大学時代の友人3人とWEBサービス開発記録シリーズ第4弾。
今回作ろうとしているWEBサービスの構成(こちらの記事で紹介しています)における
バックエンド側(API Gateway+Lambda+DynamoDB)のAPI構築方法についてまとめたいと思います。
前提
- API Gateway
- エンドポイントタイプ:リージョン
- APIキー:必須
- Lambda
- ランタイム:Python 3.8
この記事のスコープ
構成図
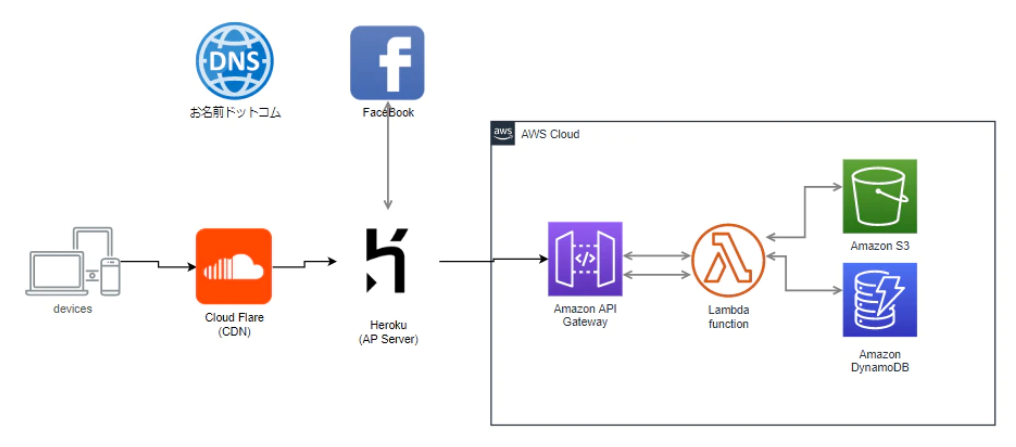
本記事では、下記2点の説明をしたいと思います。
- 上記構成図のAPI Gateway、Lambda、DynamoDB部分について現状の設定内容
- APIに新たなメソッドを追加する場合の変更手順
現状の設定内容
最初に、データの最終的な終着点であるDynamoDBの状況から解説します。
次に、Flaskアプリからのリクエストを受け取るAPI Gatewayの設定を紹介し、
最後に、DynamoDBとAPI Gatewayの間をつなぐLambdaの内容を見ていきます。
DynamoDB
