もくじ
- はじめに
- デモ
- OCRで文字列を取得
- Windowsの画面キャプチャを取得
- wxPythonでGUI作成
- pyinstallerでexe化
- 最後に
はじめに
youtubeを観ていて「広告をスキップ」ボタンを押すのが面倒くさいなと思い、自分でツールを作れないかなと考えてみました。
色々な方法が思い浮かびましたが、より人間の動きに近い実装方法が分かりやすいと思い、
OCRで文字認識を行い、指定箇所をクリックするというツールを作ることにしました。
結果、性能面での課題が多数残っていますが、おおよそ思い描いていたツールを作成することができました。
作成する際に学んだノウハウ等を書き留めておきます。
この記事が少しでも誰かのお役に立てれば幸いです。
デモ
exeファイル形式です。
自動でyoutubeの広告スキップリンクをクリックしてくれます。
OCRで文字列を取得
pythonからtesseractというソフトウェアを利用することでOCR処理を実現しました。
Windowsでpythonからtesseractを利用するためには、pip installではダメで、
モジュールをダウンロードしてパスを通す必要がありました。
具体的には下記の通りです。
# 環境変数PATHにTesseract(OCRツール)のパスを通す
os.environ["PATH"] += os.pathsep + os.path.dirname(os.path.abspath(__file__)) + os.sep + RESORSES_FOLDER_NAME
この部分はtesseractを利用するためにパスを通す部分です。
exe化の際に問題なく動作するよう、スクリプトがあるディレクトリのRESORSES_FOLDER_NAMEフォルダにパスを通しています。
このRESORSES_FOLDER_NAMEフォルダの中に、tesseractのモジュールを格納します。
# =========================
# OCR処理
# =========================
tools = pyocr.get_available_tools()
if len(tools) == 0:
wx.MessageBox('OCR tool is not installed on the terminal.\n端末にOCRツールがインストールされていません。', 'Error エラー')
sys.exit(1)
tool = tools[0]
dst = tool.image_to_string(
cap,
lang='jpn',
builder=pyocr.builders.WordBoxBuilder(tesseract_layout=6)
)
実際にtesseractで画像からテキストを取得している部分です。
パラメータは色々指定できるみたいですが、日本語を認識させるにはこのパラメータが良いとのことでした。
私も多少試してみましたが、結果的にこのパラメータになりました。
Windowsの画面キャプチャを取得
windows上で画面キャプチャを取得するためにwin32apiを利用しました。
pip installではインストールできず、別途win32apiをインストールする必要がありました。
また、マルチディスプレイに対応するために少し特殊な処理を行う必要がありました。
下記の方のソースコードが参考になりました。(というかほぼそのまま利用させてもらいました)
pythonで業務効率化/RPA自作 ? 検討 その5 マルチモニタ環境での画面全体の取得方法
# ==================================================================
# デスクトップのキャプチャ取得(マルチモニタ対応)
# 参考URLのコードをほぼそのまま利用しています。
#
# ref https://se.yuttar-ixm.com/multi-monitor-cap/
# ==================================================================
def get_capture(flag_gray: bool = True):
try:
# デスクトップ全体サイズ取得
vscreenwidth = win32api.GetSystemMetrics(win32con.SM_CXVIRTUALSCREEN)
vscreenheigth = win32api.GetSystemMetrics(win32con.SM_CYVIRTUALSCREEN)
vscreenx = win32api.GetSystemMetrics(win32con.SM_XVIRTUALSCREEN)
vscreeny = win32api.GetSystemMetrics(win32con.SM_YVIRTUALSCREEN)
width = vscreenx + vscreenwidth
height = vscreeny + vscreenheigth
# デスクトップのデバイスコンテキスト取得
hwnd = win32gui.GetDesktopWindow()
windc = win32gui.GetWindowDC(hwnd)
srcdc = win32ui.CreateDCFromHandle(windc)
memdc = srcdc.CreateCompatibleDC()
# デバイスコンテキストからピクセル情報コピー、bmp化
bmp = win32ui.CreateBitmap()
bmp.CreateCompatibleBitmap(srcdc, width, height)
memdc.SelectObject(bmp)
memdc.BitBlt((0, 0), (width, height), srcdc, (0, 0), win32con.SRCCOPY)
# イメージ取得/調整
img = np.frombuffer(bmp.GetBitmapBits(True), np.uint8).reshape(height, width, 4)
if flag_gray is True :
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 解放
srcdc.DeleteDC()
memdc.DeleteDC()
win32gui.ReleaseDC(hwnd, windc)
win32gui.DeleteObject(bmp.GetHandle())
return img
except Exception as err:
# 取得失敗
return None
wxPythonでGUI作成
もともとGUIは作成しようと考えていましたが、
今回は利便性やユーザビリティとは別に、GUIの作成が不可欠となりました。
理由は、tesseractによるOCR処理は全画面キャプチャといった大きい画像だと5秒~10秒ほど処理時間がかかってしまうことがわかったためです。
そこで、GUIでユーザーにキャプチャする範囲を指定してもらうことにしました。
# =========================
# ウインドウ設定ボタンクリック時処理
# =========================
def onclick_window_btn(self, event):
# 指定サイズの全画面キャプチャ画像取得
self.img = get_capture_img(CAPTURE_IMG_WIDTH)
# 表示用画像
self.img_copy = None
# window名設定
cv2.namedWindow(winname='img')
# マウスイベント設定
cv2.setMouseCallback('img', self.draw_rectangle)
# 画像表示
cv2.imshow('img', self.img)
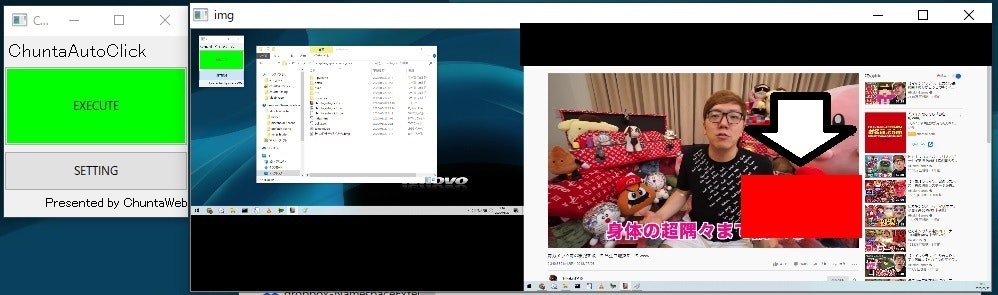
