Unsupervised 3D Pose Estimation論文まとめ
- 2019年4月にsubmitされた論文です。
- arXivはこちら
概要
- 単一の画像から得られた2D骨格(論文ではkey pointsやjointsと表現される)から3Dのポーズの推定を行った論文です。
- 3Dのポーズの推定には複数視点からの写真や動画などを利用したものが一般的でしたが、この論文では2D画像のみから生成している点が大きな特徴です。
- 3Dポーズのデータは手間がかかるので教師なし・半教師あり学習が重要になります。この論文では教師なし学習を行うので、大量の3Dポーズデータは必要ありません。
ザックリとまとめていきます。サクッと見ていきましょう。
学習の枠組み
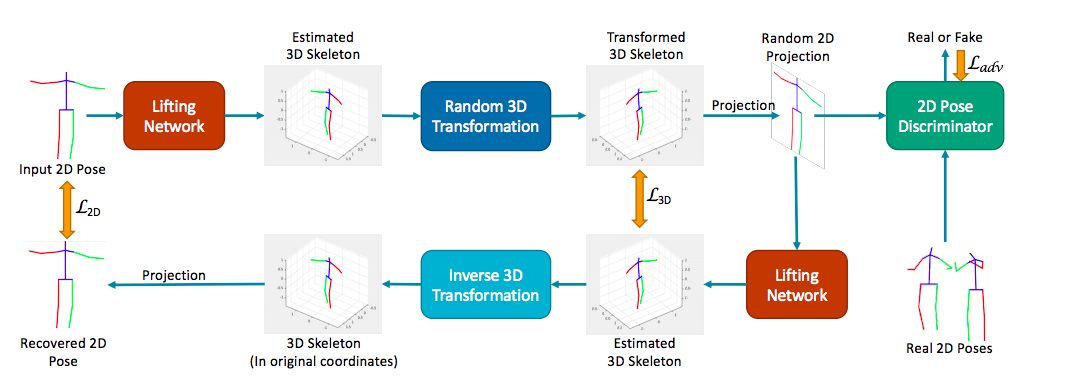
本論文より図を引用しました。順に見ていきましょう。
Lifting Network
Lifting Networkは2Dから3Dのポーズを推定するニューラルネットワークになります。
入力は2D画像のjointsが入り、3Dのポーズ推定を行います。
このネットワークのArchitectureはこちらの論文をベースにしており、こちらのQiita記事に簡潔にまとめられています。
Random Projection
上記のLifting Netが出力した3Dポーズを、別の視点から見た3Dポーズに変換します。この過程自体には学習パラメータは存在せず、教師なし学習のための幾何的な変形になります。
このRandom Projectionの後に2Dのjointsに投影します。こちらも幾何的な変形になります。
Self-Supervision via Loop Closure
ここまでに出てきたデータを確認しておきましょう。
一つは入力に使われた2Djoints(xとします)、そこから推定された3Dポーズ(Xとします)、そしてランダムに投影された3Dポーズ、2Djointsがあります。(それぞれY,yとします。)
上記のyに対して再度、Lifting Netを施すことで、ランダム化された2Djointsから、3Dポーズの推定Y'が得られます。
ある一つの三次元物体の二次元の投影図は様々な形が考えられます。円柱は上から光を照らせば、投影図は円に、側面から照らせば投影図は長方形になります。
しかし、一つの同じ三次元物体から生成された投影図は、仮に三次元への復元が可能であるとすると、同じものに帰着するはずです。(上の例なら「円柱由来の円」と「円柱由来の長方形」は復元すると円柱になる、ということ。)
上記の考えより、この論文ではYとY'の差を損失として学習に利用します。Lifting Netが推定した3Dポーズを幾何的にランダム変形し、それを教師データとして復元するような学習です。(オートエンコーダ的なタスクと言えます。)
また、ここで生成したY'を、先に施したランダム変形を逆向きに行い、投影することで、入力のxを再現するような出力x'が得られます。
Lifting Netが完全に正しく学習できていれば、これはxと一致するはずなので、このxとx’の損失も学習に利用します。
この部分が本論文の大きなポイントで、ここまでの学習で教師データは全く必要ではなく、入力の2Djointsだけから学習を行なっていることに注意しましょう。
Discriminator for 2D Pose
2D Pose Discriminatorは、2Djointsを入力にとり、0〜1のスカラー値を出力するニューラルネットワークです。
何を識別するDiscriminatorかと言いますと、入力された2Djointsが、Lifting Net由来のものか、もしくは本物の2Djointsであるかです。
これが正しく識別されることによって、Lifting Netは「本物っぽい」生成を行うことが求められます。(よくあるGANの損失設定です。)
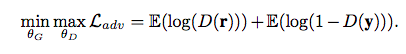
以上が本論文のメインの紹介となります。以下では付随するいくつかのテクニックを紹介していきます。
Temporal Consistency
本論文では2Djointsからの学習を想定していましたが、3Dポーズの推定には、連続的な動作・位置情報が含まれる動画の方が有利です。(コスト的に画像の方が有利だが、利用可能なら動画の方が良い、という感じ。)
そこで、本論文でも動画を入力として利用する場合も想定しており、そのために導入されるのがTemporal Consistencyです。
これは上記のGANLossに似た考え方で、時刻ステップtとt+1の差をとって、それが本物のデータ由来か、それともLifting Net由来であるかを識別する問題になります。
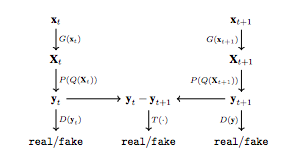
上図にあるように、各時刻での「本物かどうか」の識別を行なった上で、更に「時刻間の関係」の識別問題も行います。
数式は以下のように表現されます。
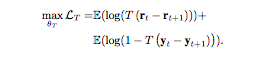
Learning from 2D Poses in the Wild
本論文では入力に2Djointsを利用していますが、画像から2Djointsを抽出する方法はいくつかの手法が存在し、どの手法を使うかによって得られる表現が大きく変わってしまいます。
そこで、2Djointsをドメイン間で対応させる2D domain adapter neural networkを用意し、これを関数Cとします。このニューラルネットワークは、先ほどまでに見てきた識別問題のように、domain Discriminatorと敵対的に学習させます。
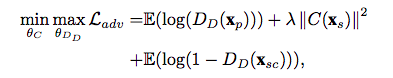
Xscが関数Cによって対象ドメインに近づくように修正された2Djointsです。λは正則化パラメータとして働きます。
このドメイン修正処理はオフラインでの処理になっており、関数Cによって処理したものがLifting Netと2D Pose Discriminatorの入力になります。
学習の枠組みの説明は以上になります。最後に最終的な損失を以下に引用しておきます。
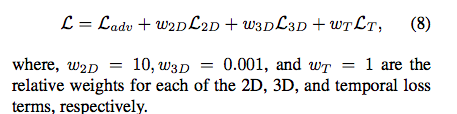
コメント
- 2D画像から3Dのポーズ推定できるの、シンプルに凄いと思いました。奥行きとかのことを考えたら複数視点からデータ取らないと出来ないような気がします。(してました)
- Loop Closureによる学習も面白いなぁと思いました。ある意味ではデータ拡張と言えるような気がします。他のタスクでも応用効きそうな手段に思えます。(画像から点群データの生成とか出来ないかなぁ...)
最後までお読みいただきありがとうございました!
ご質問等あればお気軽にコメントください!