本ページの狙い
Ⅰ:自治体のオープンデータ化における現場データの闇
Ⅱ:なるべく管理しやすいアーキテクチャ
Ⅲ:スパゲッティ化しないリーダブルコーディング例
の3点です。
※Japanese Community for Open and Reproducible Science (JCORS)のアドベントカレンダー2019年12月24日として書いてみます(遅れてすいません)。
自己紹介
髙岡昂太(@chronologic1)と申します。臨床心理士、公認心理師、司法面接士。心理学系+児童福祉系の研究と技術開発をしています。特に、子どもの虐待や性暴力、DVなどに関する行政関係のディープなデータに対して、機械学習やベイズ統計、GISを多職種チームメンバーと行っています。また、週1日程度ですがトラウマや発達障害に対するCBTやアセスメント、家族支援をしています。
動機
もともと子どもの虐待対応において、エビデンスに基づく政策決定(EBPM)を行うにあたり、コストベネフィットの推定をオープンデータを用いてしたかったのですが、そもそもオープンデータに必要なデータ自体を「作っていく」作業が必要でした。
ですが、それをするには、大きな闇が隠されていました。
オープンサイエンスにする前に、オープンデータを作るのは誰なのか?という点です。現場のデジタルデータから個人情報を除き、Tidyに整形するのが、自治体の統計局ならいいのですが、そもそも現場にはデジタル化されていないデータがたくさんあります。それをただでさえ忙しい、現場の職員さん達が作ってというのはとても難しい背景があります。
そのため、児童福祉分野のオープンサイエンスには、オープンデータを創るというよりも以前に、デジタルデータ化するというデジタルトランスフォーメーション(DX)から必要です。
たとえて言うと、料理を作る前に、食材を作る農業から、ではなく、農地を作る土木・灌漑作業から、といったところでしょうか。
実際、このあたりの課題を解決してきたのは、エストニアのX-roadという仕組みです。エストニアでは、全自治体のDBをAPIを通して、リアルタイム共有プラットフォームを参照していました。
アーキテクチャについては全くの専門外なので、尊敬するベテランエンジニアの”Oさん”に教えを請いました。今回は、そこで僕自身が学んだことを皆さんと共有できればと思いました。
エンジニア・開発者側としてはごく普通のナレッジかもしれませんが、研究業界ではまだあまり馴染みのない内容かと思います。今後、R&Dに絡むオープンサイエンスでは必須知見になりうるものかなぁと感じています。
Ⅰ:自治体のオープンデータ化における現場データの闇
現場データの闇
何が闇なのか、その一端をお送りします。
■紙データのプレゼンス
・基本、最も意味のある経過記録部分は紙で管理されている(ことも多い)
・現場職員は、他機関と情報共有する時には、紙ファイルをFAXで送信、または手渡し。受信者はFAXに書かれた文字をWordで再度打つというデジタルトランスフォーメーション(DX)以前の状況
■紙から神へ
・デジタル化されていたとしても、謎の結合がされまくった神Excel
・csvであってもエンコード問題(Shift-JISで外字、CR、LF、CR+LFなどなど)
■DBに関するベンダーあるある
・児童相談業務の同様のデータ項目を扱っているはずだが、自治体毎にスクラッチ開発しているので、同じベンダーであってもデータ構造がバラバラ(おーい)。
・データ型が年齢列でintではなく、chrとなっているものもある(まさか漢数字を許容するのか?)など、謎の多いDB設計
・そもそもベンダーにER図がない(そんなDBある!!?あるんです)
■省庁へのデータ報告はおばちゃん達の電卓計算
・自治体から省庁への報告は、正規職員よりも非正規職員のおばちゃんが電卓で作成し、そのノウハウが伝承されること自体が難しく、そのおばちゃんが退職・休職された時点で、いろいろ詰むという現場も存在します。
あくまで上記は一例ですが、このような状況が自治体データにはあります。
(ここにはtidyverse教の教えは普及していないのです)
省庁通達というポーネグリフ
なぜ、そのような状況があるかというと、各省庁の通達という書類が一因です。例えばですが、児童相談業務の中で児童養護施設などに児童を措置した際にいくらくらい国から補助(コスト)が掛かっているのかということを知りたいとします。そのような時に以下のような厚労省通達を読み解く必要があります。
児童福祉法による児童入所施設措置費等国庫負担金について
