言いたいこと
- GraphQLのAPIを自前で実装するのは面倒なんでこういうのに頼って楽したい
- Prismaもいいと思うが、PostgreSQLならHasura GraphQL Engineも結構いい
- Prismaと違ってHasura GraphQL Engineはクライアントから直接呼ばれることも可能だが、凝った実装しようとするとやはりClient専用のGraphQL Serverは必要
Hasura GraphQL Engineって何?
PrismaはPostgreSQLだけでなく、MySQL等のその他のRDBMSに対応したGraphQL Serverを構築しますが、Hasura GraphQL EngineはPostgreSQL専用のGraphQL Serverを構築します。
構築方法
結構ドキュメントがしっかり作られていて、正直この記事書く必要ないと思うくらいです。英語アレルギーの人は私の拙い日本語記事を参考にやってみてくれると幸いです。
Hasura GraphQL Engineのセットアップ
公式ドキュメントではHerokuを作った方法とDocker(-compose)を使った方法の2種類が記載ありますが、明らかにDockerを使った方が楽なので、その方法で本記事は記載します。
$ mkdir hasura_sample
$ cd hasura_sample
$ wget https://raw.githubusercontent.com/hasura/graphql-engine-install-manifests/master/docker-compose/docker-compose.yaml
まずはwgetで更新サンプルのdocker-compose.ymlを取得します。中身は特に凝った内容ではないです。
version: '3.6'
services:
postgres:
image: postgres
restart: always
volumes:
- db_data:/var/lib/postgresql/data
graphql-engine:
image: hasura/graphql-engine:v1.0.0-alpha13
ports:
- "8080:8080"
depends_on:
- "postgres"
restart: always
environment:
HASURA_GRAPHQL_DATABASE_URL: postgres://postgres:@postgres:5432/postgres
command:
- graphql-engine
- serve
- --enable-console
volumes:
db_data:
ただ、私の環境ではversion 3.6に対応していないので、version 3.3に落としたりしております。
