産休中に、
オンライン学習サービス Udemy の
『Azure OpenAI (GPT) と Cognitive Search (現: Azure AI Search ) で作る ナレッジマイニング チャットボット』を
通してみたので、ここに学習メモを残します。
講座作者: 津郷 晶也さん
この記事について
この記事はあくまで 個人的な学習メモ(学生時代から授業は丁寧にノートを取っていた名残)なので、皆様におかれましては 勉強する際は実際の動画講座をご覧になるのをオススメします。いくつかの動画は無料で見られます。
(*学習動画については、無料サンプルのものだけスクショを使いますが、そうではない箇所の動画スクショは載せません。)
(↑図:Udemy コース「Azure OpenAI (GPT) と Cognitive Search で作る ナレッジマイニング チャットボット」無料サンプル動画より)
(補足:タイトルの #PR 表記について)
また、この記事は 2024/5/14 にツイッターに投稿した Udemy さんの PR ツイート で取り上げた(推し講座として選んだ)1 講座についての学習記事になりますが、
この記事に関しては(PR 案件の中に含まれていたものではなく)勝手に書いたものです。
(すごい良い講座だったから語りたいことが多過ぎて1ツイートに収まらなかったので勝手に記事に書いたオタク)(もちろん他の講座も素晴らしいけど時間的に1講座だけ)
ですが
・他媒体で自主的にシェアいただける場合も、景品表示法の観点から #PR もしくはタイアップ設定などが必要となりまして、記事内のどこかに追記いただけますと幸いです!
とのことでしたので、タイトルに #PR と付けました。
なので #PR って書いてあるけど、頼まれて書いた宣伝記事 ではないです。
まじで勝手に書いたやつ です。
(↓ このツイートは PR ツイート)
値段
ちなみに私が 4 月に購入したときは(定価は 27,800 円でしたが)セールで 1,500 円でした。

追記 on 5/14:値段
なんか今日から初夏のビッグセールとかで私が買ったときより安くなってる😂
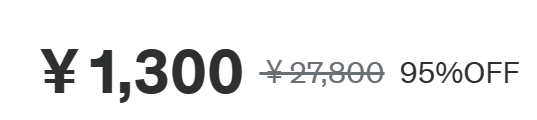
注釈 (Cognitive Search → Azure AI Search)
講座タイトルにある「Azure Cognitive Search」は、去年、名前が変わり、
現在は「Azure AI Search」( AI を活用した情報検索プラットフォーム)となっています。
参考)
(講座中にも追記としてこの名称変更についての言及は入っています (in セクション 1-5))
なので、講座で「Cognitive Search」と触れられていても、
この記事では「Azure AI Search」として書いていきます。
参考) マイクロソフト公式ドキュメント
Azure AI Search
チュートリアル: Azure OpenAI Service で独自のデータを使用するチャット Web アプリをデプロイ
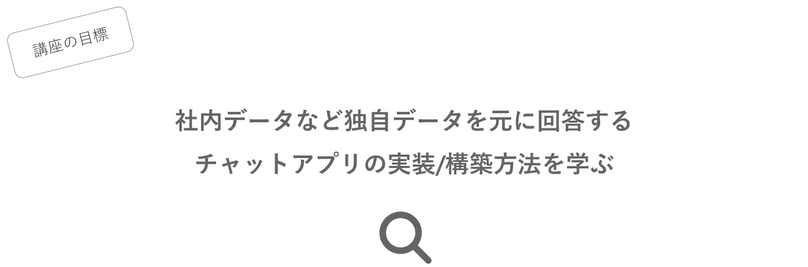
講座の目標
この講座の目標は、
社内データなど独自のデータをもとに回答する、チャットアプリの実装/構築方法を学ぶ
とのことです。
とても需要のあるシナリオで良いですね!
