はじめに
ChatGPTやGPT3の登場に伴って、自然言語処理の分野がめちゃくちゃ盛り上がっているのでその基礎的な(?)word2vecについて調べたのでまとめました。
とはいえ、Word2Vecについては良い記事がたくさんあるので、これは備忘録としての書き物です。
参考:
Alcia Solidさんの動画(youtube)
元論文
その解説論文
「絵で理解するWord2Vecの仕組み」(@Hironsan(TIS株式会社)さんの記事)
Word2Vec Explained (towards data science)
word2vecとは
word2vecを一言で説明すると、これは「単語の分散表現を得る」ことです。
そのために、CBOWやskip-gramといったニューラルネットワークベースのモデルを利用します。
分散表現とは
単語の実数値ベクトルです。
英語では"distributed embedding"と言います。
当たり前かもですが、計算機に何らかの処理(翻訳したり、文章を作成したり、防犯カメラの異常検知など)させる場合には、「数値」に変換してあげる必要があります。
それが画像のデータであれば画像をRGBの値に変換させてあげたり、音声データであれば音をデジタル信号に変換して数値化しますよね。
それと同様に言語もなんらかの数値に変換する、ということです。
word2vecではその「何らかの数値」というのが「実数値のベクトル」になるわけです。
なぜ分散表現??
いくつか理由が考えられます(というよりは良く言われていることですがw)
- 低次元化することで計算量の面で有利
- ベクトル化することで単語の相対的な位置関係がわかる
例えば次の文章を考えてみましょう。
The king is a man.
The queen is a woman.
これら文章中の単語をどうにかして「数値化」するとしたらどのようにすればいいでしょうか?
例えば、素朴にone-hot encodingのような手法で数値化してみましょう。
つまり、文章中の単語の種類に応じて次のようにベクトル化するということです。
The =
\begin{pmatrix}
1 \\
0 \\
0 \\
0 \\
0 \\
0 \\
0 \\
\end{pmatrix},
\quad
king =
\begin{pmatrix}
0 \\
1 \\
0 \\
0 \\
0 \\
0 \\
0 \\
\end{pmatrix},
\quad
is =
\begin{pmatrix}
0 \\
0 \\
1 \\
0 \\
0 \\
0 \\
0 \\
\end{pmatrix},
\quad
a =
\begin{pmatrix}
0 \\
0 \\
0 \\
1 \\
0 \\
0 \\
0 \\
\end{pmatrix},
\\
man =
\begin{pmatrix}
0 \\
0 \\
0 \\
0 \\
1 \\
0 \\
0 \\
\end{pmatrix},
\quad
queen =
\begin{pmatrix}
0 \\
0 \\
0 \\
0 \\
0 \\
1 \\
0 \\
\end{pmatrix},
\quad
woman =
\begin{pmatrix}
0 \\
0 \\
0 \\
0 \\
0 \\
0 \\
1 \\
\end{pmatrix}
この文章において例えばqueenは
\begin{pmatrix}
0 \\
0 \\
0 \\
0 \\
0 \\
1 \\
0 \\
\end{pmatrix}
というベクトルと等価ということです。(逆に、このベクトルを見たら"queen"という文字列を想起するということです)
上記の表現は例文中の全ての単語と1対1に対応するので数値化として矛盾はないです。
しかし、この表現では元の文章の単語数がもっと膨大だったら??、そしてこの単語の数値化よりももっといい数値化は無い?? という問題が生じます。
基本的に文章はたくさんの単語によって成り立ちます。
例えばそれが1万、10万単語で構成される文章であると、その分の次元数が必要になります。
また、このような数値化では単語と単語の関係性は見えません。
