課題
AI コーディングエージェントで開発していて、ノールック(または近い状態)で approve, プルリク作成していませんか。
デモ用など使い捨てのアプリならいいのですが、例えば本番運用するシステムの場合、ブラックボックス化して保守性が下がることは避けたいですよね。
ならば、人間が Cline 生成コードについてよく理解している必要があります。
イメージ
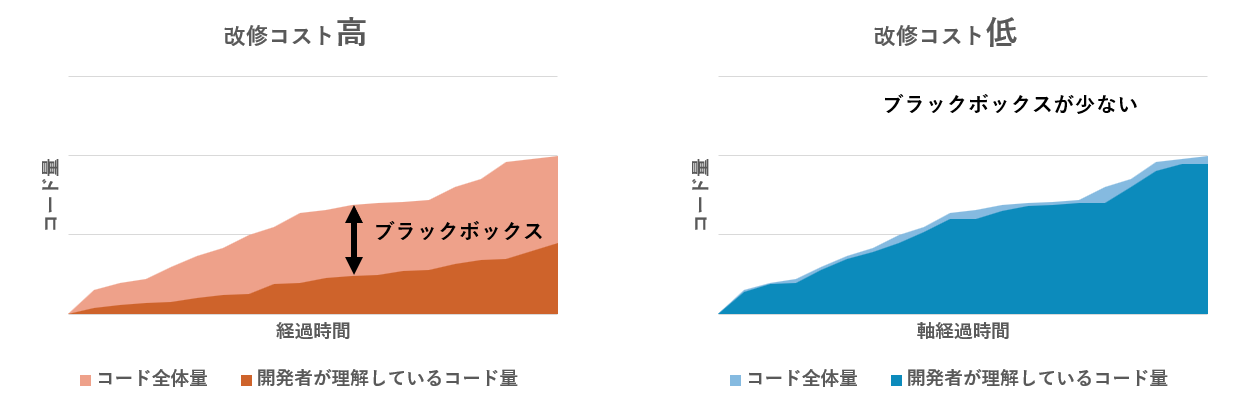
ここで、「1 プロンプトごとにCline が書いたコードをちゃんと全部読もう」と 気合で解決することは筋がわるいと思います。
なぜなら、大量の差分全てを確認する作業は負荷が高く、欠陥を見落とす可能性が高いためです。
あなたは、大きなプルリクのレビュー依頼が来てやる気をそがれたことはありませんか。
または、プルリクが大きすぎると注意されたことはありませんか。