そのままdocker-compose up叩けば終わりです。(公式では-dでデーモン起動にしてますが、ログを見たいのでデーモン起動なしで起動しています。)
PostgreSQLにテーブル作成
GraphQLで取得するデータの格納先となるPostgreSQLのテーブルを作成する必要があります。
もちろん既存のDBに接続する場合はこの処理は不要です。
先程のdocker-composeを立ち上げた状態ならばhttp://localhost:8080/consoleでHasura GraphQL Engineのコンソールにアクセスできるはずです。
まずはGraphQLで取得するデータを格納するテーブルを作成します。
画面上部にあるDATAタブをクリックし、schemaを作成する画面を表示します。
(余談ですが、画面はReactでできてますね)
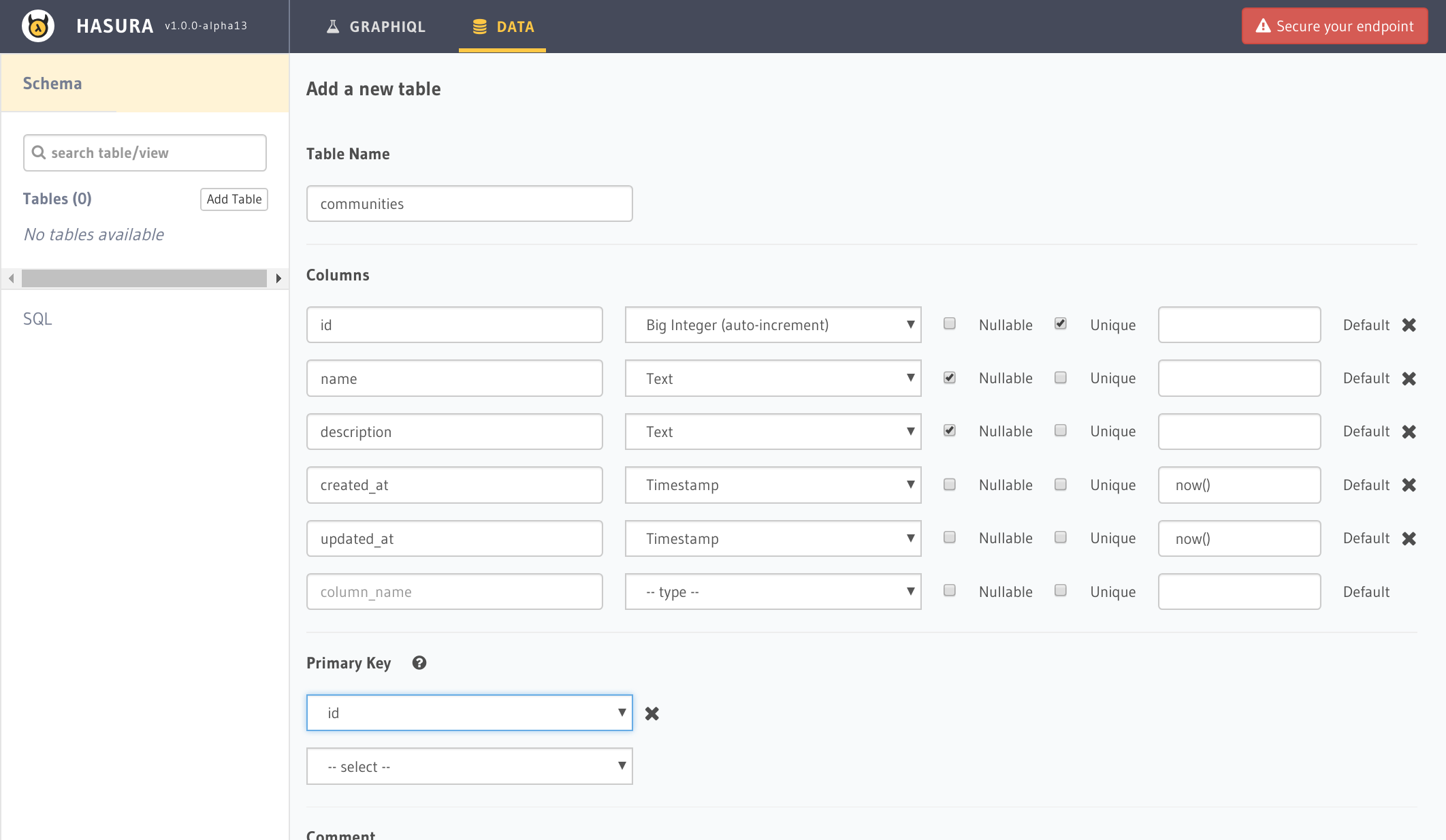
画面中央にある``Create Tableボタンをクリックするか、左メニューにある、Add Table`をクリックすることでschemaの定義画面が開けます。そこで必要な情報を入力することでテーブルが作成されます。今回は例として、コミュニティというテーブルを作成し、カラムとしては`id`と`name`と`description`の3カラムを用意するものとします。(Railsを意識してテーブルを作ってます)
