予測モデルの精度を上げたい
けど、どうしたらいいだろう…そもそも予測が外れる原因って何だろう??
そうだ、予測が外れている原因を決定木で可視化できないかな?という試み。
(理論的に間違っている部分もあるかもしれないけど)
分析の流れとかも載せようと思うので、データの処理とかやったことはあまりはしょらずに書く。
データの読み込み、前処理、データの確認、モデル構築・精度確認、要因調査という流れで書いていく。
多分長くなる。
本題はこの章 → 決定木で予測が外れた顧客の特徴の可視化
使用データ
KaggleのTelco Customer Churnのデータを使用する。
https://www.kaggle.com/blastchar/telco-customer-churn
これは電話会社の顧客に関するデータであり、解約するか否かを目的変数とした2値分類問題。
各行は顧客を表し、各列には顧客の属性が含まれている。
各列は以下のようになっている。(kaggleのカラム説明文をGoogle翻訳)
customerID:お客様ID
gender:顧客が男性か女性か
SeniorCitizen:お客様が高齢者かどうか(1、0)
Partner:お客様がパートナーを持っているかどうか(はい、いいえ)
Dependents:顧客に扶養家族がいるかどうか(はい、いいえ)
tenure:顧客が会社に滞在した月数
PhoneService:お客様が電話サービスを利用しているかどうか(はい、いいえ)
MultipleLines:顧客が複数の回線を持っているかどうか(はい、いいえ、電話サービスなし)
InternetService:顧客のインターネットサービスプロバイダー(DSL、光ファイバー、いいえ)
OnlineSecurity:お客様がオンラインセキュリティを持っているかどうか(はい、いいえ、インターネットサービスなし)
OnlineBackup:お客様がオンラインバックアップを持っているかどうか(はい、いいえ、インターネットサービスなし)
DeviceProtection:お客様がデバイスを保護しているかどうか(はい、いいえ、インターネットサービスなし)
TechSupport:お客様が技術サポートを利用しているかどうか(はい、いいえ、インターネットサービスなし)
StreamingTV:お客様がストリーミングTVを持っているかどうか(はい、いいえ、インターネットサービスなし)
StreamingMovies:顧客がストリーミング映画を持っているかどうか(はい、いいえ、インターネットサービスなし)
Contract:お客様の契約期間(月々、1年、2年)
PaperlessBilling:お客様がペーパーレス請求を行っているかどうか(はい、いいえ)
PaymentMethod:顧客の支払い方法(電子小切手、郵送小切手、銀行振込(自動)、クレジットカード(自動))
MonthlyCharges:顧客に毎月請求される金額
TotalCharges:顧客に請求される合計金額
Churn:顧客が解約したかどうか(はいまたはいいえ)
データの概要
データの中身をざっと見ていく。
基本的な情報
# パッケージインポート
import pandas as pd
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn import preprocessing
from sklearn import tree
from sklearn.externals.six import StringIO
import pydotplus
from IPython.display import Image
from dtreeviz.trees import dtreeviz
import xgboost.sklearn as xgb
plt.style.use('seaborn-darkgrid')
%matplotlib inline
# データ読み込み
df=pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv')
churn=df.copy()
print(churn.info())
display(churn.head())
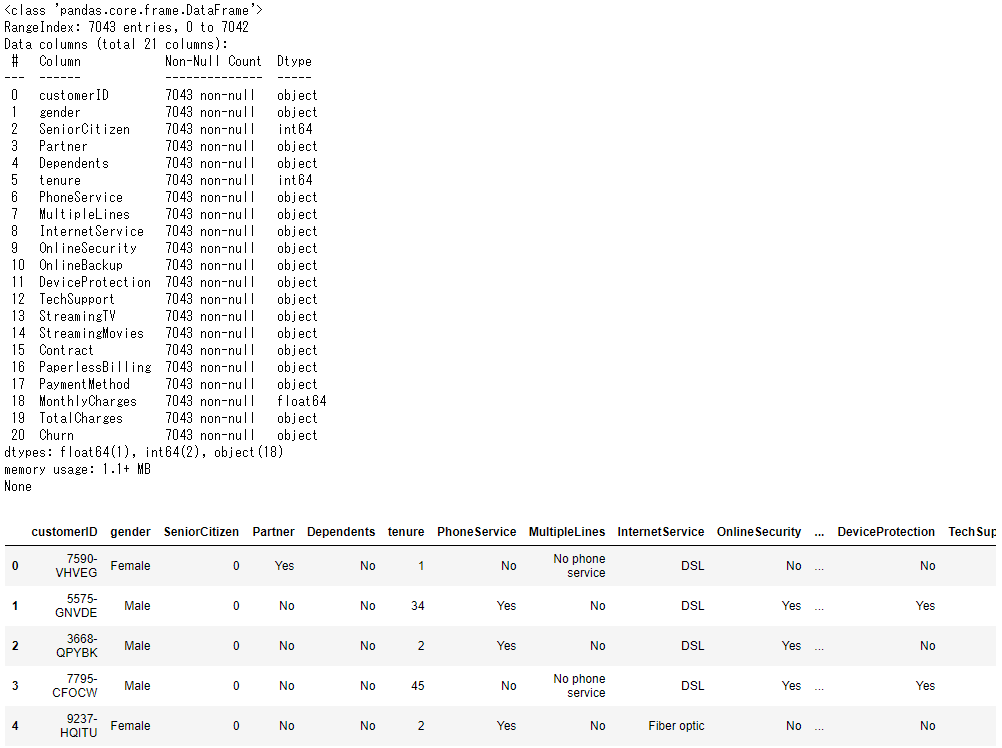
欠損行
欠損値に変更
TotalChargesカラムは数値だが、半角空白の行が存在するので数値の型になっていない。
なので空白をNanに変換して数値型に変換する。
# 半角空白をNanに変更
churn.loc[churn['TotalCharges']==' ', 'TotalCharges']=np.nan
# floatに変更
churn['TotalCharges']=churn['TotalCharges'].astype(float)
