はじめに
Splunkでは、取り込んだデータをIndexer内に保管する際、圧縮されたRawデータ(journal.gz)と索引データ(tsidx)のペアで保管されます。
通常の統計処理を行うサーチ(statsやtimechartコマンド等)では、サーチ処理の中でRawデータ及び索引データの双方を扱いますが、tstatsコマンドは索引データのみを扱うため、通常の統計処理を行うサーチに比べ、サーチの所要時間短縮を見込むことが出来ます。
tstatsコマンドにて統計処理対象として利用可能なフィールド例
- Splunk取り込み時にデフォルトで付与されるフィールド
- sourcetype, host等のデフォルトフィールド
- About default fields (host, source, sourcetype, and more) - Splunk Documentation
- CSVやJSONフォーマットのデータに含まれるフィールド
- フォーマットに合わせたINDEXED_EXTRACTIONS設定を行うことが前提
- Extract fields from files with structured data - Splunk Documentation
- PREFIX()が利用可能なフィールド(データフォーマット) ※v8.0.0以降
- index-time field extraction設定済のフィールド
- インデックス時のフィールド抽出設定を行うことが前提
- Create custom fields at index time - Splunk Documentation
- 高速化有効済のデータモデルにて定義されたフィールド
- データモデル定義及び高速化設定を行うことが前提
- Accelerate data models - Splunk Documentation
構成
- Splunk Enterpriseバージョン
- v8.2.2
- v9.0.4
- v9.3.3
tstatsコマンド利用例
例1:任意のインデックスにおけるソースタイプ毎のイベント件数検索
Splunk取り込み時にデフォルトで付与されるフィールドを集計対象とします。
-