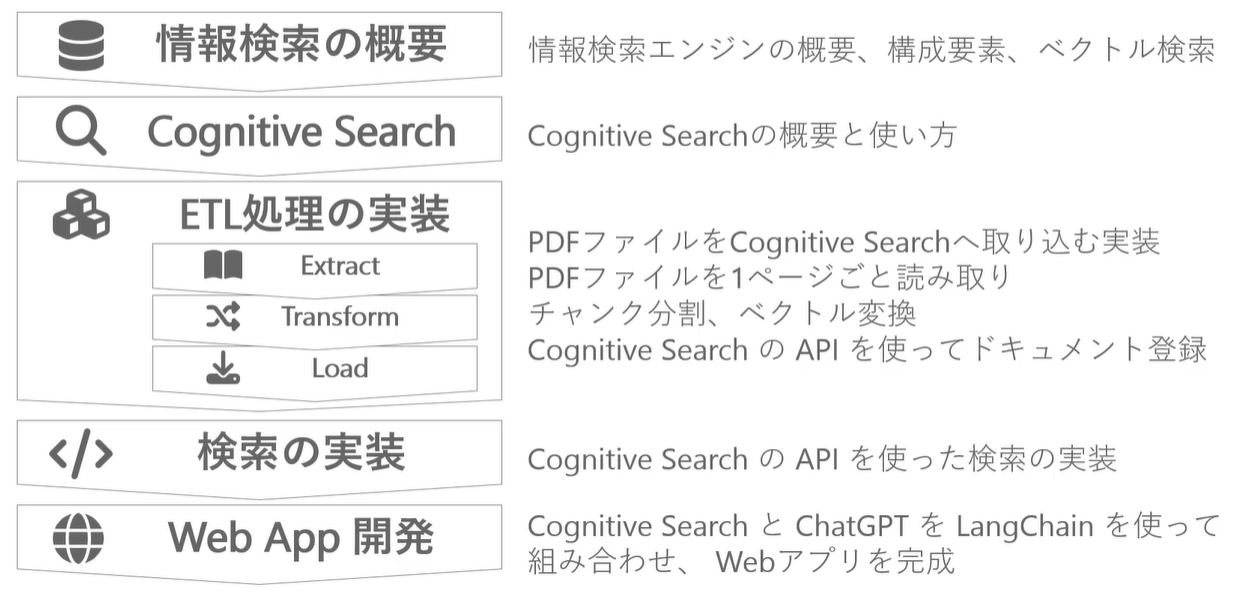
講座 全体の流れ
(↑図:Udemy コース「Azure OpenAI (GPT) と Cognitive Search で作る ナレッジマイニング チャットボット」サンプル動画より)
- 情報検索の概要
-
ETL 処理の実装
- データの抽出(Extract): pdf ファイルを AI Search に取り込む
- 変換(Transform): チャンク分割、ベクトル変換
- 格納(Load): Azure AI Search API を使ってドキュメント登録
-
情報検索システムの実装
- Azure AI Search
-
Web App 開発
- Azure AI Search
- ChatGPT (Azure OpenAI Service)
- LangChain
- Node.js v18
1. 情報検索の概要
(* 上でも書きましたが、学習動画については、無料サンプルのものだけスクショを使いますが、そうではない箇所の動画スクショは載せません。)
情報を探す仕組み - フルテキスト検索
フルテキスト検索(全文検索) エンジンについて。

(↑図:Udemy コース「Azure OpenAI (GPT) と Cognitive Search で作る ナレッジマイニング チャットボット」無料サンプル動画より)
検索のキーワードが指定されると上から順番に検索していく逐次検索 (grep 型) で情報を探す場合の課題として、
- データ量が増えたり
- 検索対象が末尾だったりすると、
検索に時間がかかることが挙げられます。
そこで、一般的に、多くの フルテキスト検索(全文検索) エンジンでは、
インデックス(索引) を用意する 索引型の全文検索 が一般的です。

