Neural Architecture Search with Reinforcement Learning論文まとめ
- 本論文は2016年11月にsubmitされた論文です。
- arXivはこちら。
- 強化学習とRNNを用いたNAS(深層学習ネットの探索)を提案しています。
- 従来の手法は探索空間が小さかったり、初期のモデルに良いものが与えられないとうまく学習できないといった問題があった。
- この論文の手法は探索空間を広く持ち、scratchから学習が可能。
この記事で説明すること
- 強化学習の概要
- 上記論文の特徴
この記事で説明しないこと
- 強化学習・RNNについての詳細な説明
ザックリとまとめていきます。サクッと見ていきましょう。
強化学習の概要
強化学習とは行動(action)を行うエージェントと、それにまつわる環境の相互作用から、エージェントが学習していく枠組みのことです。
エージェントは行動することにより、環境から報酬というシグナルを受け取り、自身の**行動方針(方策)**を改善していきます。また、環境もエージェントの行動によって変化していきます。
今回の論文では以下のような図で学習の枠組みが定義されています。
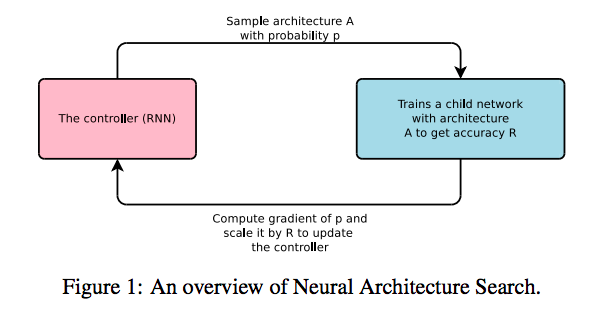
RNNという深層学習モデルがコントローラー(上記で言う所のエージェント)が、構築したいモデルのArchitectureを色々と提案し、それぞれのモデルのAccuracyを報酬として利用します。
ザックリというと、RNNが提案した複数のモデルが、それぞれ独立に学習を行い、それらの精度を受けて、さらによりよい精度を達成するようにRNNが学習していきます。(メインの学習対象はコントローラーのRNNで、欲しいものはRNNの出力する優良なモデル。)
本論文の特徴
今回は論文の流れに沿って見ていきたいと思います。
本論文は以下のような流れになっています。
- シンプルなバージョン
- 強化学習による更新
- 改良したバージョン
シンプルなバージョン
NASではコントローラーが学習モデルの構造的なハイパーパラメータを生成します。例としてCNNを考えると、フィルターの数やストライドの高さ・幅などが該当します。
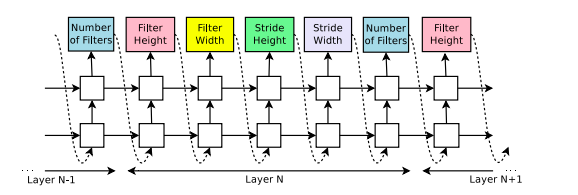
上図は本論文より引用しました。図の下のlayer-N-1は学習モデルのレイヤを示しています。つまり、コントローラーは対象のモデルの下部からハイパーパラメータを決定していきます。
強化学習による更新
コントローラーは提案したモデルの、validation setでの精度の期待値を報酬として受け取ります。コントローラーはこれを最大化するように学習していきます。
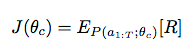
このRの期待値は微分不可能(直接、誤差逆伝播できない)ので、コントローラーのパラメータθを繰り返し更新していきます。
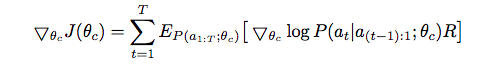
この期待値は直接得られるものではないので、経験的な推測値として以下の式を利用します。
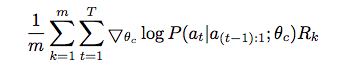
mはコントローラーが一回で提案するモデルの数で、tは時間ステップになります。
改良したバージョン
以下では本論文で提案されている、いくつかの手法を紹介します。
