はじめに
今回はResnet [He et al.,2016] を解説・実装していこうと思います!
元論文はこちら
Deep Residual Learning for Image Recognition
被引用数:199975(とんでもないですねw)
Resnet内部における恒等写像に関する解析論文
Identity Mappings in Deep Residual Networks
解説編
(できる限り論文を引用して解説していきます,訳などに問題があればご指摘ください.)
まずは,こちらをご覧くださいませませ.

NNの層を深くすれば良いモデルになりそうですが,実際に学習させてみるとそのようにならないわけですね.(画像では,20層の方が良い精度を出している)
これをdegradationというらしいです.(日本語だとモデル劣化?と訳せば良いですかね.勾配消失問題などを含めた一般的な話ですかね?)
じゃあ!ということで筆者たちは,Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it.There exists a solution by construction to the deeper model:the added layers are identity mapping, and the other layers are copied from the learned shallower modelと,浅いモデルに恒等写像を追加して深いモデルを構築したら,浅いモデルと同等の精度が深いモデルで出せるのでは?と考えたわけです.
しかしながら,But experiments show that our current solvers on hand are unable to find solutions that are comparably good or better than the constructed solution(or unable to do so in feasible time)だったそうで,思った通りの結果が得られなかったそうです.
これの原因が恒等写像を正しく学習できていないとして,今回のResnetを提案するに至ったらしいです.
Residual Blockとは
まずは,Residual Block(以下,ResBlock)アーキテクチャ図から.

ここでいう,$\mathcal{F}(\mathbf{x})$がResBlockです.
筆者らは,To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.と,このResBlockの存在によって,恒等写像を非線形変換の積み重ねで学習するよりも残差ブロックを0にする方が簡単になるでしょうとのこと.
だから,このResBlockの導入によって恒等写像の学習が楽になるそうです.
さらに,Our deep residual nets can easily enjoy accuracy gains from greatly increased depth,producing results substantially better than previous networks
らしく,このResBlockを積み重ねてDeepにする(下図参照)と精度が上がったらしいです.

疑問
個人的には,精度が上がる点が結構疑問ポイントでして。。。
学習の結果,下図のように

浅いネットワークに恒等写像が積み重なったモデルになるのではないか?と思ったわけです.
これだと,浅いネットワークと表現力が変わらないんじゃ無いかと.
すなわち,昨今のResnetの精度に説明がつかない気がしました.
ですがこちらにあるように,ResBlockによって恒等写像の学習が"楽になる"だけで,厳密にResBlockを用いて恒等写像を学習していないとすれば,多少説明がつく気がします.
つまり,どっかのResBlock+skip connection部分で恒等写像を学習して,どっか別の部分では普通に表現を学習しているのかなと.
そして,Our derivation simply that identity shortcut connections and identity after-addition activation are essential for making information propagation smooth.とResnetの解析論文にあるように,このどっかの恒等写像が勾配消失問題に寄与しているから,精度が上がっているのかなと.
この辺は要調査・検証が必要ですね(力尽きました笑).
解説まとめ
いずれにせよ.
モデル劣化問題に対してResBlockを導入することで,恒等写像の学習を楽にし,勾配消失問題が解決され精度を上げることに成功したらしいです.
以上,論文の引用を元に自分なりの解釈を交えつつ解説してみました.
何かあればぜひコメントいただきたいです.
実装編
コーディングはあまり得意ではないので、良い実装にはなっていないかもしれませんがご了承ください、、、
もしよければpytorchが出してる,こちらのコードを参照してみると良いかもです.
ひとまず,BottleNeckBlockやバッチ正規化を含まないResnetを実装します.
下表中,18-layerと書いてあるresnet18を実装します.

この表はアーキテクチャを表しているのですが,如何せん行間が省かれていてこのまま素朴に実装はできません。。。(例えば,活性化関数やpaddingの値は省かれています)
一応,Resnet論文がVERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITIONの論文で提案されたモデルを参考にしているので,こちらを読むと行間が埋まるはずです.