次に作成したコミュニティに子テーブルとなるイベントテーブルを以下のように作成します。
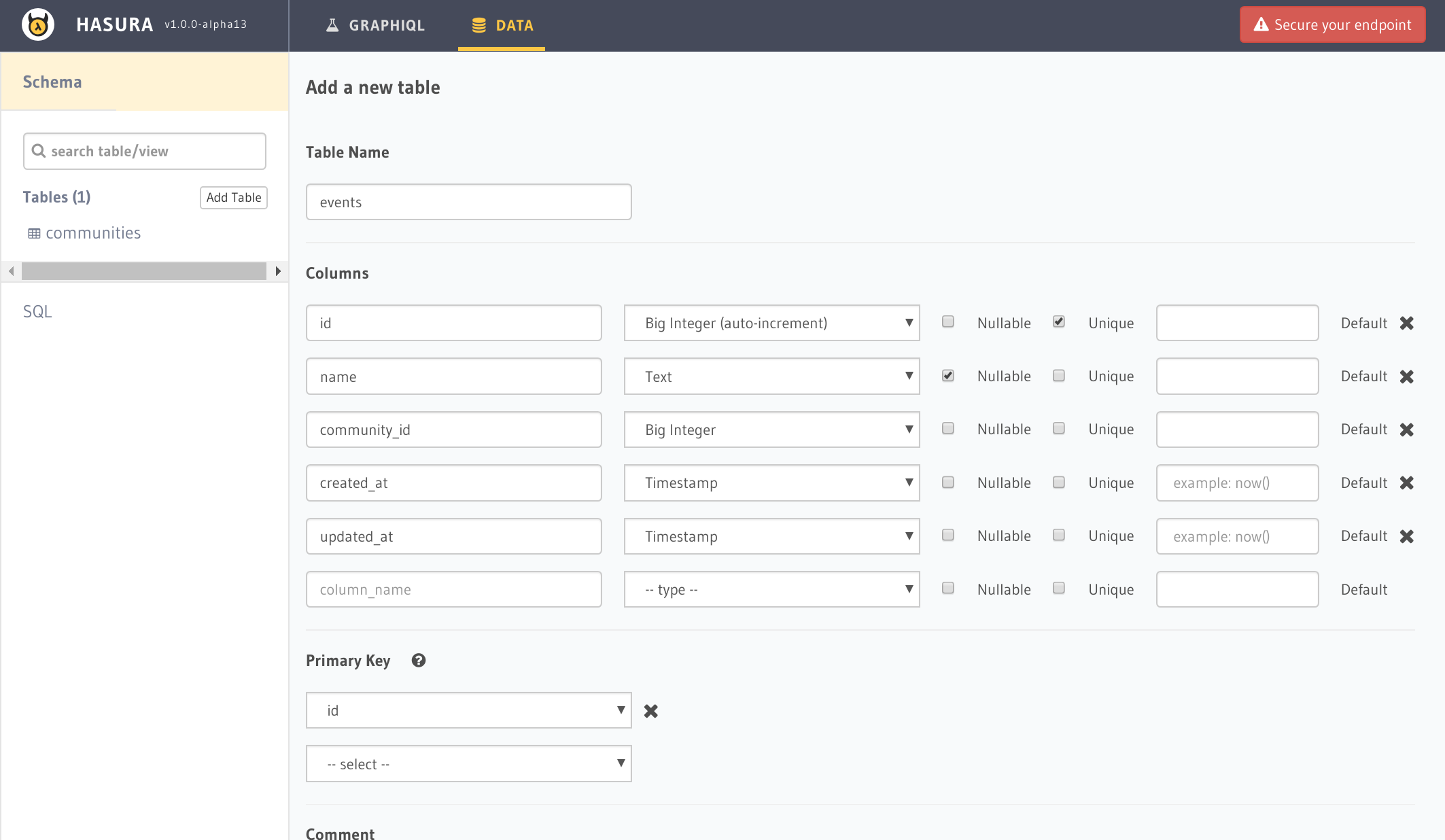
大事なのはコミュニティテーブルとリレーションを貼るcommunity_idです。
テーブルのリレーションを作成
作成したコミュニティテーブルとイベントテーブルのリレーションを定義し、GraphQLで解釈できるようにします。まずはイベントテーブルにForeign Keyを作成します。作成したイベントテーブルを開き、Modifyタブで以下のように設定します。
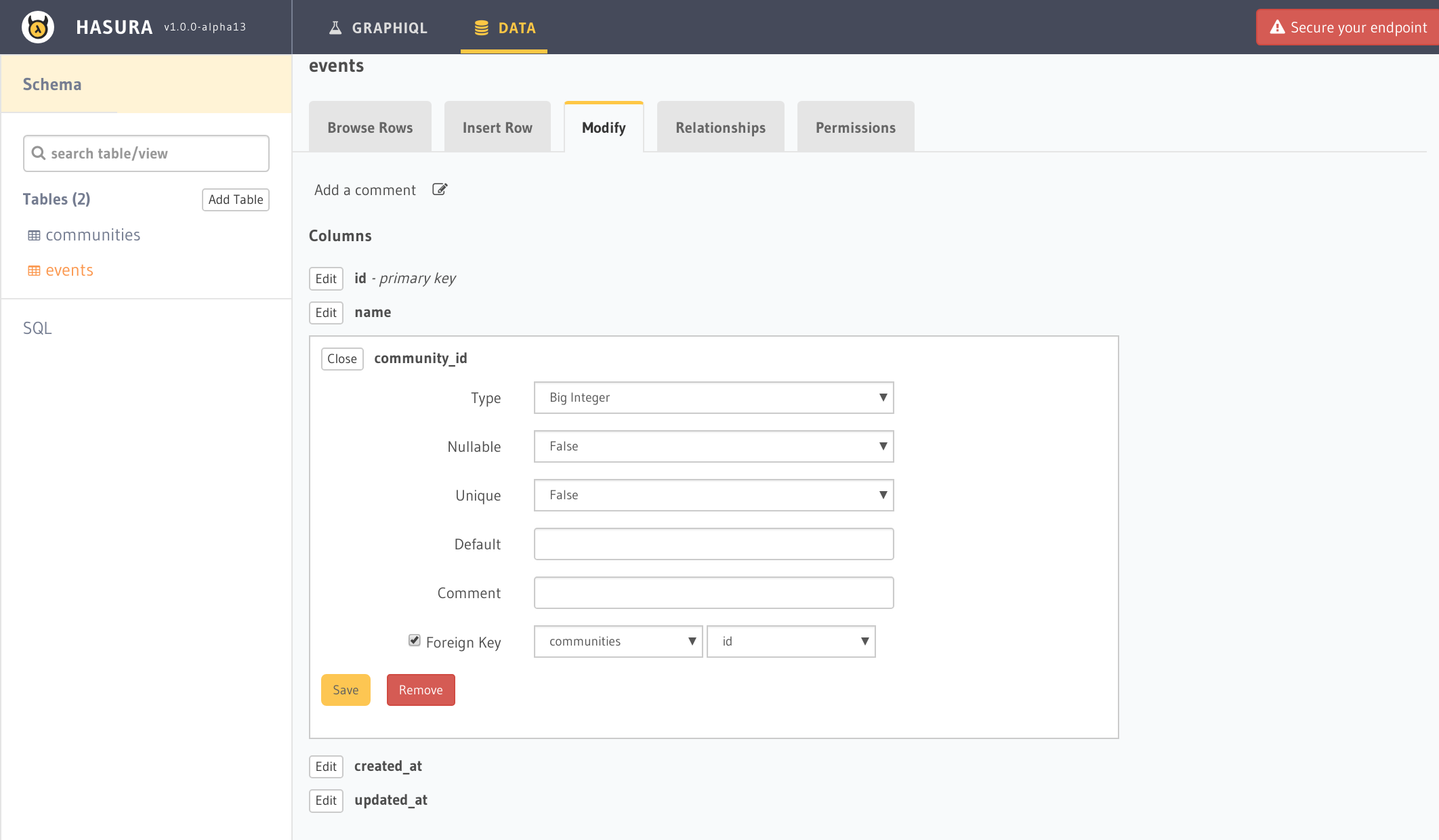
これでForeign Keyの設定は完了したので、次にコミュニティテーブルからイベントテーブルへのリレーションを作成します。コミュニティテーブルを開き、Relationshipsタブを開くとAddボタンがあると思うので、クリックすると名称の登録が開きます。ここの名称は1コミュニティから見たイベントデータなので、eventsとしておきます。要は後に使用するGraphQL queryで1communityに対するイベントデータを取得する名前になります。
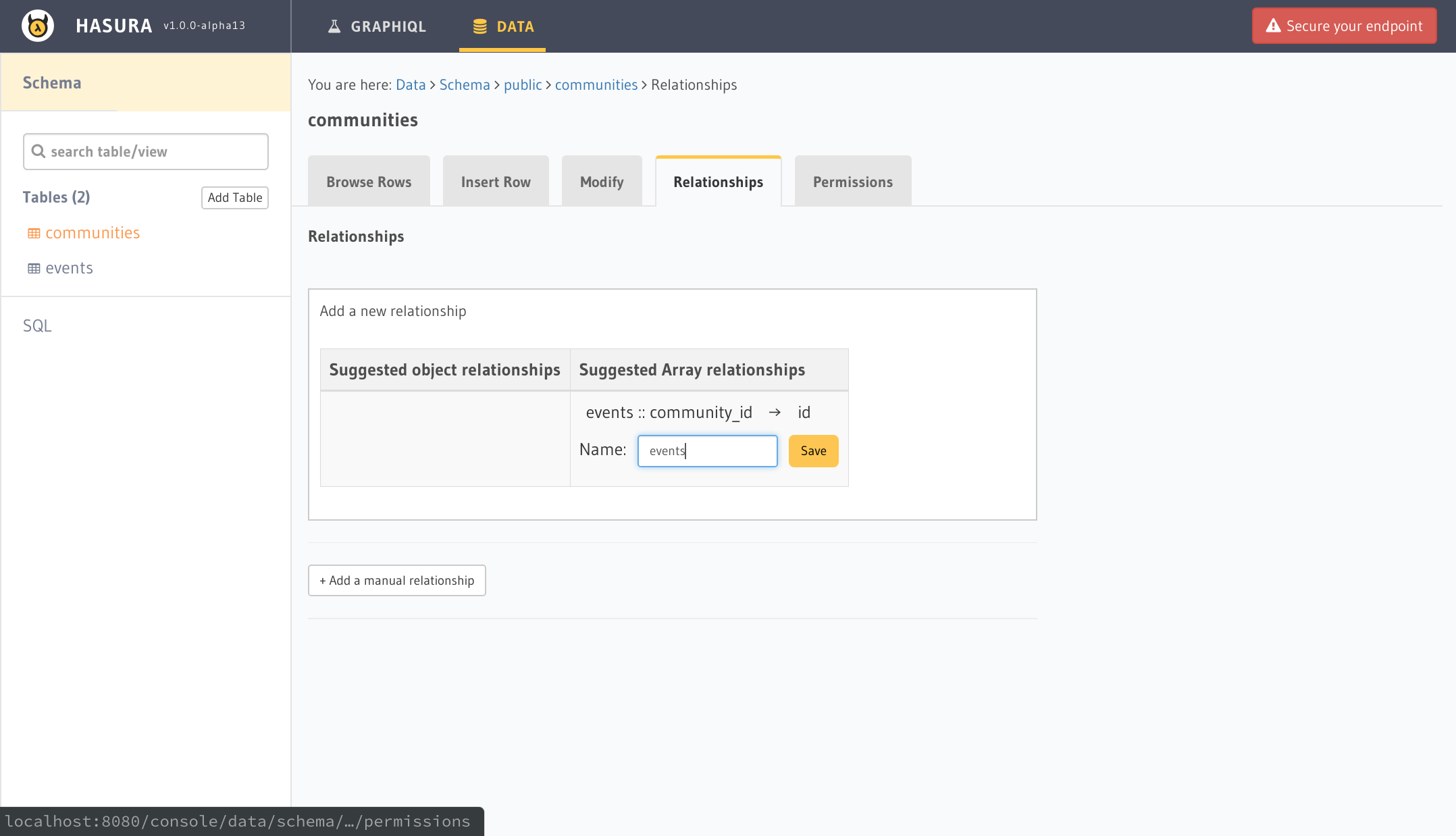
