sht47です。ツイッターで画像・動画認識の記事などを紹介していますので、画像・動画認識のことをもっと知りたい方などは @sht_47をご覧ください!
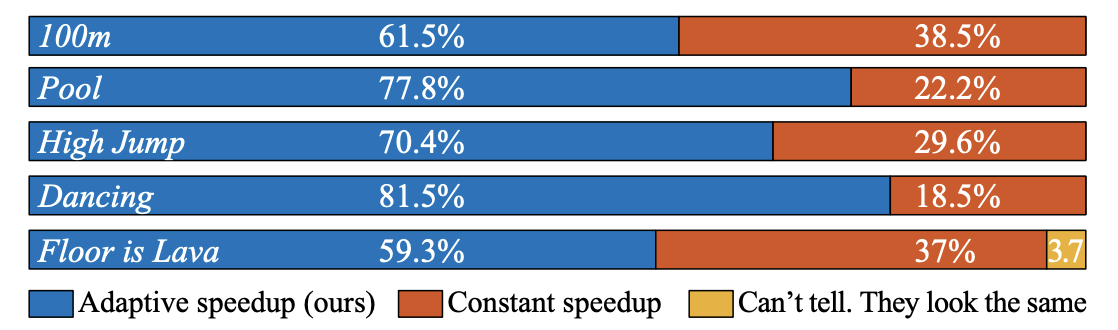
スポーツのハイライト動画を自動生成できるかもしれない、期待のモデルSpeedNet
今回はAdaptiveに動画の速度を変更することを可能にする、SpeedNetというモデルを紹介します。
2020年CVPRに採択されています。Binary Classificationという簡単な問題を解くだけで、このようなApplicationを実現していることが面白いです。データセット特有の手がかりに頼ることがないように学習の際に工夫もされています。急速に進化する動画理解の注目論文となっています。
それでは見ていきましょう!
元の動画

Adaptiveに速度を上げた動画
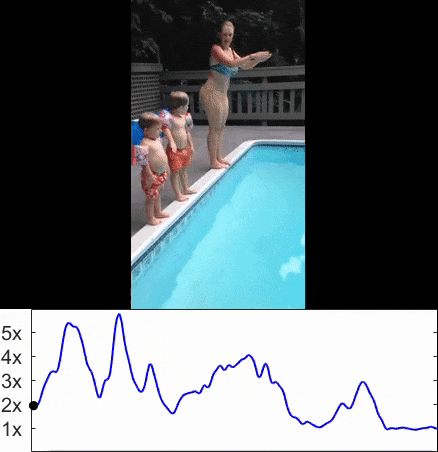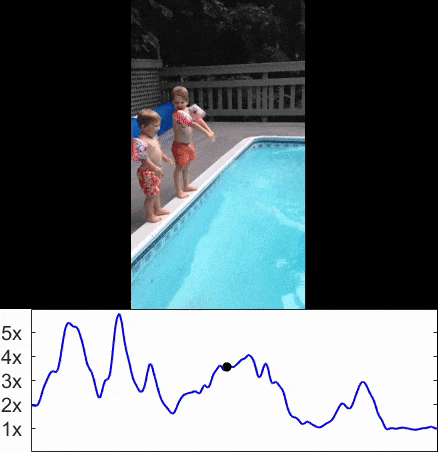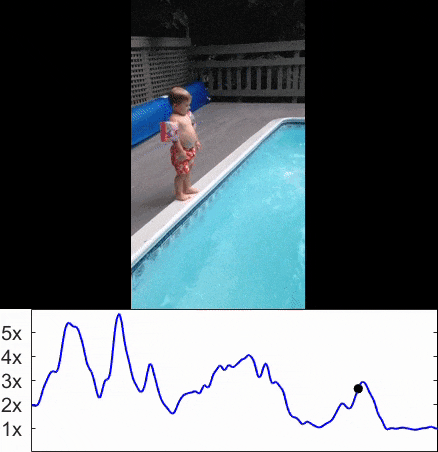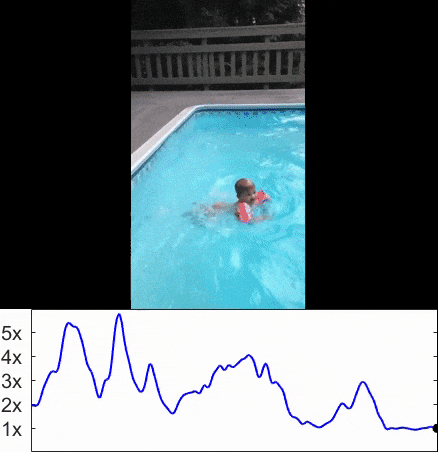
本記事の流れ:
- 忙しい方へ
- SpeedNetの解説
- SpeedNetの実験結果
- まとめと所感
- 参考
原論文: "SpeedNet: Learning the Speediness in Videos" (2020 Apr)
公式実装・非公式実装 : なし
0. 忙しい方へ
- 動画Clipの中から2倍速と普通の速度の画像列の両方を作成して、Binary Classificationをするというのが基本的な問題設定だよ
- モデルが不自然(Sped Up)と判断しない範囲で動画の速度を上げるという方針でAdaptive Sped Upな動画を作成しているよ
- SpeedNetで学習したモデルをPre-Trainingとして用いることで、ImageNetでのPre-Trainingに近づく結果を示したよ
1. SpeedNetの解説
