2019/11/21 ご指摘いただいたので一部変更。
嵐さんがデビュー20周年を機にシングル曲全曲のサブスクリプション配信を始めたので、Spotify APIを使って嵐さんの楽曲情報を取得します。
こちらの記事を参考にしつつ、
Spotify APIで楽曲情報やアーティスト情報を取得してみた
Spotify APIの取得方法は以前書いたので今回は割愛します。
Spotify APIでアーティストを指定して楽曲一覧をPythonで取得する
Spotify APIでどんな情報が手に入るか
Spotify APIを使い楽曲情報を取得すると、いろいろな指標が入っていることがわかります。
Get Audio Features for Several Tracks
詳しくはこの記事にて記載、検証しているので参考にしました。
[Spotifyの楽曲に埋め込まれている情報がハンパない話]
(https://note.mu/hkrrr_jp/n/n9925dce37cba)
認証
取得したClient ID、Seclet Client、アーティストIDを利用し、情報を取得する。
はじめにSpotify APIのライブラリspotipyをインストールしておく。
pip install spotipy
認証を行います。
今回もSpotify APIのPythonライブラリ、Spotipyを使います。
artist_idは今回嵐さんのIDで実施しています。
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import sys
import pprint
import pandas as pd
client_id = '取得したClient ID'
client_secret = '取得したClient Secret'
artist_id = '取得したいアーティストID'
# 認証を行う
client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret)
spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
アルバム情報とトラック情報を取得
アルバムのIDを取得後、それぞれのアルバムに対しトラックIDを取得して楽曲情報を取得後。ひたすらDataframeに格納します。
嵐さんの場合配信対象はシングル曲ですが、一部両A面のため、1アルバムに2曲入っているため、この処理を行います。
# アルバム情報を取得する。
results = spotify.artist_albums(artist, album_type='single', country='JP', limit=50, offset=0)
# アルバム情報を取得する。offsetオプションで続きを取得。
results2 = spotify.artist_albums(artist, album_type='single', country='JP', limit=50, offset=50)
artist_albums = []
for song in results['items'][:len(results['items'])]:
data = [
song['name'],
song['id']]
artist_albums.append(data)
for song in results2['items'][:len(results2['items'])]:
data = [
song['name'],
song['id']]
artist_albums.append(data)
# アルバムからトラック情報を取得する
song_info_track = []
for artist_album in artist_albums:
album_id = artist_album[1]
song_info = spotify.album_tracks(album_id, limit=50, offset=0)
#両A面があるのでトラックを抜き出す
for song_info_detail in song_info['items'][:len(song_info)]:
song_track_id = song_info_detail['id']
song_title = song_info_detail['name']
#曲の情報を抜き出す
result = spotify.audio_features(song_track_id)
#なぜか取得できない曲があったので(取得したIDで検索できない)、分岐をする
if result[0] is not None:
#タイトルを入れた辞書を作成
result[0]['title'] = song_title
pd.DataFrame(result)
song_info_track.append(result[0])
df = pd.io.json.json_normalize(song_info_track)
df = df.set_index('title')
結果は50曲以上あるので割愛します。
詳細はいつか別のブログに書きます。
苦戦した個所としては以下。
・全曲取得できない
Spotify APIの仕様上、最大でも最新50アルバムしか取得できないようです。
今回は初期の曲を捨て、最新曲Turning UpからPIKA☆NCHIまで(2019/11/19現在)の楽曲を取得しています。
2019/11/21 offsetを使って無理やり全曲取得しました。
・なぜか取得できない曲があったりなかったりする
アルバムからトラックIDを取得して楽曲情報する際、なぜか取得したトラックIDで楽曲情報が取得できないことがありました。
日を改めたら上手くいきましたが、怖いので取得できた場合のみDataframeに格納するようにしました。
検証する
検証するにあたり、あまり必要がない情報を削除しておく。
# 見やすくするため不要な列を削除する
# 今回はID情報などを削除する。 インストでもないのでinstrumentalnessも削除する
df = df.drop(['type', 'id', 'uri', 'track_href','analysis_url', 'time_signature', 'mode','instrumentalness'], axis=1)
IDやURIなどが不要になるほか、拍や調は詳しくないので削除。
インスト曲はないためinstrumentalnessも削除。
取得した結果のうち、今回はdanceabilltyという指標について検討します。
それぞれの指標の検証はQiitaでは割愛。オタ垢でやります。
引用は参考にしたサイトから。
・danceabillty
踊りやすさ。1に近づくほどダンサブル。テンポやリズム、ビートの強さなどから決まるらしいです。
各曲の上位曲(1に近い値)を取得します。
例としてdanceabilltyでソートをします。
# ソート
df.sort_values('danceability', inplace=True,ascending=False)
# 上位5曲
df.head()
danceabilltyの結果上位5曲は下記の通り。
| タイトル | danceability |
|---|---|
| Turning Up | 0.769 |
| Face Down | 0.733 |
| 復活Love | 0.719 |
| とまどいながら | 0.713 |
| A Day in Our Life | 0.704 |
上位3曲はわからなくはないけれど、「とまどいながら」が入るのは疑問・・・
次に散布図で別の指標との関係を見てみます。
かけ合わせる指標は次の2つ。
・energy
曲の過激さ。”過激”があらわすのが展開的なことなのか勢いなのかはよくわからず。デスメタルは高くバッハの前奏曲は低いという説明があります。
・valence
明るさ。1に近づくほどポジティブな楽曲とのことです。
まずはdanceability×energy
df.plot.scatter('danceability','energy')
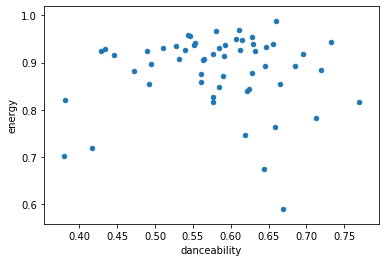
主にenergyが0.9あたりのラインに多くあることがわかります。基本的には激しめの曲が多いのでしょうか。確かにバラードはそこまで多くないかもしれません。
唯一energyが0.6以下の曲は「瞳の中のGalaxy」というミディアムバラード。
(藤井フミヤ氏提供曲です)
次にdanceability×valance
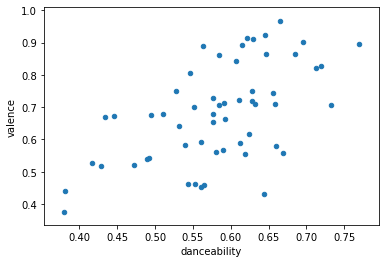
割ときれいな?正の相関になりました。
ダンス曲は明るいということでしょうか。
一番左下の曲は「明日の記憶」。これもミディアムバラード。
最後に
Spotifyの指標は感覚で違うだろ・・・というのものもありますが、大まかには合っているような気がします。
ジャニーズのグループ間で楽曲の特徴を比較したいので、早くほかのグループも楽曲配信解禁してくれ~!!特にJ-Storm~!!
さいごのさいごに!嵐さんの新曲Turning Upのリンクはこちら!!
たくさん聞いても私に1円も入らないけど聴いてください!!!