DynamoDBの設定状況を確認するために、AWSマネジメントコンソールからDynamoDBを開きます。
DynamoDBの管理コンソールを開いたら、左メニューから「テーブル」を選択してテーブル一覧を表示します。
参照したいテーブル(今回はripple_prj)を選択すると、テーブルの概要や登録されている項目などの詳細情報が表示されます。
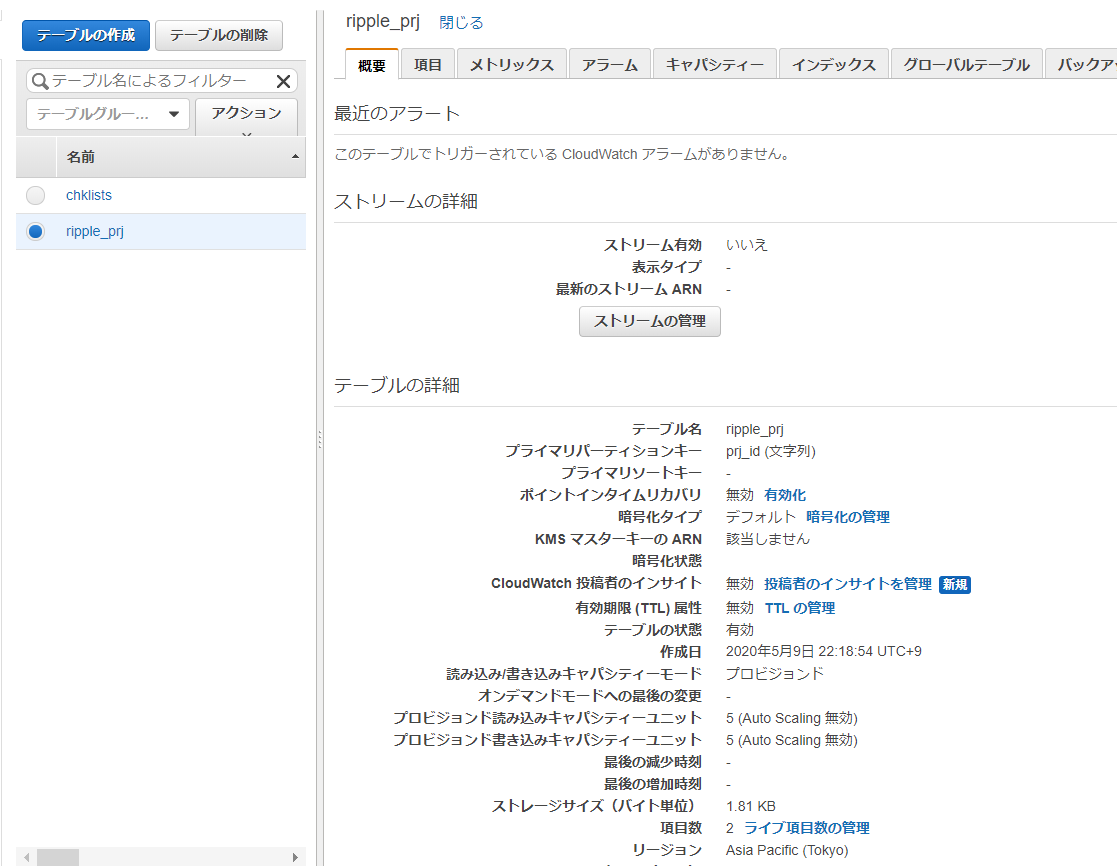
今回使うテーブルripple_prjの名前は、<サイト名>_<リソース名>のルールで命名しています。
つまり、ripple_prjは、rippleサイトのprjリソースを管理するためのテーブルです。
プライマリパーティションキーは、prj_idとしています。
今回制作しているrippleサイトでは、prj情報を全件画面に返してしまい、画面上の表示制御で検索・絞り込みできるようにするため、ソートキーは設定していません。
もしDynamoDBからデータを取得する時点で検索条件を設定したい場合は、条件設定したい項目をソートキーに指定する必要があります。
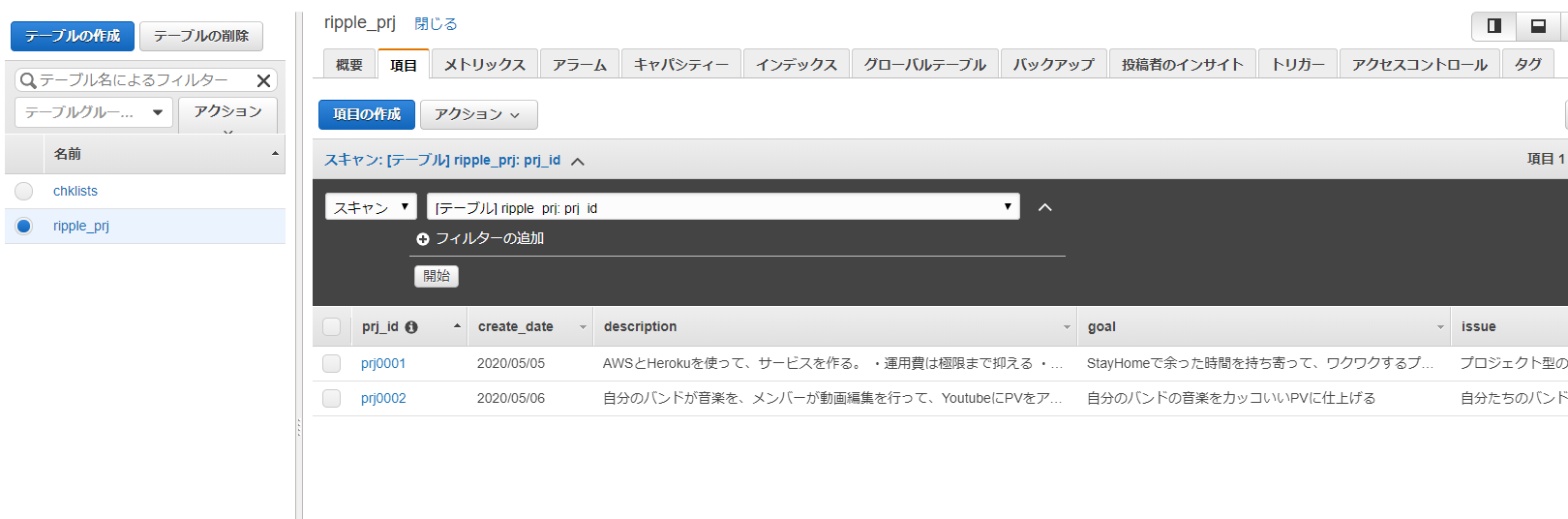
