0.背景
- AI初心者。Kaggle の Titanic 問題をやってみたところ。
- 次のステップとして、画像分類問題を解いてみたかった。
- SIGNATEの【練習問題】鋳造製品の欠陥検出 に取り組もうと考えた。 https://signate.jp/competitions/406
- 見た目でわかりやすく、データ数が少なく、取り組みやすい。
- SIGNATEの【練習問題】鋳造製品の欠陥検出 に取り組もうと考えた。 https://signate.jp/competitions/406
- SIGNATEは、Kaggleと違って開発環境は用意されていないため、Google Colab 上で解くことを考えた。
- とりあえず動かしてみたい人向け。
1. SIGNATEのAPIをインストールする
以下のサイトを参考にSignateのAPIを設定しました。
Google ColabでSIGNATE APIを使う->Google ColaboratoryでAPIの認証を実行
2.ファイルダウンロード
SIGNATEのAPIを使って学習用とテスト用の画像/CSVファイルをダウンロードして、Colabのフォルダに展開する。
!signate download --competition-id=406
import zipfile
train_data = zipfile.ZipFile('train_data.zip')
train_data.namelist() # zip内のファイル名一覧を取得
train_data.extractall() # zip内容を出力
test_data = zipfile.ZipFile('test_data.zip')
test_data.namelist() # zip内のファイル名一覧を取得
test_data.extractall()
- Colabのフォルダに保存されるため、Colabのセッションが切れると削除される。
- 毎回ダウンロードしたくない場合は、Google driveに保存するのがよいが、まずは学習・推論を動かしてみたい。この練習問題はファイルサイズが小さいので毎回ダウンロードしてもそれほど時間は掛からない。
- ダウンロードしたら、以下のように画像データにアクセスできるか確認する。
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
img = mpimg.imread('/content/train_data/cast_def_0_0.jpeg')
imgplot = plt.imshow(img)
うまくいけば以下のように画像が表示される。

3.問題を解く
3.1 学習
KerasでResnet50を使うことにした。
以下のWebサイトを参考にしています。
ResNetをFine Tuningして自分が用意した画像を学習させる
まずはCSVファイルを読み込む
import numpy as np
import pandas as pd
train = pd.read_csv("train.csv")
train['target']=train['target'].astype(str) #あとで使うflow_from_dataframeがy_colがstrでないとエラーが出るため変換
train.head()
最後のtrain.head()はcsvがきちんと読み込めているかの確認用です。うまくいけばcsvファイルの最初の5行が表示されます。
trainデータを学習(train)用と検証(validation/test)用に分割する
- ImageDateGeneratorにもvalidation_splitがあるが、正解データの割合を均一にする機能(stratify)が無いため、sklearnで分割した
- 正解データの割合を均一にする機能を使わないと、CSVデータは正常と欠陥がソートされているため、検証用データがすべて欠陥となり、すべて1と予測すればval_accuracyが1.0になってしまう。これだと、ResNet50がきちんと学習できているか検証できない。
from sklearn.model_selection import train_test_split
train_train, train_test = train_test_split(train, test_size=0.1, stratify=train['target'], random_state=2)
- ImageDateGeneratorでデータを読み込む
nb_classes=2
train_data_dir = '/content/train_data'
nb_train_samples = 225
nb_train_batch = 16
nb_validation_samples = 25
img_width, img_height = 224, 224 #インプット画像は300x300だが学習済みのResNet50が224x224なのでそちらに合わせる
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rescale=1.0 / 255, # 各画素値の0~1への正規化
rotation_range=180,
width_shift_range = 0.05,
height_shift_range = 0.05,
horizontal_flip=True, # 画像をランダムに左右反転
vertical_flip=True
)
!mkdir /content/record_train_gen/
train_generator = train_datagen.flow_from_dataframe(
train_train,
train_data_dir,
x_col = 'id',
y_col = 'target',
target_size=(img_width, img_height),
color_mode='rgb',
class_mode='categorical',
batch_size=nb_train_batch,
save_to_dir='/content/record_train_gen/')
test_datagen = ImageDataGenerator(
rescale=1.0 / 255
)
validation_generator = test_datagen.flow_from_dataframe(
train_test,
train_data_dir,
x_col = 'id',
y_col = 'target',
target_size=(img_width, img_height),
color_mode='rgb',
class_mode='categorical',
batch_size=25)
- 学習用のデータが少ないため、水増し(data augmentation)が必要です。
train_datagen = ImageDataGenerator(...でdata augmentationを設定しています。 - 一方で検証用のデータは
test_datagen = ImageDataGenerator(で生成しており、こちらはdata augmentationはしていません。このtest_datagenは学習後の推論でも使いまわしています。
学習を行うモデル(ResNet50)を作成
#学習を行うモデルを作る
from keras.applications.resnet import ResNet50
from keras.models import Sequential, Model
from keras.layers import Input, Flatten, Dense
input_tensor = Input(shape=(img_width, img_height, 3))
ResNet50 = ResNet50(include_top=False, weights='imagenet',input_tensor=input_tensor)
#入力画像は224×224のRGB画像なので,これをinput_tensorとして指定.