print(churn.info())
display(churn.head())
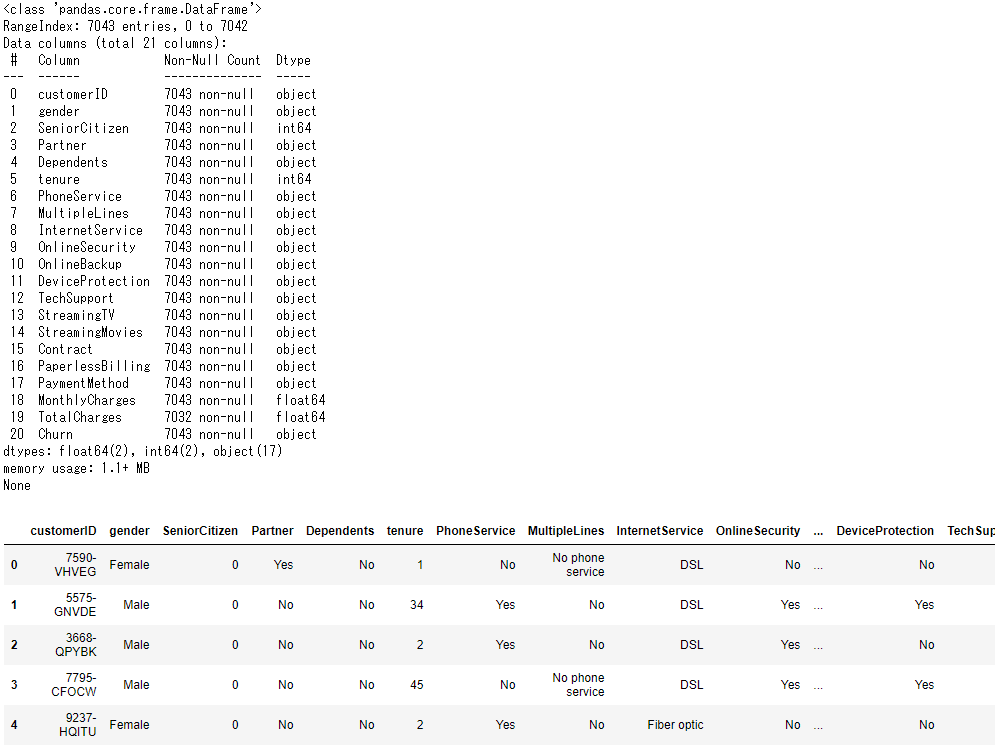
TotalChargesカラムをfloatに変換完了。
欠損行の補完
次にTotalChargesのNanを補完する作業を行う。
この時カテゴリーによってTotalChargesの偏りが最も大きいカテゴリー変数を使ってNanを埋めた方が、単純にTotalChargesの平均値を使ってNanを埋めるより予測に有効な補完ができると思われる。
なので方針としてはカテゴリー変数ごとのTotalChargesの平均値をNanに埋めることにする。
まずNanを除外したデータフレームを作成し、カテゴリー変数とTotalChargesのみのデータフレームを作成する。
# Nan行を削除したデータフレームの作成
churn2=churn[churn.isnull().any(axis=1)==False].copy()
churn2['TotalCharges']=churn2['TotalCharges'].astype(float)
# カテゴリー変数+TotalChargesのデータフレームの作成
# dtypeがobject型のデータのみ抽出
churn2_TotalCharges=churn2.select_dtypes(include=['object']).drop('customerID',axis=1)
# TotalChargesを追加
churn2_TotalCharges['TotalCharges']=churn2['TotalCharges']
print(churn2_TotalCharges.info())
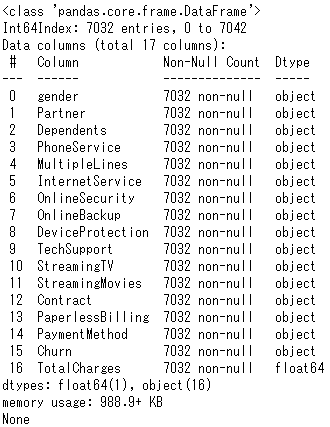
Nan行除外により7,043→7,032行になった。
次にどのカテゴリー変数がTotalChargesと関係ありそうか可視化して見てみる。
# TotalChargesを抜いたカテゴリー変数名のリストを定義
obj_columns=churn2_TotalCharges.columns.values
obj_columns=obj_columns[~(obj_columns == 'TotalCharges')]
# 各カテゴリー変数ごとにTotalChargesのヒストグラムを描いてみる
fig=plt.figure(figsize=(12,10))
for i in range(len(obj_columns)):
col=obj_columns[i]
youso=churn2_TotalCharges[col].unique()
ax=plt.subplot(round(len(obj_columns)/np.sqrt(len(obj_columns))), round(len(obj_columns)/np.sqrt(len(obj_columns))), i+1)
for j in range(len(youso)):
sns.distplot(churn2_TotalCharges[churn2_TotalCharges[col]==youso[j]]['TotalCharges'], bins=30, ax=ax, kde=False, label=youso[j])
ax.legend(loc='upper right')
ax.set_ylabel('Freq')
ax.set_title(col)
plt.tight_layout()
fig.suptitle("TotalCharges hist", fontsize=15)
plt.subplots_adjust(top=0.92)
plt.show()
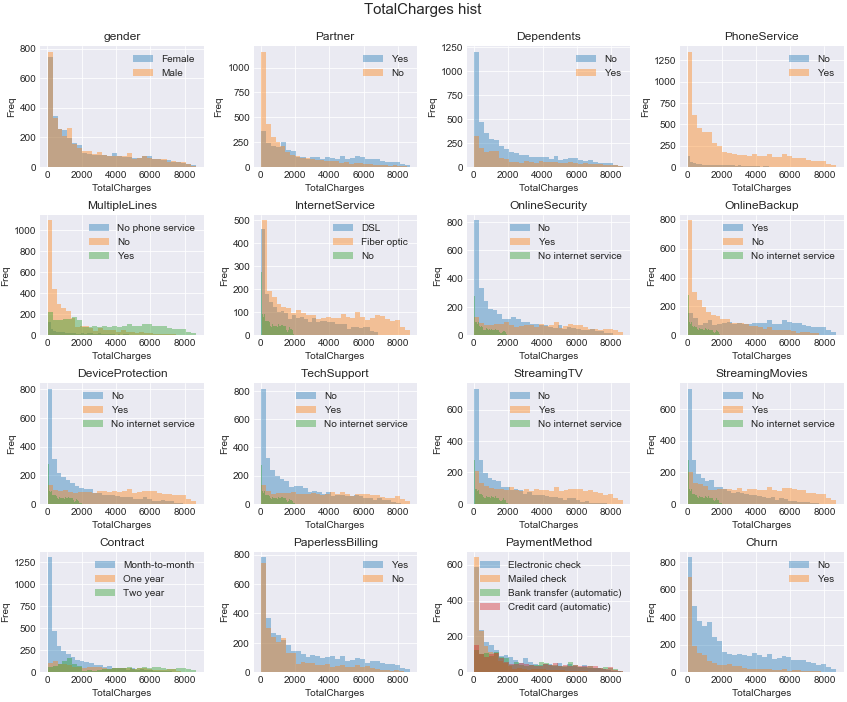
'MultipleLines', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies'
→この辺のカテゴリー変数で、カテゴリーごとにTotalChargesの分布が大きく異なる感じがある。
ここからテキトーにTotalChargesの平均を求めるカテゴリー変数を選んでもいいけど、できれば定量的に判断したい気もする。
では本題とは違うけど、ここでも決定木を使って判断してみようと思う。
CARTはジニ不純度(とかエントロピー)と情報利得をもとに目的変数を最もよく分ける説明変数の分岐を生成する。
理論的な話は、「はじめてのパターン認識」か、以下のようなサイトを参照。
https://dev.classmethod.jp/articles/2017ad_20171211_dt-2/