適宜,補足しながら実装していきます.
conv1層
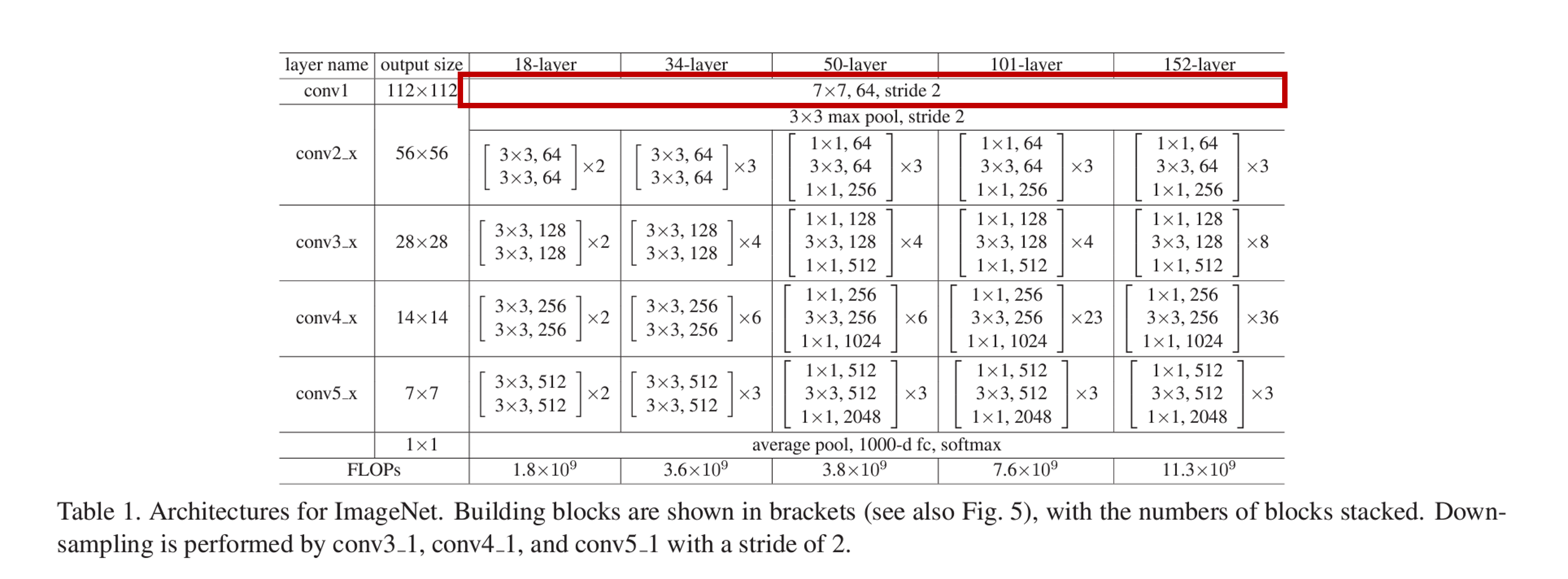
まず,conv1層から.
入力画像の次元を3チャネル,224×224pixelとします.
ここで,conv1によって3チャネル,224×224→7×7のカーネルとストライド数:2により,64チャネル,112×112になります.(この時paddingを3にすることで,画像サイズを224→112にできます)
これに注意して,次のように実装できます.
import torch
import torch.nn as nn
import torch.nn.functional as F
class ResNet18(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
# conv1
self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3)
def forward(self, x):
# conv1
out = self.conv1(x)
out = F.relu(x) #活性化関数
print("===conv1(conv 7*7, stride:2, padding:3)===")
print(" ", out.size(),"\n")
return out
if __name__ == "__main__":
# test
x = torch.randn(3, 224, 224)
model = ResNet18(in_channels=3, num_classes=1000)
print("===input size===")
print(" ",x.size())
model(x)
>>python resnet.py
===input size===
torch.Size([3, 224, 224])
===conv1(conv 7*7, stride:2, padding:3)===
torch.Size([64, 112, 112])
conv2_x(maxpooling層)

続いて,conv2_xのmaxpooling層を実装します.
conv1での出力[64, 112, 112]を[64, 56, 56]に変換します.
この時Maxpoolingを行い,その際のカーネルサイズを3×3,ストライドを2とします.
この元でpaddingを1とすることで,画像サイズを半分の56×56にできます.