SapeedNetで重要な箇所は以下の2つです。
- 問題設定をBinary Classificationにした理由
- モデルの学習方法
- Adaptive Sped up動画をどのように作成するか
1.1 問題設定をBinary Classificationにした理由
SpeedNetはBinary Classificationで普通の速度(x1)か、倍速(x2)かを予測する問題(Binary Classification)を自己教師あり学習の問題として設定しています。
ここで、速度を直接予測する回帰問題にしなかったのはモデルに動画が不自然か自然かを予測させることが目的で、必要以上に問題を難しくさせる必要はないと判断したからだそうです。(原論文)
これが、Adaptive Sped Up動画の作成の際に効いてきます。
また、人工的な不自然さを表す手がかりが入らないように、Spatial AugmentationとTemporal Data Augmentation, さらにはBatch内のそれぞれの動画数を揃える工夫をしています。
1.2 どのようのモデルを学習させるか
ここから、具体的な学習方法に写っていきます。
まず、普通速度と倍速の動画を作成するための元となる、3T個のFrameの画像列を用意しています。
ここで注意すべきことは、3Tの画像列から普通速度と倍速の画像列を両方作成することです。
そこから普通速度fはx1 ~ x1.2に、倍速動画fはx1.7 ~ x2.2に設定しています。
1-1/fの確率でFrameを飛ばしながら、長さがTになるように連続の画像列を作成します。
そして、BaseモデルとしてS3D-G(2017)のモデルを用いて学習しています。
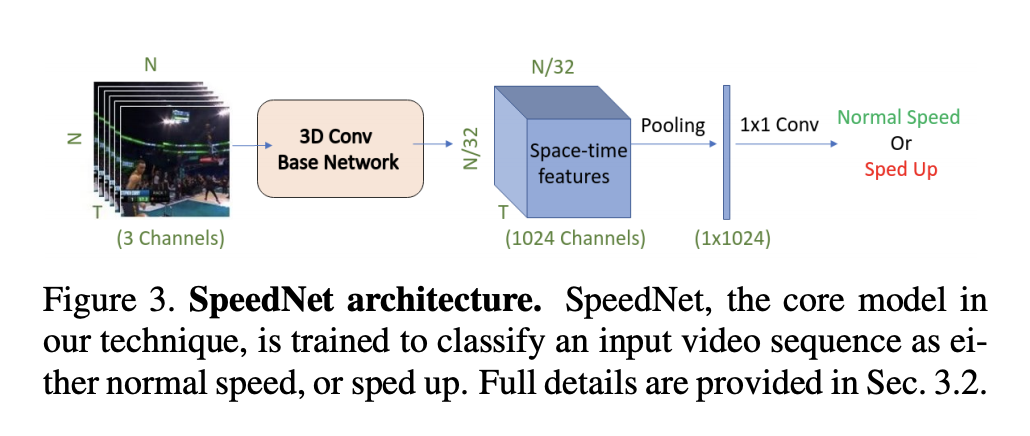
1.3 Adaptive Sped Up動画の作成方法
1.2まででT枚の画像を入力とした際に、ネットワークを通すことで、**Normal Speed(自然)かSped Up(不自然)**かどうかをモデルは80%程度のAccuracy(2.1参照)で判断できるようになりました。
