はじめに
Haskellでニューラルネットを実装して、MNISTデータを学習してみました。
もともと日曜プログラマーでHaskellが好きなのと、深層学習が出版された頃買って読んでいたので、「いつか実装してみよう!」と思っていました。(そして3年もかかった)
機械学習の話題には興味があり、TensorFlowのチュートリアルもしてみたのですが、あんまり中で何をやっているかわからず、自分で実装して見ました。
機械学習で使用する言語はPythonが隆盛ですが、単にHaskellが好きなのでHaskellを使っています。
ニューラルネットの実装自体は、「深層学習」の第4章までを、そのまま記述しています。
その他参考にしたドキュメント等です。
ゼロから作る Deep Learning(以下「ゼロから作る〜」)(学習率等のパラメータ、およびミニバッチの抽出方法)
hmatrixの使い方とニューラルネットワークの実装例(内部で行列計算に使用するhmatrixパッケージの使用方法等)
HaskellでMNISTを使えるようにする(MNISTデータの読み込み等)
ありがとうございます。
なお、計算環境は1CPU、512MBメモリ、Ubuntu 14.04(Vagrant, VirtualBox)です。
実装等
処理の概要は以下の通り。
- 隠れ層が50ユニットの2層パーセプトロン
- 入力層のイメージデータは、MNISTデータを
/255したのみ、その他のクレンジングはなし - ラベルデータはMNISTデータをone-hot表現に変換
- 隠れ層の活性化関数はReLU
- 出力層の活性化関数はSoftMax関数
- 誤差関数をcross entropyとして誤差逆伝播法による更新量の計算
- SGDで、9600回(600ミニバッチ×16エポック)学習
1エポックの学習につき、おおよそ3分程度です。
以下は、プログラム中の誤差逆伝播計算のみ抜き出したものです。
type DataSet = [(Image, Label)]
type ParamSet = (W2, B2, W3, B3)
grad :: ParamSet -> DataSet -> ParamSet
grad (w2,b2,w3,b3) = foldr (sumParam . getParamDiff) acc
where acc = (0.0,0.0,0.0,0.0)
getParamDiff (img,lbl) =
-- forward propagation
let u2 = w2 #> img + b2
z2 = cmap activate u2
u3 = w3 #> z2 + b3
z3 = softmax u3
-- back propagation
d3 = z3 - lbl
d2 = cmap activate' u2 * (d3 <# w3)
dw3 = d3 `outer` z2
db3 = d3
dw2 = d2 `outer` img
db2 = d2
in (dw2,db2,dw3,db3)
最初はこれだけ組んで、ニューラルネットが計算式そのまま書けて見やすいやんと喜んでいました。ただし、いざ動かして見ると、思わぬところに障害があったのです......。
ハマったところ
データをランダムにピックアップできない
いきなりニューラルネットの話ではないですが、「ゼロから作る〜」では60000個のデータセットから、ランダムに100個のデータを抽出してミニバッチにしています。
同じようなことを実現する以下のようなコード
let miniBatch = (dataSet !!) <$> batchMask
-
dataSet: リストに格納したデータセット(60000要素) -
batchMask: 0~59999のランダムな数のリスト(100要素)
を実行すると、私の環境ではSegmentation Faultで落ちます。
おそらく、miniBatchを評価するときにdataSetを全走査する(=全部メモリに載せる)必要があるのが問題だと思いますが、Haskellで問題を解消する実装に到達できませんでした。
しょうがないので、Cでデータをシャッフル・コピーして、16エポック分(=960000個)のデータが格納されているファイルを再作成し、それを順繰りに100個ずつ読みこんでいます。
(create-mnist-data.cppがシャッフル用のCプログラムです。やっつけですw)
計算途中でSegmentation Faultする
計算の経過を見るために結果をprintしている時はなんともなかったのですが、いざ本計算をさせて見るとSegmentation Fault......