(↑図:Udemy コース「Azure OpenAI (GPT) と Cognitive Search で作る ナレッジマイニング チャットボット」無料サンプル動画より)
インデックスとは、たとえば書籍で言うところの、一番うしろにある索引のことで、
(書籍の場合は)キーワードをベースに「何ページ目にそのキーワードがあるか」を示しています。
参考スライド
講座とは関係ないけどこのスライドめっちゃ良かったです
情報検索システムの構成要素
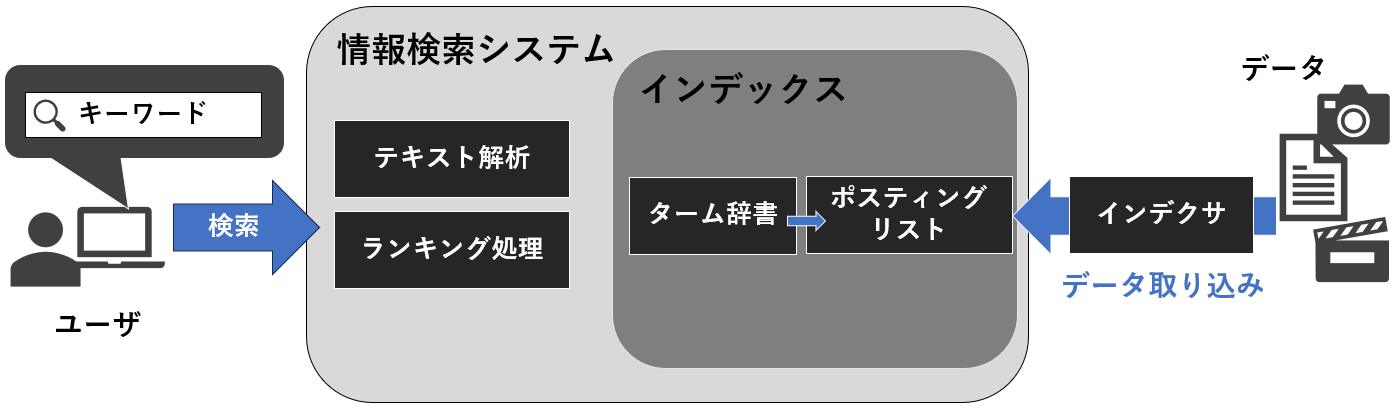
(↑図:Udemy コース「Azure OpenAI (GPT) と Cognitive Search で作る ナレッジマイニング チャットボット」セクション2-8 動画の図を参考にパワポで再構成したもの)
インデクサも「情報検索システム」(検索エンジン)の中に含める記事もありますが、ここではこの講座の説明の通りに 外に置いています。
1. データ取り込み
| term | Eng | description |
|---|---|---|
| インデックス | Index | 事前に作られる索引。検索に使う |
| インデクサ | Indexer | 一連のインデックス作成のプロセスを実行するエンジン。 |
| ETL 処理 | ETL | データを取り込む際に必要となるプロセス。 取り込みやすいフォーマットに変換・加工し、書き出す処理。 1. Extract(抽出) 2. Transform(変換) 3. Load(書き込み) |
2. テキスト解析
| term | description |
|---|---|
| ターム | 検索に利用できる単語 |
| テキスト解析 | タームを抽出する |
| ターム辞書 | タームが保存されてる |
