概要
自然言語処理分野で単語をベクトル化するWord2vecというモデルがありますが、これをECサイトなどでの商品推薦に応用した手法としてitem2vecという手法があります。
Word2vecでは与えられた文章における単語の出現頻度や距離を元に各単語をベクトル(「単語の分散表現」とも呼ぶ)に変換し、類似度計算や機械学習などで扱えるようにします。
これを応用して、ユーザーの行動履歴やアイテムに対するリアクションの情報をあたかも文章内に現れる単語のように捉え、各アイテム、各リアクションのベクトルを算出して推薦システムに使えるようにしたのがitem2vecという手法です。
2016年に発表された「Item2Vec: Neural Item Embedding for Collaborative Filtering」という論文がアイデアの初出です。
具体的な実用例として、グロービスさんやメルカリさんのテックブログで旧来の推薦モデルよりABテストで良い成績を出した事例が紹介されています。
近い推薦手法としては協調フィルタリングがすぐ思い浮かびますが、item2vecはたとえば購入時期が近いものはベクトル空間内で近くに位置付けるといったことが可能なので、買ったばかりの商品に相補性が高いものを推薦するような時間感覚も考慮に入れた推薦を実現できるのではないかと考えられます。
ということで実際にMovieLensを使ってitem2vecを軽く試してみたいと思います。
実装
セットアップ
ライブラリのインポート、データセットの準備を行います。
データセットはレビュー情報100万件を格納したMovieLens 1M Datasetを使用。
Word2vecの処理にはGensimライブラリが定番らしいのでこれを使います。
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import requests
import zipfile
import os
import time
from scipy.sparse.linalg import svds
from gensim.models import Word2Vec
# データセットをダウンロードし解凍
url = "https://files.grouplens.org/datasets/movielens/ml-1m.zip"
zip_path = "ml-1m.zip"
response = requests.get(url)
# - wb: バイナリファイルへの書き込み
with open(zip_path, "wb") as f:
f.write(response.content)
with zipfile.ZipFile(zip_path, "r") as zip_ref:
# "."でカレントディレクトリに解答
zip_ref.extractall(".")
# 作品情報のデータセットを読み込む
movie_columns = ["movie_id", "title", "genres"]
movies_df = pd.read_csv(
"./ml-1m/movies.dat",
sep="::",
engine="python",
names=movie_columns,
index_col=0,
encoding="latin1"
)
# 文字列を20文字に制限して省略
def truncate_title(title, length=30):
if len(title) > length:
return title[:length] + "..."
return title
movies_df['title'] = movies_df['title'].apply(truncate_title)
# read ratings.data
rating_columns = ["user_id", "movie_id", "rating", "timestamp"]
ratings_df = pd.read_csv(
"./ml-1m/ratings.dat",
sep="::",
engine="python",
names=rating_columns,
encoding="latin1"
)
ユーザーの評価ヒストリーをリスト化
word2vecで各映画をベクトル化するため、ユーザーが評価した映画の一覧をリストにします。低評価だった作品をレコメンドしてもユーザーから好感を得られるとは考えにくいので、便宜上評価「4」以上のものだけ抽出します。このリストをモデル学習に使います。
# timestampでソートした評価履歴DataFrameを作成
time_sorted_ratings = ratings_df.sort_values("timestamp")
# ratingが4以上のものだけ抽出
filtered_ratings = time_sorted_ratings[time_sorted_ratings["rating"] >= 4]
# user_idごとにまとめる
ratings_by_user = filtered_ratings.groupby("user_id")
# movie_idのリストを作り、movie_list列に格納する(リネームする)
user_movie_history = ratings_by_user["movie_id"].apply(list)
user_movie_history = user_movie_history.rename('movie_list')
# プレビュー
user_movie_history.head(3)
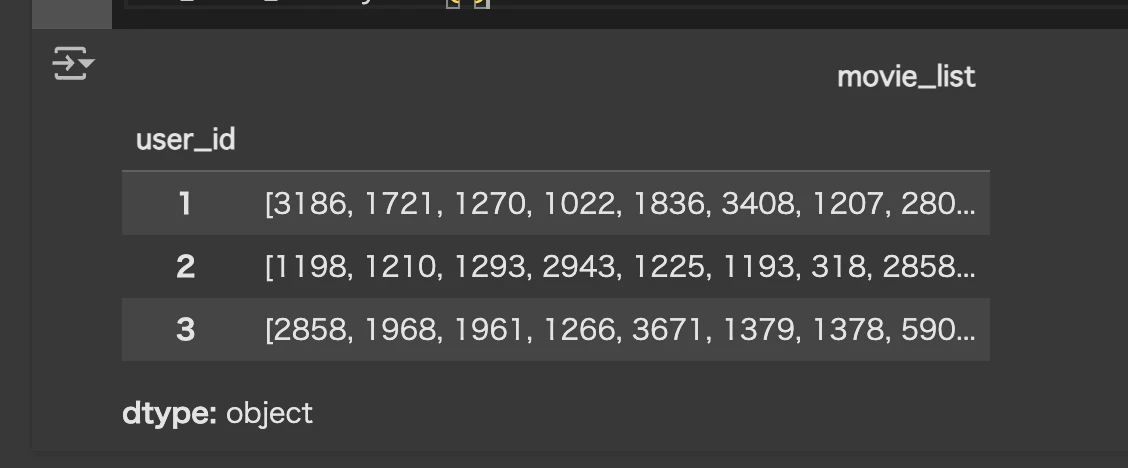
ユーザーIDごとの高評価した作品リストが得られました。
Word2Vecモデルの学習
先ほど作成したユーザーの映画評価履歴リストを使い、モデル学習を行います。
- Word2Vecの引数について
-
sentences:iterableなリスト形式のデータ。ここではpandasのSeries型のデータを渡しています。 -
vector_size:単語(ここではmovie_id)をベクトル化したい次元数 -
window:中心単語からのコンテキスト単語の範囲(ウィンドウサイズ)。ここでは前後5単語を指定。 -
min_count:トレーニングに含める単語の最小出現回数。 -
sg:学習アルゴリズムを指定。sg=1でSkip-gramを使用(中心単語から周囲の単語を予測)。 -
workers:トレーニング時に使用するスレッド数。
-
print("Train start...")
