前置き
この記事を書いているのは、RDBMSすらろくに扱ったことの無いド素人なので、内容はあまり鵜呑みにしないでください。ご指摘は大歓迎です。
グラフDBとは
グラフ構造(有向グラフ)を格納するのに特化したデータベースのことです。一番有名なものだと Neo4j、その他にはAmazon Neptune、ArangoDBなどがあります。
グラフDBのなにがうれしいの?
グラフから情報を取り出すことに特化したクエリ言語(RDBMSにおけるSQL的なもの)を備えているので、自分でいちいちアルゴリズムを組まなくてもよくなります。
JanusGraphって何?
Linux Foundationの元で開発されているオープンソースのグラフDBです。元はTitanGraphという名前の個人プロジェクトでしたが、そこからforkされ開発が続けられています。2017年4月にversion0.1がリリース、2020年3月にversion0.51がリリースされています。
Apache TinkerPopというグラフコンピューティングフレームワークの上に乗っかる形で提供されています。
ライセンスはApache 2 Licenseです。
JanusGraphのいいところ
- バックエンドのデータベース(データの保存先)として
Apache Cassandra,Apache HBase,Berkeley DBなどが選べる。ちょっと試してみる分にはBerkeley DBを選ぶのが非常に楽で、がっつり使う目的でスケーラブルな構成にしたい場合はCassandraを使う、というようなことができます。 - クエリ言語の
Gremlinは他のグラフDB(Neo4j, Amazon Neptune, Azure Cosmos DB)などでも使用できるため、JanusGraphを後々捨てたとしても完全に無駄にはならないかも。 - Dockerイメージ提供あり。まあ、今時のDBでDocker対応していないのも少ないかとは思いますが……。
- Windowsでも問題なく動かせます。
とりあえず試してみる(ダウンロード版)
ひとまず、実際に動かしてみることにします。
JVM
JanusGraphはJavaで書かれているため、Java 8のインストールが必要です。持っていない人はOracleなり、OpenJDK(AdoptOpenJDK, Amazon Corretto)なりでインストールしてください。
ダウンロードする
公式サイトではzipによるアーカイブと、Dockerイメージによる2種類の導入方法が用意されていますが、まずはzipアーカイブによる導入を試してみます。
ダウンロードページからjanusgraph-0.5.1.zip(2020年4月現在の最新版)をダウンロードします。
curl https://github.com/JanusGraph/janusgraph/releases/download/v0.5.1/janusgraph-0.5.1.zip
unzip janusgraph-0.5.1.zip
JanusGraphのルートディレクトリの内容は以下のようになっています。
今回の記事内で直接触れるのはbinディレクトリとconfディレクトリだけです。後は無視します。

binディレクトリの中身では上のものを使用します。Windowsの場合は*.batを、Linuxの場合は*.shを使います。
Gremlinコンソールの立ち上げ
JanusGraph(というよりはその土台となったTinkerPop)では、グラフDBサーバーと接続としてのデータのやり取りや、クエリの実験用として、Gremlinコンソールと呼ばれるコンソール環境が用意されています。
この環境はJavaの派生言語のGroovyで動作します。が、特にGroovyを知らなくても問題なく扱えます。
JanusGraphのルートディレクトリ上でgremlin.sh(Windowsの場合はgremlin.batを実行してコンソールを立ち上げます。
$ bin/gremlin.sh
> bin\gremlin.bat
以下のようにgremlin>というプロンプトとが表示されればOKです。
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/C:/******/janusgraph-0.5.0/lib/slf4j-log4j12-1.7.12.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/C:/******/janusgraph-0.5.0/lib/logback-classic-1.1.3.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
plugin activated: tinkerpop.server
plugin activated: tinkerpop.tinkergraph
15:55:46 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