| ポスティング | 単語と文書の対応付けの情報 |
| ポスティングリスト | 各単語におけるポスティングの列 |
3. ランキング処理
| term | description |
|---|---|
| ランキング処理 | 検索結果を返却するさい、 何かしらの基準 で並び替える処理 |
| TF-IDF | ↑ のランキング処理の「何かしらの基準」の例。 Term Frequency – Inverse Document Frequency タームがドキュメントに出現した回数 (TF) (そのタームの出現頻度が高いほど重要度が高いだろう)と、 タームが出現するドキュメント数の逆数 (IDF) (その単語がどれくらいレアなのか。レア度が高い単語ほど重要度は高そう) |
ベクトル検索
文字列(テキスト)に関しての検索で全文検索を取り上げましたが、
文字列以外の検索はどうしたらいいのでしょうか。
たとえば画像や動画など。
そういうときに ベクトル検索 (Vector Search) が挙げられます。(もちろんテキスト検索でもよく使われます)
データを数値のベクトルに変換し、このベクトル間の距離や類似度を計算することで、関連する情報を見つけ出す検索方法です。多次元の数値表現に変換し、検索する仕組み。
↓ 下の図でいうと「Vector Representation (ベクトル表現)」の部分にデータが入ってる
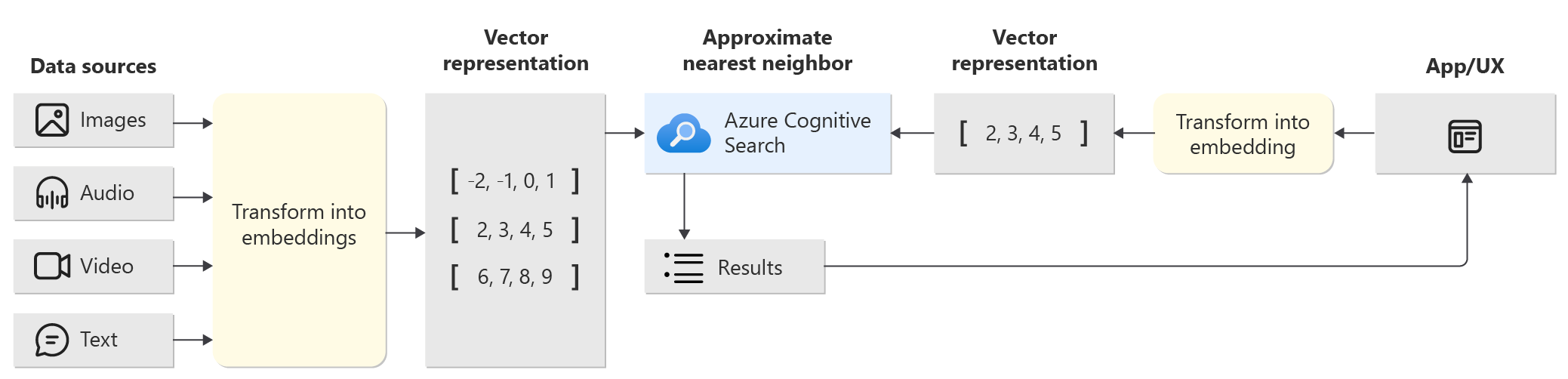
(↑図:マイクロソフトの公式ドキュメント『Azure AI Search のベクター』より)
テキスト検索時は「意味的に近い」ものが返ってくる。
テキスト検索時でのベクトル検索結果の例:
「web」検索 → 検索結果「web, インターネット, ネット」
2. Azure AI Search