start_time = time.time()
# Word2Vecモデルのインスタンスを作成し、学習を実行
model = Word2Vec(
sentences=user_movie_history,
vector_size=10,
window=5,
min_count=1,
sg=1,
workers=4
)
print("Train finished.")
print("実行時間: ", time.time() - start_time)
推薦結果
学習したモデルを使い、実際に映画ごとの推薦を実行してみます。
# 映画推薦関数
def recommend_movies(movie_id, top_n=5):
try:
# 指定されたmovie_idに類似する映画を取得(movie_idと類似度のタプルの配列を取得)
similar_movies = model.wv.most_similar(movie_id, topn=top_n)
return [(int(movie[0]), movie[1]) for movie in similar_movies]
except KeyError:
print(f"Movie ID {movie_id} not found in the training data.")
return []
target_id = 589
# レコメンデーション関数呼び出し
recommendations = recommend_movies(target_id)
print("Target movie ID:", target_id, ",", movies_df.loc[target_id]['title'], "\n")
for recommend in recommendations:
print(recommend[0], ":", movies_df.loc[recommend[0]]['title'])
Target movie ID: 589 , Terminator 2: Judgment Day (19...
2571 : Matrix, The (1999)
457 : Fugitive, The (1993)
1240 : Terminator, The (1984)
3000 : Princess Mononoke, The (Monono...
1200 : Aliens (1986)
『ターミネーター2』(id: 589)だと『マトリックス』や『ターミネーター(初代)』など結構近そうな作品がヒットしてくれました。他の作品でも試してみます。
Target movie ID: 1 , Toy Story (1995)
1223 : Grand Day Out, A (1992)
34 : Babe (1995)
3114 : Toy Story 2 (1999)
1148 : Wrong Trousers, The (1993)
3429 : Creature Comforts (1990)
『トイストーリー』の例です。続編の『トイストーリー2』を差し置いて1番目に『ウォレスとグルミット』、2番目に『ベイブ』が来ているのは公開時期が近かったからでしょう。
Target movie ID: 3000 , Princess Mononoke, The (Monono...
2987 : Who Framed Roger Rabbit? (1988...
589 : Terminator 2: Judgment Day (19...
457 : Fugitive, The (1993)
3213 : Batman: Mask of the Phantasm (...
2692 : Run Lola Run (Lola rennt) (199...
『もののけ姫』(1997年)だと1番目にアニメ映画『ロジャー・ラビット』が来ましたが、並べてオススメするのに相応しい作品かと問われると微妙ですね。
 (これがロジャー・ラビット。いかにもアメリカン)
(これがロジャー・ラビット。いかにもアメリカン)
比較のために協調フィルタリングでも試してみましたが、この作品については協調フィルタリングの方が理想に近い推薦ができている気がします。ただこれについては元データの偏りの問題でもあるでしょう。

おわりに
ここしばらく協調フィルタリング、特異値分解、item2vecと推薦アルゴリズムの基本的な手法を使って色々推薦システムを試してきて、どの手法を使ってもある程度まともっぽい推薦が実現できると分かりました。
もちろんそれぞれ一長一短な点があり、目的と条件にあったデータの準備、アルゴリズム選定をしていく必要はあります。コールドスタート問題やリアルタイム推薦などに取り組むならさらなる工夫が求められるでしょう。一言で推薦システムと言っても沼は深いです。
とはいえ、無機質なデータの集まりから「アイテムを推薦する」という擬人的な現象を実現することができるのはシンプルに面白いです。開発というのはこうでなくちゃって改めて思いました。
感想文はこのあたりで、それでは皆さま素敵なレコメンドライフを。
参考