つまりTotalChargesを目的変数にCARTを適用すれば、TotalChargesを最もよく分ける説明変数が第1分岐に来るはずである。
実際にやってみる。
# 新しくデータフレームをコピーしておく
churn2_TotalCharges_trans=churn2_TotalCharges.copy()
# カテゴリー変数をlabel encoding
for column in churn2_TotalCharges_trans.columns:
le = preprocessing.LabelEncoder()
le.fit(churn2_TotalCharges_trans[column])
churn2_TotalCharges_trans[column] = le.transform(churn2_TotalCharges_trans[column])
display(churn2_TotalCharges_trans)
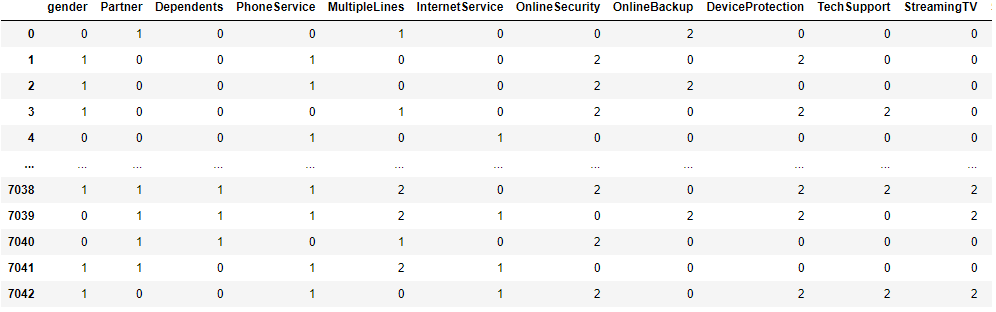
# 決定木モデル構築
clf = tree.DecisionTreeRegressor(max_depth=1)
# カテゴリー変数だけのデータフレームを説明変数に、TotalChargesを目的変数に
clffit = clf.fit(churn2_TotalCharges_trans.drop('TotalCharges',axis=1).values\
, churn2_TotalCharges_trans['TotalCharges'].values)
# 決定木の可視化
dot_data = StringIO()
tree.export_graphviz(clffit, out_file=dot_data,\
feature_names=churn2_TotalCharges_trans.drop('TotalCharges',axis=1).columns.values,\
class_names=True,\
filled=True, rounded=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
'DeviceProtection'がTotalChargesを最もよく分ける変数なので、この変数のカテゴリーごとのTotalChargesの平均値でNanを埋めて補完する。
# DeviceProtectionごとのTotalChargesの平均を求める
churn2_TotalCharges_mean=churn2.groupby(['DeviceProtection'])[['TotalCharges']].mean().reset_index().rename(columns={'TotalCharges':'TotalCharges_mean'})
# DeviceProtectionごとのTotalChargesの平均をNan含むデータフレームにマージ
churn=pd.merge(churn,churn2_TotalCharges_mean,on=['DeviceProtection'],how='left')
# Nanを補完
churn.loc[(churn.isnull().any(axis=1)==True), 'TotalCharges']=churn['TotalCharges_mean']
# TotalChargesの平均カラムを削除
churn=churn.drop('TotalCharges_mean',axis=1)
# Nan行の確認
display(churn[churn.isnull().any(axis=1)==True])
Nanは補完された。

データの俯瞰
欠損値も無くなりデータが完成したので、連続値変数、カテゴリー変数のデータ俯瞰を実施していく。
# Churn:解約のYes or No割合の円グラフ
pie=churn.groupby(['Churn'])[['customerID']].count().reset_index()
fig=plt.figure(figsize=(8,8))
ax=plt.subplot(1,1,1)
texts = ax.pie(pie['customerID'], labels=pie['Churn'], counterclock=False, startangle=90, autopct="%1.1f%%")
for t,t2 in texts[1],texts[2]:
t.set_size(18)
t2.set_size(18)
ax.set_title('Churn ratio', fontsize=20)
plt.show()
