
\alpha_j = \frac
{e^{-||u_i-v_j||^2}}{\sum_k^M e^{-||u_i-v_j||^2}}
のようになります。 ここで$u_i$と$v_j$の距離はCosine類似度またはL2ノルムを用いて求めています。
さらにえられた$\tilde{v}$の最近傍の点を上の方法と同様に$U$から求める
\hat{y_i} =\sum_k^N*\beta_k u_k \\
\beta_k = \frac
{e^{-||\tilde{v_i}-u_k||^2}}{\sum_k^N e^{-||\tilde{v_i}-u_k||^2}}
$y_i$はi番目のみ1のOne-Hotベクトルとなっており、$\hat{y_i}$がi番目の予測をするように学習させています。
L_{cbc} = -\sum_i^Ny_ilog(\hat{y_i})
1.3.2 Cycle-Back Regression Loss
上の方法だと、$\hat{y_i}$の予測がiからどれだけずれているかを捉えることができないので、 平均がi近傍、分散が小さくなるようにすることを目的にRegression Lossを定義しています。
L_{cbr} =\frac
{-|i-\mu|^2} {\sigma^2}+{\lambda} log(\sigma)\\
\mu = \sum_k^N \beta_k *k \\
\sigma^2=\sum_k^N\beta_k*(k-\mu)^2
1.4 モデルの概要
モデルは至って、シンプルです。
まず、ResNet50を用いてGAPの直前の層を取り出します。次に、その取り出した層に対して3D Convを2層ほど通します。その後Global Max Pooling, FCを取り出し、Embedding Vectorを手に入れることができます.
ここでは簡単のため、サンプリングした画像の直前15Frame目の画像を加えるContextという処理を省いて記載しています。 また、3D ConvやFCも実際には複数層が含まれています。

2. TCCの実験結果
2.1 Evaluation Metrics
今回の実験では3つの評価指標を用いています。
2.1.1 Phase Classification Accuracy
フレームごとにActionのなかの、どの動作の最中かを予測します。
今回は学習したEmbedding + SVMを用いて予測しています。
2.1.2 Phase Progression
動作の推移をどの程度予測できているかを計測する指標です。
2.1.3 Kendall's Tau
Validationのデータセットの、全ての動画のペアに、一方の動画から2つのFrameペアをとり、それぞれのembedding最近傍からもう一方の対応するFrameを求めて順番があっているかどうかを求めます。
単調なFrameがないという過程の元で作られており、今回はそれを満たしているそうです。
それぞれのActionにおけるKey Event一覧
2.2 Embeddingの学習
それぞれのActionにおけるKey Event一覧

一枚の画像のembeddingを、t-SNEを用いて2次元で可視化したグラフになります。
個々のポイントは、画像列の中の1枚の画像に対応しています。
それぞれの動画の同じ動作が近くに位置しており、動作の表現が学習できていることが分かります。