#今回FineTuningを行うにあたって,出力結果は2クラスの分類にしたいので,全結合層を変更します.
#そのためにまず,include_top=Falseとすることで,全結合層を除いたResNet50をインポートします.
#そしてこのとき, weights=’imagenet’とすることで学習済みのResNet50が読み込めます.逆に,weights=Noneとすると,ランダムな初期値から始まります.
#除去した全結合層の代わりに用いる新たな全結合層を作成
top_model = Sequential()
top_model.add(Flatten(input_shape=ResNet50.output_shape[1:]))
top_model.add(Dense(nb_classes, activation='softmax'))
#2行目のコードで,ResNet50の出力を1次元化しています.
#これを出力クラス数が5の全結合層に入力する形で,新たな全結合層を定義します.
model = Model(inputs=ResNet50.input, outputs=top_model(ResNet50.output))
#全結合層を取り払ったResNet50と,新たに作った全結合層をくっつけてモデルの形づくりは完了
#チェック用
#model.summary()
損失関数など学習の条件を設定
#学習処理を決めるコンパイル
from tensorflow import keras
from tensorflow.keras import optimizers
#from keras import optimizers
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
loss_weights=[0.3, 0.7],
metrics=['accuracy'])
#最適化アルゴリズムに確率的勾配降下法
-
loss_weights=[0.3, 0.7]:正常データに比べて欠陥データが少ないため、欠陥データでの学習の重みを少し大きくしている。
学習
- ここは実行に時間が掛かります。ColabのランタイムタイプがNoneの場合は、GPUに切り替えてください。
- ランタイムタイプがGPUの場合で30分くらい掛かりました。
history = model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples//nb_train_batch,
epochs=200,
validation_data=validation_generator,
validation_steps=1)
- ハマったポイント:
steps_per_epoch=nb_train_samples//nb_train_batch,の//nb_train_batchがコメントだと思って入力していなかった。C言語だと//はコメントだが、Pythonだと整数の商。
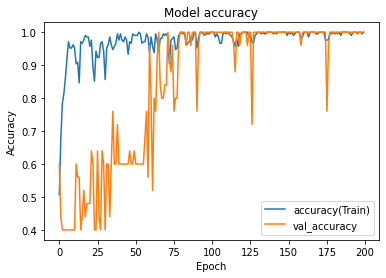
学習がうまくいっていそうかグラフ化して確認
#学習が収束しているかグラフ化してみてみる
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
- 例として私の結果は以下のような感じでした。
- ハマったポイント:最初は20 epochくらいで試しに回してみたところ、val_accuracyが上がらないため、バグがあると思って探し回っていました。30 epochくらいから val_accuracyが上がり始めます。
- この問題のトレーニングデータは、正常:欠陥=6:4なので、Accuracyが0.6以下だと何も予測できていないといえます(全部正常と予測すれば0.6のAccuracyになるため)。
- ハマったポイント:最初は20 epochくらいで試しに回してみたところ、val_accuracyが上がらないため、バグがあると思って探し回っていました。30 epochくらいから val_accuracyが上がり始めます。
3.2 推論
学習したモデルでテストデータに対する推論を行う
#学習結果からtestデータに対して予測する
sample_submission = pd.read_csv("sample_submission.csv", header=None)
test_data_dir = '/content/test_data/'
test_generator = test_datagen.flow_from_dataframe(
sample_submission,
test_data_dir,
x_col=0,
target_size=(img_width, img_height),
color_mode='rgb',
shuffle=False,
class_mode=None)
pred = model.predict_generator(test_generator,verbose=1)
地味にハマったポイント
shuffle=False をしないとデータの順番がシャッフルされて提出データの結合時にidと結果がずれてしまいました。
推論結果をSIGNATEへの提出用のCSVファイルに出力
#print(pred)
predicted_class_indices=np.argmax(pred,axis=1) #One-hotから最大値を取り出し
#通常は以下のように数字をラベルに置き換える。今回は{'0': 0, '1': 1}なので変換不要
#labels = (train_generator.class_indices)
#labels = dict((v,k) for k,v in labels.items())
#predictions = [labels[k] for k in predicted_class_indices]
my_submission=sample_submission
my_submission[1] = list(predicted_class_indices)
my_submission.to_csv("submission.csv", index=False, header=None)
4.投稿する
- Colabから一度ローカルにダウンロードして、SIGNATEのサイトにアップロードしていました。
- 上記のResNet50で、評価は0.99でした。
- 上記のResNet50で、評価は0.99でした。