以下実装.
class ResNet18(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
# conv1
self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3)
# conv2_x(maxpool)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
def forward(self, x):
# conv1
out = self.conv1(x)
out = F.relu(x) #活性化関数
print("===conv1(conv 7*7, stride:2, padding:3)===")
print(" ", out.size(),"\n")
# conv2_x(maxpool)
out = self.maxpool(out)
out = F.relu(out)
print("===maxpool(maxpool 3*3, stride:2, padding:1)===")
print(" ",out.size(),"\n")
return out
if __name__ == "__main__":
# test
x = torch.randn(3, 224, 224)
model = ResNet18(in_channels=3, num_classes=1000)
print("===input size===")
print(" ",x.size())
model(x)
>>python resnet.py
===input size===
torch.Size([3, 224, 224])
===conv1(conv 7*7, stride:2, padding:3)===
torch.Size([64, 112, 112])
===maxpool(maxpool 3*3, stride:2, padding:1)===
torch.Size([64, 56, 56])
conv2_x(ResBlock)
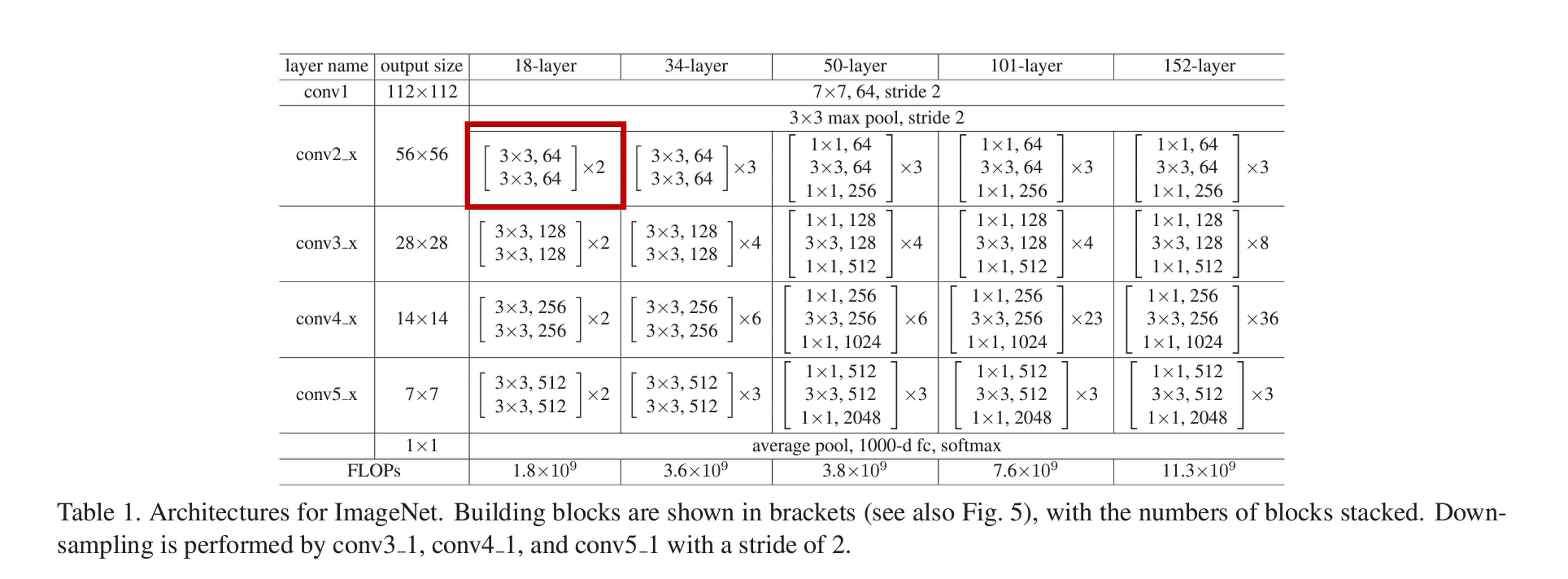
さて,ここからResBlockの実装を行います.が,ここで表中のconv2_xの添字xについて簡単に補足しておくと,これは層の番号を表しています.
さらに表を補足します.上表の赤枠部分は
\begin{bmatrix}
3 \times 3, \,64\\
3 \times 3, \,64
\end{bmatrix}\times 2
のようになっています.これは,
3 \times 3, \,64
が一つの畳み込み層を表し,$3\times3$のカーネルを64枚用いて64チャネルの出力をする畳み込み層であることを表しています.
そして,
\begin{bmatrix}
3 \times 3, \,64\\
3 \times 3, \,64
\end{bmatrix}
は,そのような畳み込み層が2つ組み込まれたResBlockを表します.
さらに,$\times 2$はこのResBlockが2つあることを表しています.
このことを図示すると下の図のようになります(skip connectionと活性化関数もついでに書いています).
かなり雑な図ですみません。

なお,論文中でこのようなResBlockがBuildingBlockと呼ばれていたので,それに準えて実装におけるクラス名はそのようになっています.