プルリクコード量と欠陥発見率
1
横軸:LOC = コード行数。Lines of Code
縦軸:欠陥数 / コード行数
変更差分が多くなるほどレビュワーの意欲や集中力は低下し、欠陥を見つけづらくなります。
そのため、気合ではなく工夫で解決したい。
どうすればいいか
1 回のプロンプトで生成される差分を小さくすることにエネルギーを注ぐべきだと思います。
実際に Cline で試して良かった方法を 2 つ紹介します。
1. 関心の単位で AI に指示出し
異なる関心事を混ぜて指示すると、大量のコードが生成されます。
巨大な差分。読むのに根性が必要
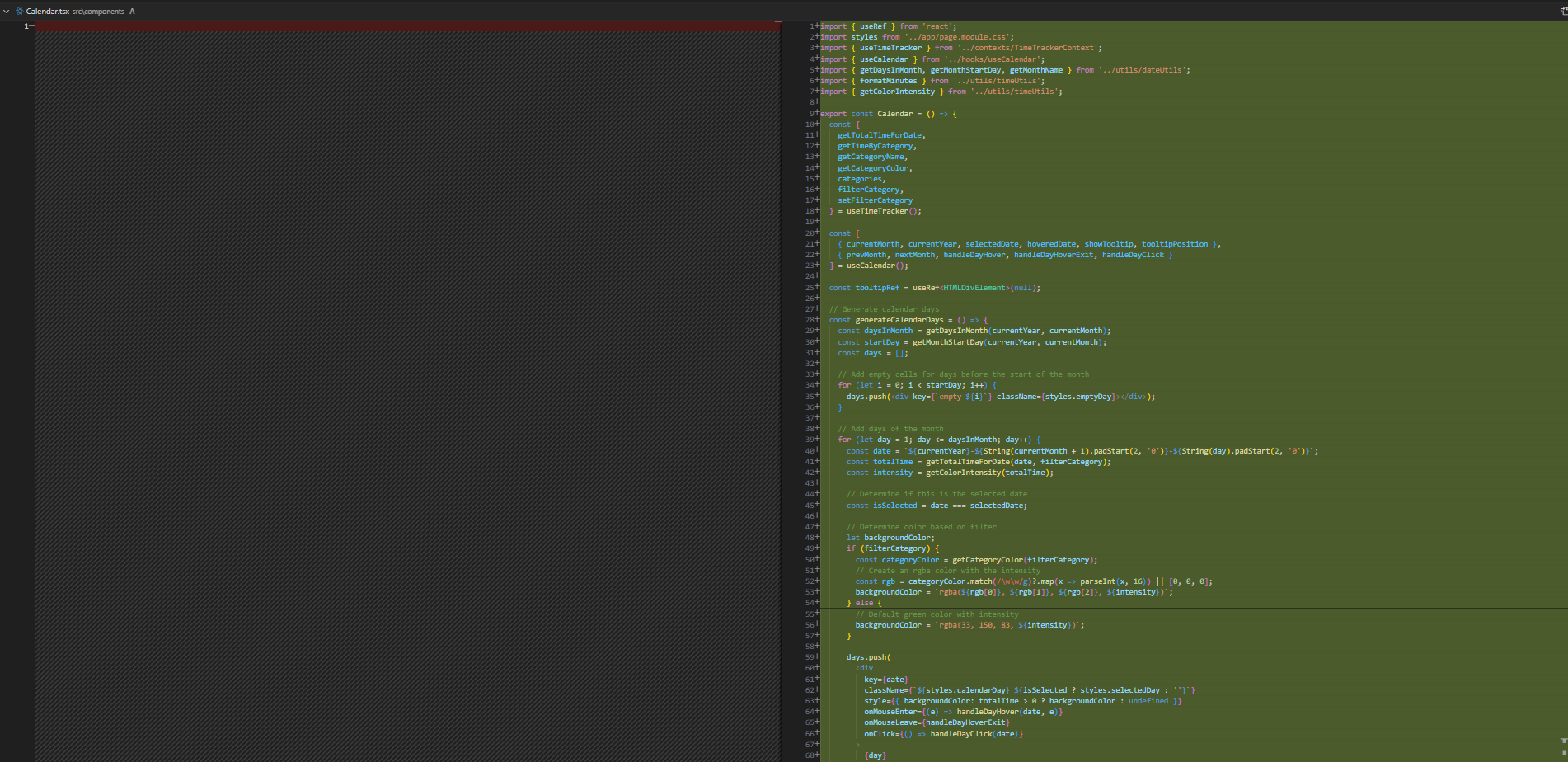
これに対し、関心ごと単位で指示を出すと、必然的に AI 生成の差分も小さくなりラクにレビューできます。