# 連続変数だけを取り出してデータフレーム作成
churn_select=churn.select_dtypes(include=['number']).copy()
# カテゴリー変数だけを取り出してデータフレーム作成(後で使う)
churn_select_obj=churn.select_dtypes(include=['object']).copy()
churn_select_obj['SeniorCitizen']=churn_select['SeniorCitizen']
# 目的変数追加
churn_select['Churn']=churn['Churn']
churn_select=churn_select.drop('SeniorCitizen',axis=1)
# label encoding
le = preprocessing.LabelEncoder()
le.fit(churn_select['Churn'])
# Churn Yes:1、No:0
churn_select['Churn'] = le.transform(churn_select['Churn'])
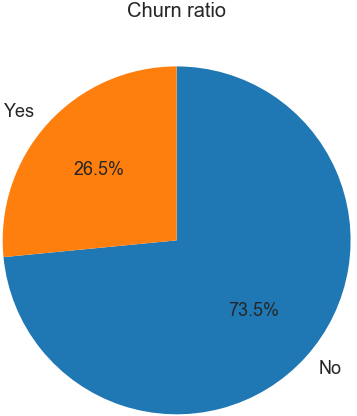
# 連続変数のpairplot
sns.pairplot(data=churn_select, hue='Churn', diag_kind='hist',plot_kws={'marker': '+', 'alpha': 0.5},diag_kws={'bins': 20})
plt.show()
# カテゴリー変数名のリスト
col=churn_select_obj.columns.values[1:]
col2=col[~(col == 'Churn')]
# 横軸Churn、縦軸カテゴリーごとのcountのbarplot
fig=plt.figure(figsize=(10,10))
churn_num=churn.copy()
churn_num['num']=1
for i in range(len(col2)):
ax=plt.subplot(round(len(col2)/np.sqrt(len(col2))),round(len(col2)/np.sqrt(len(col2))),i+1)
sns.barplot(data=churn_num.groupby(['Churn',col2[i]])[['num']].count().reset_index(),x='Churn',y='num',hue=col2[i],ax=ax)
ax.legend(loc='upper right')
ax.set_ylabel('count')
ax.set_title(col2[i]+' count')
plt.tight_layout()
plt.show()
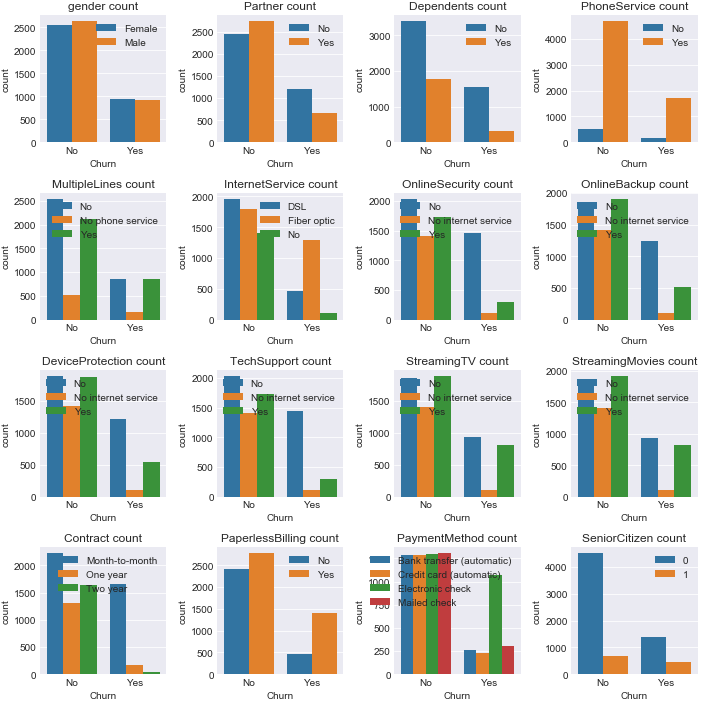
やや不均衡データだなーとか、tenureやTotalChargesが大きい方が解約しない傾向だなーとか、Contractが年払いだったら解約者あんまりいないなー、genderは関係なさそうだなーとか考えたりする。
モデル構築
データを見たのでモデルを作ってみる。
# LabelEncodingしたデータフレームchurn_encodeを作る
churn_encode=churn.copy()
columns=list(churn_encode.select_dtypes(include=['object']).columns.values)
for column in columns:
le = preprocessing.LabelEncoder()
le.fit(churn_encode[column])
churn_encode[column] = le.transform(churn_encode[column])
churn_encode=churn_encode.drop('customerID',axis=1)
# Train, Testデータを作る関数
def createXy(df, col, target, test_size=0.3, random_state=0):
# 説明変数と目的変数の分離
dfx=df[col]
dfy=df[target]
X_train, X_test, y_train, y_test = train_test_split(dfx, dfy, test_size=test_size, random_state=random_state)
print('TrainX Size is {}'.format(X_train.shape))
print('TestX Size is {}'.format(X_test.shape))
