2021E資格を取得したので、本格的に実装にチャレンジを始めました。
SIGNATEのQUESTも半年プランを契約しました。
が、このチャレンジ知ってたら契約しなくてよかったな。
はるか上のレベルのものを詳しく解説してくれている。
(このチャレンジはみたこともないようなよいチュートリアルがついています。
教科書として使うべく、自分のPCにダウンロードしました。)
初心者でも参加できるように工夫されています。感動した。
とりあえずチュートリアルをみながら、Google Coraboで作ればだれでも投稿までできます。
注意事項としては、理由はわかりませんがよくわからないエラーがでることです。
そのときは、以下のようにしてください。
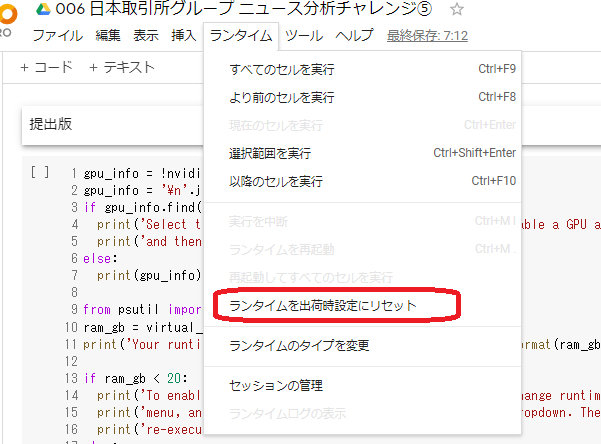
すると今までなにを苦労していたんだろう、という感じで解消されます。
なんとなくですが、モジュールをimportして、モジュールを修正して単純に
実行すると、修正したモジュールはimportされず、古いモジュールが動く
googleの仕様ではないかと思ってます。(正確にはよくわかりません)
あとは、とんでもなく時間がかかるので、Google Corabo Proにしてみました。
1か月たった1000円程度払うだけで、早いマシンとメモリが使えるのは大きい。
思考錯誤しながらやるので、チューニング時は必須だと思います。
私がやったこと。
1.第3章の提出
2.第4章の提出
3・第6章の提出
手抜きをせずにチュートリアルを見て、実行してを繰り返しました。
GitHubからもってくれば一発なのですが、なにも得られないので、
コマンドを打ったら、変数になにがはいっているか確認しながら進めました。
提出すると、同じスコアの人が何人もいます。
当たり前ですが、チュートリアルに沿ってやると同じスコアになります。
問題となるのは、これをどのように改善するかです。
まずは、チュートリアルを3回読みました。
結局どのように予測するかのロジックがわからないと
改善の使用がない。
今は小手先の改善をしているところです。
一番簡単に考えられるのは、ストラテジーの変更ってとこでしょうか。
とりあえず、strategy=5にしています。(テスト環境でためすとスコアが上がります。)
今回のチャレンジは、ニュース分析した結果を株価にどう反映するか、
ですが、ニュース分析した結果、毎週ほぼ同じ結果しか得られない。
チュートリアルをみても同じ。
さて、これをどうしたものなのでしょうか?