http://zidonet.org/wp/wp-content/uploads/2018/12/dd87d837afb0f0450d56eec1871c112c.pdf
中を読んでみると、養護施設などの運営費用に関する国庫負担金の条件が書いています。とても大事な情報が詰まっているのですが、まず問題なのは、慣れても「読みにくさ100点満点」であること。
さらに、読んでいる途中で一つ前の通達を読まないと文章が理解できない文章があります。また、実際にコストを算術するには、昭和に制定された関連する法律や金額計算を参照しないと意味が分からないものなど、読み手への配慮が全くない文書です。他にも、後ろの方のページには費用負担の金額テーブルがこれでもかと載っています。
ポーネグリフ解読に必要なスキル例
上記のような通達について、比較的分かりやすい部分を抜粋してみます。
第4 各月の支弁額の算式及び支弁の方法 (※筆者注:上記URL12ページ)
1 地方公共団体の支弁義務
地方公共団体は、法第50条第6号、第6号の2、第7号、第7号の3、第8号、第51条第3号及び第5号の規定によりその施設等に対し、2及び3に定めるところにより算定した事務費及び事業費の費目の種類ごとの支弁額を合算した額を、その月の措置費等の支弁額として支弁しなければならないこと。
ただし、保育の措置については、第3の1のただし書きに掲げる費用について定めるところにより算定した額を支弁しなければならないこと。
2 措置費等の費目の使途及び各月の支弁額の算式
児童養護施設、児童自立支援施設、児童心理治療施設、乳児院、母子生活支援施設、助産施設、自立援助ホーム、ファミリーホーム、里親又は一時保護所に対する措置費等の費目の種類は、次表第1欄に掲げるとおりとし、それぞれの費目の種類ごとの支弁対象児童等、その経費の使途及びその各月の支弁額の算式は、同表の第2欄から第4欄に掲げるとおりとすること。
3 定員外支弁の禁止 (※筆者注:こちらは表より筆者が追記しています)
事業費の各種目ごとの支弁額の算定に用いる措置人員の数には、やむを得ない特別の理由がある場合を除いては、その施設の定員を超える部分は算入しないものとすること。
読んで頂いてわかるように、コーディングするとなると、
1 地方公共団体の支弁義務の中には、「ただし、保育の措置については、第3の1のただし書きに掲げる費用について定めるところにより算定した額を支弁しなければならないこと。」という部分が、最初のif文条件に来て、その判定により、
「2及び3に定めるところにより算定した事務費及び事業費の費目の種類ごとの支弁額を合算した額を、その月の措置費等の支弁額として支弁しなければならない」
と続きます。まずif文判定の読み取りスキルが必要です。
次に「2 措置費等の費目の使途及び各月の支弁額の算式」の中で、各養護施設などにより、支弁額の算式は「同表の第2欄から第4欄に掲げるとおり」となっているので、同表の第2欄から第4欄をテーブルまたはリストで持っておき、読み込む関数を作る必要があるかもしれません・・・。文字からテーブル設計というスキルが必要です。
さらに次の3で、「同表の第2欄から第4欄の中に事業費の各種目ごとの支弁額の算定に用いる措置人員の数には、やむを得ない特別の理由がある場合を除いては、その施設の定員を超える部分は算入しないものとすること。」という記載があります。
お役所文書あるあるでなるべく広く解釈できるようにという温かい配慮として「やむを得ない特別の理由がある」という文言ですが、この段階で、コーディングを行うには「やむを得ない特別の理由」の定義と、その条件の宣言が必要となりますが、どこにもその定義は明記されていません。
実は、各自治体で特別な理由の定義が違うので、その定義を許容する設計にしておく必要が生じます。コーディング技術というより、むしろ文脈を読んだり、担当者に聞きに行くというコミュニケーションスキルまでが求められます。
また、そもそもの前提として、この第3パラグラフの特別の理由があるかどうかが最初の条件分岐にあたるため、1,2のコーディングよりもif文の第1行にこなければなりません。
たったこの3パラグラフだけで、バリエーションが沢山あるのがおわかり頂けたと思いますが、さらに施設別、土地柄特性別、厚労省指定自治体別、ボイラー使うかどうかなど、条件分岐が項目分だけ増えていきます。
さらに、この通達内容がほぼ毎2,3年で全更新されていきます・・・。
算術はほぼほぼ和積で済むのですが、パターンが五万とあるのが、ポーネグリフ解読における課題です(これを自分の自治体の必要な箇所だけ丸暗記し、暗黙知として電卓叩くおばちゃんはすごい!)