さて,これを元にBuildingBlockを実装します.
class BuildingBlock(nn.Module):
"""
H(x) = BuilidingBlock(x) + x
"""
def __init__(self, in_channels, med_channels, out_channels, is_downsample=False):
super().__init__()
# 一旦このif文部分は無視で.
if is_downsample == True:
stride = 2
else:
stride = 1
self.m_1 = nn.Conv2d(in_channels, med_channels, kernel_size=3, stride=stride, padding=1)
self.m_2 = nn.Conv2d(med_channels, out_channels, kernel_size=3, stride=1, padding=1)
def forward(self, x):
out = self.m_1(x)
out = F.relu(out)
out = self.m_2(out)
return out
class ResNet18(nn.Module):
def __init__(self, in_channels, num_classes):
self.num_classes = num_classes
super().__init__()
# conv1
self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3)
# conv2_x(maxpool)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# conv2_x
self.resblock2_1 = BuildingBlock(in_channels=64, med_channels=64, out_channels=64)
self.resblock2_2 = BuildingBlock(in_channels=64, med_channels=64, out_channels=64)
def forward(self, x):
# conv1
out = self.conv1(x)
out = F.relu(x) #活性化関数
print("===conv1(conv 7*7, stride:2, padding:3)===")
print(" ", out.size(),"\n")
# conv2_x(maxpool)
out = self.maxpool(out)
out = F.relu(out)
print("===maxpool(maxpool 3*3, stride:2, padding:1)===")
print(" ",out.size(),"\n")
# conv2_x
out = self.resblock2_1(out) + out
out = F.relu(out)
print("===conv2_1(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
out = self.resblock2_2(out) + out
out = F.relu(out)
print("===conv2-2(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
return out
if __name__ == "__main__":
# test
x = torch.randn(3, 224, 224)
model = ResNet18(in_channels=3, num_classes=1000)
print("===input size===")
print(" ",x.size())
model(x)
===input size===
torch.Size([3, 224, 224])
===conv1(conv 7*7, stride:2, padding:3)===
torch.Size([64, 112, 112])
===maxpool(maxpool 3*3, stride:2, padding:1)===
torch.Size([64, 56, 56])
===conv2_1(residual Block 3*3, stride:1, padding=1)===
torch.Size([64, 56, 56])
===conv2-2(residual Block 3*3, stride:1, padding=1)===
torch.Size([64, 56, 56])
conv3_x
続いて,conv3_x層です.
ここが終われば残りの出力層直前までは同じブロックの繰り返しです.

ここで,表中のoutput sizeとチャネル数に注目してください.
[64, 56, 56]から[128, 28, 28]に変わっていますね.
どこで変わったかというと,表のキャプションにDownsampling is performed by conv3_1, conv4_1,and conv5_1 with a stride of 2.と書いてある通り,conv3_1で変わっています.
そこで,下図のようにチャネル数を2倍に,ストライドを2にすることによってデータサイズを半分にします.

しかし,さらに問題が.
下図をご覧下さい.

そう.サイズが違うので足せないんですよ.
そこで,入力の$x$を

と変換します(論文中Eqn.(2)に相当).
論文では,We also note that although the above notations are about fully-connected layers for simplicity, they are applicable to convolutional layers.と書いてあり,簡単のため全結合っぽく書いているけど,畳み込み演算による変換でも良い(適用可能だ)よと言ってます.
具体的には,(A)The shortcut still performs identity mapping,with extra zero entries padded for increasing dimensions.This option introduces no extra parameter;(B)The projection shortcut in Eqn.(2)is used to match dimensions (done by 1 × 1 convolutions). For both options,when the shortcuts go across feature maps of two sizes,they are performed with a stride of 2.だそうなので,1×1のカーネルでチャネル数を増やし,strideを2にすることで画像サイズを半分にして調整します.
よーするに,

ということです.なお,論文ではこのサイズ調整についても実験をしていますので,よければご参照ください.