plugin activated: tinkerpop.hadoop
plugin activated: tinkerpop.spark
plugin activated: tinkerpop.utilities
plugin activated: janusgraph.imports
gremlin>
現状ではグラフDBサーバーは立ち上がっていませんが、この状態でもいろいろ試すことができます。
Gremlinコンソールのより詳しい使い方については公式の情報を参照してください。また、以下の記事に豆知識をまとめました。
グラフの生成(練習用)
組み込みの練習用グラフを生成して、クエリ言語Gremlinを使ったクエリを行ってみます。
以下のコマンドを入力します。
gremlin> graph = TinkerFactory.createModern()
以下のように応答が返り、グラフが作成されます。
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
これは図のようなグラフです(Apache TinkerPopのドキュメントより)。
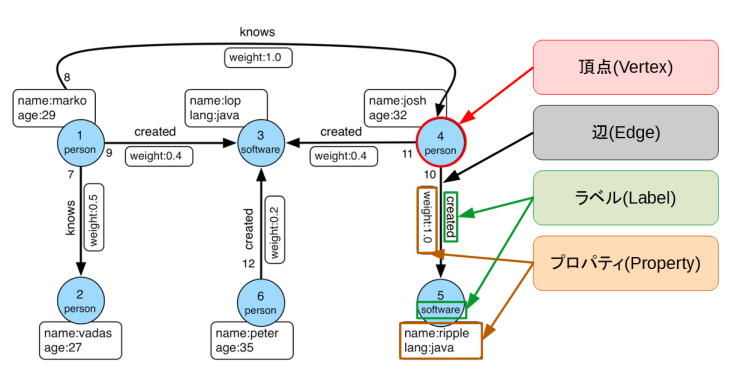
開発者と開発言語のリレーションを表したグラフになっています。頂点と辺がそれぞれ6つずつあるグラフです。それぞれの頂点と辺は1つのラベルとN個のプロパティを持つことができる仕様です。
頂点のラベルにはpersonとsoftwareの2種類があり、プロパティはname,age,langの3種類があります。
辺のラベルにはcreated,とknowsの2種類があり、プロパティはweightの1つのみです。なお、頂点と辺にそれぞれ付いている数字はIDを表しています。
GraphとTraversalSource
今作成したgraphは、JanusGraph(TinkerPop)におけるGraphというクラスから派生しています。このクラスは主にグラフ固有の各種設定を参照/変更するために使用します。グラフの頂点や辺のデータの編集機能も備わっていますが、これを直接操作することはほとんどしません。
グラフに対するクエリはGraphTraversalSourceという走査(Traversal)のためのインターフェースを介して行います。以下のようにして獲得します。
gremlin> g = graph.traversal()
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
基本的にこのgを介してデータの追加/変更/クエリを行っていきます。gの名前は好きに変えても構いませんが、一般的にこの名前を用います。
基本的なクエリ
ようやくですが、準備が整ったので、クエリを試してみます。
ひとまずここでは簡単なクエリの仕方の解説に留めますので、詳しいGremlinの操作方法については、TinkerPopドキュメントをご覧ください。全編英語で相当なボリュームですが、これを読まないと実用は辛いところですね。
- Apache TinkerPop Getting Started: チュートリアル
-
TinkerPop Documentation: リファレンス
- The Graph: グラフの各要素(頂点/辺/ラベル/プロパティ)について
- The Traversal: 各種走査方法についての説明
頂点/辺/プロパティへのアクセス
説明する基本的な操作は以下の7つです。
| 走査名 | 説明 |
|---|---|
| V([id, ...]) | 頂点(Vertex)を選択する |
| E([id, ...]) | 辺(Edge)を選択する |
| has(property_name, value) has(label_name, property_name, value) |
特定の値のプロパティを持っている要素(Element)※1を選択する |
| hasLabel(label_name) | 特定の値のラベルを持っている要素を選択する |
| values([property_name, ...]) | 要素の持っているプロパティの値を列挙する |
| valueMap([property_name, ...]) | 要素の持っているプロパティの値をMap形式※2で取得する |
| id() | 要素の持っているIDの値を取得する |
※1 JanusGraph(TinkerPop)ではVertexとEdgeをひっくるめてElementと呼びます。
※2 言語によっては連想配列といったり、辞書と言ったり、ハッシュマップと言ったりするアレ
最初に、すべての頂点を取得してみます。
gremlin> g.V()
==>v[1] // 結果の中身が頂点(Vertex)の場合は v[ID]の形で表示される
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
