はじめに
きっかけ
是非「いいね」お願いします。励みになります!
就職活動を進める中で、エンジニアとしての技術力を具体的かつ明確にアピールする必要性を強く感じました。特に、エントリーシート(ES)では、どのくらいの技術経験があるのかを定量的に示す項目が多く見受けられます。例えば、「使用経験のある技術やツールを5段階で評価する」といった質問や、「最大でどれだけのステップ数を自作したか」「どのようなライブラリやフレームワークを使用したか」を具体的に記載するよう求められるケースが頻繁にあります。
特に、複数の言語やツールを使用してプロジェクトを進めた場合、どの言語をどれだけ使ったかの割合や、各ツールがどのようにプロジェクトに貢献したのかを簡潔に伝えるのは難しいと感じました。定期的に更新し、努力を可視化することでもチーベーションを維持しましょう!便利なAPIもあるけど、自作すると幅が広がる
完成品
Githubのファイル数
リポジトリの読み書きの権限を与える
GitHub Actionsを活用してリポジトリを自動更新する場合、リポジトリに対して適切な権限を付与する必要があります。この章では、鍵の発行、権限の登録、そしてそれをWorkflowに反映する手順を詳しく説明します。
鍵の発行
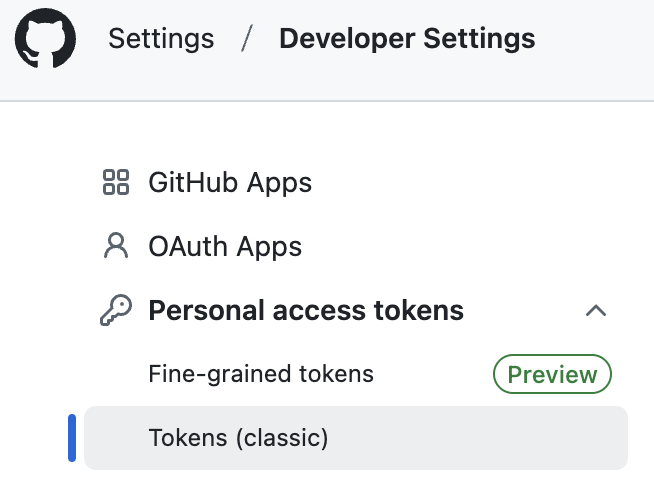
- GitHubの画面右上のプロフィールアイコンをクリックし、Settingsを選択。
- 左側メニューのDeveloper settings > Personal access tokens > Tokens (classic)をクリック
- Generate new tokenを選択し、適切なスコープを設定します。

トークンを発行し、メモ帳などに一時保存します(このトークンは後から確認できません)。
リポジトリに権限の登録
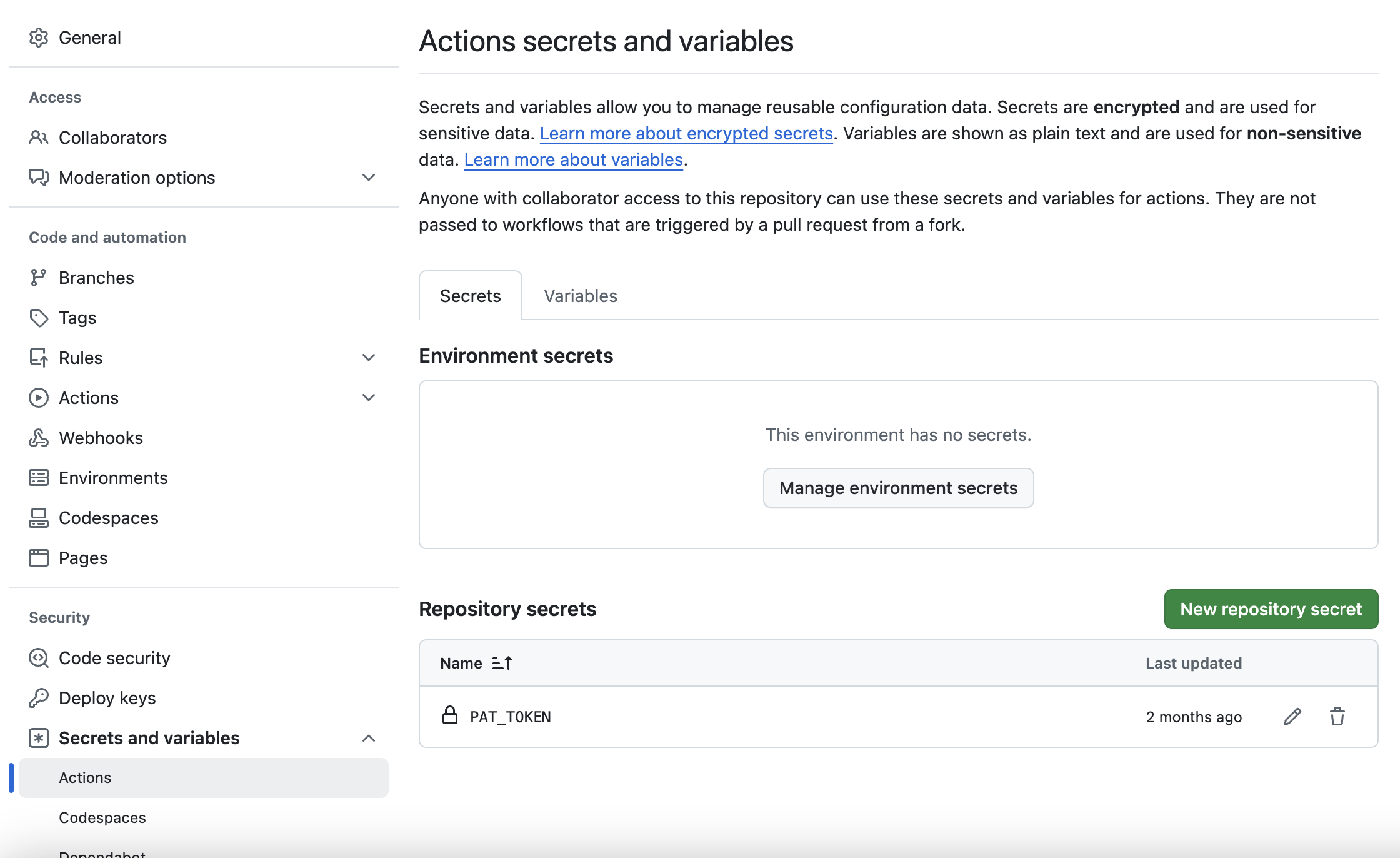
- 対象リポジトリのページでSettingsを開きます。
- 左メニューのSecrets and variables > Actionsをクリック。
- New repository secretをクリックし、以下を入力:
Name: ACCESS_TOKEN(任意の名前を設定可能)
Value: 生成したトークンの値を入力
関数の作成(app.py)
- リポジトリの解析: GitHub APIを使用して、ユーザーのすべてのリポジトリを取得。
- 言語データの集計: 各リポジトリ内のコードを言語ごとに分類し、ステップ数やファイル数を記録。
# リポジトリデータを取得
def fetch_repositories():
url = 'https://api.github.com/user/repos'
headers = {
'Authorization': f'token {os.getenv("GITHUB_TOKEN")}'
}
params = {
'per_page': 100,
'type': 'all'
}
repos = []
while url:
response = requests.get(url, headers=headers, params=params)
response_data = response.json()
repos.extend(response_data)
url = response.links.get('next', {}).get('url')
return repos
# 各リポジトリの言語データを取得
def fetch_languages(repo):
url = repo['languages_url']
headers = {
'Authorization': f'token {os.getenv("GITHUB_TOKEN")}'
}
response = requests.get(url, headers=headers)
return response.json()