てことで,実装.
class BuildingBlock(nn.Module):
"""
H(x) = BuildingBlock(x) + x
"""
def __init__(self, in_channels, med_channels, out_channels, is_downsample=False):
super().__init__()
# 先ほど無視したif文で,ダウンサンプリングが必要な場合はstrideを2にしています.
if is_downsample == True:
stride = 2
else:
stride = 1
self.m_1 = nn.Conv2d(in_channels, med_channels, kernel_size=3, stride=stride, padding=1)
self.m_2 = nn.Conv2d(med_channels, out_channels, kernel_size=3, stride=1, padding=1)
def forward(self, x):
out = self.m_1(x)
out = F.relu(out)
out = self.m_2(out)
return out
class ResNet18(nn.Module):
def __init__(self, in_channels, num_classes):
self.num_classes = num_classes
super().__init__()
# conv1
self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3)
# conv2_x(maxpool)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# conv2_x
self.resblock2_1 = BuildingBlock(in_channels=64, med_channels=64, out_channels=64)
self.resblock2_2 = BuildingBlock(in_channels=64, med_channels=64, out_channels=64)
# conv3_x(一つ目はダウンサンプリングのため,ストライドを2とする)
self.resblock3_1 = BuildingBlock(in_channels=64, med_channels=128, out_channels=128, is_downsample=True)
self.resblock3_2 = BuildingBlock(in_channels=128, med_channels=128, out_channels=128)
def conv11(self, in_channels, out_channels):
"""
入力xの調整用
if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer.
だそうなので,画像のサイズが1/2になり,フィルタの数が2倍になっていく.
そのため,画像のサイズを調整し,チャンネル数も調整する必要がある.
画像のサイズはstrideを2にすることで,1/2に,チャンネル数は1*1のカーネルをin_channelsの2倍用いて,畳み込みをすればよい.
"""
return nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=2, bias=False)
def forward(self, x):
# conv
out = self.conv1(x)
out = F.relu(out)
print("===conv1(conv 7*7, stride:2, padding:3)===")
print(" ", out.size(),"\n")
# maxpool
out = self.maxpool(out)
out = F.relu(out)
print("===maxpool(maxpool 3*3, stride:2, padding:1)===")
print(" ",out.size(),"\n")
# conv2_x
out = self.resblock2_1(out) + out
out = F.relu(out)
print("===conv2_1(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
out = self.resblock2_2(out) + out
out = F.relu(out)
print("===conv2-2(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
# conv3_x
# resblock3_1で入力画像のサイズ調整
out = self.resblock3_1(out) + self.conv11(64, 128)(out)
out = F.relu(out)
print("===conv3-1(residual Block 3*3, stride:2, padding=1)===")
print(" ",out.size(),"\n")
out = self.resblock3_2(out) + out
out = F.relu(out)
print("===conv3-2(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
return out
if __name__ == "__main__":
# test
x = torch.randn(3, 224, 224)
model = ResNet18(in_channels=3, num_classes=1000)
print("===input size===")
print(" ",x.size())
model(x)
===input size===
torch.Size([3, 224, 224])
===conv1(conv 7*7, stride:2, padding:3)===
torch.Size([64, 112, 112])
===maxpool(maxpool 3*3, stride:2, padding:1)===
torch.Size([64, 56, 56])
===conv2_1(residual Block 3*3, stride:1, padding=1)===
torch.Size([64, 56, 56])
===conv2-2(residual Block 3*3, stride:1, padding=1)===
torch.Size([64, 56, 56])
===conv3-1(residual Block 3*3, stride:2, padding=1)===
torch.Size([128, 28, 28])
===conv3-2(residual Block 3*3, stride:1, padding=1)===
torch.Size([128, 28, 28])
以降のconv4,5_x層
conv3_xとほぼ同様なので割愛します.
以下実装.
class ResNet18(nn.Module):
def __init__(self, in_channels, num_classes):
self.num_classes = num_classes
super().__init__()
# conv1
self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3)
# conv2_x(maxpool)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# conv2_x
self.resblock2_1 = BuildingBlock(in_channels=64, med_channels=64, out_channels=64)
self.resblock2_2 = BuildingBlock(in_channels=64, med_channels=64, out_channels=64)
# conv3_x(一つ目はダウンサンプリングのため,ストライドを2とする)
self.resblock3_1 = BuildingBlock(in_channels=64, med_channels=128, out_channels=128, is_downsample=True)
self.resblock3_2 = BuildingBlock(in_channels=128, med_channels=128, out_channels=128)
# conv4_x(一つ目はダウンサンプリングのため,ストライドを2とする)
self.resblock4_1 = BuildingBlock(in_channels=128, med_channels=256, out_channels=256, is_downsample=True)
self.resblock4_2 = BuildingBlock(in_channels=256, med_channels=256, out_channels=256)
# conv5_x(一つ目はダウンサンプリングのため,ストライドを2とする)
self.resblock5_1 = BuildingBlock(in_channels=256, med_channels=512, out_channels=512, is_downsample=True)
self.resblock5_2 = BuildingBlock(in_channels=512, med_channels=512, out_channels=512)
# 出力のサイズを指定してAvgPooling
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# fully connectionによって変換
self.fc = nn.Linear(512, self.num_classes)
def conv11(self, in_channels, out_channels):
"""
if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer.