頂点が6個あり、それらが全て列挙されています。Vはグラフの要素から頂点(Vertex)だけに絞り込むための命令です。括弧内にIDを指定することで、そのIDがついた頂点だけを選択することもできます。
gremlin> g.V(2, 4)
==>v[2]
==>v[4]
[]の中には頂点を識別するためのIDが表示されていますが、これだと分かりづらいですね。次は、頂点が持っているプロパティから、名前(name)を取得してみます。
gremlin> g.V().values("name")
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peter
Gremlinによるクエリでは、このようにメソッドチェーンでどんどん後ろに書き足していくことによって、データを絞り込んだり、効果を波及させることができます。valuesはSQLでいうところのSELECTに相当します。valuesの引数に何も与えないと、全てのプロパティを取り出します。
gremlin> g.V().values()
==>marko
==>29
==>vadas
==>27
==>lop
==>java
==>josh
==>32
==>ripple
==>java
==>peter
==>35
これだと戻ってきた結果が構造化されてなくて使いづらいかもしれません。valueMapというのもあります。こちらは全部のデータをハッシュマップ(辞書)にまとめてくれます。結果の返り方が違うだけで使い方は同じです。どちらが良いかは目的次第でしょうけれど。
gremlin> g.V().valueMap()
==>[name:[marko],age:[29]]
==>[name:[vadas],age:[27]]
==>[name:[lop],lang:[java]]
==>[name:[josh],age:[32]]
==>[name:[ripple],lang:[java]]
==>[name:[peter],age:[35]]
プロパティの情報をもとに要素(頂点あるいは辺)を絞り込むにはhasを使用します。
gremlin> g.V().has("name", "josh") //nameがjoshである頂点を探す
==>v[4]
gremlin> g.V().has("name", "josh").valueMap()
==>[name:[josh],age:[32]]
ラベルで絞り込むにはhasLabelを使用します。
gremlin> g.V().hasLabel("person").valueMap("name", "age")
==>[name:[marko],age:[29]]
==>[name:[vadas],age:[27]]
==>[name:[josh],age:[32]]
==>[name:[peter],age:[35]]
ラベルとプロパティ両方で絞り込みたい場合は3引数のhasが用意されています。
gremlin> g.V().has("person", "name", "josh").valueMap("name", "age")
==>[name:[josh],age:[32]]
ここでは文字列の一致だけを説明しましたが、hasは他にも文字列の部分一致や数値の大小比較など、様々な条件によるフィルタリングを行うことができます。詳しくはリファレンスのHas-Stepを参照してください。
ところで、valueMapの値がそれぞれ[]で囲まれててなんか気持ち悪いと思うかもしれません。頂点や辺は同じ名前のプロパティを複数持てる仕様なので、リストが返ってくるのは当然っちゃ当然なのですが、1つしか持たないという前提の運用であれば、以下のようにして括弧を外すことができます(byとunfoldについてはここでは解説しませんが)。
gremlin> g.V().has("name", "josh").valueMap().by(__.unfold())
==>[name:josh,age:32]
注意: gremlinコンソール上では__.は省略してもOKです(後で説明するPythonでは必要です)。
次はIDの値を取ってみます。これは非常に簡単で、idを使用します。
gremlin> g.V().has("name", "marko").id()
==>1
次に辺(Edge)についても同様に絞り込み方を確認します。辺の場合はEを用います。
gremlin> g.E()
==>e[7][1-knows->2]
==>e[8][1-knows->4]
==>e[9][1-created->3]
==>e[10][4-created->5]
==>e[11][4-created->3]
==>e[12][6-created->3]
頂点の場合より情報が多いですが、これはgremlinコンソールが勝手に表示してくれているので、実際には自分で手繰る必要があります。
辺の場合も頂点と同様にhas,hasLabel,valuesなどを使うことができます。
gremlin> g.E().has("weight", 1.0)