print('TrainY Size is {}'.format(y_train.shape))
print('TestY Size is {}'.format(y_test.shape))
return X_train, y_train, X_test, y_test
今回は面倒なのでとりあえず特徴量の選定とかハイパラの調整とかは無しで。
# 説明変数名
colx=churn_encode.columns.values[:-1]
# 目的変数名
coly='Churn'
X_train, y_train, X_test, y_test = createXy(churn_encode, colx, coly, test_size=0.3, random_state=0)
# XGBoostでモデルを作る
xgb_model = xgb.XGBClassifier()
xgb_model.fit(X_train, y_train)
print('Train accuracy_score',xgb_model.score(X_train, y_train))
y_true=y_test.values
y_pred=xgb_model.predict(X_test)
# Testデータの精度の確認
print('Test accuracy_score',accuracy_score(y_true, y_pred))
print('Test precision_score',precision_score(y_true, y_pred))
print('Test recall_score',recall_score(y_true, y_pred))
print('Test f1_score',f1_score(y_true, y_pred))
結果:
Train accuracy_score 0.8267748478701825
Test accuracy_score 0.7946048272598202
Test precision_score 0.6307692307692307
Test recall_score 0.5189873417721519
Test f1_score 0.5694444444444443
# Confution Matrixも見る
result=pd.DataFrame({'y_true':y_true,'y_pred':y_pred})
result['dummy']=1
display(result.pivot_table(result,index='y_true',columns='y_pred',aggfunc='count').fillna(0))
1:解約、0:未解約

さて、ここまででようやくモデルの精度の確認まで完了。
次から予測が外れた原因を見てみる。
決定木で予測が外れた顧客の特徴の可視化
ようやく本題。
予測が外れたのはどんな特徴の顧客だろうか?ということを決定木で見てみたい。
前述したが、決定木のCARTアルゴリズムはジニ不純度(とかエントロピー)と情報利得をもとに目的変数を最もよく分ける説明変数の分岐を生成する。なので予測が当たった or 外れたの2値を目的変数として決定木を描けば、予測が当たった or 外れたということを最もよく分ける説明変数の分岐が生成できると思われる。
まずは予測が当たった・外れたを示す列を作る
# X_testのコピーを作り新たな変数を追加する
churn_test=X_test.copy()
churn_test['true']=y_true
churn_test['pred']=y_pred
churn_test['RightOrWrong']=0
# y_trueとy_predが一致してた場合RightOrWrong=1とする
churn_test.loc[(churn_test['true']==churn_test['pred']),'RightOrWrong']=1
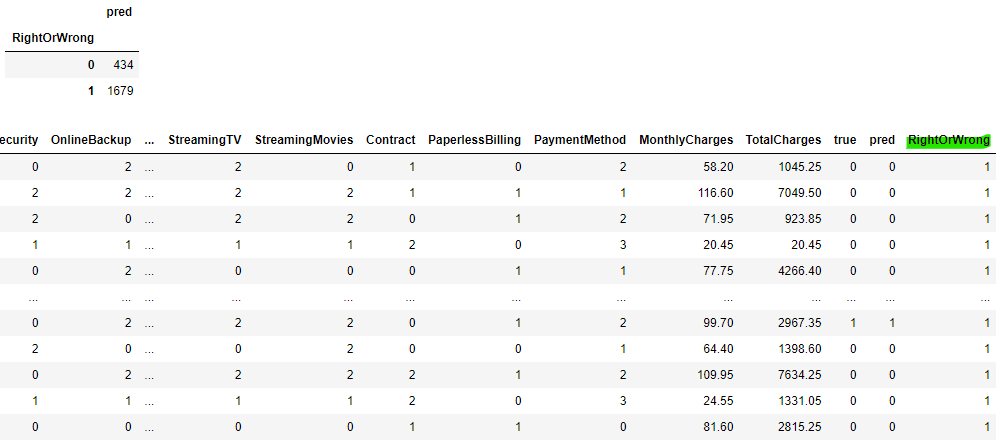
display(churn_test.groupby(['RightOrWrong'])[['pred']].count())
display(churn_test)
予測が外れた顧客は2,113人中434人
この434人にはどういう傾向があるのか決定木で可視化してみる。
# 木の深さ3(テキトー)
clf = tree.DecisionTreeClassifier(max_depth=3)
# 'true','pred','RightOrWrong'を抜いた説明変数、'RightOrWrong'を目的変数
clffit = clf.fit(churn_test.drop(['true','pred','RightOrWrong'],axis=1), churn_test['RightOrWrong'])