Microsoft が提供する、フルマネージドの高度な検索サービス Azure AI Search (旧「Cognitive Search」) について見ていきましょう。
他の Azure のサービスとの強力な統合機能(データソースから自動で検索インデックス作ってくれたり)もあったり、大変便利です。
公式ドキュメント:
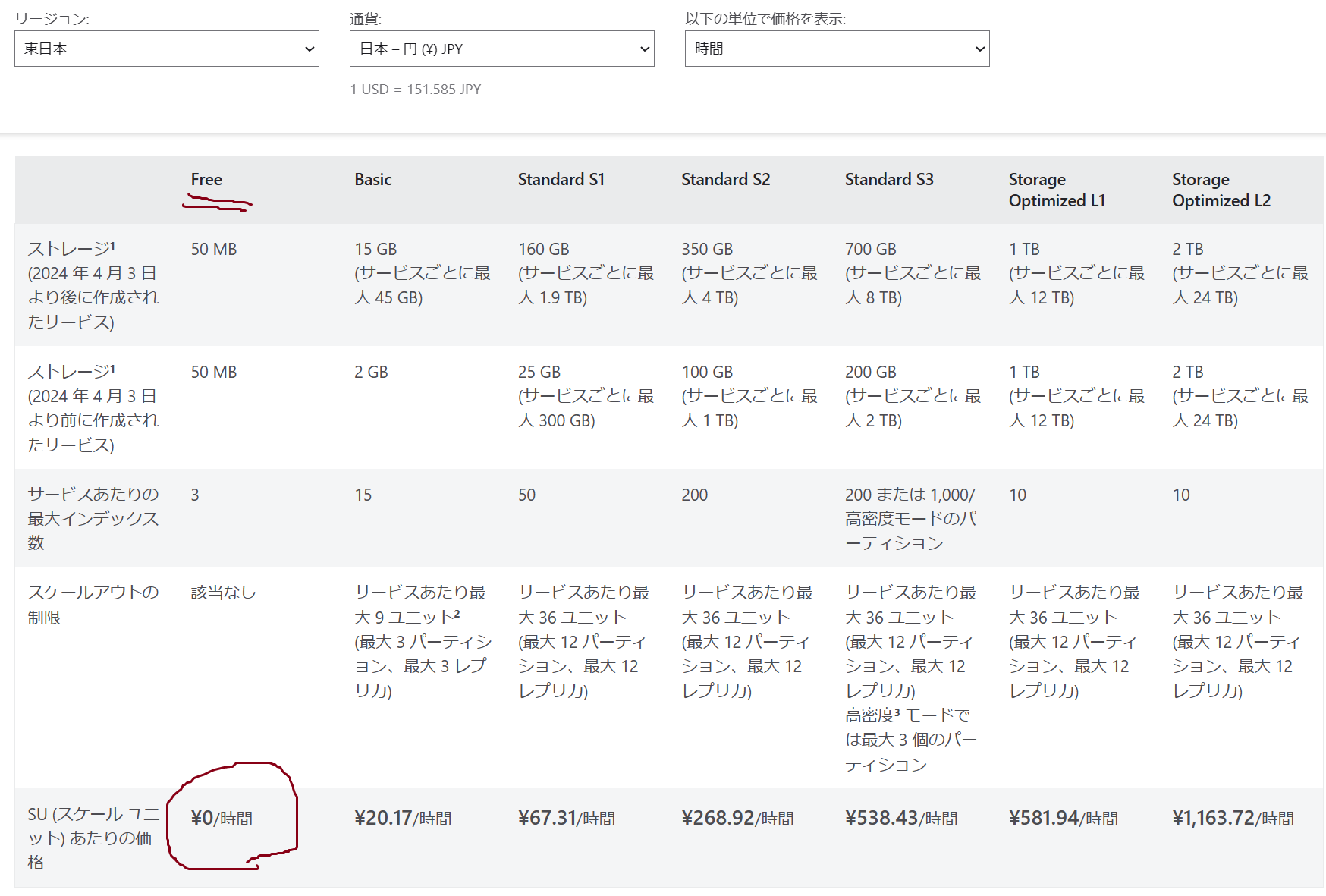
値段
基本的なコスト構造としては、稼働時間に対してコストがかかるようになっています。
おためし版の無料 (Free) 版あります!
課金すると、作成可能な検索インデックス数やストレージの容量などが上がっていきますね。
(テストではなく本番運用する際は Standard 以上を選びましょう!)
Azure AI Search (旧「Cognitive Search」) とは

(↑図:Udemy コース「Azure OpenAI (GPT) と Cognitive Search で作る ナレッジマイニング チャットボット」無料サンプル動画より)
Azure AI Search (旧「Cognitive Search」) とは、
情報検索を行うために必要となる機能群を まとめて提供してくれているサービスになります。
利用できる検索(クエリタイプ)
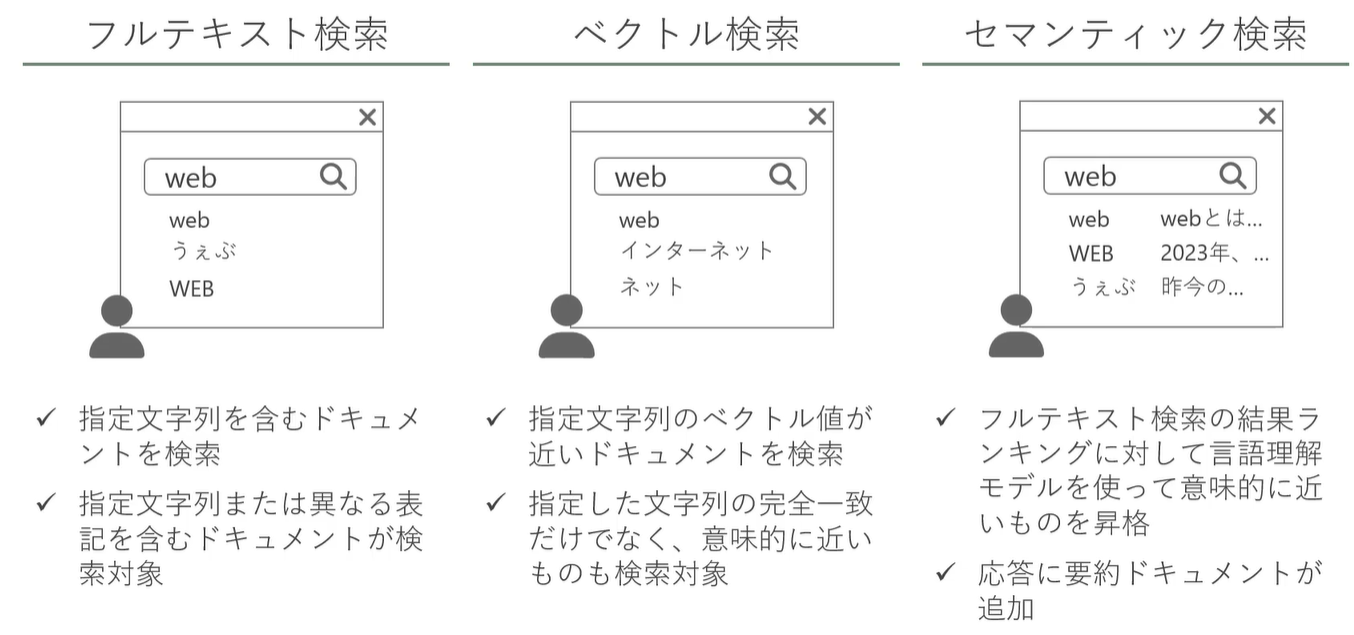
(↑図:Udemy コース「Azure OpenAI (GPT) と Cognitive Search で作る ナレッジマイニング チャットボット」無料サンプル動画より)
| Types of queries | in Eng | Description | Doc |
|---|---|---|---|