- リポジトリのファイル解析:ファイル内容を解析し、コード行数やimport文をカウント。
def analyze_repository_files(repositories):
language_data = defaultdict(lambda: {
"file_count": 0,
"total_steps": 0,
"import_counts": Counter(),
"max_steps": 0
})
headers = {'Authorization': f'token {os.getenv("GITHUB_TOKEN")}'}
for repo in repositories:
repo_name = repo['name']
contents_url = repo.get('contents_url', '').replace('{+path}', '')
print(f"Fetching files for repository: {repo_name}")
# 全てのファイルを再帰的に取得
files = fetch_repository_files_recursive(contents_url, headers)
for file in files:
if isinstance(file, dict) and file.get("type") == "file":
file_path = file["path"]
file_download_url = file.get("download_url")
print(f"Analyzing file: {file_path}")
# ファイル内容を取得
file_response = requests.get(file_download_url, headers=headers)
if file_response.status_code != 200:
print(f"Failed to download file {file_path}: {file_response.status_code}")
continue
file_content = file_response.text
language = repo.get("language", "Unknown")
lines = file_content.splitlines()
step_count = len(lines)
# 更新: ファイル数、ステップ数の合計
language_data[language]["file_count"] += 1
language_data[language]["total_steps"] += step_count
language_data[language]["max_steps"] = max(
language_data[language]["max_steps"], step_count
)
# import文をカウント
imports = re.findall(r'^\s*(import\s+\w+|from\s+\w+\s+import)', file_content, re.MULTILINE)
language_data[language]["import_counts"].update(imports)
return language_data
- ライブラリの特定:リポジトリ全体で頻繁に使用されているライブラリをランキング形式で出力。
def get_top_imports(language_data, top_n=10):
import_totals = Counter()
for data in language_data.values():
import_totals.update(data["import_counts"])
return import_totals.most_common(top_n)
workflowへの反映
Workflow内でシークレットとして登録したトークンを使用します。以下は基本的な設定例です.