この章では、SpeedNetを用いてAdaptive Sped Up動画の作成を行うかを説明していきます。
基本方針は モデルが不自然と判断するまで動画の速度を上げ続けるという至ってシンプルな方法です。
まず、対象の動画$v$に対して、10個の速度の動画($v_0$, $v_1$, ..., $v_{10}$)を作成し、それぞれに対してBinary Classificationで予測します。
それぞれの速度は$1.25^0$, $1.25^1$, $1.25^2$, ..., $1.25^{10}$となっています。
なので、1倍速から9.3倍速までの動画が作れることになります。
そして、それぞれの$v_i$に対して、T枚の画像列を予測し、Slide Windowの方式で予測結果が一番中央のFrameの予測結果になるようにします。WindowをSlideさせていくことで、x軸が時間となるBinary Classificationの予測分布$P_{v_i}(t)$を作成することができます。 (1=Normal, 0=Sped Up)
$P_{v_i}(t)$のうち、$P_{v_0}(t)$と比べて足りないフレームの予測結果は線形補完をして求めます。
次に、あるフレームに対して、Normal Speedとモデルが判断する最も早い速度を決めるために、閾値$\rho$を設定します。$\rho$は0.1, ..., 0.9で設定し、早くしたい速度(合計時間)を満たすように設定されます。
$P_{v_i}(t)$に$1.25^i$を掛け合わせ、Naturalと判断する最大の速度をとるることで、求めたいフレームごとの**Speed Vector $V(t)$**を求めることができます。
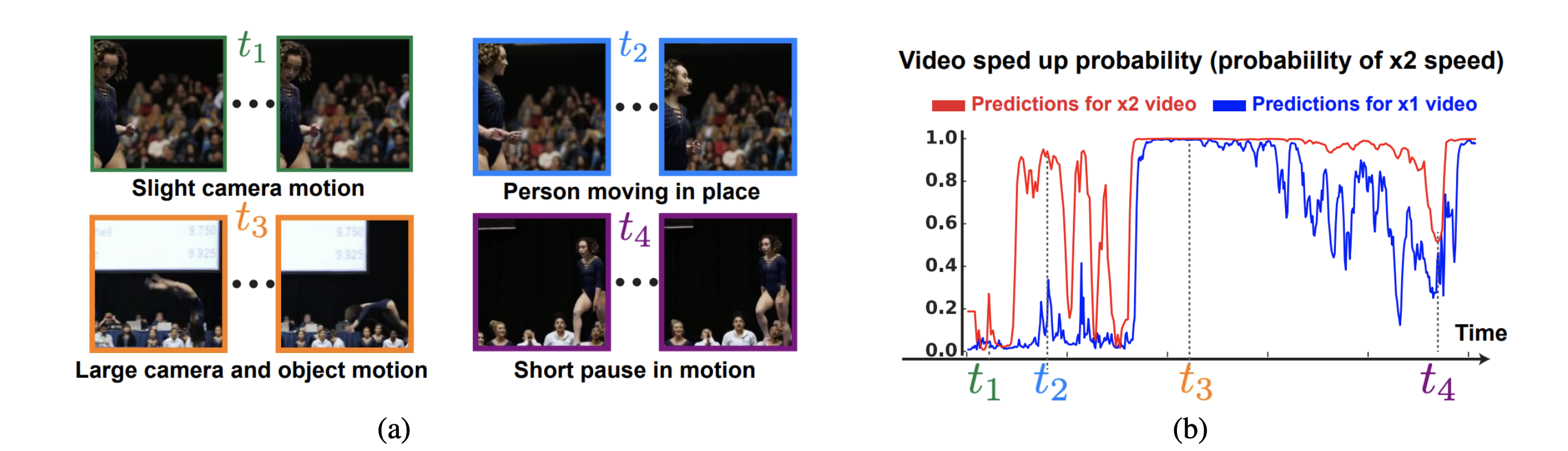
例えば、左の動画に対してx1, x2を作成し予測を行った結果が右の図になります。
注意して欲しいのは、今回の(b)のY軸は1-$P_i(t)$となっており、1はSped Up, 0はNormalという意味になります。
したがって、$t_2$は2倍速にすると大きくSped Upと判定します。その一方で、$t_1$は2倍速にしてもNaturalに感じているということがこの図から読み取れます。