だそうなので,画像のサイズが1/2になり,フィルタの数が2倍になっていく.
そのため,画像のサイズを調整し,チャンネル数も調整する必要がある.
画像のサイズはstrideを2にすることで,1/2に,チャンネル数は1*1のカーネルをin_channelsの2倍用いて,畳み込みをすればよい.
"""
return nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=2, bias=False)
def forward(self, x):
# conv
out = self.conv1(x)
out = F.relu(out)
print("===conv1(conv 7*7, stride:2, padding:3)===")
print(" ", out.size(),"\n")
# maxpool
out = self.maxpool(out)
out = F.relu(out)
print("===maxpool(maxpool 3*3, stride:2, padding:1)===")
print(" ",out.size(),"\n")
# conv2_x
out = self.resblock2_1(out) + out
out = F.relu(out)
print("===conv2_1(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
out = self.resblock2_2(out) + out
out = F.relu(out)
print("===conv2-2(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
# conv3_x
out = self.resblock3_1(out) + self.conv11(64, 128)(out)
out = F.relu(out)
print("===conv3-1(residual Block 3*3, stride:2, padding=1)===")
print(" ",out.size(),"\n")
out = self.resblock3_2(out) + out
out = F.relu(out)
print("===conv3-2(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
# conv4_x
out = self.resblock4_1(out) + self.conv11(128, 256)(out)
out = F.relu(out)
print("===conv4-1(residual Block 3*3, stride:2, padding=1)===")
print(" ",out.size(),"\n")
out = self.resblock4_2(out) + out
out = F.relu(out)
print("===conv4-2(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
# conv5_x
out = self.resblock5_1(out) + self.conv11(256, 512)(out)
out = F.relu(out)
print("===conv5-1(residual Block 3*3, stride:2, padding=1)===")
print(" ",out.size(),"\n")
out = self.resblock5_2(out) + out
out = F.relu(out)
print("===conv5-2(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
return out
if __name__ == "__main__":
# test
x = torch.randn(3, 224, 224)
model = ResNet18(in_channels=3, num_classes=1000)
print("===input size===")
print(" ",x.size())
model(x)
===input size===
torch.Size([3, 224, 224])
===conv1(conv 7*7, stride:2, padding:3)===
torch.Size([64, 112, 112])
===maxpool(maxpool 3*3, stride:2, padding:1)===
torch.Size([64, 56, 56])
===conv2_1(residual Block 3*3, stride:1, padding=1)===
torch.Size([64, 56, 56])
===conv2-2(residual Block 3*3, stride:1, padding=1)===
torch.Size([64, 56, 56])
===conv3-1(residual Block 3*3, stride:2, padding=1)===
torch.Size([128, 28, 28])
===conv3-2(residual Block 3*3, stride:1, padding=1)===
torch.Size([128, 28, 28])
===conv4-1(residual Block 3*3, stride:2, padding=1)===
torch.Size([256, 14, 14])
===conv4-2(residual Block 3*3, stride:1, padding=1)===
torch.Size([256, 14, 14])
===conv5-1(residual Block 3*3, stride:2, padding=1)===
torch.Size([512, 7, 7])
===conv5-2(residual Block 3*3, stride:1, padding=1)===
torch.Size([512, 7, 7])
出力層
出力層では,average poolingによって1 × 1まで画像サイズを落とし,1次元化した後に全結合をして,クラスラベルの数まで次元を変換します.