これであらかたのテーブル定義が完了です。もちろんイベントテーブルからコミュニティテーブルを参照するようなGraphQL queryが必要な場合は逆方向のリレーション登録も必要です。
GraphQLの実行
画面上部にあるGRAPHQLタブを開くことによってGraphQLを実行することが可能です。
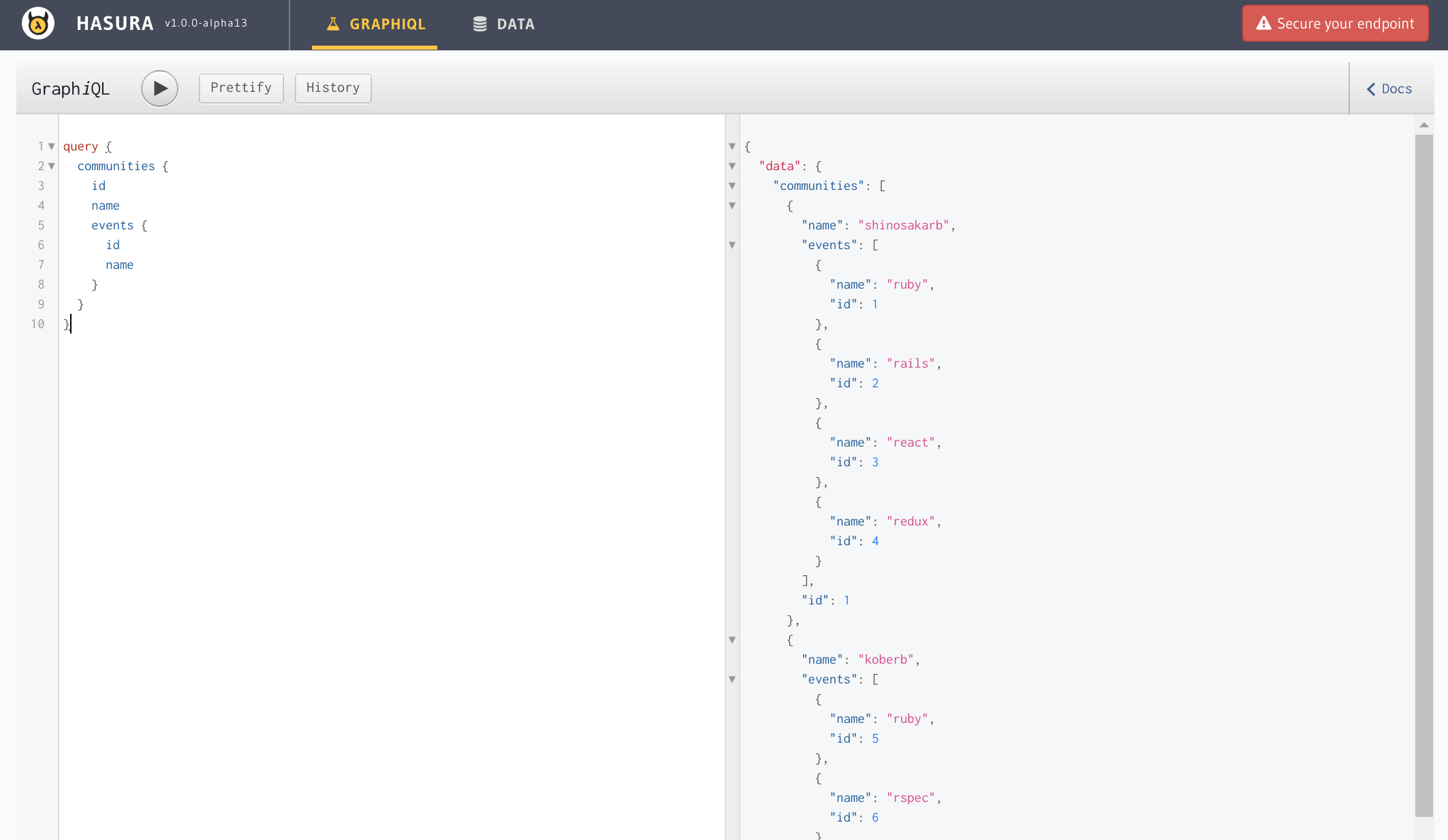
という感じに既にGraphQL Serverが完成しています。データの絞り込み(where)やソート(order_by)のSQLを書く間隔で使用できて、私的にはとてもわかりやすい。
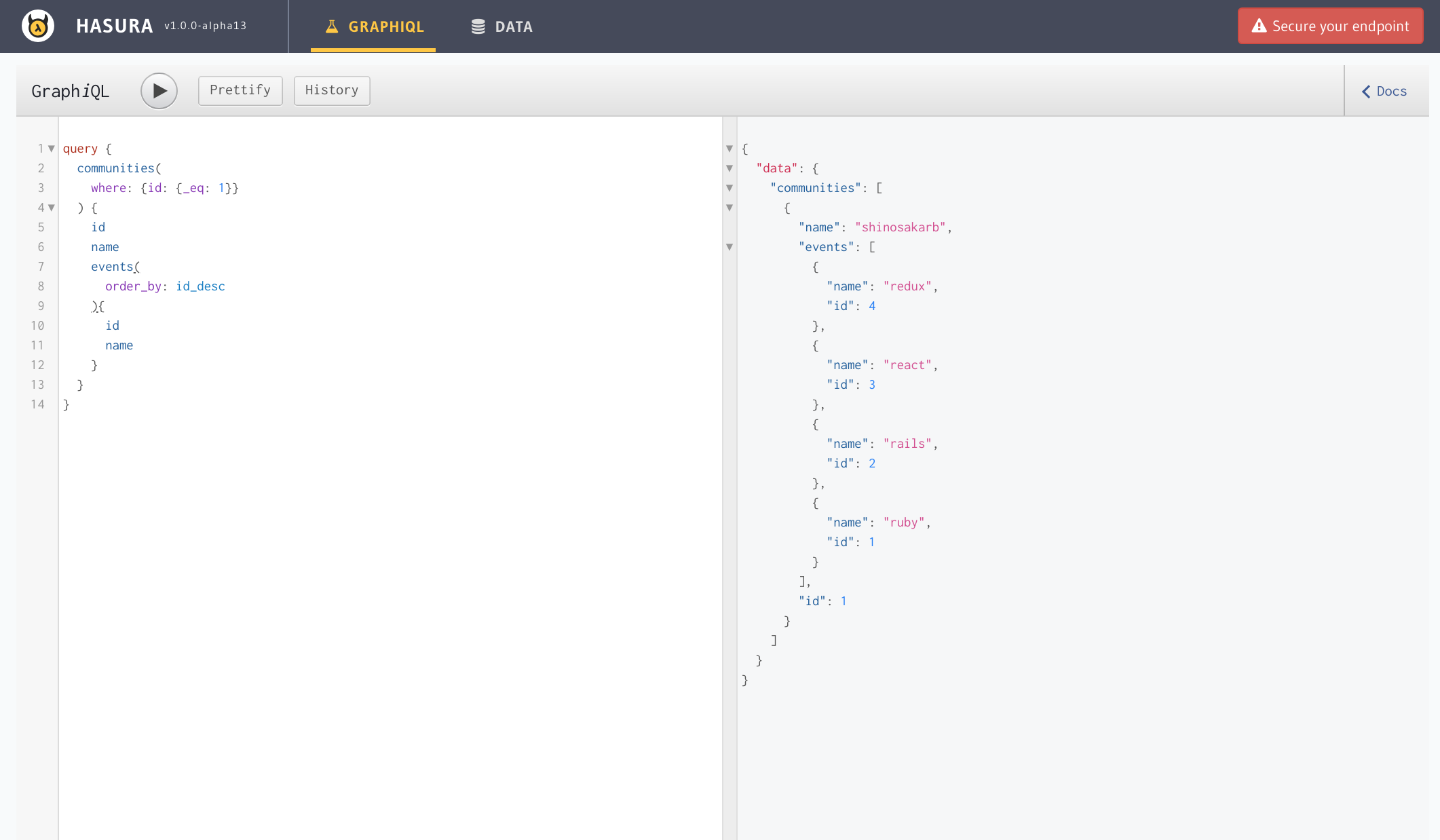
もちろんlike検索も可能です。
通常のCRUDならとても簡単に実装できてしまいました。
認証・認可
認証
認証が必要ならばwebhookで実装することも可能。
https://docs.hasura.io/1.0/graphql/manual/auth/index.html
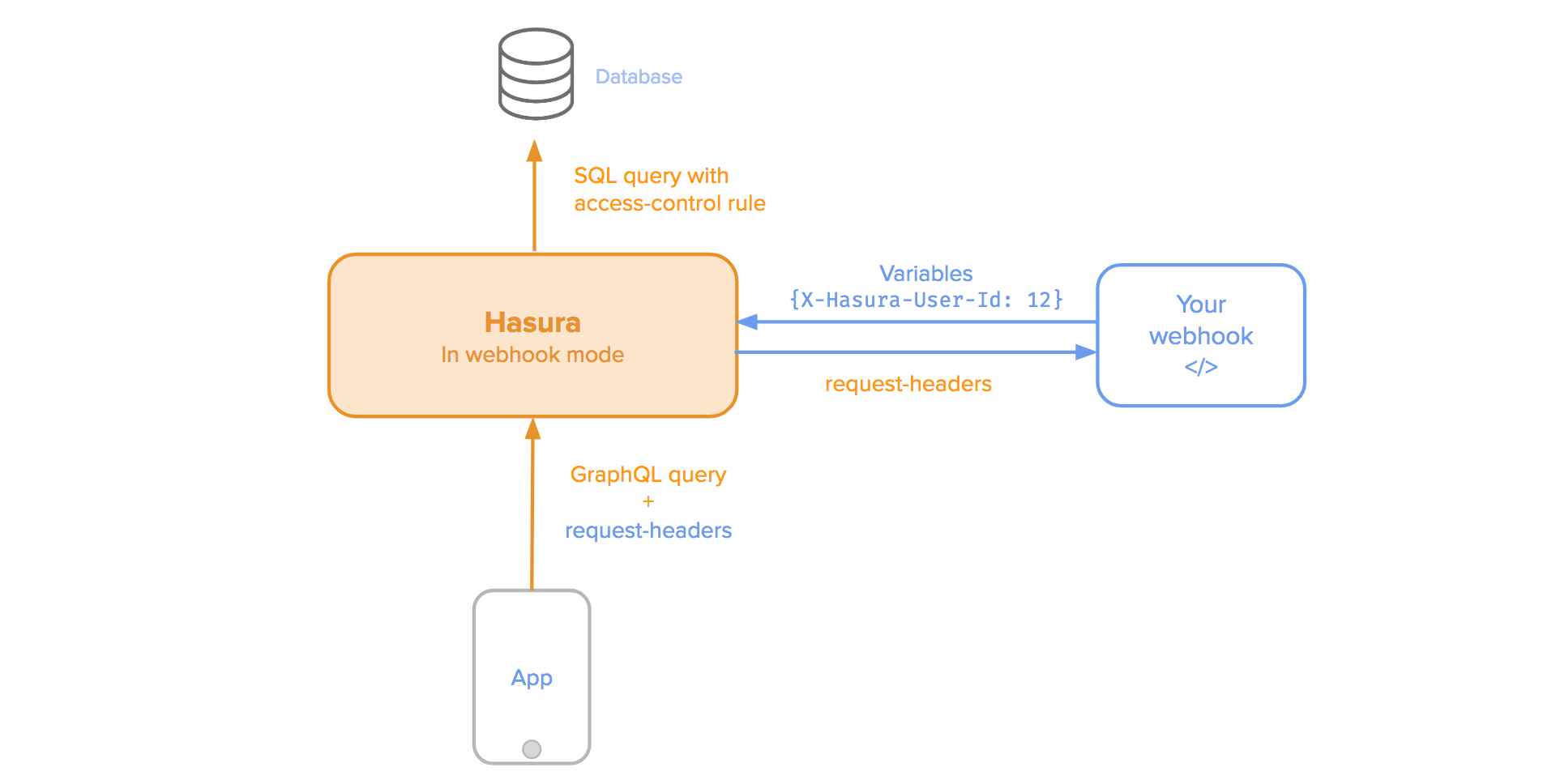
もちろん、webhookで受けた先の認証は好きに行なえますが、AWS cognitoを使ってもよし、firebaseも使ってもよしで実装できるならなんでも可能です。
認可