👍認知負荷の低い小さい差分
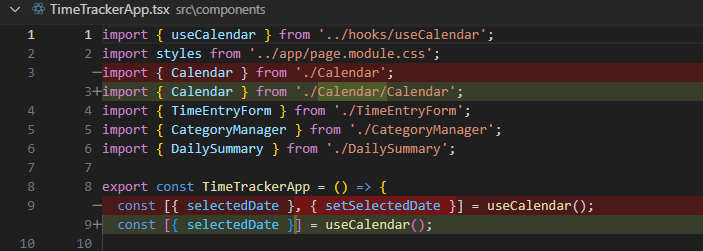
上記は style のみに関心を限定して AI に修正を依頼。style 変更のみ起きるはずが、 hook 呼び出しまで勝手に修正していることに気付けました。
2. 早期に設計や依存関係を理解
もし既にブラックボックス化しているコードが存在している場合、まずは元の設計やファイル構成を理解することが大切だと思います。
なぜなら、ある対象の理解度は、読解力より知識量に左右されるためです。
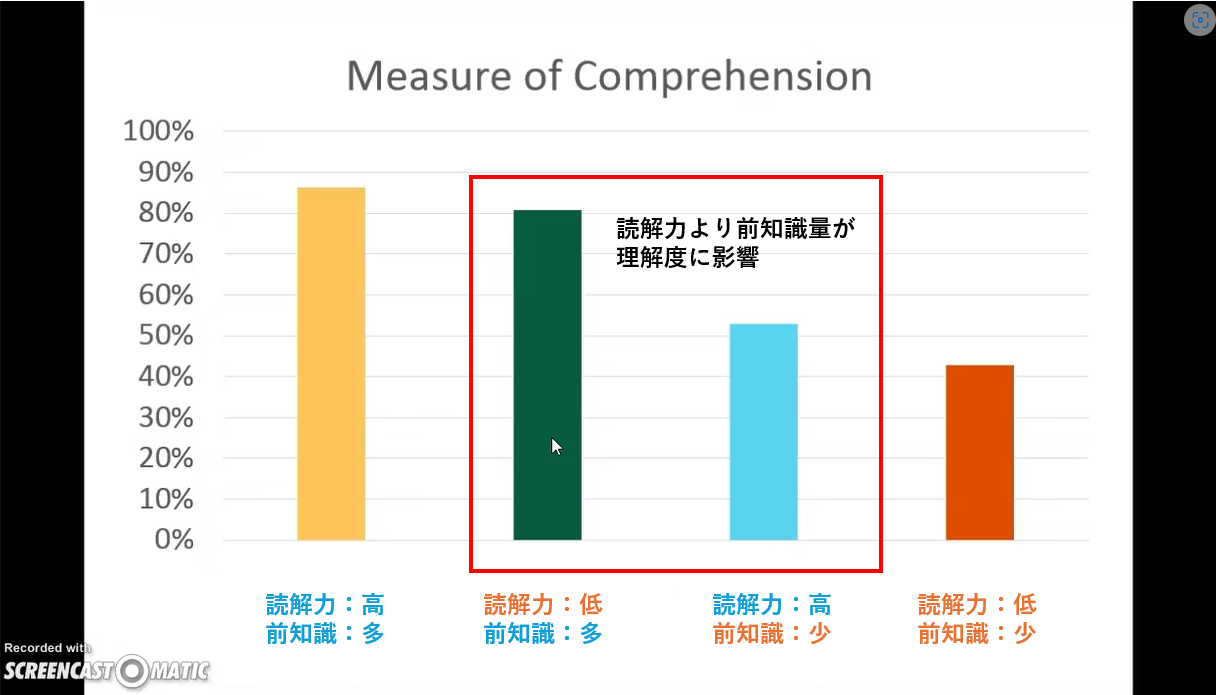
(参考)中学生を読解力の高低で 2 つに分けたあと、野球知識の大・小によって、計 4 グループに分ける。
野球に関する文章を読ませたあと理解度のテストをした。