# dtreevizで可視化
viz = dtreeviz(\
clffit,\
churn_test.drop(['true','pred','RightOrWrong'],axis=1),\
churn_test['RightOrWrong'],\
target_name='RightOrWrong',\
feature_names=churn_test.drop(['true','pred','RightOrWrong'],axis=1).columns.values,\
class_names=[0,1], histtype='bar'\
)
print('Data Count ',len(churn_test))
display(viz)
Data Count 2113
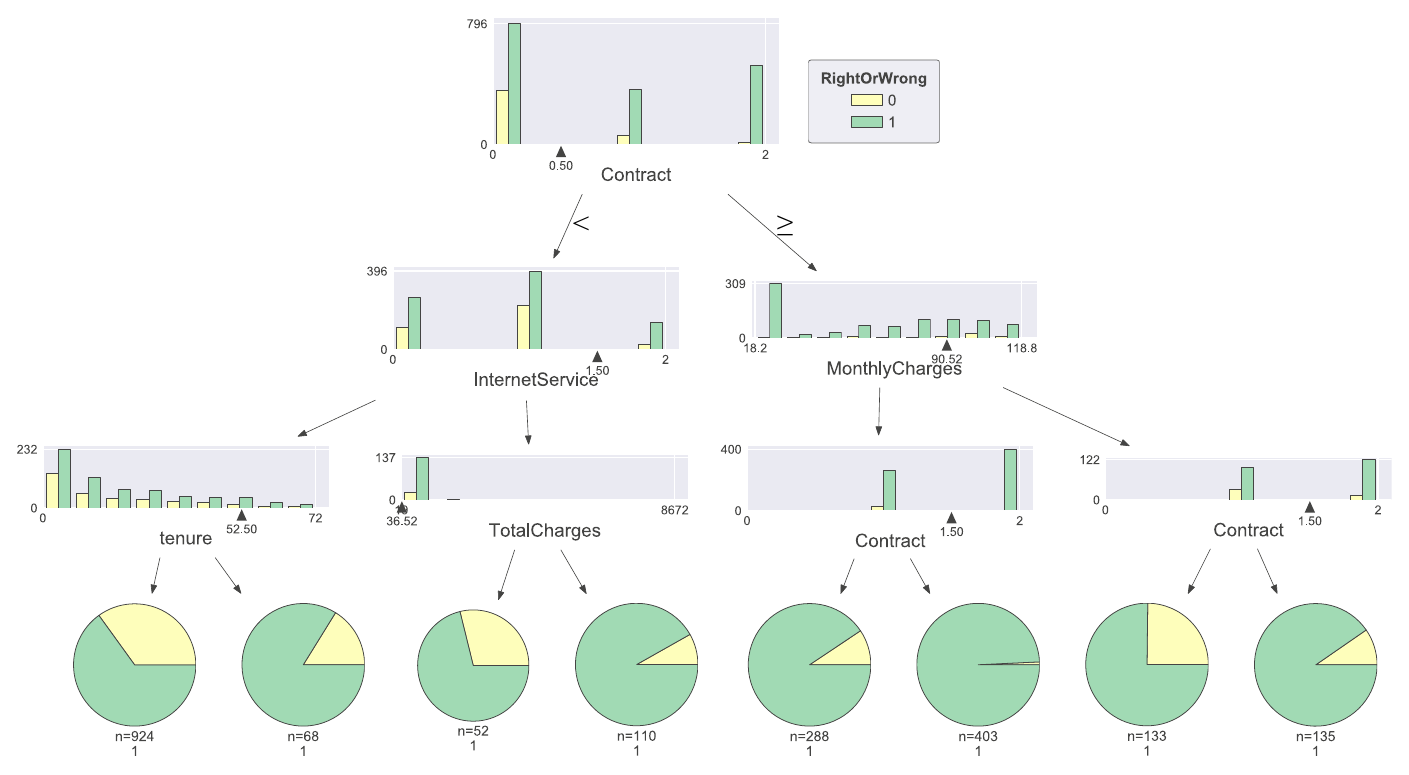
どうやらContractが木の最上位に来ているので、予測が当たった or 外れたということを最もよく分ける説明変数らしい。
Contractが0=月々払いの人達の予測が外れる傾向。逆に1=年払い、2=2年払いの人たちはかなりの割合で予測は当たっているっぽい。
月々払いの人達の中でも、InternetServiceが2=Noの人は予測が当たる傾向で、0=DSL、1=Fiber optic(光ファイバー)の人たちは外れている人も多いとかがわかる。
ここで前に出していたグラフをもう一度見てみる。
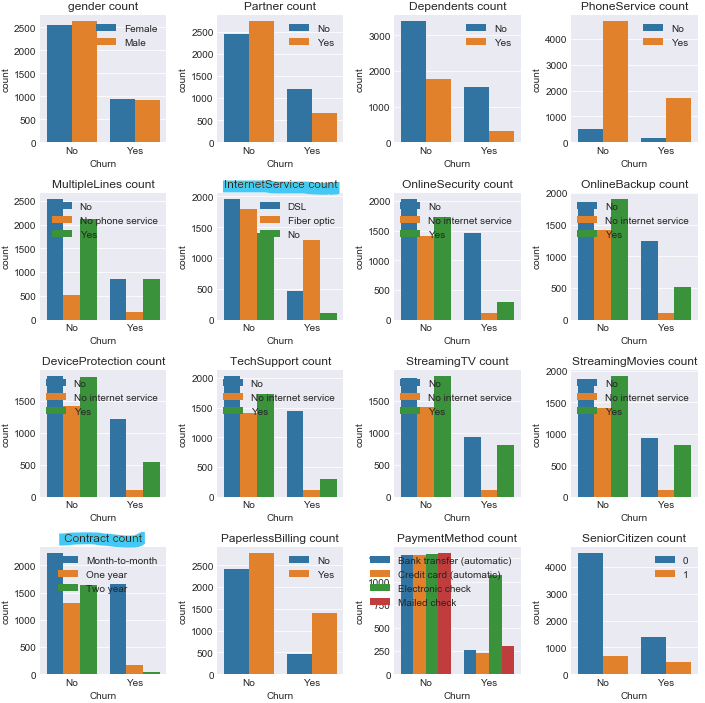
Contractが月々払いの人はChurnのYesもNoも多いし、InternetServiceが光ファイバーの人はChurnのYesもNoも多いなどが読み取れる。
(インターネットサービス使っている人が解約する傾向って、回線遅いから不満を持っているんじゃ?笑)
こういう人たちはChurnのYes, Noの傾向が見えづらいので予測が外れやすいのかなと考えられそうだし、実際に決定木で可視化した結果、予測が外れてしまう傾向にあることがわかった。
TotalChargesも木に出てきているけど、ある程度値が大きくなると予測精度の傾向は変わらなさそう。
とりあえずこれら結果を踏まえて、合成変数とか、clippingとかした変数を追加して、もう一度モデルを作り精度を確認してみる。
fig=plt.figure(figsize=(10,10))
ax1=plt.subplot(2,2,1)
ax2=plt.subplot(2,2,2)
ax3=plt.subplot(2,2,3)
ax4=plt.subplot(2,2,4)
# TotalChargesのヒストグラム
ax1.hist(X_train['TotalCharges'].values,bins=20)
ax1.set_title('X_train TotalCharges')
ax2.hist(X_test['TotalCharges'].values,bins=20)
ax2.set_title('X_test TotalCharges')
# TotalChargesをClipping
upperbound, lowerbound = np.percentile(X_train['TotalCharges'].values, [0, 90])
TotalCharges_train = np.clip(X_train['TotalCharges'].values, upperbound, lowerbound)
ax3.hist(TotalCharges_train,bins=20)# TotalChargesのヒストグラム
ax3.set_title('X_train TotalCharges clipping')
# TotalChargesをClipping
upperbound, lowerbound = np.percentile(X_test['TotalCharges'].values, [0, 90])
TotalCharges_test = np.clip(X_test['TotalCharges'].values, upperbound, lowerbound)
ax4.hist(TotalCharges_test,bins=20)# TotalChargesのヒストグラム
ax4.set_title('X_test TotalCharges clipping')
plt.show()
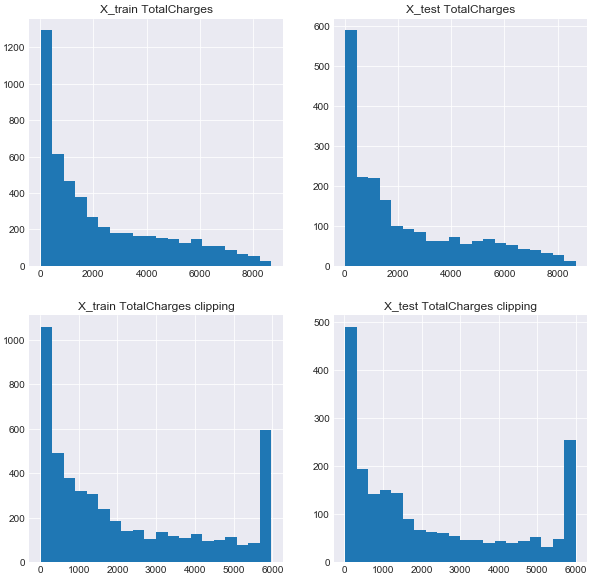
# 変数を加えた新しいTrain, Testを作る
new_X_train=X_train.copy()
new_X_test=X_test.copy()