認可もある程度は定義できそうです。
https://docs.hasura.io/1.0/graphql/manual/auth/common-roles-auth-examples.html
例を交えて設定例を下記に書きます。
例えばwebhookで認可するユーザIDが判明した場合に、そのユーザのみが参照できるデータを表示するということを想定したいと思います。
まずは作成したコミュニティテーブルに作成者となるuser_idを追加します。
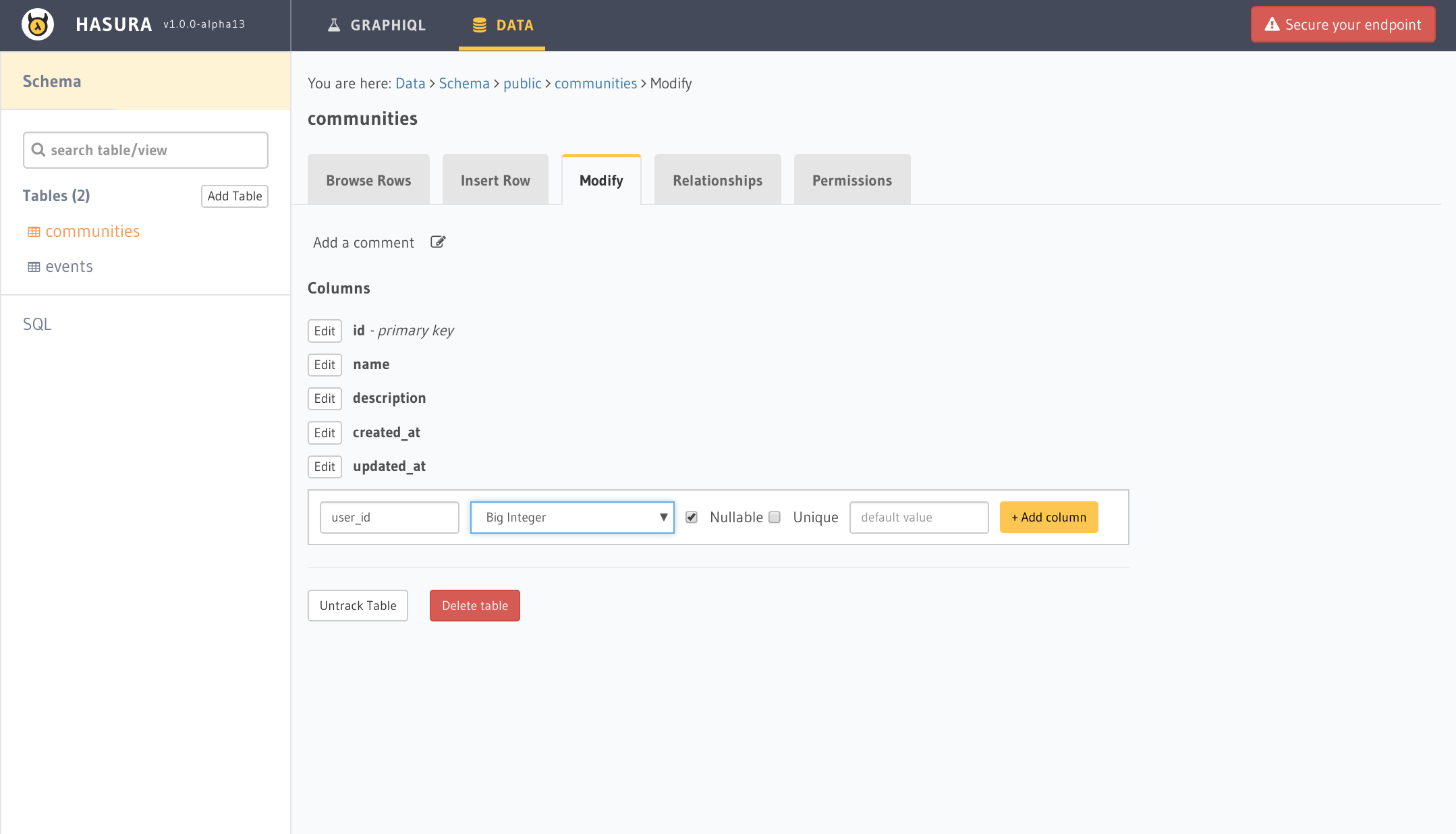
次にPermissionsタブを開きuserというロールを追加した後に以下のようにX-HASURA-USER-IDというパラメータで先程作成したuser_idが一致するもののみ表示する設定にします。このX-HASURA-USER-IDはGraphQLのAPI呼び出しの際にhttp headerとして付与する必要があります。もし認可にwebhookを使っているならwebhookのレスポンスに設定するといいです。
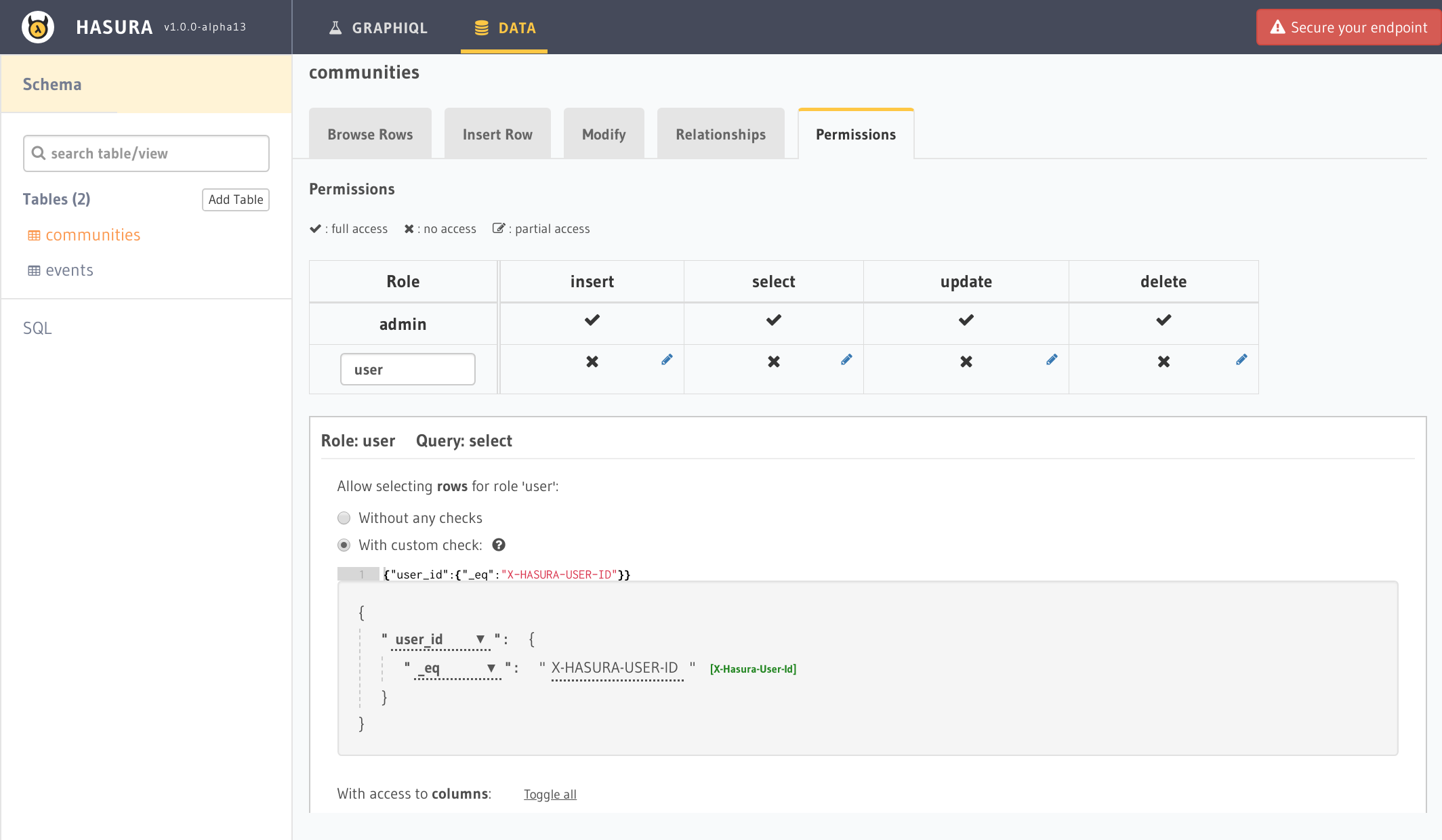
現状の設定ではhttp headerに何もつけなければすべて取得する認可設定となっているので、以下のようにすべてのデータが取得できてしまいます。
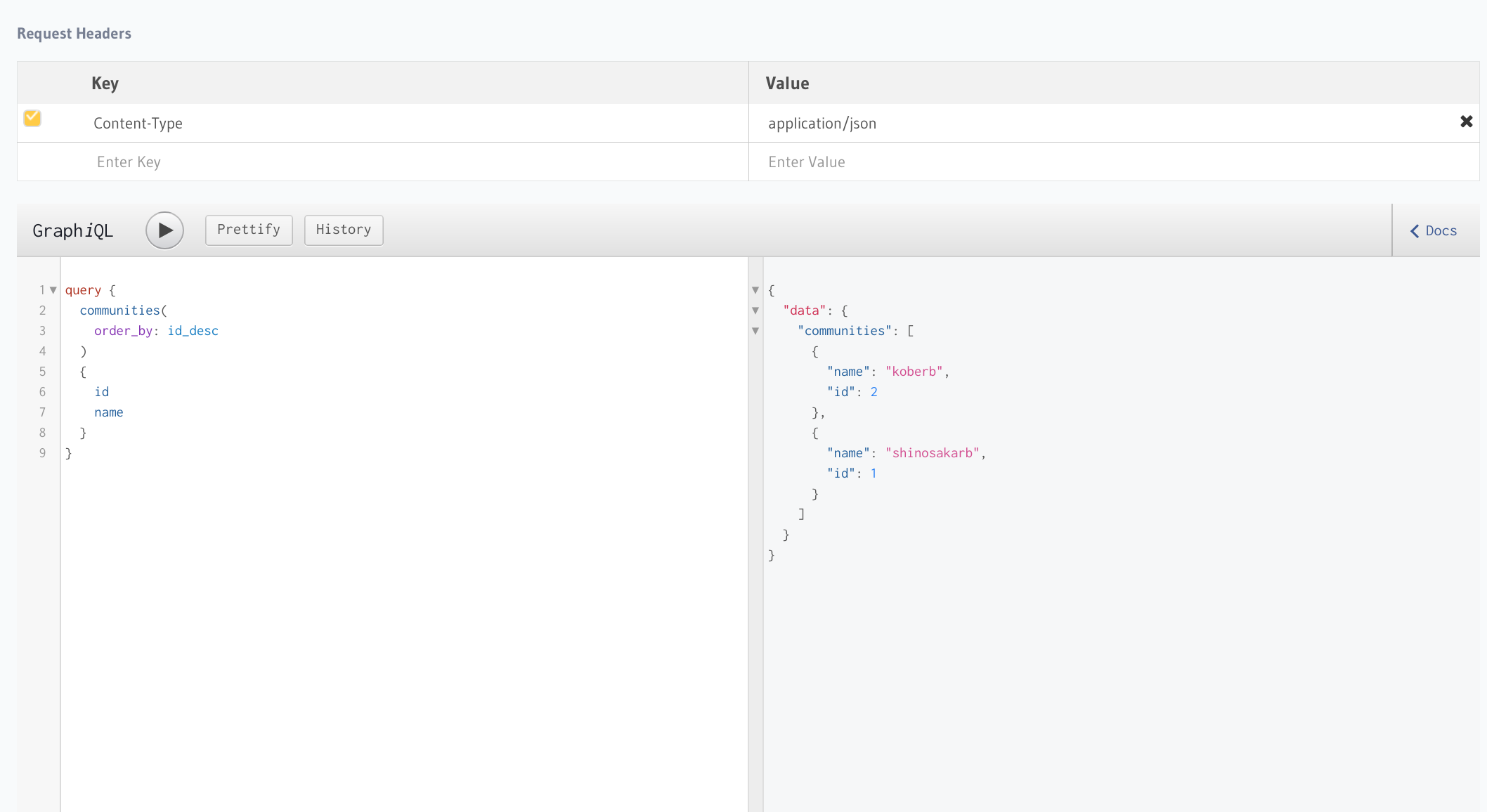