name: Update README with Language Usage
on:
schedule:
- cron: "0 */1 * * *" # 毎日1時間ごとに実行
workflow_dispatch: # 手動での実行も可能
jobs:
update-readme:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
run: |
pip install requests
pip install matplotlib
- name: Run language usage script
env:
GITHUB_TOKEN: ${{ secrets.PAT_TOKEN }}
run: python app.py
結果をjsonファイルにまとめて、リポジトリを更新する。
生成したデータをGitHubリポジトリに保存し、常に最新の状態を維持するために、結果をJSONファイルとしてまとめてリポジトリにコミットします。このプロセスにより、言語使用データやその他の統計情報を視覚化したファイルを、外部から簡単に確認・再利用できるようになります。
# 言語ごとの詳細をJSONファイルに保存
def save_language_details(language_data, filename="language_details.json"):
# Counterをリストに変換してJSONに保存可能な形式に
formatted_data = {
language: {
"file_count": data["file_count"],
"max_steps": data["max_steps"],
"top_imports": data["import_counts"].most_common(5)
}
for language, data in language_data.items()
}
with open(filename, "w") as f:
json.dump(formatted_data, f, indent=4)
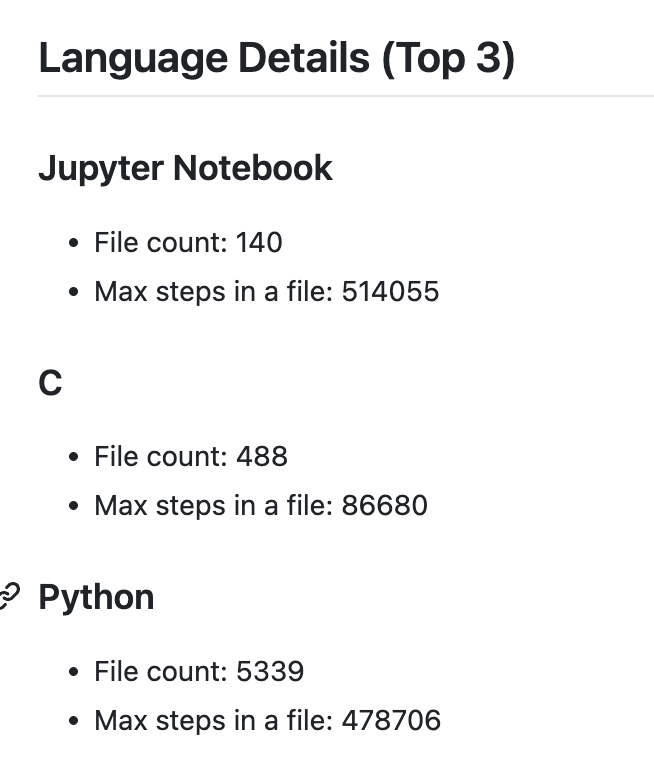
Readmeの更新
def save_readme(language_usage, language_data):
# 現在の日時を取得
update_time = datetime.now(timezone.utc).strftime('%Y-%m-%d %H:%M:%S UTC')
# トップ3の言語の詳細を追加
f.write("\n## Language Details (Top 3)\n")
top_3_languages = sorted(language_usage.keys(), key=lambda x: language_usage[x], reverse=True)[:3]
for language in top_3_languages:
data = language_data.get(language, {"file_count": 0, "max_steps": 0, "import_counts": Counter()})
f.write(f"\n### {language}\n")
f.write(f"- File count: {data['file_count']}\n")
f.write(f"- Max steps in a file: {data.get('max_steps', 'N/A')}\n")
改良前の問題点
初期実装では、GitHub Actionsの実行時にリポジトリの更新処理でエラーが発生!
特に以下のような状況でエラーが発生しました。同じ内容のJSONファイルを更新しようとすると、Gitが「変更がない」と判断してコミットがスキップされます。複数のWorkflowが同時に動作し、競合が発生します。
.ymlファイルに下記を追加することで解決
- name: Commit changes
env:
PAT_TOKEN: ${{ secrets.PAT_TOKEN }}
run: |
git config --local user.name "github-actions[bot]"
git config --local user.email "github-actions[bot]@users.noreply.github.com"
git add -A
git commit -m "Staging changes before rebase" --allow-empty
# リモートの変更を取得してリベース
git fetch origin main
git pull --rebase origin main
# 再生成されたファイルを追加
if [ -f language_usage.json ]; then git add language_usage.json; fi
git add README.md language_usage.png
# 変更がなくても常に新しいコミットを作成
git commit -m "Force update of README and image" --allow-empty || echo "Nothing to commit"
git push origin main || echo "Push completed or no changes to push"
参考サイト