wx.MessageBox('Choose About Where Your Ads Appear.\n広告が表示される場所をアバウトに選択してください', 'Select advertising area 広告領域を選択')
# ==================================================
# 四角形を描画
# ==================================================
def draw_rectangle(self, event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
self.flg_drawing = True
self.ix, self.iy = x, y
elif event == cv2.EVENT_MOUSEMOVE:
if self.flg_drawing == True:
self.img_copy = self.img.copy()
self.img_copy = cv2.rectangle(self.img_copy, (self.ix, self.iy), (x, y), (0, 0, 255), -1)
cv2.imshow('img', self.img_copy)
elif event == cv2.EVENT_LBUTTONUP:
self.flg_drawing = False
self.img_copy = cv2.rectangle(self.img_copy, (self.ix, self.iy), (x, y), (0, 0, 255), -1)
cv2.imshow('img', self.img_copy)
if event == cv2.EVENT_LBUTTONUP:
global setting_value
# 右に行くほど増加
if self.ix < x:
left = self.ix
right = x
else:
left = x
right = self.ix
# 下に行くほど増加
if self.iy < y:
bottom = y
top = self.iy
else:
bottom = self.iy
top = y
setting_value.top = top
setting_value.bottom = bottom
setting_value.left = left
setting_value.right = right
画面キャプチャを表示し、画像上にマウスで四角形を描画させる処理です。
最終的に描画された四角形の座標を取得し、これをキャプチャの範囲とします。
# ==================================================
# auto_clickスレッド
# ==================================================
class auto_click_Thread(threading.Thread):
# =========================
# コンストラクタ
# =========================
def __init__(self):
super(auto_click_Thread, self).__init__()
# 呼び出し元が終了したらスレッドも終了するようデーモン化
self.setDaemon(True)
# =========================
# stop処理
# =========================
def stop(self):
global setting_value
setting_value.flg_stop = True
# =========================
# 実行処理
# =========================
def run(self):
global setting_value
setting_value.flg_stop = False
txt = setting_value.txt
min_interval_time = setting_value.min_interval_time
top = int( setting_value.top * (1 / setting_value.rate) )
bottom = int( setting_value.bottom * (1 / setting_value.rate) )
left = int( setting_value.left * (1 / setting_value.rate) )
right = int( setting_value.right * (1 / setting_value.rate) )
click_text(txt, min_interval_time, top, bottom, left, right)
# ==================================================
# スタート
# ==================================================
def start():
global exec_thread
global setting_value
exec_thread = auto_click_Thread()
exec_thread.start()
# ==================================================
# ストップ
# ==================================================
def stop():
global exec_thread
exec_thread.stop()
GUIからOCR処理を呼び出す部分です。
GUIがビジーにならないようスレッドキックする形にしていることに加えて、
親がkillされた場合に子もkillされるよう、デーモン化しています。
つまり、GUIを終了させた際にバックグラウンドでOCR処理が走らないようにしています。
また、スレッドを直接killすることは難しいため、
ストップ処理はOCR処理が参照するグローバル変数の値を変更する形で実装しました。
pyinstallerでexe化
通常のexe化だけでは、ユーザーがtesseractをインストールする必要があります。
これだとさすがに面倒なので、インストールしなくても利用できるようにしました。
# 環境変数PATHにTesseract(OCRツール)のパスを通す
os.environ["PATH"] += os.pathsep + os.path.dirname(os.path.abspath(__file__)) + os.sep + RESORSES_FOLDER_NAME
ここは前述した部分と重複しますが、スクリプトと同じフォルダ上にあるRESORSES_FOLDER_NAMEフォルダにパスを通す処理です。
exe化した後にexeファイルのフォルダ上にRESORSES_FOLDER_NAMEフォルダを作成し、ここにtesseractのモジュールを格納します。
余談ですが、pyinstallerの--onefileによる1ファイルのexe化も試してみましたが、起動に1分以上かかってしまうために辞めました。
pyinstaller --clean --icon=chunta_auto_click.ico -n chunta_auto_click chunta_auto_click.py --noconsole
上記はexe化した際のコマンドです。
最後に
性能面での課題が多数残っていますが、おおよそ思い描いていたツールを作成することができました。
私のようなそこら辺の人間でも、ネットで情報収集すれば気軽にOCRライブラリを利用できる良い時代になったと痛感しました。
この記事が少しでも誰かのお役に立てれば幸いです。