はじめに
RLlibはPythonでの強化学習ライブラリの一つです。
公式のGetting Startedに記載があるように、強化学習環境ライブラリGymnasiumに用意された環境では(そこそこ)簡単に強化学習モデルを構築できます。しかし、自身で状態や報酬などを定義した環境での強化学習モデル構築のためにはカスタム環境を定義する必要があり、そこまでの筋道が公式ドキュメントではわかりづらかったためその方法についてまとめました。
また、Ray 2.10.0からの新しい記法がNew API stackとして推奨ていますが、この記法がネット上の古い情報と異なるためNew API stackでの基本的な記法に準拠したコードを記載します。
最後に公式ドキュメントの所在についても整理して記載します。
記法の間違いやより適切な方法がありましたら指摘いただけると幸いです。
RLlibの準備
RLlibのインストール
インストール手順については以下のページを参照。pipでもcondaでもインストール可能です。
M1チップ搭載のmacの場合は特に手順が異なるため、対象のセクション(下記)を参照
https://docs.ray.io/en/latest/ray-overview/installation.html#m1-mac-apple-silicon-support
Gymnasiumの環境を使用した実行確認
カスタム環境を使用する前にGymnasiumの環境を用いて実行テストを行いました。正常に回り、トレーニングごとに報酬が増加することを確認できればOKです。
コード
# モジュールのインポート(以降のコードでも同じものを使用)
import gymnasium
import numpy
import ray
import ray.rllib.algorithms.ppo
import torch
# Rayの初期化
ray.init(ignore_reinit_error=True)
# 環境とアルゴリズムの設定
config = (
ray.rllib.algorithms.ppo.PPOConfig()
.api_stack(enable_rl_module_and_learner=True, enable_env_runner_and_connector_v2=True)
.environment(env="CartPole-v1")
.env_runners(num_env_runners=1)
)
ray.rllib.algorithms.ppo = config.build()
# 学習の繰り返し(5回)
print("Training")
for _ in range(5):
result = ray.rllib.algorithms.ppo.train()
print(f" trained steps: {result['num_env_steps_sampled_lifetime']}")
# トレーニング後のエージェントの動作(1エピソードで得られる総報酬)を確認
rl_module = ray.rllib.algorithms.ppo.get_module() # RLmoduleを取得
env = gymnasium.make("CartPole-v1") # 環境を作成
obs, info = env.reset()
total_reward = 0
terminated = truncated = False
while (not terminated) and (not truncated):
# observationをTensorに変換
torch_obs_batch = torch.from_numpy(numpy.array([obs]))
# actionの確率を取得
action_logits = rl_module.forward_inference({"obs": torch_obs_batch})["action_dist_inputs"]
# 確率が最大のactionを選択
action = torch.argmax(action_logits).numpy()
# 環境を1ステップ進める
obs, reward, terminated, truncated, info = env.step(action)
total_reward += reward
# 1エピソードでの総報酬を出力
print(f" Total reward: {total_reward}")
ray.rllib.algorithms.ppo.stop()
ray.shutdown()
実行結果(一部省略)
実際にはログとワーニングがはじめに20行ほど出ました。
出力からは一回のトレーニングごとに4000ステップ実行されており、学習を経るごとに1エピソードでの報酬が増えていることがわかります。
Training
trained steps: 4000
Total reward: 48.0
trained steps: 8000
Total reward: 103.0
trained steps: 12000
Total reward: 317.0
trained steps: 16000
Total reward: 500.0
trained steps: 20000
Total reward: 272.0
この記事で例に使う環境 - Simple Corridor
はじめに以降で例に使う強化学習環境であるSimple Corridorについて説明を記載しておきます。
これはRLlibのexampleコードをベースとした環境です。
この環境ではエージェントは数直線上の$x = 0$の点からスタートし、$x = X$を目指します。エージェントの取り得る状態は$[0, X]$区間の整数($0,1,...,X$)で、点$x$にいる時、$x + 1$(ひとつ右)もしくは$x - 1$(ひとつ左)に移動することができます。つまりエージェントにはどの点にいても常に右に移動するという行動を選択することで報酬を最大化できます。