そこで分散表現を用いて、低次元の(2値変数でない)実数値ベクトルとして単語を表現したくなるわけです。
これによって次のような不思議な演算が可能になります。
word2vecによって、各単語が次のようにベクトル化できたとします。
king =
\begin{pmatrix}
2 \\
3 \\
\end{pmatrix},
\quad
man =
\begin{pmatrix}
0.2 \\
0.2 \\
\end{pmatrix},
\quad
queen =
\begin{pmatrix}
1.6 \\
2.6 \\
\end{pmatrix},
\quad
woman =
\begin{pmatrix}
-0.2 \\
-0.2 \\
\end{pmatrix},
\quad
The = \cdots
このような分散表現が得られるとすると、
king - man + woman = queen
という不思議な等式が書けます。
もちろん、実際にはモデルの最適化によって単語の分散表現が得られるので、学習する文章によってはこうならない場合もあります。上記の分散表現が得られた例で学習に使われた文章では、おそらくkingとqueenは似ていて、それぞれmanという要素とwomanという要素を持っている、というような意味の文章が書かれているのでしょう。
さて、ここで改めて分散表現を見てみると、
queen =
\begin{pmatrix}
1.6 \\
2.6 \\
\end{pmatrix}
という数値(ベクトル)が それ単体 で何を意味しているかは分かりません。(≒単語の絶対的な値はわからない、バナナの数値は?東京の数値は?と言われても答えられないですよね笑)
しかし、学習のために用いた文章中においては queenはkingから男の人の要素を引いて、女の人の要素を足したもの という意味の単語であるということがこの分散表現から読み取れます。
つまり、分散表現によって文章中の意味解釈が数値的に行えるようになった ということです。
例えば(こんな結果になるかわかりませんが、というよりword2vecじゃできない??)、家庭内で圧倒的に父親より母親の権力が強いということが書かれている文章では分散表現によって下記のような等式が得られるかもしれないし、
父親は母親の1000分の1
father = (mother - woman + man) / 1000
フランスの首都はパリです、日本の首都は東京です、といった表現がされている文章では、
Paris = Tokyo - Japan + France
のような等式が得られるかもしれませんね。
分散表現すごいですねー。
word2vecはどのように分散表現を求めるか
ここまでで分散表現とは何か、なぜそれが欲しいのか、というところまで説明しました。
それでは実際に、学習する文章からどのように文章中単語の分散表現を得るのかについて簡単に説明します。
実は、結論から言うとContinuous Bag-of-Words(CBOW)やskip-gram(NNモデル)に単語を学習させたときの最適なパラメータ(重み) がその文章中における単語の分散表現になっています。
ちなみに、CBOWやskip-gramがどんなタスクに対するモデルかと言うと、
- CBOW :ある文章中の単語Xの周辺単語から、単語Xを予測する
- skip-gram:ある文章中の単語Xから周辺単語を予測する
というタスクに対するモデルです。
なんだかよくわからないモデルですね。笑
ただ、ここで重要なのはそのモデルのパラメータ(重み)は その文章中に含まれる単語の分散表現を与える ということです。
ここでは直感的な説明をしますが、今回は「ある単語からその周辺単語」、「周辺単語からある単語」という文章中の単語ごとの関係性に基づくモデルなので、そのパラメータは「文章における単語の相対的な値」を表すということですね。
詳しくは別の機会でpythonとpytorchを用いて実装をしようと思っているので、その時に。。。
CBOWとskip-gramはこちらを参考にすると良いかもです。
NLP 101: Word2Vec — Skip-gram and CBOW(towards data science)
さて、ここまで調べて僕は思いました。
冗長では!?