2. SpeedNetの実験結果
2.1 基本的な実験
実験にはKineticsを用いて行っています。
自己教師あり学習なので、今回データセットのActionラベルは使用しておりません。 また追加のTest Datasetとして**Need For Speed Dataset(NFS)**を用いています。Kineticsと異なるActionが多く含まれているため、汎化性能の検証のために用いています。
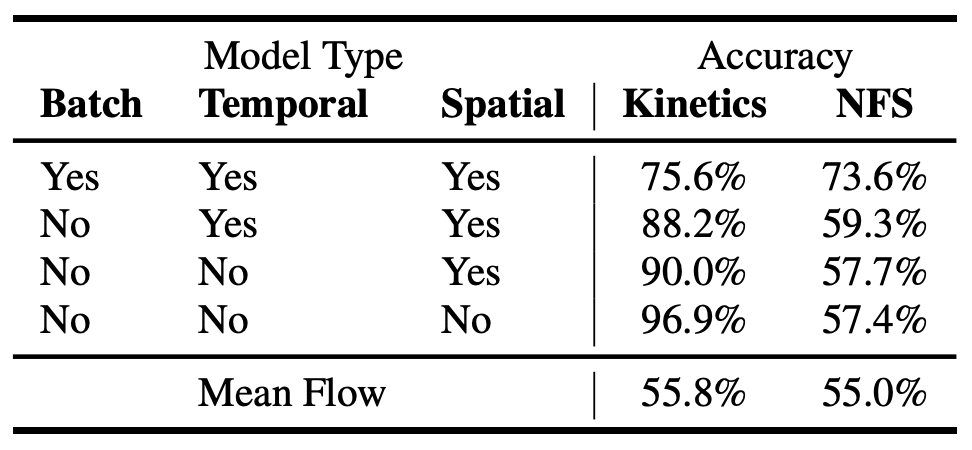
この実験では、
- Batch内の普通の速度の動画と倍速の動画の個数を揃えるかどうか
- Temporal Augmentation
- Spatial Augmentationの有無
の3つで、普通(x1) or 倍速(x2)のBinary ClassificationのAccuracy比較をしてます。
特に、KineticsのTest DataとNFS DatasetのAccuracyの差を着目すると、全てありの場合に差分が最も低くなることから、**Kinetics特有の手がかり(Cue)**を使わず予測できていると考えられます。
また、Optical Flowとの比較では大きく上回っており、Optical Flowが物体が大きくor早く動いた際に対応できないことや、Kineticsのデータセットが普通の速度で大きく動く物体が十分でないことを原因として考えているそうです。
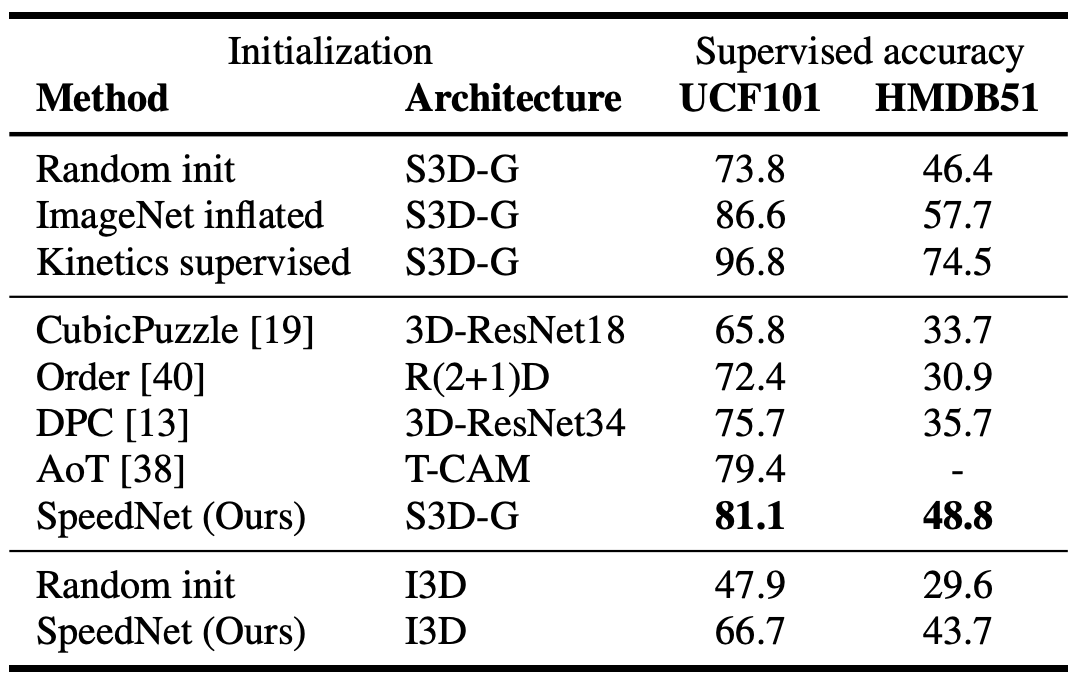
SpeedNetがPre-Trainingとして有効かどうかを確かめるために、Kineticsで学習したものを転移学習として用いる手法を比較しています。
S3D-GというSOTAモデルと組み合わせることで、Random Initを超える性能を見せる一方で、Kineticsで教師ありでPre-Trainingしたものには及ばないという結果になりました。
また、BaselineのモデルをI3Dに変更すると大きな性能悪化をも確認されました。
さらに、作成した適応的に速度を上げる動画に対して、30人のユーザーを集め、主観的に見やすいかどうかを尋ねる実験もしています。