$x=X$を目指すように常に右に移動することをエージェントに学習させるために、エージェントに与える報酬を、$x = X$に到達したとき1、それ以外の点に移動した時$-0.01$とします。
カスタム環境による強化学習モデルの構築方法
カスタム環境の定義
カスタム環境クラスの要件
カスタム環境クラスの要件については下のページに記載があります。
次のコードは上記のページからシングルエージェントのカスタム環境クラスの要件を引用したものです。まず、__init__()で行動空間(action_space)と観察空間(observation_space)を設定します。また、reset()とstep()というメソッドを実装し、それぞれで現在の状態(obs)や報酬(reward)等を返すように実装します。
class MyEnv(gymnasium.Env):
def __init__(self, env_config):
self.action_space = <gym.Space>
self.observation_space = <gym.Space>
def reset(self, seed, options):
return <obs>, <info>
def step(self, action):
return <obs>, <reward: float>, <terminated: bool>, <truncated: bool>, <info: dict>
上記の最低限の実装ができていれば十分ですが、カスタム環境の定義についてはGymnasiumの公式ドキュメントの下記のページに詳細があります。reset()メソッドの最初にsuper().reset(seed=seed)を呼ぶことや、他にオーバーライド可能なメソッド等について記載があります。
Simple Corridorの例
上記の要件に沿って、先に説明したSimple Corridorの環境を定義するコードを次に記載します。ただし、モジュールは上のセクションのものをインポートしてください。
class SimpleCorridor(gymnasium.Env):
def __init__(self, env_config):
super().__init__()
# env_configを取得
self.X = env_config['X']
self.max_repeat = env_config['max_repeat']
# エージェントが取れる行動と観測できる空間の定義
self.action_space = gymnasium.spaces.Discrete(2)
self.observation_space = gymnasium.spaces.Box(low=0, high=self.X, shape=(1,), dtype=numpy.float32)
self.x = None # 現在位置
def reset(self, *, seed = None, options = None):
super().reset(seed=seed)
self.x = 0 # 現在位置
observation = numpy.array([self.x], dtype=numpy.float32)
info = {'x': self.x}
return observation, info
def step(self, action):
match action:
case 0:
self.x -= 1 if (self.x > 0) else 0
case 1:
self.x += 1 if (self.x < self.X) else 0
observation = numpy.array([self.x], dtype=numpy.float32)
reward = (1 if self.x == self.X else -0.01)
terminated = (self.x == self.X)
truncated = False
info = {'action': action, 'x': self.x}
return observation, reward, terminated, truncated, info
強化学習アルゴリズムの設定と構築
作成した環境を用いて学習を進めるためには強化学習アルゴリズムを指定し、パラメータを指定する必要があります。
アルゴリズムの指定
RLlibには複数の強化学習アルゴリズムが用意されています。例として、PPO (Proximal Policy Optimization) や DQN/Rainbow (Deep Q Networks) があります。
アルゴリズムの一覧は次のページに記載があります。
使用するアルゴリズムを決めたら、対応するAlgorithmConfigオブジェクトを作成します。例として上に挙げたPPOであればPPOConfig()、DQNであればDQNConfig()などです。
アルゴリズム・学習の設定項目の指定
アルゴリズム・学習に関する設定としては学習率(learning rate)や一回の学習での環境の実行回数などが挙げられます。これらを設定するためには上で作成したAlgorithmConfigオブジェクトに対してメソッドを呼び出します。
例として、学習に関する設定として時間割引率(gamma)と学習率(lr)、および環境を指定するコードを次に示します。
config = (
ray.rllib.algorithms.ppo.PPOConfig()
.training(gamma=0.9, lr=0.01)
.environment(env="CartPole-v1")
)
AlgorithmConfig.training()やAlgorithmConfig.environment()などの設定用メソッドは戻り値として同じAlgorithmConfigオブジェクトを返します。そのため、上のように連結させて記載することができます。
そのほかの設定項目として代表的なものは次のページに記載があります。
設定項目の指定用のメソッドの一覧は次のページに記載があります。
AlgorithmConfigからのAlgorithmの作成