と。
つまり、なんだか変なタスクを解いて、そのパラメータが分散表現であるという主張なわけですが、直接対象のベクトル求めたらええやんと思いました。
しかし、少し考えたらそれはとても難しいタスクになることがわかりました。
それを説明するために次の教師あり学習の簡略図を見てください。
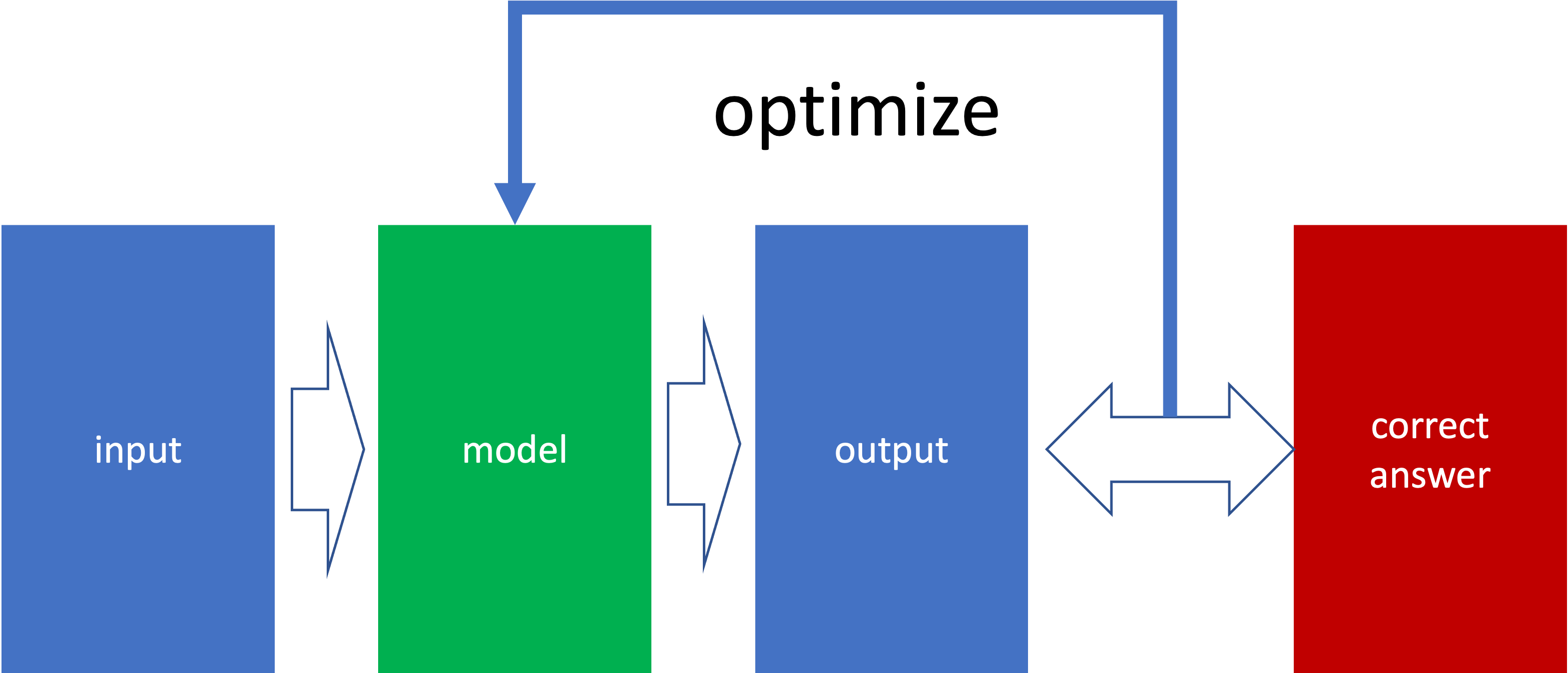
これを見て少し考えるとわかるのですが、今回のような教師あり学習には正解ラベルが必要です。
それでは、今回の単語の分散表現における正解ラベルってなんでしょうか?
…
…
…。
無い、、、というかそれを決めるのってむずいですよね。
queenの分散表現は?manの分散表現は?
これらに対する絶対的な表現ってないですよね。
だからこのタスクは正解ラベルの決め方にかなりの自由度がある難しいタスクなわけです。
そこでCBOWやskip-gramのようなものを考えて、分散表現を得る、と。
賢いですわぁ、、、
まとめ
- word2vecは、ある文章中における単語の分散表現を得るものだよ
- 分散表現はモデル(CBOWやskip-gram)のパラメータだよ
ちなみに
BERTというモデル(transformerのエンコーダ部分を何層も重ねたやつ)も単語の分散表現を得るためのモデルみたいです。
word2vecよりも新しいし、より良い分散表現を与えるみたいです。
今度調べてみます。
そして昨今流行っているGhatGPTくんはtransformer+強化学習によるモデルを使ってるらしい。