# TotalChargesをClippingしたものに変更
new_X_train['TotalCharges']=TotalCharges_train
new_X_test['TotalCharges']=TotalCharges_test
# ContractとInternetServiceの合成変数を作る
new_X_train['Contract_InternetService']=new_X_train['Contract'].astype(str)+new_X_train['InternetService'].astype(str)
new_X_test['Contract_InternetService']=new_X_test['Contract'].astype(str)+new_X_test['InternetService'].astype(str)
# ContractとInternetServiceの合成変数をLabelEncoding
le = preprocessing.LabelEncoder()
le.fit(new_X_train['Contract_InternetService'])
new_X_train['Contract_InternetService'] = le.transform(new_X_train['Contract_InternetService'])
le = preprocessing.LabelEncoder()
le.fit(new_X_test['Contract_InternetService'])
new_X_test['Contract_InternetService'] = le.transform(new_X_test['Contract_InternetService'])
# モデルを構築
xgb_model = xgb.XGBClassifier()
xgb_model.fit(new_X_train, y_train)
print('Train accuracy_score',xgb_model.score(new_X_train, y_train))
y_true=y_test.values
y_pred=xgb_model.predict(new_X_test)
# 精度の検証
print('')
print('Test accuracy_score',accuracy_score(y_true, y_pred))
print('Test precision_score',precision_score(y_true, y_pred))
print('Test recall_score',recall_score(y_true, y_pred))
print('Test f1_score',f1_score(y_true, y_pred))
# 混同行列の確認
result=pd.DataFrame({'y_true':y_true,'y_pred':y_pred})
result['dummy']=1
display(result.pivot_table(result,index='y_true',columns='y_pred',aggfunc='count').fillna(0))
結果:
Train accuracy_score 0.8253549695740365
Test accuracy_score 0.7998106956933271
Test precision_score 0.6406926406926406
Test recall_score 0.5352622061482821
Test f1_score 0.5832512315270936
最初の結果(再掲):
Train accuracy_score 0.8267748478701825
Test accuracy_score 0.7946048272598202
Test precision_score 0.6307692307692307
Test recall_score 0.5189873417721519
Test f1_score 0.5694444444444443
混同行列
1:解約、0:未解約
結果:

最初の結果(再掲):
すべての評価指標でTestデータに対する精度が向上した。
まとめ
データの読み込み、前処理、データの確認、モデル構築・精度確認、予測が外れる要因調査まで全部記述した。
この記事の本題は決定木で予測が外れる要因を調べられるのではないか?という考えを実践したこと。
理論とか解釈が間違っていたらゴメンナサイ。
PoCとかでお客さんに、予測モデルの現状の問題点とか報告するときとかに便利かもしれないと思った。