ただ、ここを乗り越えないと、EBPMどころか、オープンサイエンス、はたまたオープンデータにも行き着きません。
Ⅱ:なるべく管理しやすいアーキテクチャ
では、どのように頻繁に変更されるDBについて、アーキテクチャの設計をするべきでしょうか?以下にポイントをまとめます。
変更に強いプログラムとは?
• 変更要求が入ったときに「バグを作りこみにくい」つくりにしているということ。
• 大事なのは変更後の正しい結果を返すことよりも、間違った結果を返さないことを重視する姿勢。
• 例: 条件変更の際、何か所直さなければならないか?1か所忘れたら何が起こるのか?
即ち、「定数(テーブル自体を更新することも含む)を設定すればよい」という考え方は安易かもしれません。なぜならば、テーブルの各種記載自体も通達で更新されるため、定数を読み込めばよい、という設計自体が柔軟性に欠いてしまうためです。
〇階層アーキテクチャの設計例
先ほどのURLにおいて、せっかくなので心理系として、(20)心理療法担当職員加算分保護単価(常勤的非常勤・非常勤単価)取得処理(上記URL80・81ページ)を見てみましょう。
例えば、毎日働いている非常勤の心理療法担当職が、母子生活支援施設で働いている場合を考えてみましょう。
通達文書を読み解くのを省略するため、概要としてポイントだけまとめます
心理療法職員の非常勤への加算分は、
・施設にいる定員は何人か?
・処理された対象年月日はいつか?
・施設の種別は何か?
になります。
これらを階層構造として設計すると、以下のようになります。
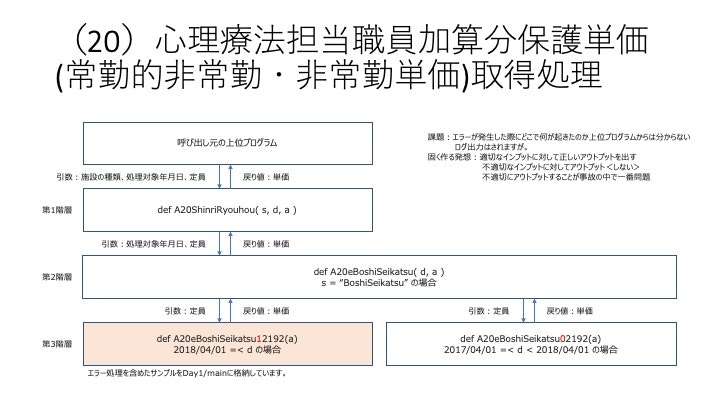
固く開発するためには心得ておくことは
・適切なインプットに対して正しいアウトプットを出す
・不適切なインプットに対してアウトプット<しない>
・不適切にアウトプットすることが事故の中で一番問題
なぜならば、もし出力されたデータが間違っていると、データの一貫性・信頼性を失いますし、何がコーディング上問題だったのかが分かりません。
そのため、正常ケースと異常ケースを予め設定しておくことが重要となります。
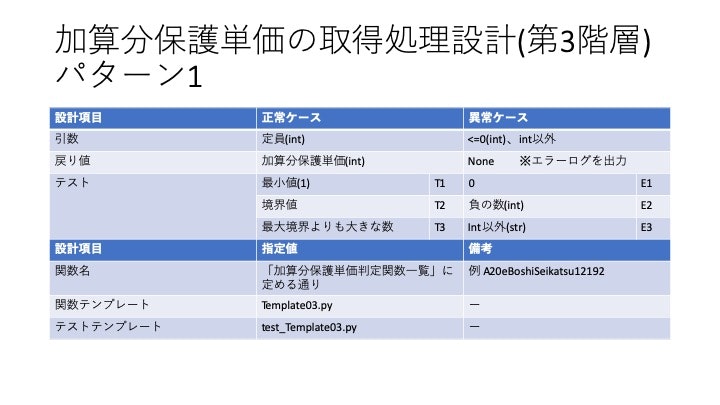
(ネーミングについてもある程度の一貫性が必要です。
参考:https://qiita.com/Kunikata/items/0337c6744a7c8fbc1586 )
設計のポイント
・通知の該当箇所の文章を抽出。(もれなく該当箇所を抜き出せるか?)あまりおおざっぱな抽出ではなく、電卓で計算できる粒度まで特定。
・抽出した文章から、プログラムで使用する「変数」を抽出する。何が引数としてインプットされるもので、何を戻り値としてアウトプットされるものであるかまで明確にする。判定のためのフラグがある場合は、それも抽出する変数に含むものとする。
・何をいつ判定する必要があるか検討する。(これが処理フローの骨組み)
Ⅲ:スパゲッティ化しないリーダブルコーディング
コーディングには様々な考え方があり、あくまでここは僕自身が現在Oさんに教えてもらった考え方です。ただ、可読性が高く、正確なデータを出力するためにも、バグが出にくい方向を重要視するため、以下のような内容をご紹介します。
リーダブルコードの一案
Ⅱで触れたように、様々なパターンが多いと、データサイエンティストとしてはまりがちなのが、If文を幾重にも重ねるネスト構造です。ネスト構造は可読性が下がり、バグの原因となりやすくなります。
では、ネスト構造を割けるにはどのようにすればいいのでしょうか?