結果、「読解力低・野球知識多」グループのほうが、「読解力高・野球知識少」グループよりも、記憶力や要約能力が優れていた。2
The Baseball Study by Recht and Leslie の解説動画 より。画像の中の日本語と赤線は私が付け加えました。
私は最初、アプリ要件の全てを Cline に伝えたところ大量のコードが生成されてしまい、どのファイルが何の役割を果たしているのか、循環依存など起きていないか、不安な状態に陥りました。
したがって、まずは Cline にプロジェクトの依存関係図やデータフロー図を書かせました。
結果、全体の見通しが良くなり、手を入れるべきファイルが分かりました。また、AI が誤って生成した所も見つけました。
全体像を見渡せると関心ごと単位で指示を出せ、差分も小さくなり開発体験がぐっと良くなります。
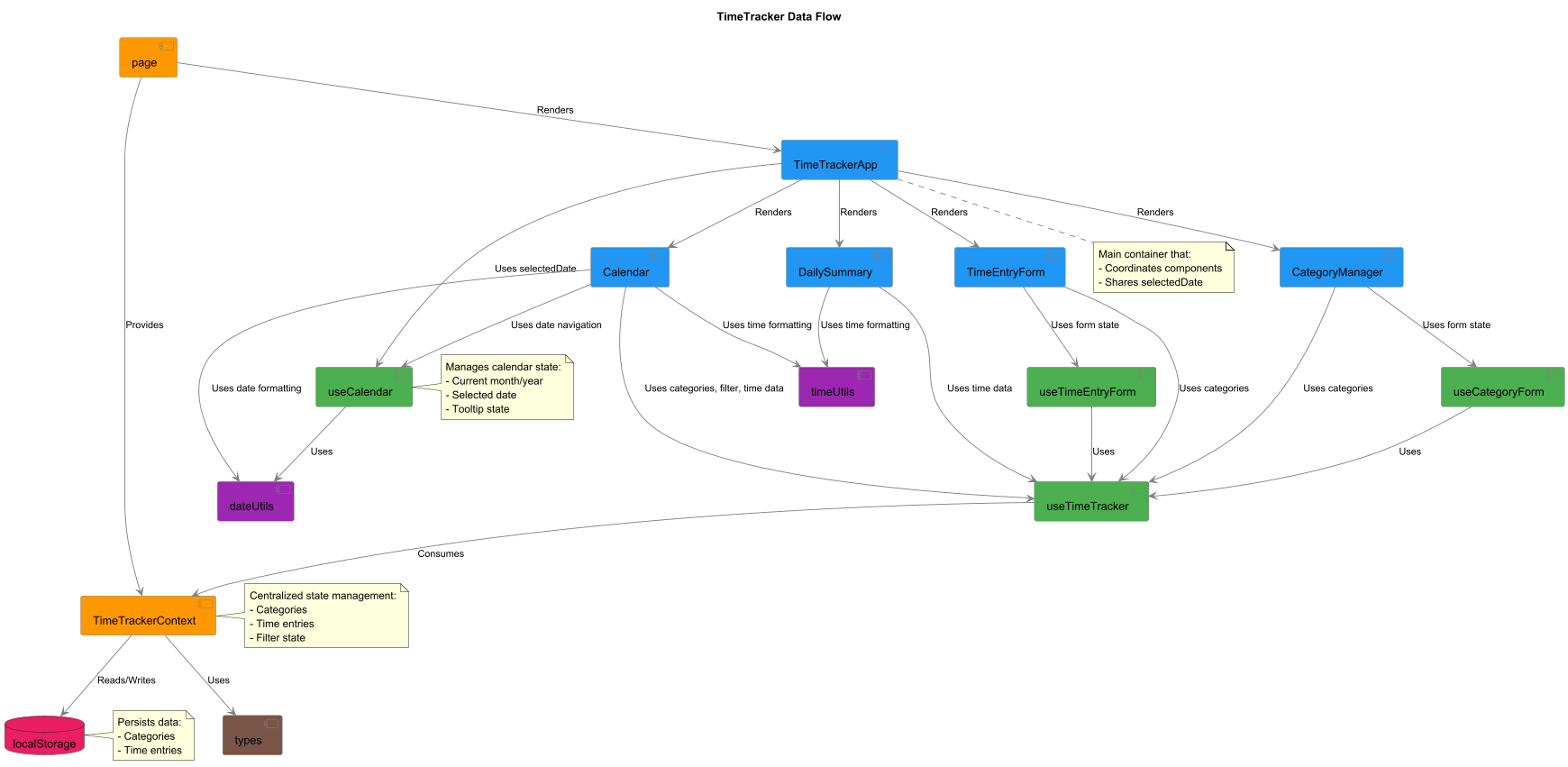