上記で作成したAlgorithmConfigを用いて学習に使用するAlgorithmを構築するためには次のようにbuild()メソッドを呼び出します。これによりAlgorithmオブジェクトが返されます。
algo = config.build()
Simple Corridorの例でのアルゴリズムの設定と初期化の例
ここではアルゴリズムとしてPPOを用いたAlgorithmConfigをppo_configとして作成し、それを元に作成したAlgorithmオブジェクトをppoという変数に格納しています。
また、AlgorithmConfig.api_stack()メソッドによってNew API stackの要素を使用するかを指定します。ここではどちらも使用するように設定しています。
print('Initialization')
# AlgorithmConfigの作成
ppo_config = (
ray.rllib.algorithms.PPOConfig()
.api_stack(enable_rl_module_and_learner=True, enable_env_runner_and_connector_v2=True)
.training(gamma=0.9, lr=0.01)
.env_runners(explore=True)
.environment(env=SimpleCorridor, env_config={'X': 9, 'max_repeat': 100})
)
# AlgorithmConfigからのAlgorithmの初期化
ppo = ppo_config.build()
学習の実行
一回の学習はAlgorithm.train()メソッドを呼び出すことで実行されます。次のように実行したい回数分train()メソッドを呼び出すだけで学習を実行できます。
for i in range(10):
training_result = ppo.train()
学習したポリシーの確認
Algorithm.train()メソッドによる学習では環境で設定された報酬を最大化するようにポリシーが更新されていきます。学習によって更新されたモデルの性能を確認する方法としてシミュレーションを行う方法があります。そのためには学習されたポリシーを取得し、上で構築したカスタム環境における観測(observation)に対する行動を算出する必要があります。
それぞれポリシーの取得、ポリシーからの行動の分布の取得とサンプリング、環境のステップの順で説明します。
ポリシーの取得
ポリシーはRL Moduleというオブジェクトとして取得できます。RL Moduleは簡単に言うと環境における観測(observation)を入力するとエージェントの行動を返す関数のようなものです。内部的にはパラメータを更新可能なニューラルネットワークモデルなどが入っています。Algorithm.train()を実行すると環境における報酬が高くなる行動を選択するようにRL Moduleのパラメータが更新されます。
RL Moduleは次のようにAlgorithmオブジェクトのget_module()というメソッドで取得できます。
rl_module = ppo.get_module()
RL Moduleからの行動の分布の取得とサンプリング
Simple Corridorの例では行動は右に行くか左に行くかの2つでした。上のRL Moduleの説明で報酬を最大化する行動を選択するようにパラメータを更新すると書きましたが、出力は「右」や「左」のような確定的な選択ではなく、「右90%・左10%」のような確率的な選択を返します。
Simple Corridorのような離散選択の場合、RL Moduleはロジットと呼ばれる値を返します。ロジットの値が大きい選択肢ほど高い確率で選択されることを表し、Softmax関数に入力することで全選択肢の選択確率の和が1の確率に変換することができます。
最後に、右90%・左10%のような確率ではシミュレーションがしづらいので、この確率に従ってサンプリングすることで行動を決定します。つまり試行ごとに選択結果が異なり、結果的に報酬も異なります(ただし学習ができていれば妥当な選択をする確率はどんどん上がり、現実的には不適切な選択をすることは無いレベルまで行くことは期待できます)。
環境の1ステップごとの観測(obs)を与えて、行動をサンプリングするコードを次に示します。RLModule.get_inference_action_dist_cls()により確率分布オブジェクトのクラスを取得し、RLModule.forward_inference()に観測を与えることでロジットを取得します。最後に先ほど取得した確率分布オブジェクトをロジットから作成し、サンプリングを行うメソッドを呼び出します。
# エージェントの行動の確率分布オブジェクトのクラスを取得
action_dist_cls = rl_module.get_inference_action_dist_cls()
# 現在のobservationの下での行動の確率分布を定義するパラメータ(action logits)を取得
action_logits = rl_module.forward_inference({'obs': torch.from_numpy(obs).to(torch.float32)})['action_dist_inputs']
# 学習したモデルでエージェントの行動の確率分布を指定しサンプリング
sampled_action = action_dist_cls.from_logits(action_logits).sample()
環境のステップ
行動がサンプリングできたら環境を1ステップ進めます。Simple Corridorの例では右に進むか左に進むかを選択することで$x$が更新されます。
上で設定したようにobs, reward, terminated, truncated, infoが返されるのでそれぞれの変数に格納します。このうちobsは次の行動選択に、terminatedやtruncatedはエピソード終了の判定に使用します。