class ResNet18(nn.Module):
def __init__(self, in_channels, num_classes):
self.num_classes = num_classes
super().__init__()
# conv1
self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3)
# conv2_x(maxpool)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# conv2_x
self.resblock2_1 = BuildingBlock(in_channels=64, med_channels=64, out_channels=64)
self.resblock2_2 = BuildingBlock(in_channels=64, med_channels=64, out_channels=64)
# conv3_x(一つ目はダウンサンプリングのため,ストライドを2とする)
self.resblock3_1 = BuildingBlock(in_channels=64, med_channels=128, out_channels=128, is_downsample=True)
self.resblock3_2 = BuildingBlock(in_channels=128, med_channels=128, out_channels=128)
# conv4_x(一つ目はダウンサンプリングのため,ストライドを2とする)
self.resblock4_1 = BuildingBlock(in_channels=128, med_channels=256, out_channels=256, is_downsample=True)
self.resblock4_2 = BuildingBlock(in_channels=256, med_channels=256, out_channels=256)
# conv5_x(一つ目はダウンサンプリングのため,ストライドを2とする)
self.resblock5_1 = BuildingBlock(in_channels=256, med_channels=512, out_channels=512, is_downsample=True)
self.resblock5_2 = BuildingBlock(in_channels=512, med_channels=512, out_channels=512)
# 出力のサイズを指定してAvgPooling
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# fully connectionによって変換
self.fc = nn.Linear(512, self.num_classes)
def conv11(self, in_channels, out_channels):
"""
if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer.
だそうなので,画像のサイズが1/2になり,フィルタの数が2倍になっていく.
そのため,画像のサイズを調整し,チャンネル数も調整する必要がある.
画像のサイズはstrideを2にすることで,1/2に,チャンネル数は1*1のカーネルをin_channelsの2倍用いて,畳み込みをすればよい.
"""
return nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=2, bias=False)
def forward(self, x):
# conv
out = self.conv1(x)
out = F.relu(out)
print("===conv1(conv 7*7, stride:2, padding:3)===")
print(" ", out.size(),"\n")
# maxpool
out = self.maxpool(out)
print("===maxpool(maxpool 3*3, stride:2, padding:1)===")
print(" ",out.size(),"\n")
# conv2_x
out = self.resblock2_1(out) + out
out = F.relu(out)
print("===conv2_1(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
out = self.resblock2_2(out) + out
out = F.relu(out)
print("===conv2-2(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
# conv3_x
out = self.resblock3_1(out) + self.conv11(64, 128)(out)
out = F.relu(out)
print("===conv3-1(residual Block 3*3, stride:2, padding=1)===")
print(" ",out.size(),"\n")
out = self.resblock3_2(out) + out
out = F.relu(out)
print("===conv3-2(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
# conv4_x
out = self.resblock4_1(out) + self.conv11(128, 256)(out)
out = F.relu(out)
print("===conv4-1(residual Block 3*3, stride:2, padding=1)===")
print(" ",out.size(),"\n")
out = self.resblock4_2(out) + out
out = F.relu(out)
print("===conv4-2(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
# conv5_x
out = self.resblock5_1(out) + self.conv11(256, 512)(out)
out = F.relu(out)
print("===conv5-1(residual Block 3*3, stride:2, padding=1)===")
print(" ",out.size(),"\n")
out = self.resblock5_2(out) + out
out = F.relu(out)
print("===conv5-2(residual Block 3*3, stride:1, padding=1)===")
print(" ",out.size(),"\n")
# avgpool
out = self.avgpool(out)
out = F.relu(out)
print("===avgpool===")
print(" ",out.size())
# fully connection
out = self.fc(out.flatten())p
print("===fully connection===")
print(" ",out.size())
# 必要に応じてsoftmax
return out
if __name__ == "__main__":
# test
x = torch.randn(3, 224, 224)
model = ResNet18(in_channels=3, num_classes=1000)
print("===input size===")
print(" ",x.size())
model(x)
===input size===
torch.Size([3, 224, 224])
===conv1(conv 7*7, stride:2, padding:3)===
torch.Size([64, 112, 112])
===maxpool(maxpool 3*3, stride:2, padding:1)===
torch.Size([64, 56, 56])
===conv2_1(residual Block 3*3, stride:1, padding=1)===
torch.Size([64, 56, 56])
===conv2-2(residual Block 3*3, stride:1, padding=1)===
torch.Size([64, 56, 56])
===conv3-1(residual Block 3*3, stride:2, padding=1)===
torch.Size([128, 28, 28])
===conv3-2(residual Block 3*3, stride:1, padding=1)===
torch.Size([128, 28, 28])
===conv4-1(residual Block 3*3, stride:2, padding=1)===
torch.Size([256, 14, 14])
===conv4-2(residual Block 3*3, stride:1, padding=1)===
torch.Size([256, 14, 14])
===conv5-1(residual Block 3*3, stride:2, padding=1)===
torch.Size([512, 7, 7])
===conv5-2(residual Block 3*3, stride:1, padding=1)===
torch.Size([512, 7, 7])
===avgpool===
torch.Size([512, 1, 1])
===fully connection===
torch.Size([1000])
これでresnet18の実装が完了です.