例としてpython3で解説します。
よくあるif文構造は以下のようなものだと思います。
’’’
• if x != y:
print("xとyは別の値です。")
else:
print("xとyは同じ値です。")
• if x == 100:
print('x = 100’)
elif x == 200:
print('x = 200’)
else:
print('条件を満たしていません’)
ただ、このようなオーソドックスなelse, elif構造は、ネスト化しやすく、今回のように単純にパターンが多いときは可読性が下がってしまいます。
そのかわり、コーディングとして、以下のように、上からコードを走らせ、条件に合致した場合のみ、returnを返すという書き方でシンプルにし、それ自体を関数化したほうが可読性、再現性があがります。
(20)心理療法担当職員加算分保護単価(常勤的非常勤・非常勤単価)
エ 母子生活支援施設(常勤的非常勤職員)
平成30年12月19日厚生労働省発子1219第2号
平成30年4月1日から適用(2018/04/01~)
引数aは定員。定員に応じた月額単価を返却する関数。
以下では、
def A20eBoshiSeikatsu12192(a):
#aの大きさを判定
if 1 <= a <= 10:
#判定結果がTrueならば、bに値を代入
b = 28370
#標準出力にbの値を出力
return(b)
if 11 <= a <= 20:
b = 14180
return(b)
if 21 <= a <= 30:
b = 9450
return(b)
if 31 <= a <= 40:
b = 7090
return(b)
if 41 <= a <= 50:
b = 5670
return(b)
if 51 <= a:
b = 4720
return(b)
変数aに値を代入
a = 10
関数 A20eBoshiSeikatsu12192 を呼び出し
print(A20eBoshiSeikatsu12192(a))
### ログの出力
このあたりも再現性の中ではとても大切にされている分野ですが、通常の心理統計やデータサイエンスではあんまりカバーされていないところなので、まとめてみます。開発だけでなく、機械学習やベイズ周りでも、ログ出力はコーディングが上手くいかない時に予め仕込んでおけると、デバッグがしやすくなります。
ログ出力の設計思想のポイント
• ログ出力の一貫性を重視する。ログ出力に関する個別の作りこみは禁止。
• コーディングミスの影響最小化のために「 import logging」は禁止。(from logging import ~ で、オブジェクトを明示的に指定)
logger.error(“Hello World!”) のみ許し、
logging.error(“Hello World!”) は拒絶される(エラーになる)ようにしておく。
※python環境のログにおいても、loggingがよく触れられていますが、じつはloggerの方が使いやすいです。
参考:ログ出力のための print と import logging はやめてほしい
https://qiita.com/amedama/items/b856b2f30c2f38665701
### 今回触れていない部分
開発においてはテスト自体もログ出力と合わせて組み込むことが効率的です。特にPython3では、pytestという便利な一括テストができるプログラム、またtkinterというリアルタイムに入出力をGUIでテストできるプログラムが標準的にカバーされていて便利ですが、このあたりは今回触れていません。
### まとめ
いかがでしたでしょうか?
オープンサイエンスにしたいけど、おそらくオープンデータすら出来ない、しにくい分野も多々あるかと思いますが、今後様々な研究者や企業、スタートアップがオープンデータを公開していくことで、その領域のEvidence Informed Approachが進むと期待されます。
私自身も子どもの安全・安心な社会を作っていくために、現場データのオープンサイエンスを目指して少しでも貢献できればと思っています。
ここまでお読み頂き、ありがとうございました。
謝辞:エンジニアOさんに心から御礼申し上げます。