==>e[8][1-knows->4]
==>e[10][4-created->5]
gremlin> g.E().hasLabel("created")
==>e[9][1-created->3]
==>e[10][4-created->5]
==>e[11][4-created->3]
==>e[12][6-created->3]
gremlin> g.E().values()
==>0.5
==>1.0
==>0.4
==>1.0
==>0.4
==>0.2
頂点と辺の簡単な走査
情報にアクセスする基本的な操作は分かったと思うので、次は頂点と辺で構成されるグラフを辿っていく方法について説明します。
クエリした対象が頂点か辺かでそれぞれ行うことのできる走査が変化します。
頂点に対する走査
| 走査名 | 説明 | 結果の種類 |
|---|---|---|
| outE() | 頂点から出ている辺の取得 | Edge |
| out() | 頂点から出ている辺の先の頂点の取得 | Vertex |
| inE() | 頂点に入ってくる辺の取得 | Edge |
| in() | 頂点に入ってくる辺の元の頂点の取得 | Vertex |
| bothE() | 頂点に対してつながっている辺の取得。方向不問 | Edge |
| both() | 頂点に対してつながっている頂点の取得。方向不問 | Vertex |
辺に対する走査
| 走査名 | 説明 | 結果の種類 |
|---|---|---|
| outV() | 辺につながっている元の頂点の取得 | Vertex |
| inV() | 辺につながっている先の頂点の取得 | Vertex |
辺の情報が必要な場合はinE,outE,inV,outV,bothEを使って頂点と辺を交互に辿っていきます。逆に辺の情報が必要ない(頂点どうしのつながりだけ見ればよい)場合はout,in,bothを使って頂点を渡っていくことができます。
gremlin> g.V(1).outE() // 頂点1から出ている辺
==>e[9][1-created->3]
==>e[7][1-knows->2]
==>e[8][1-knows->4]
gremlin> g.V(1).outE().outV() // 来た方向(頂点1)に戻る(無意味)
==>v[1]
==>v[1]
==>v[1]
gremlin> g.V(1).outE().inV() // 頂点1の先にある頂点を選ぶ
==>v[3]
==>v[2]
==>v[4]
gremlin> g.V(1).out() // outは outE&inVとイコール
==>v[3]
==>v[2]
==>v[4]
gremlin> g.V(4).both()
==>v[5]
==>v[3]
==>v[1]
outEとinV, inEとoutVはセットということを覚えておけば特に混乱せずに扱えるかと思います。
経路の取得
pathを使うと、それまでの走査で辿ってきた経路を順に出力することが可能になります。
gremlin> g.V(1).out().out().path() // 頂点1(marko)から2つ先に進める経路
==>[v[1],v[4],v[5]] // 順にv(1)の結果、out()の結果、out()の結果
==>[v[1],v[4],v[3]]
gremlin> g.V(1).out().out().values("name").path() // 順に出力されるのは頂点や辺に限らず、プロパティ等も例外ではない
==>[v[1],v[4],v[5],ripple] // 順にv(1),out(),out(),values()の結果
==>[v[1],v[4],v[3],lop]
gremlin> g.V(1).out().out().path().by("name") // 頂点が返ってくるところを特定のプロパティに置き換えたい場合はbyを用いる
==>[marko,josh,ripple]
==>[marko,josh,lop]
2つ先の頂点を取るのにout().out()などと書きましたが、10個先の頂点を取るのに同じ書き方ではダサすぎます。そんな場合はrepeatとtimesを用います。
gremlin> g.V(1).repeat(__.out()).times(2).path()
==>[v[1],v[4],v[5]]
==>[v[1],v[4],v[3]]
前にも出てきましたが、この__は特別な名前空間で、走査名と同じ名前の様々な関数が用意してあります。これを呼び出した返り値を走査に渡すと、その名前に応じた処理を行わせることができます。例えば上記のようにrepeat走査に__.out()を渡すとoutを複数回繰り返してくれます。__.in()を渡せば逆向きに繰り返してくれます。TinkerPopではこれをanonymous traversal(参照)と呼んでいます。デザインパターンで言うところのStrategyパターンと言えばわかりやすいでしょうか?
