Hybrid Task Cascade for Instance Segmentation論文まとめ
- 2019年1月にsubmitされた論文です。
- Cascade-R-CNNをInstance Segmentationにも適用した論文。
- arXivはこちら
関連論文
- Faster R-CNN論文 2015年発表
- Mask R-CNN論文 2017年発表
- Cascade R-CNN論文 2017年発表
まず本論文の概要を説明し、続いて関連手法を説明する形で見ていこうと思います。
Hybrid Task Cascade for Instance Segmentationの概要
まず、この論文の目指すところは、既存の手法を組み合わせることで高精度なInstance Segmentationの達成です。
Instance Segmentationとは以下のようなものです。(本論文より引用)

ざっくりといってしまうとObject detection(物体検出)とSemantic Segmentation(日本語訳分かりません...)を組み合わせたようなタスクになります。個々の物体(Instance)を認識し、Segmentationを行う感じです。
Instance Segmentationにおけるベースライン的なモデルとしてMask R-CNNという手法が、そして高精度な物体検出手法としてCascade R-CNNという手法が存在します。本論文はこれらを組み合わせることで、より精度の高いInstance Segmentationモデルの開発を目指しました。
しかし、上記のモデルを単純に組み合わせるだけでは、Segmentationの精度があまり上がらないことが分かりました。その理由としてSegmentationを行うモデルの部分(Mask branches)への入力が、洗練された特徴量のみだったことが挙げられています。
この問題に対応するために、Cascadeという考え方(Cascade R-CNNの部分で説明します。)に基づき、処理の流れを変更することで高精度なInstance Segmentationに成功しています。
本論文で提案されたモデル構造については、関連手法の説明の後に記述することにし、とりあえず関連手法を見ていきましょう。
Faster R-CNN
Faster R-CNNは上記では特に触れられていませんが、Mask R-CNN、Cascade R-CNNのベースとなっているモデルであり、Hybrid Task Cascade(以下HTC)でも利用されているモデルになっています。
このモデルはObject Detectionを目的としたモデルになっており、その他の様々なタスクに応用されているもので、モデルの構造は以下のようになっています。
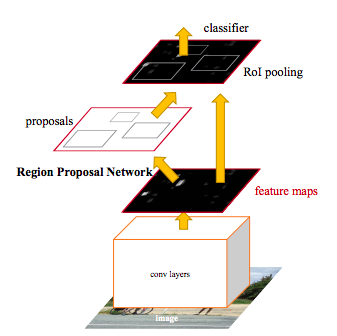
まず画像データに対してConvolutionを施すことで特徴量を取り出し、その後に物体の位置を予測するRPN(Region Proposal Network)に特徴量が流されます。
そしてRPNで物体があると考えられた場所をRoI poolingという操作で取り出し、その場所ごとにClassifierに流し込みます。このClassifierにはConvolutionによって抽出した特徴量も流されていることも重要な点です。
Classifierはバウンディングボックスという物体のある範囲を定める座標とクラス分類の結果を出力します。
以上がFaster R-CNNの簡単な説明になります。このFaster R-CNNを改良したモデルがCascade R-CNNであり、Instance Segmentationに拡張したものがMask R-CNNになります。
二つのモデルを順に見ていきましょう。
Cascade R-CNN
Cascade R-CNNのモデル構造に入る前に、Object Detectionの一般的な問題として、しきい値の設定問題を説明します。
「しきい値の設定問題」の「しきい値」とは何に対するしきい値かというと、**IoU(Intersection over union)**に対する値です。
IoUは教師データのバウンディングボックスと予測したバウンディングボックスの重なり具合の指標になります。(下図参照)
具体的にはIoUがある値以上であればpositive sample(物体)として認識し、それ以下であればnegative sampleとなり、物体として認識しません。
以上の説明を聞くと「しきい値を高くすれば精度の高い検出できそう」と思いますが、実際にはそう簡単にはいきません。
しきい値を小さくするとノイズが入り、大きくすると検出のパフォーマンスが下がることが知られています。
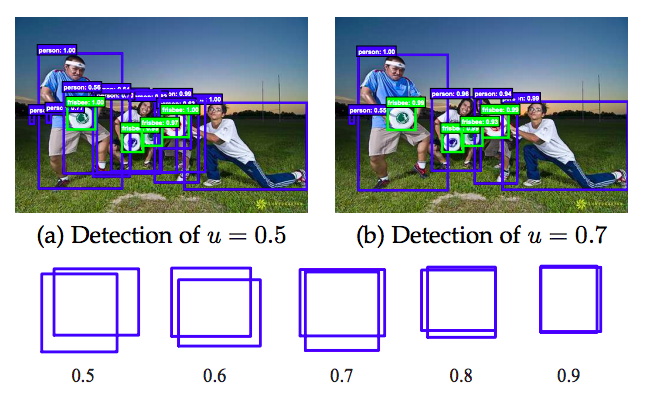
しきい値を大きくした時にパフォーマンスが下がる理由として、以下の二つが挙げられます。
- positive sampleの指数的減少によるOver fitting
- inference-time mismatch between the IoUs for which the detector is optimal and those of the input hypothesis.(論文そのまま引用しました)
1の理由は簡単で、しきい値を高くすることで学習に使われるサンプルが減少してしまいOver fittingが起きやすくなってしまいます。(RoI poolingによってClassifierへと進むサンプルが減少してしまう)
2はdetectorにとって最適なIoUが、必ずしも入力されるデータに対して最適とは限らないということが考えられます。具体的には、全ての画像で綺麗なバウンディングボックスが提示できるとは限らず(遠くに写ってたり、物体が重なっていたり)、そうなるとIoUが高くなりにくくなり、実用的でなくなってしまいます。
→2についてはあんまり理解できませんでした。どなたかご教授いただけると幸いです...!