コード(printデバッグ抜き)
class BuildingBlock(nn.Module):
"""
H(x) = BuildingBlock(x) + x
"""
def __init__(self, in_channels, med_channels, out_channels, is_downsample=False):
super().__init__()
if is_downsample == True:
stride = 2
else:
stride = 1
self.m_1 = nn.Conv2d(in_channels, med_channels, kernel_size=3, stride=stride, padding=1)
self.m_2 = nn.Conv2d(med_channels, out_channels, kernel_size=3, stride=1, padding=1)
def forward(self, x):
out = self.m_1(x)
out = F.relu(out)
out = self.m_2(out)
return out
class ResNet18(nn.Module):
def __init__(self, in_channels, num_classes):
self.num_classes = num_classes
super().__init__()
# conv1
self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3)
# conv2_x(maxpool)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# conv2_x
self.resblock2_1 = BuildingBlock(in_channels=64, med_channels=64, out_channels=64)
self.resblock2_2 = BuildingBlock(in_channels=64, med_channels=64, out_channels=64)
# conv3_x(一つ目はダウンサンプリングのため,ストライドを2とする)
self.resblock3_1 = BuildingBlock(in_channels=64, med_channels=128, out_channels=128, is_downsample=True)
self.resblock3_2 = BuildingBlock(in_channels=128, med_channels=128, out_channels=128)
# conv4_x(一つ目はダウンサンプリングのため,ストライドを2とする)
self.resblock4_1 = BuildingBlock(in_channels=128, med_channels=256, out_channels=256, is_downsample=True)
self.resblock4_2 = BuildingBlock(in_channels=256, med_channels=256, out_channels=256)
# conv5_x(一つ目はダウンサンプリングのため,ストライドを2とする)
self.resblock5_1 = BuildingBlock(in_channels=256, med_channels=512, out_channels=512, is_downsample=True)
self.resblock5_2 = BuildingBlock(in_channels=512, med_channels=512, out_channels=512)
# 出力のサイズを指定してAvgPooling
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# fully connectionによって変換
self.fc = nn.Linear(512, self.num_classes)
def conv11(self, in_channels, out_channels):
"""
if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer.
だそうなので,画像のサイズが1/2になり,フィルタの数が2倍になっていく.
そのため,画像のサイズを調整し,チャンネル数も調整する必要がある.
画像のサイズはstrideを2にすることで,1/2に,チャンネル数は1*1のカーネルをin_channelsの2倍用いて,畳み込みをすればよい.
"""
return nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=2, bias=False)
def forward(self, x):
# conv
out = self.conv1(x)
out = F.relu(out)
# maxpool
out = self.maxpool(out)
out = F.relu(out)
# conv2_x
out = self.resblock2_1(out) + out
out = F.relu(out)
out = self.resblock2_2(out) + out
out = F.relu(out)
# conv3_x
out = self.resblock3_1(out) + self.conv11(64, 128)(out)
out = F.relu(out)
out = self.resblock3_2(out) + out
out = F.relu(out)
# conv4_x
out = self.resblock4_1(out) + self.conv11(128, 256)(out)
out = F.relu(out)
out = self.resblock4_2(out) + out
out = F.relu(out)
# conv5_x
out = self.resblock5_1(out) + self.conv11(256, 512)(out)
out = F.relu(out)
out = self.resblock5_2(out) + out
out = F.relu(out)
# avgpool
out = self.avgpool(out)
out = F.relu(out)
# fully connection
out = self.fc(out.flatten())
# 必要に応じてsoftmax
return out
まとめと感想
今回はresnetについて解説・実装を行いました.
アイデア自体は難しくないですが,実装がやややっかいでした(実装力不足なのもありますが。。。)
次はODENetやりたいですね.(torchdiff使うか,pytorchでRunge-Kutta書くか。。。)
何かあればぜひコメントください.
補足
後は,BottleNeckBlockを組み込めばResnet50などの大規模なモデルを構築できます.
BottleNeckBlockについて簡単に補足すると,

のようにBuildingBlockを少し書き換えたものになります.
論文中に. If the identity shortcut in Fig. 5(right) is replaced with projection, one can show that the time complexity and model size are doubled, as the shortcut is connected to the two high-dimensional ends. So identity shortcuts lead to more efficient models for the bottleneck designs.とあり,計算量?が抑えられる的なことが書いてありました.
なので,モデルが大きくなった時にこのBottleNeckBlockを組み込んでモデルが構成されています.