データの追加(頂点/辺/プロパティ)
Gremlinではデータの追加も当然できます。
| 走査名 | 説明 |
|---|---|
| addV(label_name) | 頂点(Vertex)を追加する |
| addE(label_name) | 辺(Edge)を追加する |
| property(property_name, value) | プロパティを追加・更新する |
| drop() | 要素またはプロパティを削除する |
頂点を追加する場合は次のようaddVを使用します。
gremlin> g.addV("person")
==>v[13]
gremlin> g.V()
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
==>v[13] //追加されている
辺を追加するにはaddE,from,toを使用します。
g.addE("knows").from(g.V(1)).to(g.V(13))
==>e[14][1-knows->13]
辺にはその両端になる頂点を指定しなければなりません。
fromの中に辺の元になる頂点を、toの中に辺の先になる頂点を指定します。
プロパティを設定するにはpropertyを使用します。
gremlin> g.V(13).values()
gremlin> g.V(13).property("name", "bob").property("age", 33)
==>v[13]
gremlin> g.V(13).values()
==>bob
==>33
頂点や辺、プロパティについて、不要になった場合、dropで削除することができます。
gremlin> g.V(13).properties("name").drop()
gremlin> g.V(13).values()
==>33
gremlin> g.V(13).drop()
gremlin> g.V()
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
propertiesはここまで紹介していませんでしたが、要素からプロパティを取り出す命令です。プロパティに対してはkey(プロパティ名を取り出す)、value(値を取り出す)やdrop(削除する)などの命令を実行できます。
より高度なクエリについて(ミニQ&A集)
ここで述べた機能はGremlinのほんの一部であり、より複雑で繊細なクエリを行う方法が用意されていますが、それだけで記事が何本かかけそうなボリュームがあるため、各自リファレンスを参照ください。
ここでは私が今のところ把握している情報で、「この場合はこれが使える」という情報のリンク集を書いておきます。公式の「Recipes」にはいろいろと載っていますね。
- Q.ループを検出するには?
- A. 公式の「Cycle Detection」を参照
- Q.頂点や辺の重複を見つけて削除するには?
- A. 公式の「Duplicate Vertex Detection」や「Duplicate Edge Detection」を参照
- Q.頂点と頂点の最短経路を取得するには?
- A. 公式の「Shortest Path」またはstackoverflowの「Best way to find a shortest path between two nodes in Tinkerpop 3.1」
- Q.SQLなら分かるんだけど、そういう人向けのGremlin解説はないの?
- A. なんかそれっぽいのはあります(よく読んでませんが) => 「SQL2Gremlin」
JanusGraph DBの設置
コンソールだけでもグラフの作成と操作(走査)は出来ますが、データの保存(永続化)が行われません。コンソールを閉じた瞬間に、作業した内容は失われてしまいます。ここでは、JanusGraphという名のGremlinサーバーを実行する方法を説明します。
サーバーの立ち上げ(with Berkeley DB)
JanusGraphではデータの内部的な保存先(ストレージ・バックエンド)として、Apache Cassandra,Apache HBase,Berkeley DB,なし(インメモリ)を選択することができます。また、インデックスの処理(インデックス・バックエンド)にLucene,ElasticSearch,Solrを選択可能です。デフォルトではElasticSearchになりますが、インデックスを必要としない場合は特に何もしなくてもOKです。今回は、この中で比較的シンプルなBerkeley DB&ElasticSearch構成での立ち上げを試してみます(インデックスは使いません)。
JanusGraphのアーカイブにあるconf/gremlin-serverディレクトリには、デフォルトの各種設定ファイルが置いてあります。
| 設定ファイル名 | ストレージ・バックエンド(括弧内は接続先) | インデックス・バックエンド(括弧内は接続先) |
|---|---|---|
| gremlin-server.yaml | Apache Cassandra (127.0.0.1) |
Elastic Search (127.0.0.1) |
| gremlin-server-berkeleyje.yaml | Berkekey DB (127.0.0.1) |