学習を加速させるための手法
NASでは、コントローラーが提案したモデルのそれぞれが安定した精度を得るまで学習させる必要があります。
今回の方法はハイパーパラメータの探索空間が広いので、優良なモデルを得るまでにかなり長い時間が必要になってしまいます。
そこでこの論文ではdistribute trainingという方法を利用します。
S個のパラメータサーバー(複製されたコントローラーの共有された重みを蓄えているサーバ)と、K個のコントローラーの複製を用意します。
それぞれのコントローラーはm個の学習モデルを提案し、それらを並行して学習させます。そして、それぞれのコントローラーは学習モデルから勾配を受け取り、サーバーに送信してパラメータの更新を行います。
実装では設定したエポック分を学習したら更新するようにしています。
より複雑な構造を実現する方法
上記の例で見たモデルでは、下部のレイヤから単純にスタックする方法だったのでGoogleNetやResidual Netのような構造を提案することができませんでした。
こういった入り組んだ構造を提案するためにset selection type attentionという手法が利用されています。
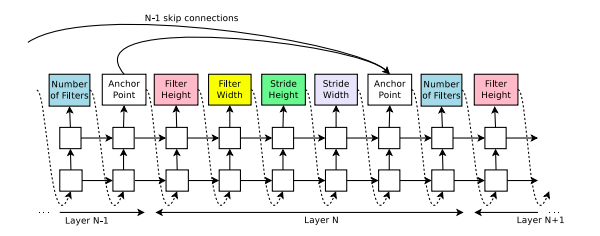
この手法は各レイヤに対応する時刻ステップの後にAnchor Pointというものを設定し、この部分で、以前の時刻の何を入力に使うかを決定します。
これによって、そのレイヤの最適化に必要な入力レイヤを選択することができます。
この方法には二つの問題があります。一つは「入力レイヤが複数の時にサイズが不適合」な場合と「入出力レイヤを持たないレイヤが存在しない」場合です。
前者に対しては、入力レイヤのうち、小さいレイヤを大きいサイズのレイヤに合わせて0paddingのようにしてサイズを合わせる手法を採用しています。後者の問題に対しては、入力レイヤが存在しない場合は一番初めの入力(入力データ)を入れることとし、出力に関しては、全てのレイヤの出力を最終レイヤに接続することで対応します。
Recurrent Cell Architectureの生成
上記ではCNNモデルの生成を見てきましたが、いくつかの修正をすることでRNNやLSTMモデルも生成することができます。
RNN・LSTMは前時刻の中間出力と、現在時刻の入力を結合して出力を生成します。
これを考えるには、結合方法と生成方法の二つを考えます。単純な足し算、要素ごとの積などが結合方法、tanhやsigmoidが生成方法(活性化関数)の手段として考えることができます。これらをハイパーパラメータと考えれば、今まで見てきた手法を応用することができます。
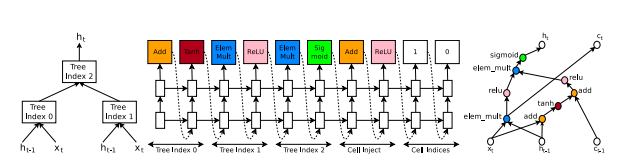
CNNの時とは違い、木構造として考えていることに注意しましょう。
関連論文
- MobileNet v3 2019年発表
補足・イメージ・教訓
- 強化学習の理論の勉強をしてるので、応用例も見ておこうと思い読んで見ました。
- 訓練には800枚のGPUを利用したとのことなので、パワーで殴れる人じゃないと自分で使うのは厳しそうだなぁというのが本音です。
- Distribute trainingとかset-selectionとか個々の手法の他への適用もなんかできそうな気もします。
最後までお読みいただきありがとうございました!
ご質問等あればお気軽にコメントください!