変更前サーチ文
index=_internal | stats count by sourcetype
-
tstatsを用いたサーチ文
| tstats count WHERE index=_internal by sourcetype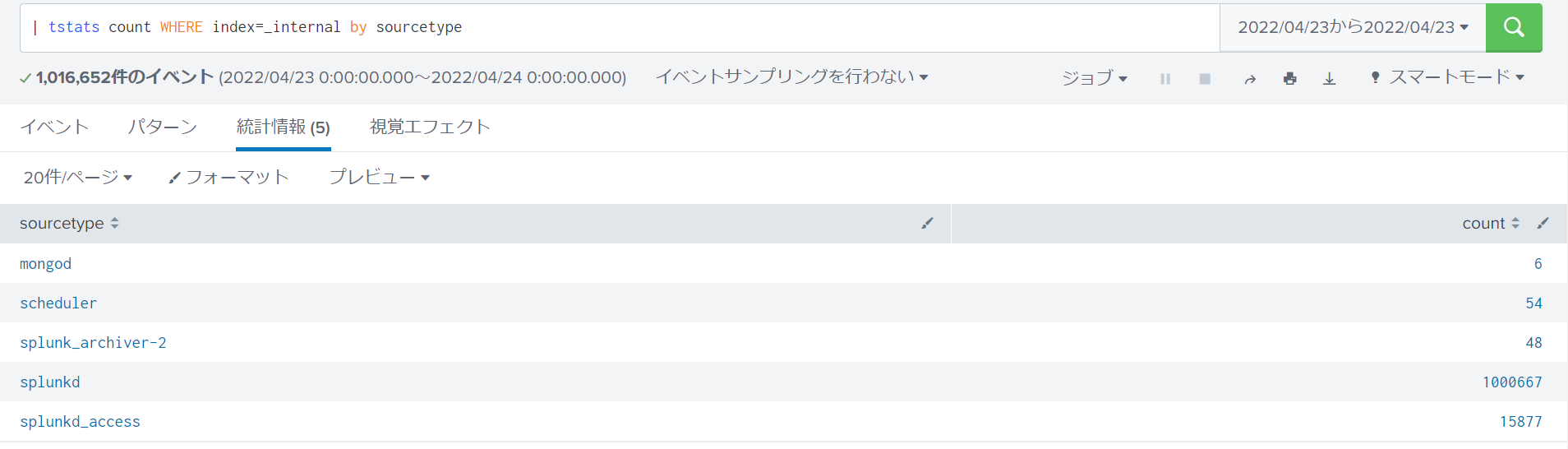
例2:任意のインデックスにおける時系列イベント件数検索
Splunk取り込み時にデフォルトで付与されるフィールドを集計対象とします。
-
変更前サーチ文
index=_internal | timechart count span=10m
-
tstatsを用いたサーチ文
| tstats count WHERE index=_internal by _time span=10m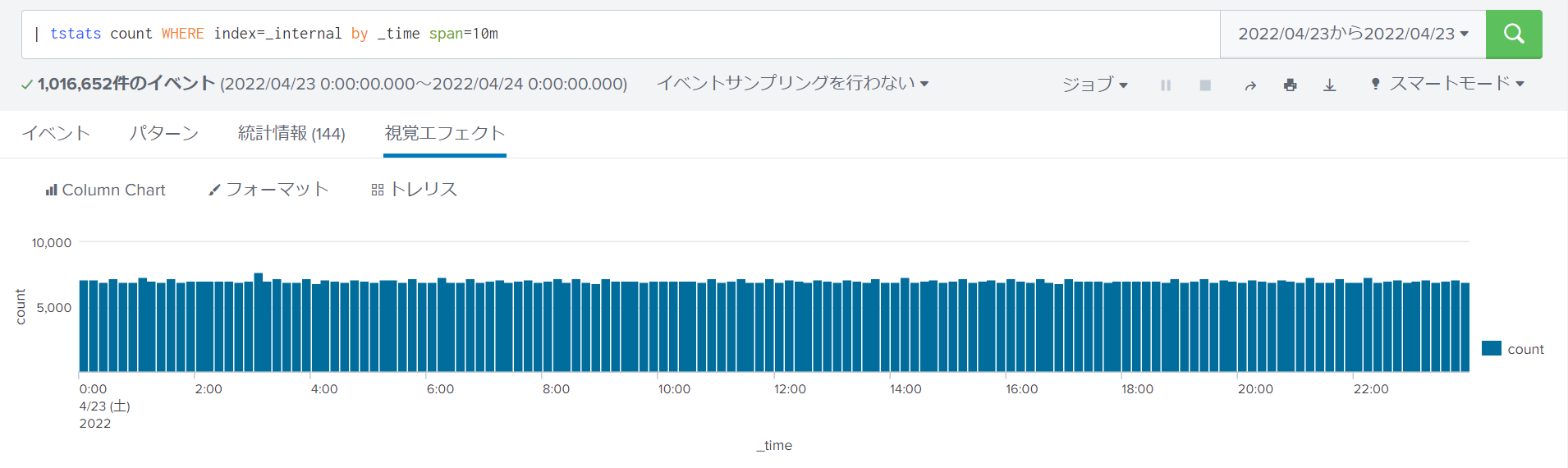
例3:JSONフォーマットデータを対象とした件数検索
INDEXED_EXTRACTIONS=json設定にて取り込んだJSONフォーマットデータ(sample.json)におけるフィールドを集計対象とします。
-
変更前サーチ文
index=customer source=sample.json | stats count by gender isActive
-
tstatsを用いたサーチ文
| tstats count WHERE index=customer source=sample.json by gender isActive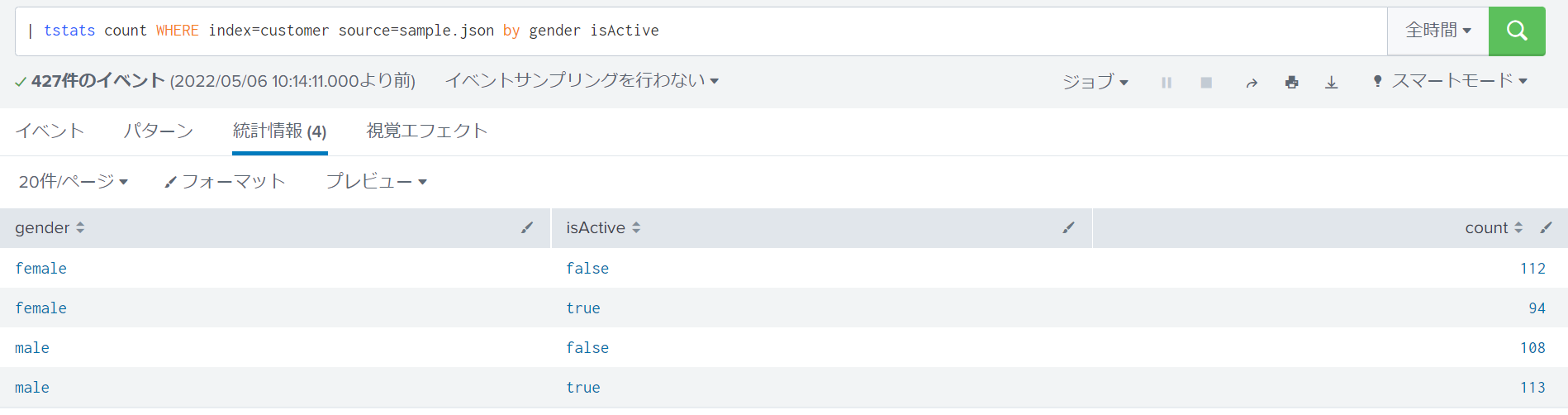
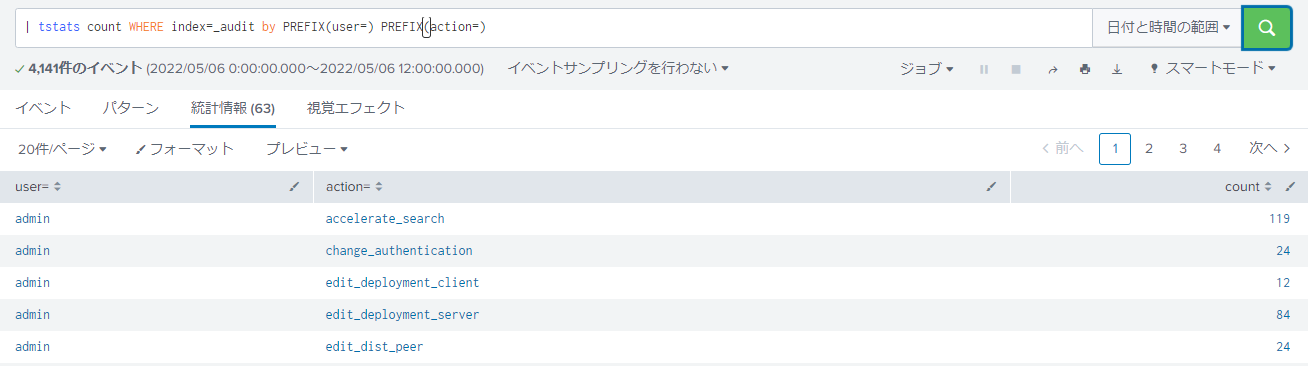
例4:PREFIX()が利用可能なフィールド毎のイベント件数検索
PREFIX()を利用して、key=value形式で記載されたフィールドを集計対象とします。
-
変更前サーチ文
index=_audit | stats count by user action
-
tstatsを用いたサーチ文
| tstats count WHERE index=_audit by PREFIX(user=) PREFIX(action=)