生成してもらったデータフロー図
開発が進んでからでは図が正しいかの確認作業が大変なので、早期にやっておいてよかったです。
結果
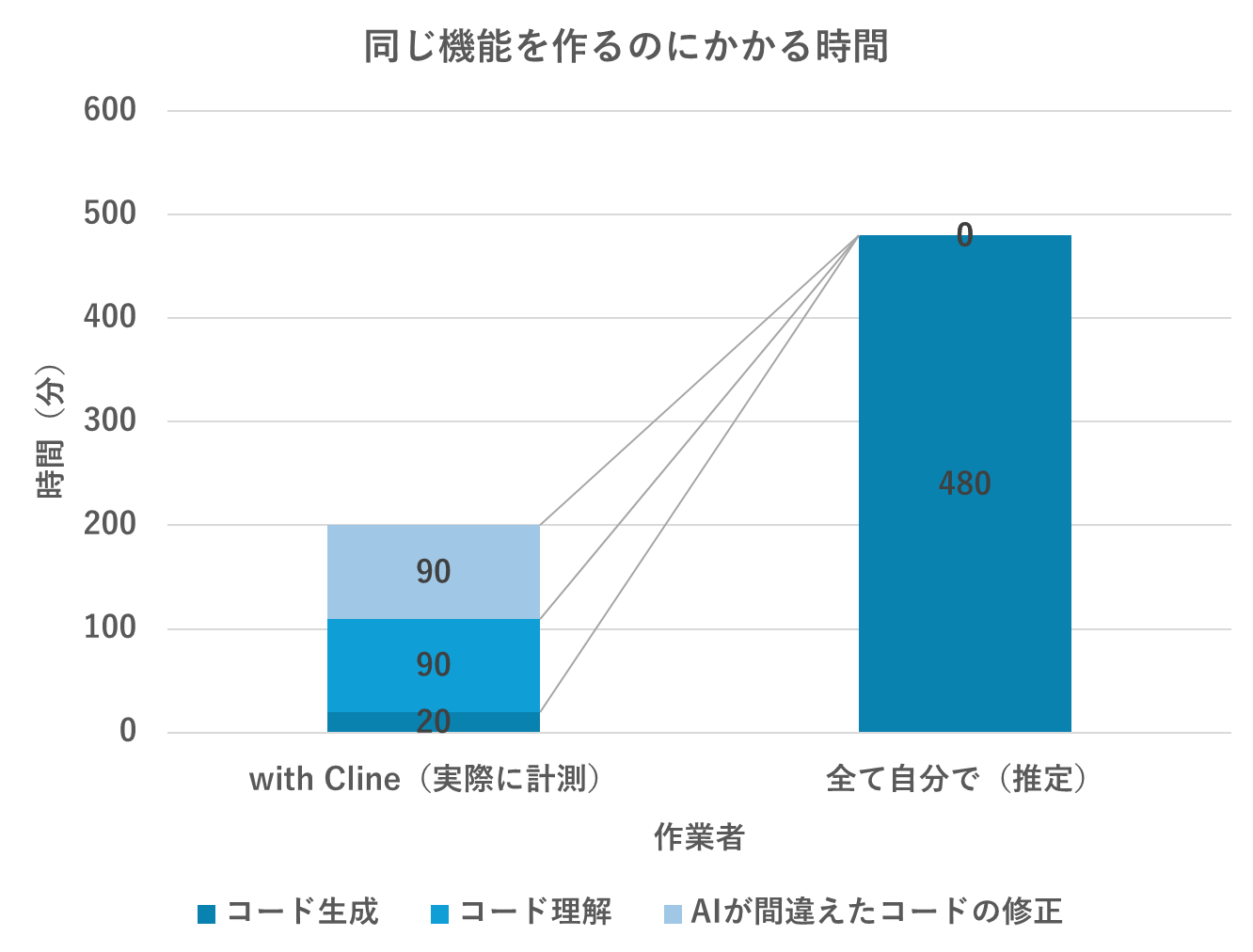
AI が間違えて生成したコードの修正を含めても、自分で全部書くより時間は短縮されたと思います。
かつ、初期段階でコードの依存関係を整理したドキュメントも生成したため、リポジトリ全体の理解度も高められたと思います。
余談ですが、最初に要件全体を Cline に伝えて生成させことで、学習量の多い React の思想に沿っている設計にしてくれたように見えました(例えば複数ファイルで使うオブジェクトは single source of truth としてコンテキストとして提供するなど)。これは AI エージェントを使うメリットの一つかもしれません。