はてさて、1日遅れてしまいましたがAdventCalendar5日目です。
昨日は社内イベントで盛大に負けてとても勉強になった一日でした。もっとキャッシュ力を高めていこうと思った30歳・冬。
財布には千円しかなかった寂しさを乗り越え、今日も前向きにいきたいと思います。
前回は特定区間の処理時間をpercentileで出力し、なんとなく把握してみようというものをやりました。
グルーピングの条件も特定アクション毎の集計だったのでレンジが長くなればなるほど大雑把になってしまいます。
ああいった処理時間を可視化したい、ということは何かしら変なことが起きていないかわかるようにしたい、ということでもありますので
今日は1日毎かつアクション毎に処理時間の平均を集計し、日付順で並べてみましょう。そうすればもっと変化量が視覚的にわかりやすくなります。
テーブル構成は前回と同じと仮定します
select
TD_TIME_FORMAT(time, 'yyyy-MM-dd', 'JST') as day,
action,
avg(elapsed) as average
from
access_log
where
TD_TIME_RANGE(time, '2014-11-01 00:00', '2014-11-7 23:59:59', 'JST')
group by
TD_TIME_FORMAT(time, 'yyyy-MM-dd', 'JST'),
action
これで日付・ページ名・処理時間平均という結果が得られるようになったのですがこのままではグラフに描きづらいので後処理をします。
ここらへんは何でもいいので好きな言語や得意な言語で書くと良いと思います。
この分野はRを使ったほうが断然楽なんですが、PHPでもまとめておくと意外と実用的なのでこういうネタを覚えておくと運用に役立ったりします。
<?php
$data = file_get_contents("a.dat");
$keys = array();
$result = array();
$devs = array();
foreach(explode("\n", $data) as $line) {
$line = trim($line);
if (empty($line)) {
continue;
}
$args = explode("\t", $line);
$result[$args[1]][$args[0]] = $args[2];
$keys[$args[0]] = $args[0];
}
// 日付 ページ名...
// yyymmdd 平均値...
// というように出力しやすいように積み直しつつデータに抜けがある場合は0を入れる
$rows = array();
foreach ($keys as $d) {
$tmp = array();
foreach ($result as $act => $v) {
if (isset($v[$d])) {
$tmp[] = $v[$d];
} else {
$tmp[] = 0.0;
}
}
$rows[$d] = $tmp;
}
//出力
echo "date\t" . join("\t", array_keys($result)) . PHP_EOL;
foreach ($rows as $d => $row) {
printf("%s\t%s\n", $d, join("\t", $row));
}
これで出力結果をグラフに書くとこんなかんじになります。
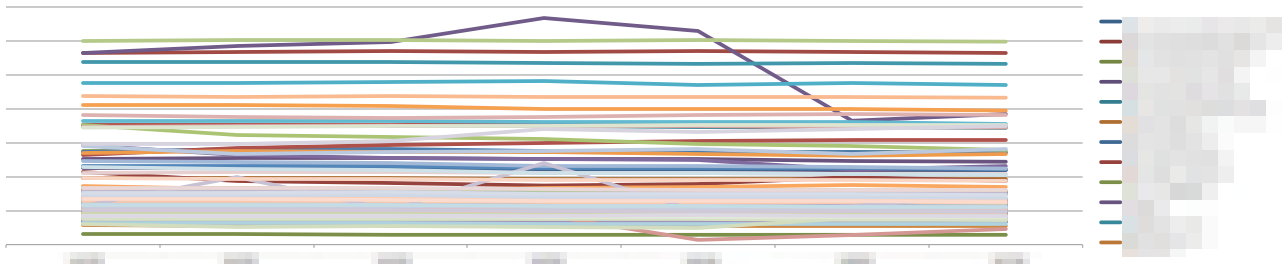
ウッ、項目数が多くて読みづらい…
そんなときは標準偏差を計算してばらつきが大きそうなものだけを表示してみると良いです。
標準偏差の計算方法は平均の差を自乗して足したものを要素数で割ったものをsqrtしてあげると出ます。
function stddev($values) {
$avg = array_sum($values) / count($values));
$r = 0.0;
foreach ($values as $val) {
$r += pow($val - $avg, 2);
}
return sqrt($r / count($values));
}
Presto側でもstddev関数などがあるので前もって計算する事はできるんですが、こうやってあとでごにょごにょするのも楽しいもんです。
標準偏差が一定値以上のページを表示したものが次のグラフです。
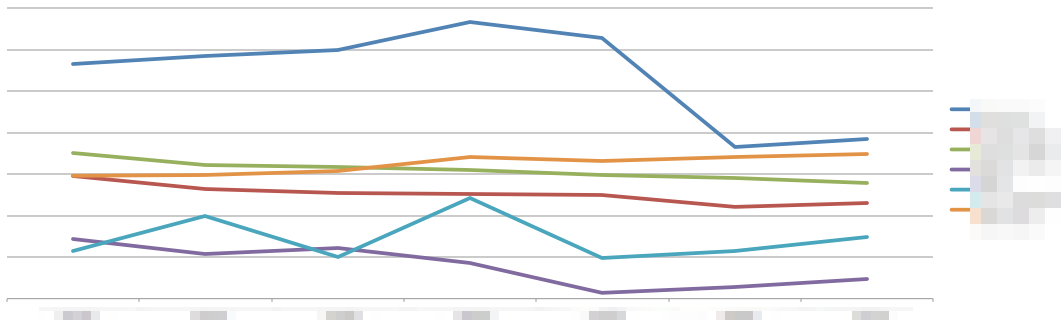
だいぶみやすくなりましたね。
こんな感じで処理結果をごりごりフィルタして書き換えていって突き詰めていくと、だれでも気づけるものは機械に任せていこう、人はもっと素敵なアイデアとか判断ができるように注力しようといったことができるのでやっとくとよかったりします。
え、これTreasureDataに関係なくねって?いやいや、こうやってTreasureDataで集めたデータをどうやって可視化するか、とかをふつうのエンジニアが覚えられると結構べんりなんですよ!