2.3 実験結果
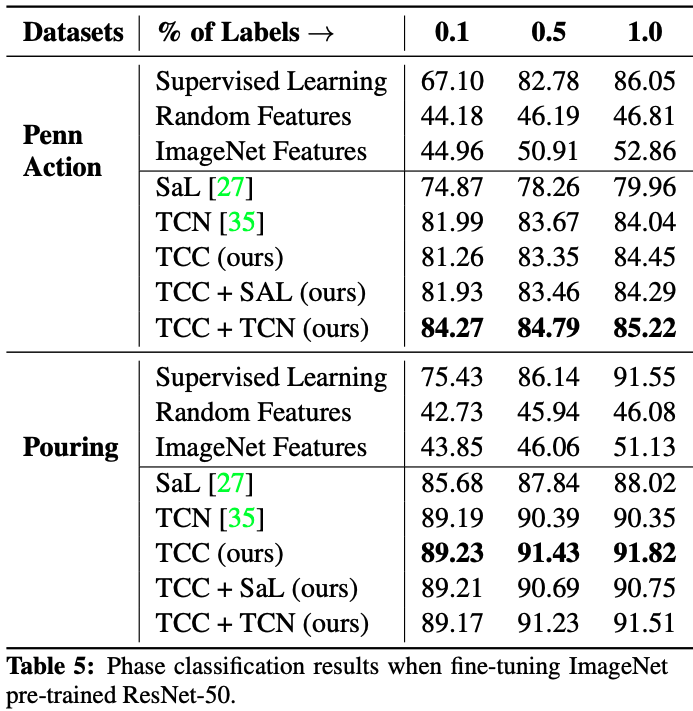
まず、Action Phase Classificationについてです。 Self-Supervised Learningで学習したEmbeddingの有効性を調べるため、少ないラベルデータ(10%, 50%, 100%)での比較も行なっています。
TCC単独またはSaLとTCNという自己教師あり学習の手法と組み合わせることで、SOTAのTCNと比べて1%~3%ほどの性能向上が見られました。
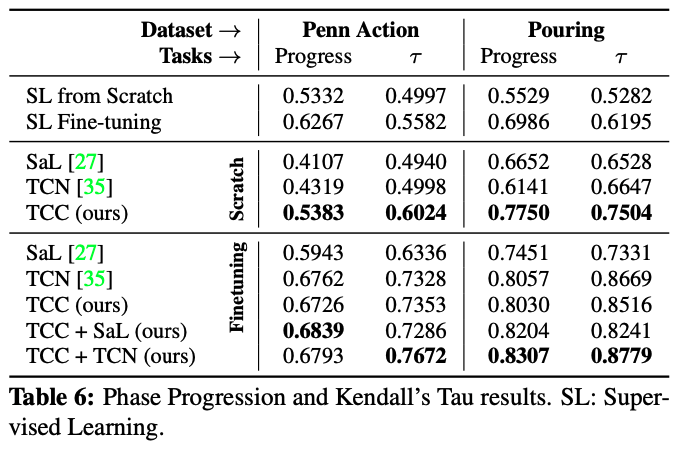
次に、Phase ProgressionとKendalls's TauのMetricについてです。 ResNet50においてImageNetのPre-Trainingを用いないScratchから組んだ場合(Scratch)とImageNetのPre-Trainingありの場合(Fine-Tuning)を比較しています。
どちらにおいても、TCCを組み合わせることでベストな結果が得られています。
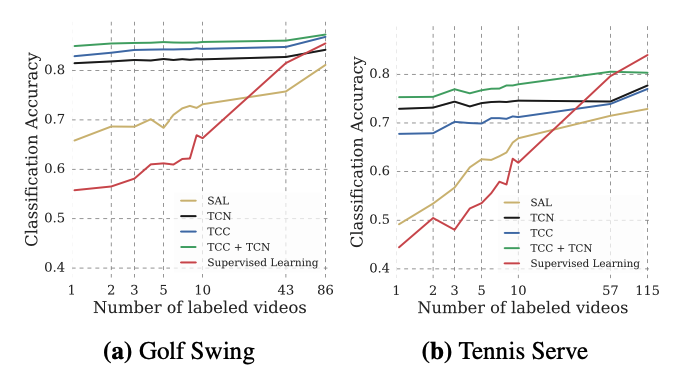
最後にFew Show Action Classificationの結果です。 この結果はSelf-Supervised Learningの大きな可能性や有用性を示しており、1枚のラベルでGolf Swingを自己教師あり学習で学習した際のClassification Accuracyは、50枚のラベルをSupervised Learningで学習した際と同等の結果を示すというものです。Supervised Learningでラベルが少ない際に、Self-Supervsied Learningを組み合わせることで、Few Show Learningができることや、生の動画データから教師あり学習と同様の有用な情報を取れる可能性があることを示しています。
さらなる応用先
特定の動作のみを大量の動画から引き出すことができるそうです。そのため、画像を入力として類似画像をYouTubeから検索すると言ったApplicationがGoogleからそのうちでてくるかもしれません。

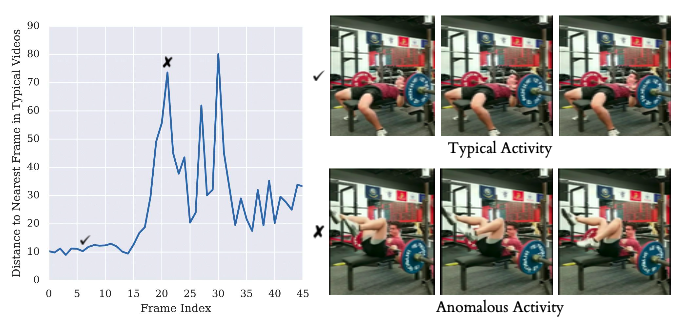
Embeddingの最近傍の点への距離を調べることでAnomaly Detectionへの応用が示されています。介護や監視といった分野での応用も期待できそうです。
3. まとめと所感
動画認識におけるすごいリープフロッグな論文であるように思いました。
しかし、他のデータセットでも同様の結果が出るのか、Embeddingが128次元で十分かどうかの検討、さらには異なる類似したアクション同士でのEmbedding Spaceの比較等まだまだ、研究の余地があるように思えます。今後も注目して読んでいきたいです。
面白い関連論文や質問等あれば、コメントまでよろしくお願いいたします。
読んで少しでも何か学べたと思えたら 「いいね」 や 「コメント」 をもらえるとこれからの励みになります!よろしくお願いします!
4. 参考
Google AI Blog
この記事に衝撃を受けて読み始めました。
ミュンヘン工科大学のTCC解説記事
TensorflowとGoogleColabでの実装がありがたかったです。
筆者ブログ
論文に書かれていない情報が書かれており面白かったです。
Time Contrasive Learning(TCL)の原論文
この論文も元となった論文で勉強になりました。
Penn Action Dataset
動画でスポーツを扱えてめちゃくちゃ楽しいです。データセットを作ってくださり、ありがとうございます!