これらのしきい値問題に対応する手法の一つとしてCascade R-CNNが考案されました。
基本的な考え方としては、複数のしきい値で学習したdetectorを用意することで、上記の問題に対応します。
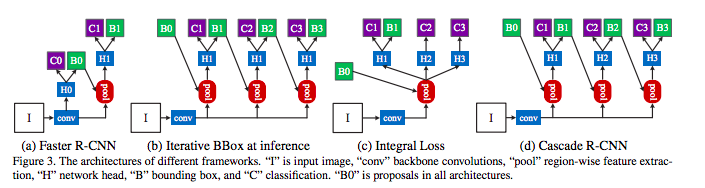
一番右のモデルが推論時に利用されるモデル構造です。’B0’というのはFaster R-CNNのRPNから出力されるバウンディングボックス(Region Propasal)になります。
ここで注意すべきなのは推論時のみdetectorを重ねて配置することです。
B1からB3に向かうほど、学習時のIoUのしきい値が高くなっています。つまりざっくりとした予測から、次第にpreciseな予測へと向かっていくようになっています。
これによって高精度な予測では取りこぼされてしまう物体も拾うことが可能になります。
上記のような、一つの出力を連続的に処理していくような手法をCascadeな処理と言います。
Mask R-CNN
続いて、Instance SegmentationにFaster R-CNNを拡張したMask R-CNNについて見ていきます。
Mask R-CNNはFaster R-CNNにSegmentationのためのモデル構造を追加したような構造になっています。
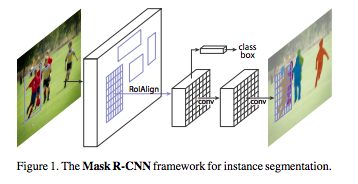
上図の「class box」と書いてある部分がFaster R-CNNの部分で、その下の部分がSegmentationを担うMask branchesとなります。
このMask branchesは画像の空間的な情報を必要とするため、Convolutionをメインとした構造(ResNetやFPN)が用いられることが一般的です。
Faster R-CNNとのもう一つの大きな違いが、RoI Alignという処理です。
RoI poolingは小さい特徴量マップに対する特徴量抽出する一般的な手法ですが、その操作内のQuantization(量子化)はピクセルごとの判断を要するタスクに対して悪い影響を与えると考えられています。(クラス分類のような画像全体に対するタスクに関してはロバストであると考えられる。)
※RoI poolingは実数で構成されるRoIをfeature mapのサイズでスケーリングした後に小数点以下を切り捨てる操作が一般的です。これをMask R-CNN論文内ではquantize(量子化)と表現しています。
そこでMask R-CNNではRoI poolingに変わる手法としてRoI Alignを適用しています。RoI Alignは、RoI poolingから単純に量子化操作を省いたものになっています。
以上がHTCの関連手法のざっくりとした説明になります。続いてHTCのモデル構造について確認しましょう。
HTC のモデル構造
まず、HTC論文の問題意識・背景を再度確認しましょう。
はじめに、Cascade R-CNNとMask R-CNNを組み合わせることで、高精度なInstance Segmentationを達成しようとしました。
しかし、実際にやってみるとバウンディングボックスの精度はよく向上したものの、Segmentationに関してはあまりCascadeの恩恵を受けていない結果となりました。
その理由として著者たちはSegmentation部分はモデルの後半部分に位置するために、「洗練された」特徴量のみを利用していることが挙げられており、Information flowを変化させることでよりよいモデルが得られると仮定し、新しいモデル構造を構築していきました。
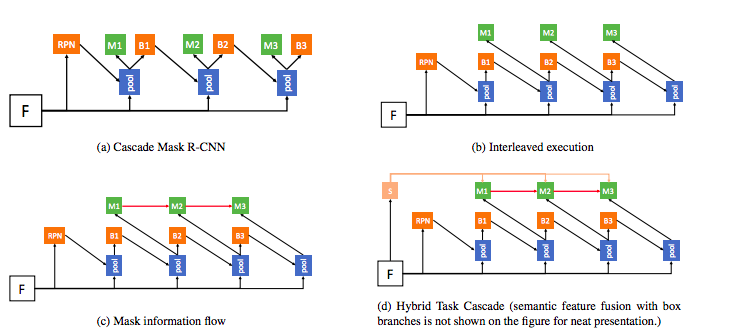
上記の図(本論文より引用)を用いて簡単にモデル構築の流れを見ていきます。
