はじめに
データ分析では、Apache Spark + Cassandraの組み合わせて実装する選択肢もよくあります。
Apache Sparkとは
Apache Sparkはとても有名なデータ分析ツールです。
Access data in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.
RDD(Resilient Distributed Dataset)とDataFrameとDataSetなど。。。
Cassandraとは
CassandraはNoSQLのワイドカラム型のデータベースです。

Manage massive amounts of data, fast, without losing sleep
出典:http://cassandra.apache.org/
特に最初からスケーラビリティの考慮していますので、クラスターが簡単にできます。
CSVファイルデータをCassandraに保存するサンプル
Sparkはいろんな機能がありますが、CSVをCassandraに保存するサンプル作成してみます。
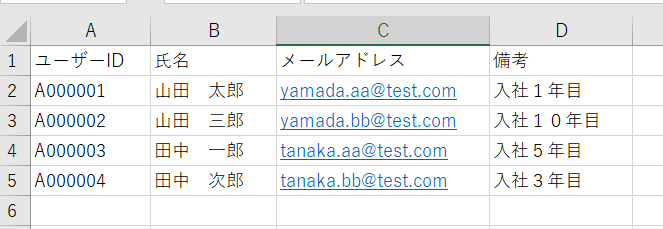
users.csvというサンプルファイルを作成
Gradleのプロジェクトにライブラリ導入
build.gradle
dependencies {
// https://mvnrepository.com/artifact/org.scala-lang/scala-library
compile group: 'org.scala-lang', name: 'scala-library', version: '2.11.12'
// https://mvnrepository.com/artifact/org.apache.spark/spark-core
compile group: 'org.apache.spark', name: 'spark-core_2.11', version: '2.3.4'
// https://mvnrepository.com/artifact/com.datastax.spark/spark-cassandra-connector
compile group: 'com.datastax.spark', name: 'spark-cassandra-connector_2.11', version: '2.4.1'
// https://mvnrepository.com/artifact/org.apache.spark/spark-sql
compile group: 'org.apache.spark', name: 'spark-sql_2.11', version: '2.3.4'
// https://mvnrepository.com/artifact/org.apache.spark/spark-streaming
compile group: 'org.apache.spark', name: 'spark-streaming_2.11', version: '2.3.4'
}
CSVからCassandraに保存し、DBから取得してみる。
CsvReader.java
package com.test.spark;
import com.datastax.driver.core.Session;
import com.datastax.spark.connector.cql.CassandraConnector;
import java.util.List;
import org.apache.log4j.Logger;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Column;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
public class CsvReader {
private static final Logger logger = Logger.getLogger(CsvReader.class);
public static void main(String[] args) {
// Spark設定
SparkConf conf = new SparkConf();
conf.setAppName("CSVReader");
conf.setMaster("local[*]");
conf.set("spark.cassandra.connection.host", "192.168.10.248");
conf.set("spark.cassandra.connection.port", "9042");
// Cassandraのkeyspaceとテーブル名
String keyspace = "sample";
String tableUser = "user";
String userCsv = "C:\\data\\spark\\users.csv";
JavaSparkContext sc = new JavaSparkContext(conf);
try {
SparkSession sparkSession = SparkSession.builder().master("local").appName("CSVReader")
.config("spark.sql.warehouse.dir", "file:////C:/data/spark").getOrCreate();
// Cassandraのコネクション
CassandraConnector connector = CassandraConnector.apply(sc.getConf());
try (Session session = connector.openSession()) {
// keyspaceある場合は削除する
session.execute("DROP KEYSPACE IF EXISTS " + keyspace);
// keyspaceを作成する
session.execute("CREATE KEYSPACE " + keyspace
+ " WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1}");
// テーブルを作成する
session.execute("CREATE TABLE " + keyspace + "." + tableUser
+ "(user_id TEXT PRIMARY KEY, user_name TEXT, email_address TEXT, memo TEXT)");
}
// CSVからデータを取得する
// テーブル定義に合わせるため、カラムのASも重要
Dataset<Row> csv = sparkSession.read().format("com.databricks.spark.csv").option("header", "true")
.option("encoding", "UTF-8").load(userCsv).select(new Column("ユーザーID").as("user_id"),
new Column("氏名").as("user_name"),
new Column("メールアドレス").as("email_address"),
new Column("備考").as("memo"));
// Cassandraに保存
csv.write().format("org.apache.spark.sql.cassandra")
.option("header", "true")
.option("keyspace", keyspace)
.option("table", tableUser)
.option("column", "user_id")
.option("column", "user_name")
.option("column", "email_address")
.option("column", "memo")
.mode(SaveMode.Append)
.save();
// Cassandraからデータを読み出す
Dataset<Row> dataset = sparkSession.read().format("org.apache.spark.sql.cassandra")
.option("keyspace", keyspace)
.option("table", tableUser).load();
// データセットから配列を取得する
List<Row> asList = dataset.collectAsList();
for (Row r : asList) {
logger.info(r);
}
} catch (Exception e) {
logger.error(e);
} finally {
sc.stop();
sc.close();
}
}
}
Cassandraのデータ
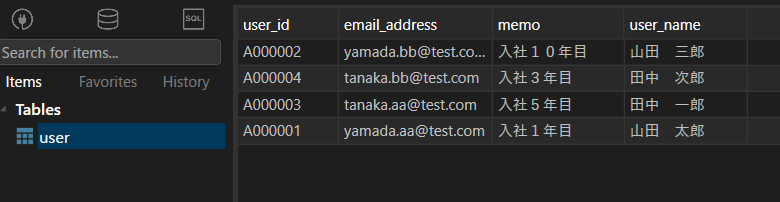
JAVA側の取得したユーザーデータ
19/10/11 23:18:27 INFO CsvReader: [A000002,yamada.bb@test.com,入社10年目,山田 三郎]
19/10/11 23:18:27 INFO CsvReader: [A000004,tanaka.bb@test.com,入社3年目,田中 次郎]
19/10/11 23:18:27 INFO CsvReader: [A000003,tanaka.aa@test.com,入社5年目,田中 一郎]
19/10/11 23:18:27 INFO CsvReader: [A000001,yamada.aa@test.com,入社1年目,山田 太郎]
基本操作などの詳しい資料はガイドにあります。
Spark Programming Guide: https://spark.apache.org/docs/2.2.0/rdd-programming-guide.html
以上