| フルテキスト検索 | Full text search | (説明済みなので略) | Doc |
| ベクトル検索 | Vector search | (説明済みなので略) | Doc |
| ハイブリッド検索 | Hybrid search | フルテキスト検索とベクトル検索を組み合わせた検索方法。ふたつの結果を Reciprocal Rank Fusion (RRF) というアルゴリズムで再ランク付けして返す | Doc |
他にも「地理空間検索 (Geospatial search)」などありますが、省略します。
参考)マイクロソフト公式ドキュメント
「Azure AI Search の機能 - クエリのタイプ」
アナライザー
インデックス作成とクエリ実行中に文字列を処理する、フルテキスト検索エンジンのコンポーネントである アナライザー についてです。
たとえば、重要でないワードだったり、句読点を削ったり、活用形を原型に変換したりなどしてくれます。
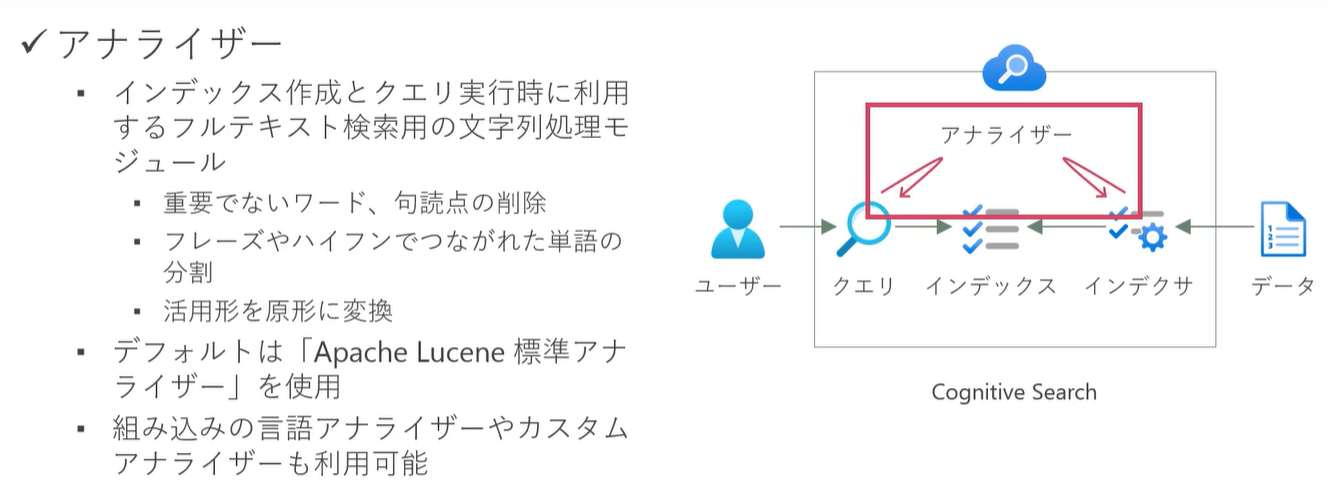
(↑図:Udemy コース「Azure OpenAI (GPT) と Cognitive Search で作る ナレッジマイニング チャットボット」無料サンプル動画より)
参考)マイクロソフト公式ドキュメント
「Azure AI Searchでのテキスト処理用のアナライザー」
インデクサー
Azure AI Search のインデクサーは、
データソースからデータを抽出し、
ソースデータと検索インデックスの間のフィールド間マッピングを使用して検索インデックスを設定するクローラーです。

(↑図:Udemy コース「Azure OpenAI (GPT) と Cognitive Search で作る ナレッジマイニング チャットボット」無料サンプル動画より)