obs, reward, terminated, truncated, info = env.step(sampled_action)
Simple Corridorでの例
次の例では一回のエピソードを終了まで実行し、かかった総ステップ数と総報酬を算出しています。
# RL Moduleを取得
rl_module = ppo.get_module()
# エージェントの行動の確率分布オブジェクトのクラスを取得
action_dist_cls = rl_module.get_inference_action_dist_cls()
# 環境を初期化
env = SimpleCorridor(env_config={'X': 9, 'max_repeat': 100})
obs, info = env.reset()
# エピソード終了まで繰り返し
terminated = truncated = False
total_reward = 0
steps_num = 0
while (not terminated) and (not truncated):
# 現在のobservationの下での行動の確率分布を定義するパラメータ(action logits)を取得
action_logits = rl_module.forward_inference({'obs': torch.from_numpy(obs).to(torch.float32)})['action_dist_inputs']
# 学習したモデルでエージェントの行動の確率分布を指定しサンプリング
sampled_action = action_dist_cls.from_logits(action_logits).sample()
# 確率分布からサンプリングした行動で1ステップ進める
obs, reward, terminated, truncated, info = env.step(sampled_action)
total_reward += reward
steps_num += 1
print(f"step={steps_num} -> sampled_action={sampled_action} action_logits={str(action_logits)}")
print(f"total_reward: {total_reward} steps_num: {steps_num}")
env.close()
十分に学習ができていた場合出力は次のようになります。それぞれのステップで1という行動が選択されており、右に進み続ける行動の確率が高いことがわかります。action_logitsを見ても0に対して1の値が大きくなっていることがわかります。
step=1 -> sampled_action=1 action_logits=tensor([-1.6561, 2.0106])
step=2 -> sampled_action=1 action_logits=tensor([-2.4759, 2.8695])
step=3 -> sampled_action=1 action_logits=tensor([-2.7531, 3.0037])
step=4 -> sampled_action=1 action_logits=tensor([-2.9283, 3.0838])
step=5 -> sampled_action=1 action_logits=tensor([-2.9790, 3.1247])
step=6 -> sampled_action=1 action_logits=tensor([-2.9952, 3.1525])
step=7 -> sampled_action=1 action_logits=tensor([-3.1429, 3.2289])
step=8 -> sampled_action=1 action_logits=tensor([-3.1849, 3.2575])
step=9 -> sampled_action=1 action_logits=tensor([-3.1825, 3.2646])
total_reward: 0.92 steps_num: 9
試しにAlgorithm.train()を一度も呼び出していないAlgorithmで試したところエピソード終了までに441ステップかかり、総報酬は-4.00となりました。学習により行動の選択確率が変わっていることがわかります。
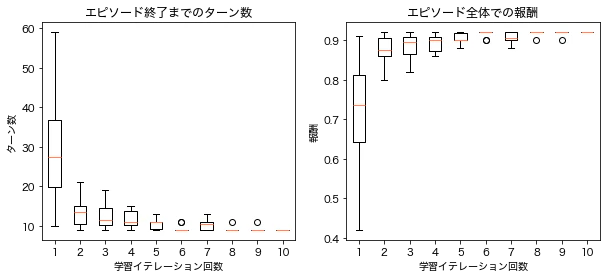
RL Moduleは学習の途中でも取得することができ、学習に影響せずにシミュレーションも可能です。下の画像は各学習イテレーション実行ごとに100回シミュレーションを行い、ターン数と総報酬を記録したものです。学習を進めるごとにシミュレーション上でもターン数が少なくなり、報酬が高くなっていることがわかります。
おわりに
この記事ではRLlibでカスタム環境を定義する例を示しました。RLlibではカスタム環境の定義、AlgorithmConfigオブジェクトの生成とメソッドによる設定、Algorithmの構築、学習の実行の手順でカスタム環境を構築・学習可能です。
今回定義した環境はシングルエージェント環境でしたが、マルチエージェント環境も同様に定義することが可能です(詳しくはこちらを参照)。
公式ドキュメントの整理
Getting Started with RLlib
Gymnasium環境を用いた実行コード例、代表的なアルゴリズム設定項目など
Key Concepts
強化学習の理論と対応するRLlibの概念、RLlibの代表的なオブジェクトの位置付け
Environments
カスタム環境の構築方法、マルチエージェント環境の構築方法
Algorithms
アルゴリズムの一覧とアルゴリズムごとの代表的な設定項目
New API stack migration guide
New API stackへの対応方法
Ray RLlib API
ライブラリの詳細なドキュメントの入り口