topして経過を見ると、急速にメモリ使用率が上昇していました。
printの手前でmodifyIORef経由で更新しており、そこが怪しいと思って色々原因を調べて見ると、あった。
[Haskell]僕が人生で起こした唯一のスペースリーク - あどけない話
どうやらmodifyIORefは評価が正格ではなく、どんどんサンクが溜まっていくらしい。
そのため、代わりに評価が正格なmodifyIORef'を使用すれば良いようです。
なお、記事には
単に新しい値で置き換えているだけだから、writeIORef で十分だ。
とありましたが、自分のコードでwriteIORefを使用している箇所も同じような問題が発生していて、まだ解決していません。(現状は、writeIORefの後にすぐ値の出力をしているので、Segmentation Faultは抑制されています。)
またニューラルネットとは関係ない話だった。
結果のプロット
誤差関数の値の時間変化と、エポックごとの訓練データ・推論データの認識率を描きました。
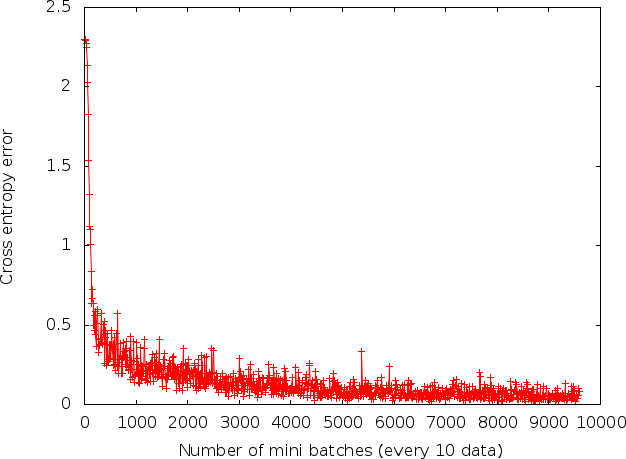
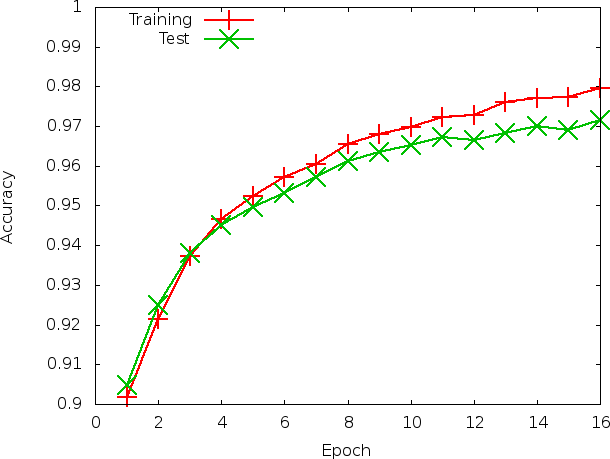
エポック数増やせばもう少し精度が出そうですが、一旦ここでストップしました。
過学習はしていなさそうですが、4エポック目くらいから徐々に訓練データと推論データの認識率が乖離しています(と言っても1%もないですが)。訓練データの情報はニューラルネットに含まれる一方、推論データは含まれないので、差が出るのは妥当と思われます。この辺りの評価方法も身につけたい。
所感
- (手慣れた言語だからかもしれませんが)実装自体はそんなに難しいことを考えなくてもできた気がします。特に、数式で書かれたモデルを殆どそのまま実装に落とし込めるのは素晴らしい。
- ただし、IOやらスペースリークやら課題はあるので、なんとかしたい。
- 現状、やって見た以上ではないので、自分で問題を設定して解析して見たいなー、と思います。
- とはいえ、モデルを実装することはまだまだ楽しいので、当面いろんなサンプルデータや有名なネットワークを実装して遊んでみようと思います。
- 誤差逆伝播法の箇所は、モナディックに実装したらもう少しスッキリするかもしれない。
以上です。