Elastic Search (127.0.0.1) |
| gremlin-server-berkeleyje-es.yaml | Berkekey DB (127.0.0.1) |
Elastic Search (elasticsearch) |
| gremlin-server-configuration.yaml | Apache Cassandra (127.0.0.1) |
Elastic Search (127.0.0.1) |
正直、用意してくれている設定ファイルの数とバリエーションは微妙です。これ以外の構成を選択したい場合は、自分で用意する必要があります(設定ファイルをコピペしてgraphsの部分を書き換えれば大体なんとかなる感じ)。
今回はgremlin-server-berkeleyje.yamlを使用します。ルートディレクトリ上からbin/gremlin-server.shまたはbin\bremlin-server.bat(Windows)を実行します。
$ bin/gremlin-server.sh conf/gremlin-server/gremlin-server-berkeleyje.yaml
> bin\gremlin-server.bat conf\gremlin-server\gremlin-server-berkeleyje.yaml
沢山ログが流れますが、最後に下記のようなログが表示されていればOKです。
4839 [gremlin-server-boss-1] INFO org.apache.tinkerpop.gremlin.server.GremlinServer - Channel started at port 8182.
サーバーを停止させる場合はCtrl+Cを入力します。
Gremlinコンソールからのリモート接続
サーバーが立ち上がったら、サーバー上に設置されているグラフにアクセスします。各種プログラミング言語用に用意されたドライバを使って接続することもできますが、まずは先ほど使ったGremlinコンソールからの接続を試してみます。
Gremlinコンソール上で、:remoteコマンドを使ってサーバーと接続します。
gremlin> :remote connect tinkerpop.server conf/remote.yaml
以下の応答があれば成功です。
==>Configured localhost/127.0.0.1:8182
これにより、(同じPC上ですが)リモート接続状態になったので、以降は:>コマンドを使用してサーバーに命令を転送することができます。:>は:submitコマンドの省略系で、命令のスクリプトをサーバーに転送するコマンドです。
今回立ち上げたサーバーの設定では、グラフとしてgraph変数が、GraphTraversalSourceとしてg変数があらかじめ用意されています。
gremlin> :> graph
==>standardjanusgraph[berkeleyje:db/berkeley]
gremlin> :> g
==>graphtraversalsource[standardjanusgraph[berkeleyje:db/berkeley], standard]
ローカルとリモートの変数は完全に分かれているのでごっちゃになって混乱しないようにご注意ください。
最初はグラフは空なので、適当にデータを追加してみます。
gremlin> :> g.addV("person").property("name", "marko")
==>v[4288]
gremlin> :> g.addV("person").property("name", "bob")
==>v[40964224]
gremlin> :> g.V()
==>v[40964224]
==>v[4288]
頂点のIDがランダムに設定されますが、これはグラフの設定と実装によって異なります。JanusGraphのデフォルト設定ではランダムのようです。
リモート接続を解除するには:remote closeコマンドを使用します。接続を解除しても、追加したデータは残り続けます。
プログラムからの接続(Pythonの場合)
データの永続化ができるようになったので、あとはDBを利用するプログラムを書くだけです。各種言語用にドライバが用意されているので、それを利用します。対応言語はリストを参照してください。Java、Groovy、Python、.NET、Javascriptについては公式の解説があります。
今回はPythonで試してみます。Python用のGremlin用ライブラリはgremlinpython(PyPI)です。
以下のコマンドでpipからインストールします。
$ python -m pip install gremlinpython
簡単なクエリを送るプログラムは以下になります。
from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection
from gremlin_python.process.anonymous_traversal import traversal
from gremlin_python.process.graph_traversal import __
from gremlin_python.process.traversal import T, P, TextP