イメージとしては、来週は景気が悪化しそうだとおもったら、投資額を
減らし、よくなりそうだと判断したら、逆にしたいですが。
あと、フォーラムをみていると俺は我が道をいくぜ、のような
ものもありますが、それはそれでいいと思います。
私の場合は明らかにチュートリアルの方が自分の知識より豊富にあることを
考慮して、ここは謙虚に教えを乞うスタンスでいきたいと思います。
JPXさんの説明会がありました。
考えていませんでしたが、決め打ちのものはダメですとのことです。
銘柄を固定するようなロジックはNGです。AIのコンペだから当たり前ですが。
あと、一発逆転を狙ったランダム性を持たせたらだめだそうです。
考えてた人いたかな。
入力に変化がなければ、出力に変化があってはいけないルール。
メインのアルパカさんの説明はさすがでした。
難しいBERTでなくLDAを使ってモデルを作成するということです。
以下のようなアドバイス、アイディアがありました。
(聞きながらメモッているのでわかりずらかったらすいません)
・大型株のニュースが多いため、ニュースを素材にすると大型株を中心とした、
ポートフォリオとなる。よいかどうかは別として。
・ニュースの70%程度は250銘柄に集中する。
・まずはシンプルなモデルでベンチマークを図る。
LinerRegでやってみる。ただ、単純なLinerRegではAccuracy0.5程度しなでない。
どのような課題でも、LinerRegをやるといい。
・特徴量を増やせばLinerRegでできるのか判断するの、そのあたりが重油。
・33業種、17分類(セクター)でなにかできないか。
トレインデータである程度線形分離はできた。
・セクターを使ったRandomforestを試した。
probabilityをソートして、自信のあるデータを利用する。
importance_をみると、トピックの貢献度が高い。
確かに、データコンペでLightGBMを最初に使ってしまうが、結局単純な
モデルの方がいいスコアがでたことが多々あり、納得できるところが多かった。
あとは、当たり前ですが仮説をたててデータ分析していくのが大事ということ。
私の場合、なんとなくいつもいい結果がでるモデルを使い、ハイパーパラメータを
変えたりしながらスコアを見ている。
これを機会に、株の知識はあまりないですが、ある程度仮説をたてて、
データで新たな知見を得ていくという方向が、初心者には重要かな
と思いましたので、そのようにやって少しでも実力をつけていきたいです。
結局、未来予測は単純なロジックだろうと、複雑なロジックだろうと
正確に当てることは不可能。
ちょっとロジックを単純化して、わかりやすいものにしてみようかな。
いろいろロジックをいじったり、パラメータをいじったりしました。
なにを目標にしていじればいいのか。
submitすれば暫定スコアがでますが、あくまでも過去のデータでの話。
未知のデータが入力された時、どうすればいいのか。
結局、わからなくなって元のプログラムに戻しました。
自信はまったくないが、なんとなく自分の中で納得できる
ロジックになったので、まあいいやと思いもう放置することにしました。
さて、次はパナソニックさんの物体認識に力を入れていこうとおもってます。
たまに、google colaboで突然、resetしても正常に動作しなくなることがあります。
セルを動作させても、グルグル回るだけで動かない。
そういうときは、セッションを殺すしかないです。
▼をおします。
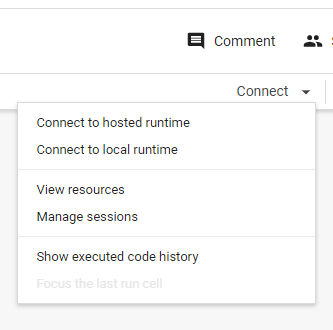
Manage sessionsを選択します。
Active sessionsが表示されます。
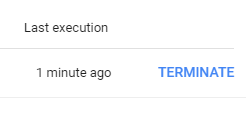
terminateをclickします。そうして再実行すると、うまく動くことが多いです。
google corabolatory proを使っていても以下のエラがでます。

GPUの需要供給のバランスできまるのかよくわかりませんが、これがでてしまうと3~9時間ぐらいGPUが使えなくなってしまいます。休みの日に3時間ぐらい使うとこのメッセージがでて、夜まで使えないなんてこともありました。
最近気が付いたのですが、どうも2時間程度利用したら一旦ランタイムをリセットして、それからまた使うということをすると、この制限に引っかからないということがわかってきました。
困っていたら、試してみてください。
ついでに、GPUで学習させながらCPUでモデルを作成していると、これまたGPUに接続できなくなるケースがあります。
新たにセッションを作ろうとすると、使っているセッションが多すぎるといわれみると、セッションが1つしか動いてないことがあります。
これは、colabo Proで学習させ、別の無料IDを取得してモデルを作成するようにしています。