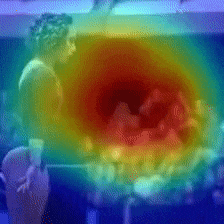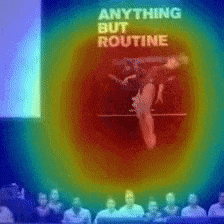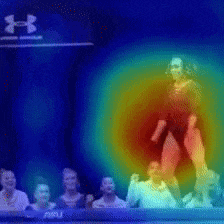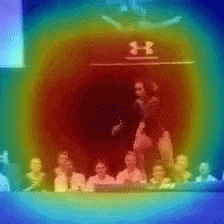
2.2 可視化の実験
Vimeo内に存在するMemory Elevenという動画を用いて、動画内で早く動いている箇所とゆっくり動いている箇所をCAMで当てるということを行っています。
黄色がゆっくり動いている箇所、青が早く動いている箇所となっており、推測することができていますね。

また、こちらの動画のようにDynamicに動く物体を推測することも行っています。
大枠では、動く箇所を当てることができています。
最後となりますが、最終層の1024次元のベクトルのCosine類似度をとることで、同様の動作をする動画を引き出すことが可能です。
一番の下の例から、ドラムを叩くというActionではなく、手の使い方という動作が類似のものとして引き出されているのは面白いですね。

3. まとめと所感
動画のSpeedを判断するという問題設定、さらにそれをSelf-Supervised LearningとしてAction Classificationに応用させるという点がすごく興味深いと思いました。
個人的にConv3Dに変わるOperatorが2021年に登場してくるのではないかと期待しています。
実装してAdaptive Sped Up Videoを作って、普通の倍速動画と比べて、どの程度印象が変わるのかを見てみたいですね。
4. 参考
- "原論文 SpeedNet: Learning the Speediness in Videos" (2020 Apr)
- Project Page
-
Seeing the Arrow of Time
2014年のOxford大学の類似研究 -
Learning and Using the Arrow of Time
2018年のOxford大学の類似研究