domain = "localhost" # GremlinサーバーのIPアドレスorドメイン名
port = 8182 # Gremlinサーバーのポート番号(デフォルトでは8182)
traversal_name = "g" # TraversalGraphSourceの変数名(デフォルトでg)
url = f"ws://{domain}:{port}/gremlin" # 接続するURL
# サーバーと接続する
connection = DriverRemoteConnection(url, traversal_name) # ①
g = traversal().withRemote(connection) # ②
# クエリを発行
print("Query: toList version")
vertices = g.V().values("name").toList() # ③ toListを使う場合
for vertex in vertices:
print(vertex)
print("Query: next version")
vertices = g.V().values("name") # ③ hasNext,nextを使う場合
while vertices.hasNext():
print(vertices.next())
# サーバーとの接続を解除
connection.close() # ④
① URLとアクセスするグラフを指定してGremlinサーバーと接続します。URLはws://host:port/gremlinの形式と決まっています。デフォルトではws://127.0.0.1:8182/gremlinです。アクセスするグラフはGraphTraversalSourceの名前で指定します。今回はgです。
② 確立した接続からクエリを送るためのインターフェースgを取得します。これの扱い方はほぼGremlinコンソールと同じでOKです。
③ クエリを発行します。g.V().values("name")という簡単なクエリです。注意しなければならないのは、最後にTerminal-Stepsと呼ばれる命令を付け加える必要があります。これを加えないとクエリが実行されません(Gremlinコンソールは親切にも自動的に付け加えてくれていました)。Terminal-StepsにはhasNext,next,toList,iterateなどがあり、使い分け基準については、以下のように考えるといいと思います。
- 結果の数が少ないとわかっている場合 →
toListを使う。結果をリストで得ることができます。 - 結果の数が単数、あるいは不明の場合 →
hasNext,nextを使う。hasNextは次のデータがあるか判定し、nextはデータを一つ取り出せます。この2つを組み合わせて、whileループによるイテレーションが可能です。 - データを追加/削除するクエリの場合 →
iterateを使う。
④ 用が済んだら接続を解除します。
Dockerによるお手軽DB設置
※Dockerに興味ない方は読まなくて大丈夫です。
ここまではダウンロードしたJanusGraphのアーカイブからサーバーを起動していましたが、せっかく公式がDockerイメージを提供してくれているので、こちらでもサーバーの立ち上げを試してみます。すでにサーバーが立ち上がっている場合は終了しておいてください。また、Dockerは別途インストールしておいてください。
公式のインストールページにDocker用のコマンドが載っていますが、ちょっと微妙なので少しだけアレンジしたものを紹介します。
docker run --name my_janus -d -p 8182:8182 -v janusgraph-default-data:/var/lib/janusgraph janusgraph/janusgraph:latest
上記コマンドを実行すると、Berkeley DBを使う設定のGremlinサーバーが起動します(ただしインデックス・バックエンドはLuceneになっています)。
公式のコマンドとの差異は2つあり、一つはコンテナに名前(my_janus)を付けています。コンテナ名を付けていないと後の扱いが面倒なので。もう一つはボリュームを指定しています。公式のコマンドそのままだと、コンテナを削除してしまうと、DBのデータも一緒に消えてしまうので、少し不便です。ボリュームを指定することで、コンテナを消してもデータが残るようになります。
コンテナの停止はdocker stop my_janus、再起動はdocker start my_janusで行えます。
多くの人はdocker単体ではなく、複数のコンテナを組み合わせるためにDocker Composeを使うと思います。その場合は公式が作成したdocker-compose.ymlをベースに設定を構築すると良いでしょう。
Dockerイメージを使って、別のストレージ・バックエンドを使用する設定についてはこちらを参照してください。私はまだ試してませんが。
終わりに
これはほんの入り口であり、実際に運用していくには、キャッシュ、インデックス、スキーマ、トランザクション、デプロイ、バックアップなど知らなければならないことが山ほどあります。私も勉強中です。分かったことがあれば新しく記事を書きたいと思います。