ところが、先程のuserロールとデータにあるユーザIDをhttp headerに設定すると一部のデータしか参照することができなくなります。
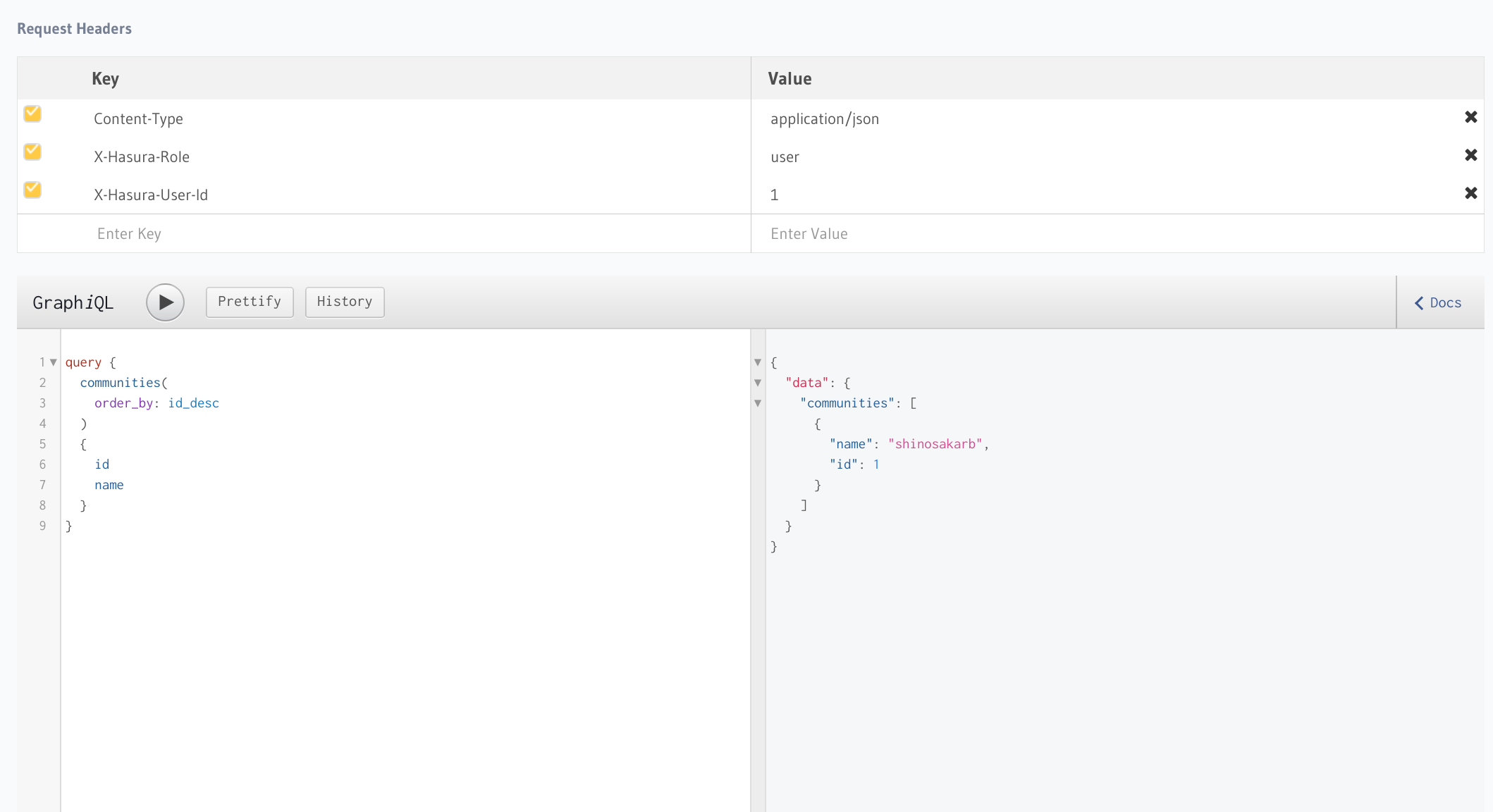
ただし、このままで子テーブルのデータを同時に取得しようとするとエラーとなってしまいます。
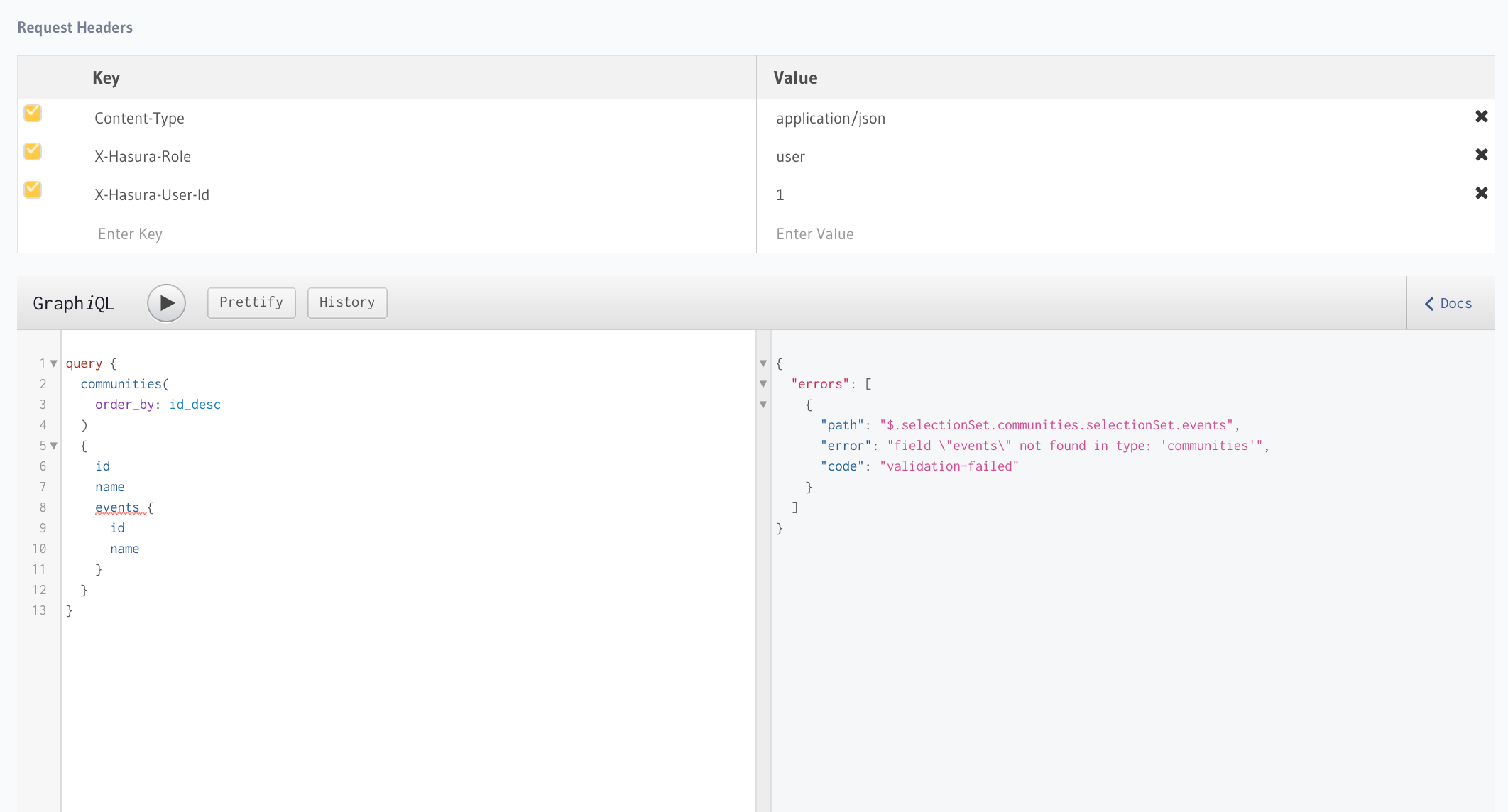
これはイベントデータに認可の権限が設定されていないためにデータ取得が行えないためのエラーが発生しているためです。なのでイベントテーブルに認可の設定を追加します。
今回はコミュニティテーブルのuser_idでデータの参照をコントロールしているためにイベントテーブルからも同様にします。そこでまずはイベントテーブルからコミュニティテーブルのリレーションを作成します。
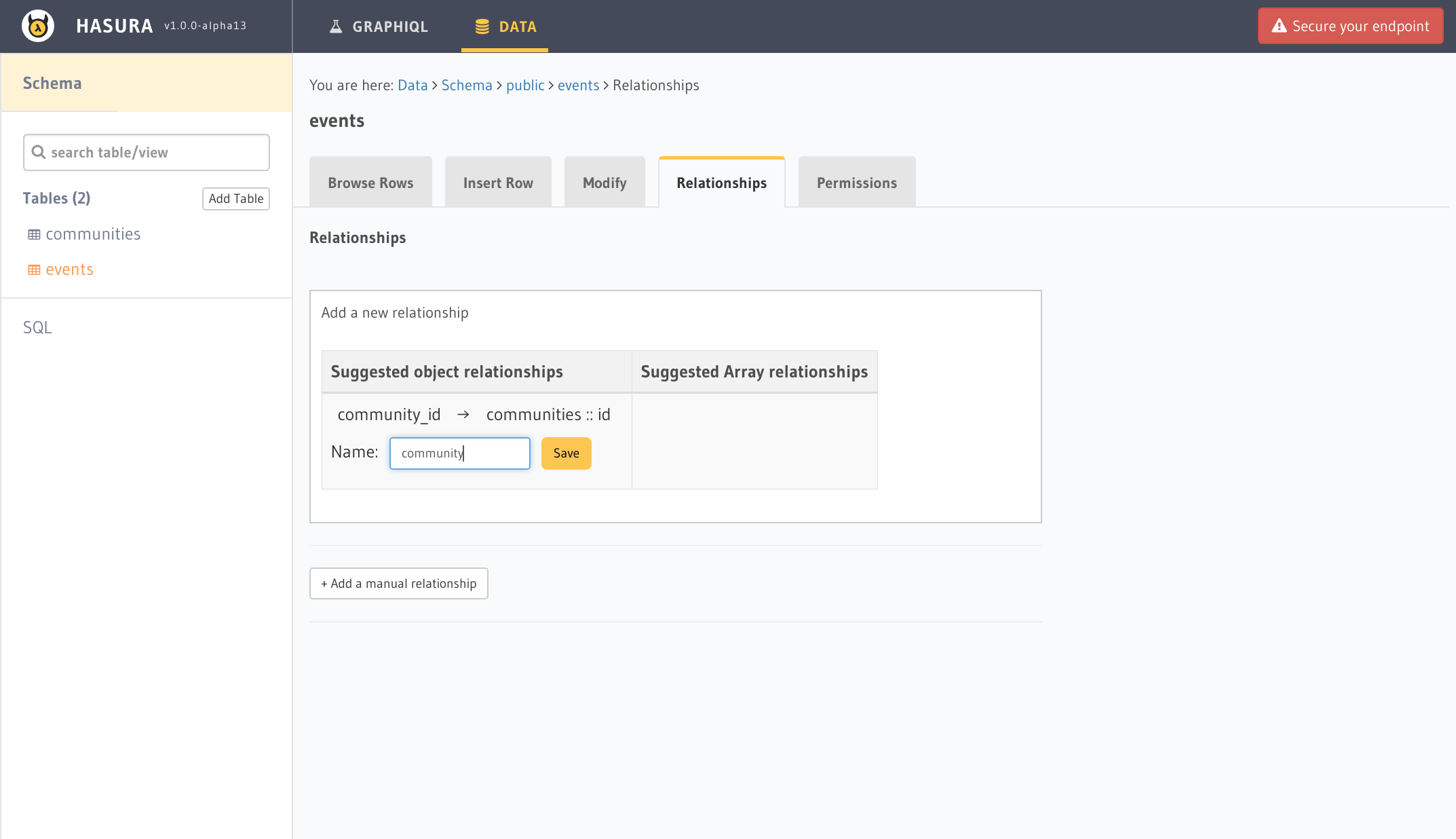
Relationshipsタブを開けばAddボタンをクリックしてから名前を入れれば完了です。
最後のイベントテーブルのPermissioinsタブからコミュニティテーブルのuser_idにてデータの絞り込みを行う設定にすれば完成です。
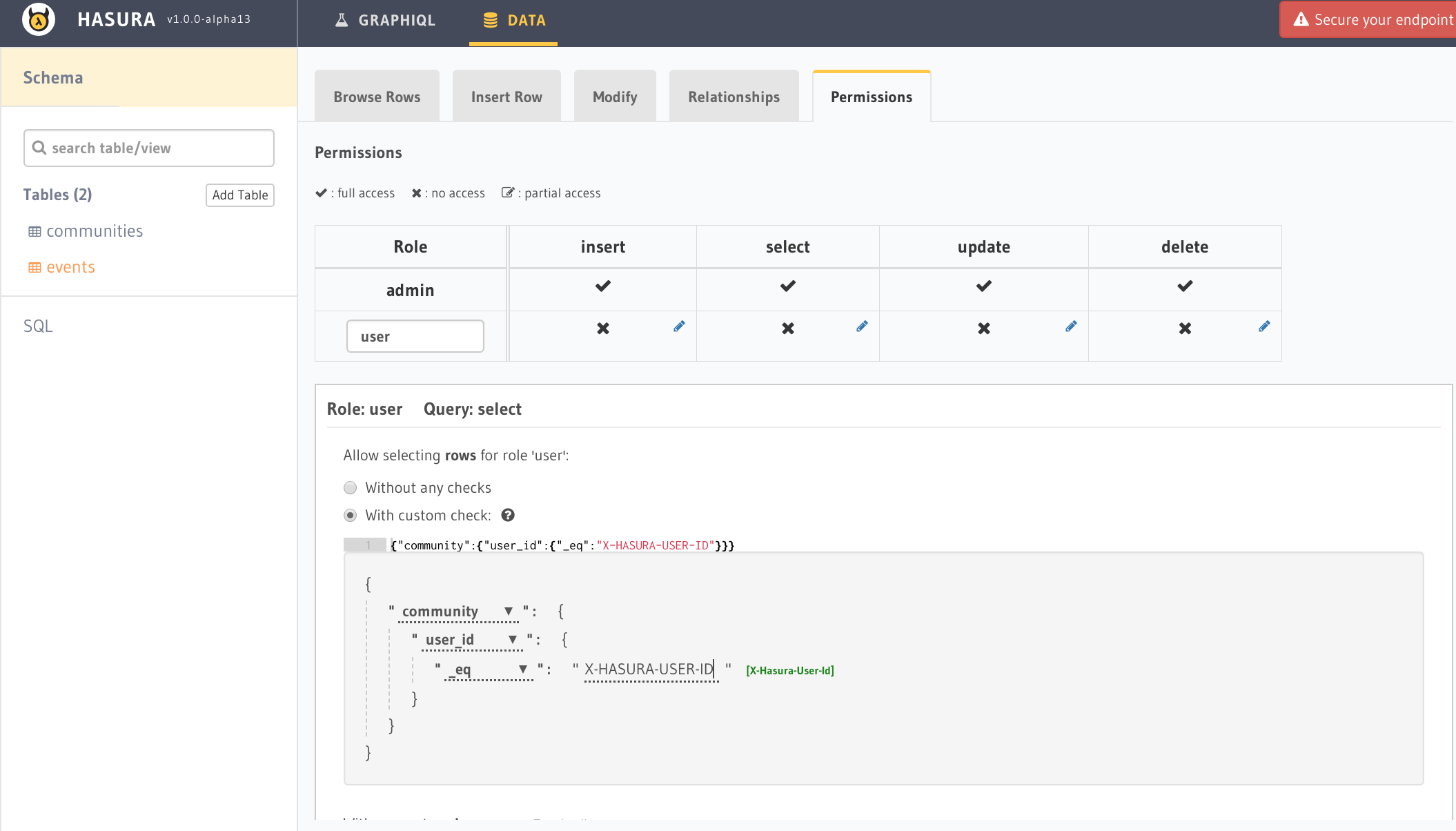