push 形式、つまり AI Search にデータを送りつける場合は API を使用します。
pull 形式の場合は、Azure の AI Search のポータル画面から設定を行っていきます。
利用できるデータソースはこちらの公式ドキュメントから一覧を確認することができます👀
Azure AI Search - データ ソース ギャラリー
参考)マイクロソフト公式ドキュメント
「Azure AI Search のインデクサー」
クエリ(検索)
通常のフルテキスト検索であれば、そのまま API を叩けば大丈夫ですが、
ベクトル検索を行いたい場合は、
あらかじめ OpenAI の Embedded モデルを使ってベクトル値に変換し、
その変換された数値情報を AI Search に渡す必要があります。
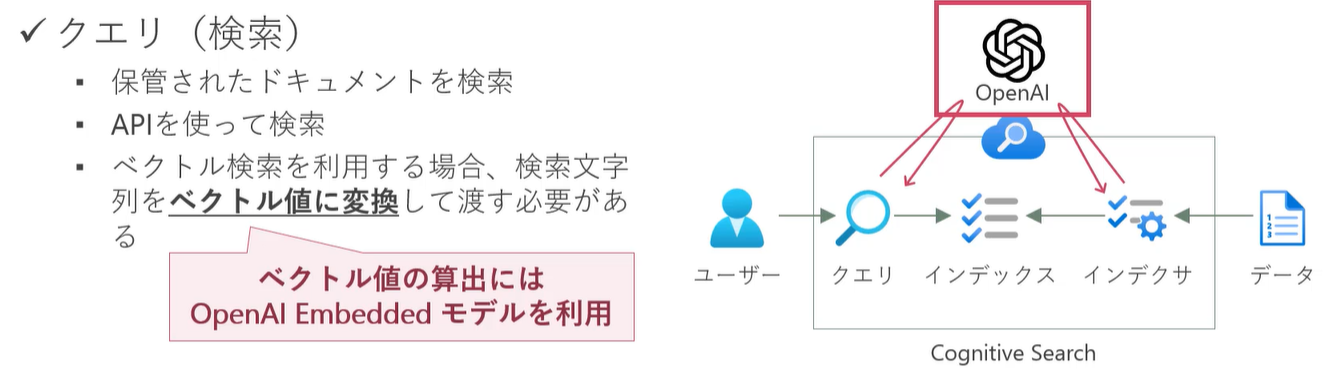
(↑図:Udemy コース「Azure OpenAI (GPT) と Cognitive Search で作る ナレッジマイニング チャットボット」無料サンプル動画より)
まとめ
以上が、講座『Azure OpenAI (GPT) と Cognitive Search で作る ナレッジマイニング チャットボット』前半の座学パートでした。
後半では実際に手を動かしてのハンズオンパートが始まります。
システム全体アーキテクチャ
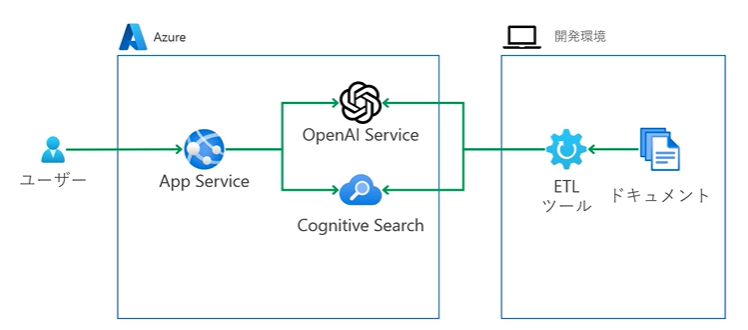
(↑図:Udemy コース「Azure OpenAI (GPT) と Cognitive Search で作る ナレッジマイニング チャットボット」無料サンプル動画より)
後半部も記事に書こうと思ったのですが、
長くなったのでとりあえず前半部の座学パートだけでいったんここで締めます。