(a)はMask R-CNNに単純にCascadeを適用したモデルになります。図内の’B’はバウンディングボックスを、’M’はSegmentationを表しています。(MはMaskのMです)
このモデルの計算式は以下のようになります。
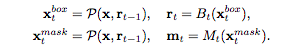
PはPooling、B,MはバウンディングとSegmentationのbranchを表しています。
このモデルは先述したように、バウンディングボックスに関しては良い結果が得られたものの、Maskに関しては微妙な結果でした。
このモデルの欠点としてバウンディングボックスとSegmentationが並行的に処理されてしまっているために、結果としてそれぞれが独立に学習してしまっているという点です。
そこで、二つのタスクを織り交ぜた(b)のようなモデルを構築しました。
※Interleaveが織り交ぜるという意味です。
このモデルの計算式は以下になります。
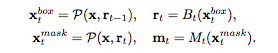
先ほどの計算式と比べると二行目のXmaskの入力の添字が変わっていることが分かります。
このモデルはmask branchesがバウンディングボックスの予測を利用する形になっており、パフォーマンスが向上したことが述べられています。
上記のデザインは、各マスクの予測はRoIの特徴量とバウンディングボックスの予測を利用しており、そこには前段階のSegmentationの予測に関しては間接的な情報利用になっています。
そこで、Cascadeの「前段階の予測を利用する」という考えに則り、前段階のSegmentationの情報を現段階に注入するモデル構造に変更しました。これが上図の(c)に該当します。
計算式は以下のようになります。
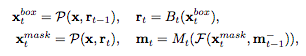
mt-1が前段階のSegmentationの結果になり、これを元にして処理をしてから現段階のSegmentationを予測しています。
以上のモデル構造に加えて、画像の前面と後面を見分けるのを助けるために、空間的な情報をより利用することを考えます。
そこで、ここまで使っていたMask(Segmentation)の予測のみを出力するMask branchから、予測と特徴量を出力するSegmentation branchに変更します。
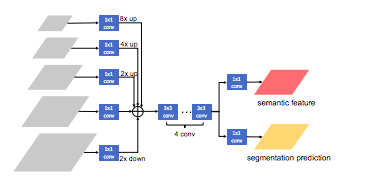
この図の「semantic feature」がモデル概要図の'S'に該当し、各段階のMaskの予測に利用されます。
HTCの最終的な計算式は以下のようになります。
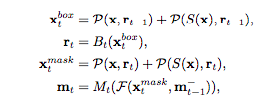
以上がHTCのモデル構造の説明となります。
要点をまとめると以下のようになります。
- 二つのR-CNNをシンプルに組み合わせたものはSegmentationの結果が微妙だった
- Segmentationの結果を向上させるために情報の流れを変更した(CascadeとSemantic featuresの利用)
コメント
- Faster R-CNNは偉大でした
- Cascadeの絞り込んでいく感じは他のタスクでも使えそうな気がしました
補足
Cascade R-CNNの著者らがCascade R-CNNをInstance Segmentationに適用した論文が最近発表されましたが、HTCの方が精度が高いようです。
Cascade R-CNN:High Quality Object Detection and Instance Segmentation 2019年6月発表
最後までお読みいただきありがとうございました!
ご質問等あればお気軽にコメントください!