学習曲線とかも出しつつ、決定木の結果も見せて、「データが足りないかもー」とか、「この辺で予測が外れて詰まっているのでこんな感じで対処しよかなーって思ってますー」とかお客さんと議論するのも良い。
そういう話の中でドメイン知識が豊富なお客さんから「そういえばこんなデータもあって変数に加えられるかも?」とか思い付きがあったりして助けられる場面もあると思われる。
決定木は見やすいからね!SHAP値載せてもいいけど、お客さんには分かりづらいかもしれないし、説明も難しい。
おまけ(SHAP)
SHAP値でも予測が外れた時の顧客の傾向を確認してみる。
(まだ理解しきれていないので解釈の仕方を間違えているかもしれない。)
やり方は以下のKooさんのブログを参照。
SHAPを使って機械学習モデルと対話する
import shap
# XGBoostでモデルを作る
xgb_model = xgb.XGBClassifier()
xgb_model.fit(X_train, y_train)
# notebook内でJavascriptを動かすための呪文らしい
shap.initjs()
# modelと解釈したいデータを渡す。
X_test=X_test.reset_index().drop('index',axis=1)# indexを初期化しておく
explainer = shap.TreeExplainer(model=xgb_model)
shap_values = explainer.shap_values(X=X_test)
# summary_plot
shap.summary_plot(shap_values,X_test)
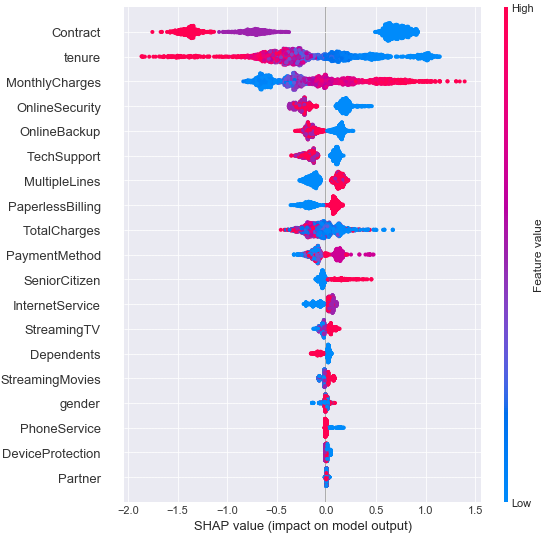
summary_plotを見る。
色が赤いほどその変数の値が高く、青いほどその変数の値が低いことを表し、横軸がSHAP値になる。
点が個々のサンプルを表し、特徴量は予測全体への影響力が大きい順に上から並んでいるので、Contractが最も影響力が大きい。
Contractが0=月々払いは予測に対して正の影響(つまり解約する方向の予測)を与え、1=年払い、2=2年払いは予測に対しては負の影響(つまり解約しない方向の予測)を与えていると読み取る。
月々払いは予測に対して正の影響(つまり解約する方向の予測)を与えているのがそもそも外れる原因なんだろうなぁ。とか考える。
次に予測が当たった顧客、外れた顧客がどの変数で引っ張られて最終的な予測が出たのか、予測の典型的なパターンを可視化してみる。
# 予測が外れたindex、当たったindexを取得
make_index=X_test.copy()
make_index['y_pred']=y_pred
make_index['y_true']=y_true
make_index['tf']=0
make_index.loc[aaa['y_true']!=aaa['y_pred'], 'tf']=1
miss=make_index[make_index['tf']==1].index.values
nonmiss=make_index[make_index['tf']==0].index.values
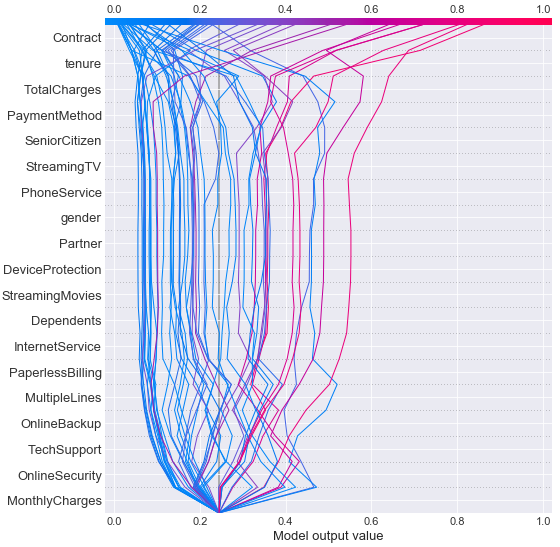
# decision_plotで当たった人の可視化
shap.decision_plot(explainer.expected_value\
, shap_values[nonmiss[:50]], X_test.iloc[nonmiss[:50],:]\
,link="logit",ignore_warnings = True, feature_order='hclust')
# decision_plotで外れた人の可視化
shap.decision_plot(explainer.expected_value\
, shap_values[miss[:50]], X_test.iloc[miss[:50],:]\
,link="logit",highlight=range(len(miss[:20])),ignore_warnings = True, feature_order='hclust')
当たった顧客
外れた顧客
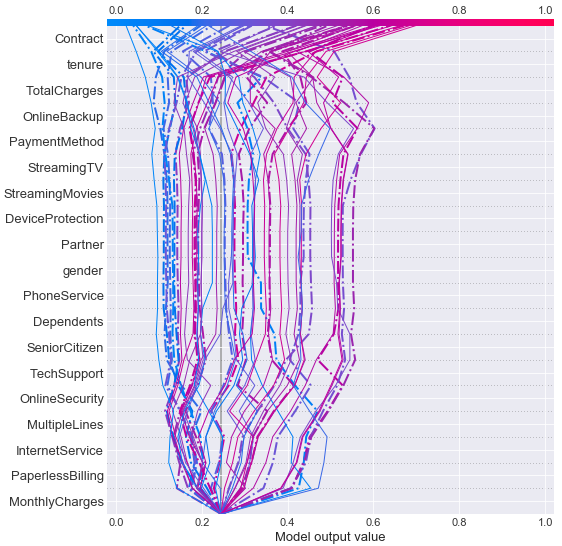
色が赤いほど解約する方向(=1)に向かい、青いほど解約しないという方向(=0)に向かうことを示している。
これを見るとContractやtenureに大きく引っ張られて最終的な予測結果になっていることが見えるが、外れた顧客はContractやtenureにより間違った予測に引っ張られている傾向も見える。
これら結果から特徴量としてContractやtenureに何かしら手を加える方法を考えたりしてもいいかもしれない。
以上!