そうすることによってイベントテーブルのデータも正常に取得できるようになります。
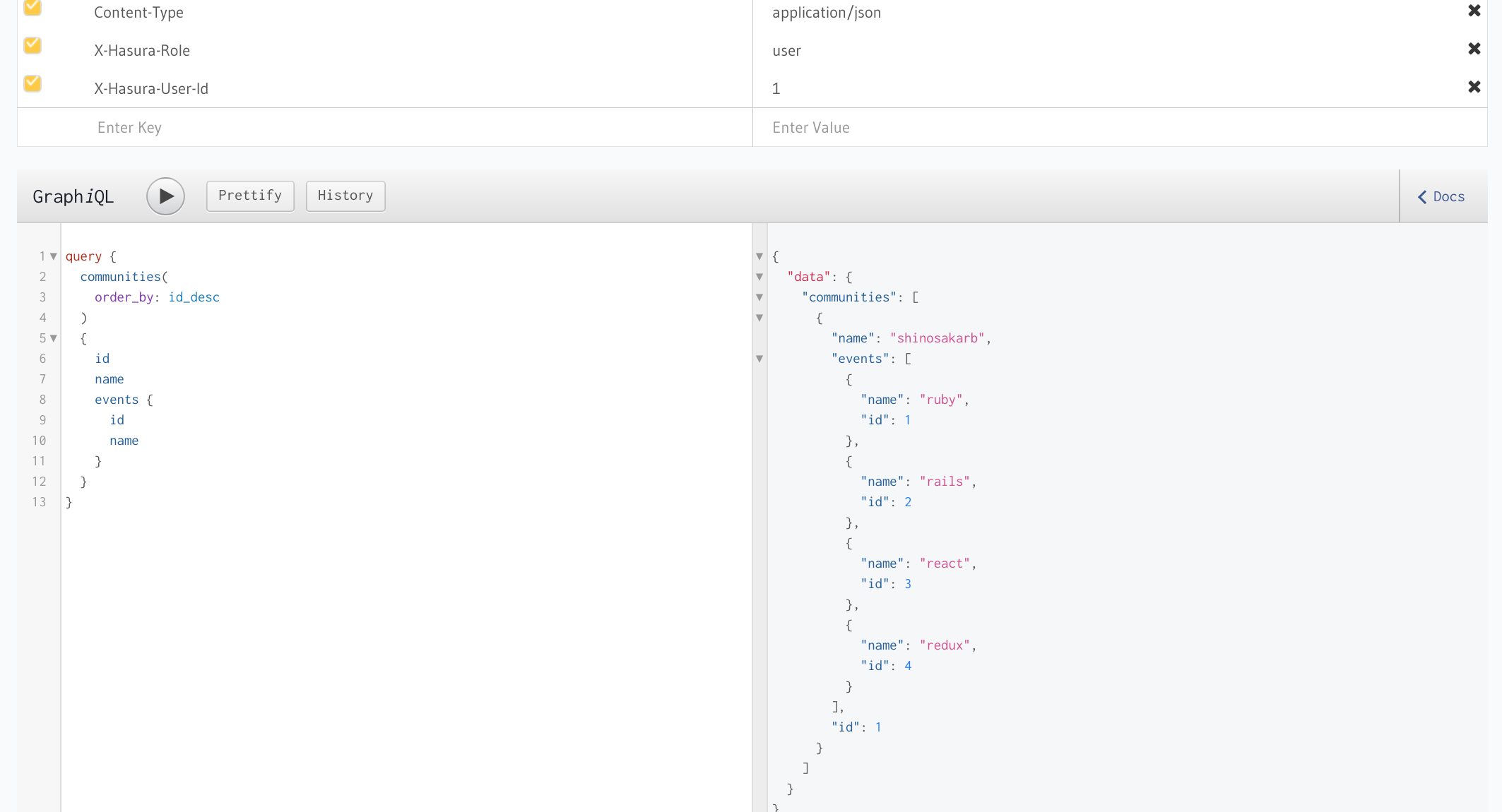
その他実際に使用する場合に出てくるであろう要件
集計関数が必要な場合はviewを定義すれば可能です。
https://docs.hasura.io/1.0/graphql/manual/queries/aggregations.html
※その他実務上で必要になってきそうなものがあればココに追記します。
最後に
これだけでGraphQLのAPIが作成できてしまうので、バックエンドの構築はとても楽です。フロント専門のエンジニアでもある程度は構築できることでしょう。AWS AppSyncも悪くないですが、既存のデータをGraphQL対応したり、検索も強固なものにするにはRDBMSを用いたGraphQLを構築したいはずです。
ただ、書いた通り通常のCRUDは簡単に構築できるのですが、集計データを保持する場合にクライアントが集計処理をしないといけないのはアプリケーションの実装上避けたい場合もありますので、そういう場合は考えないとダメですね。
そのような場合や、複数のマイクロサービスからデータを取得し合算してクライアントに返す場合は、Prismaみたいに途中に外部公開用のGraphQL Serverを立てて、そこで処理するのがベターでしょうか。