項目タブを開くと、ripple_prjテーブルに登録されているデータを参照することができます。
各行のプライマリパーティションキー(prj_id列で青色表示されているprj0001やprj0002部分)をクリックすると、各レコードの詳細を確認・編集可能です。
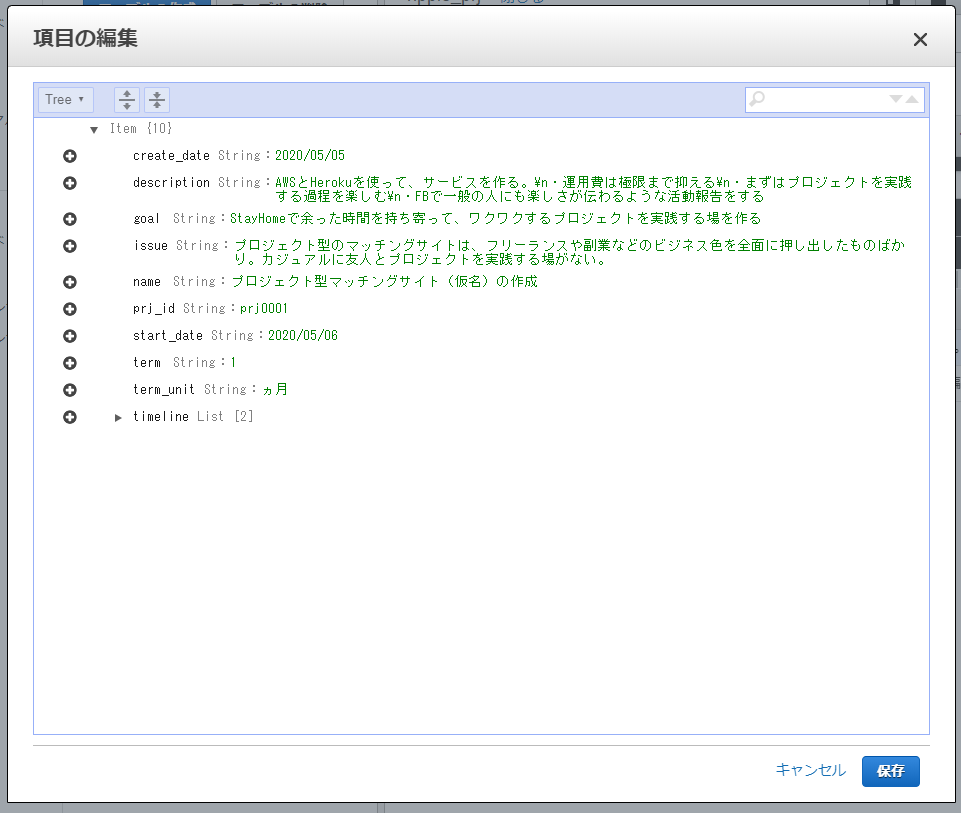
ここまでで、DynamoDB上のテーブルと、テーブル内に格納されているデータの内容について確認できました。
実際にFlaskアプリと連携する際には、このDynamoDBのデータをどのように取得し、どのように登録・更新するかを検討・実装していくことになります。
API Gateway
AWSマネジメントコンソールからAPI Gatewayを開きます。
API Gatewayに設定されているAPI一覧が開きます。
今回制作しているWEBサービスのAPIはrippleという名前で作ってあるので、クリックして詳細を開きます。

API上に設定されているリソースとメソッドの階層構造が表示されます。
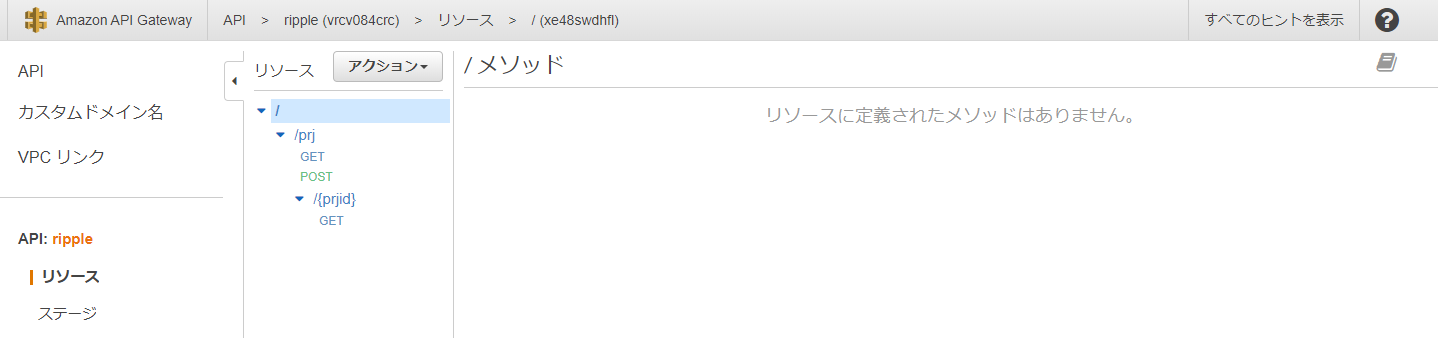
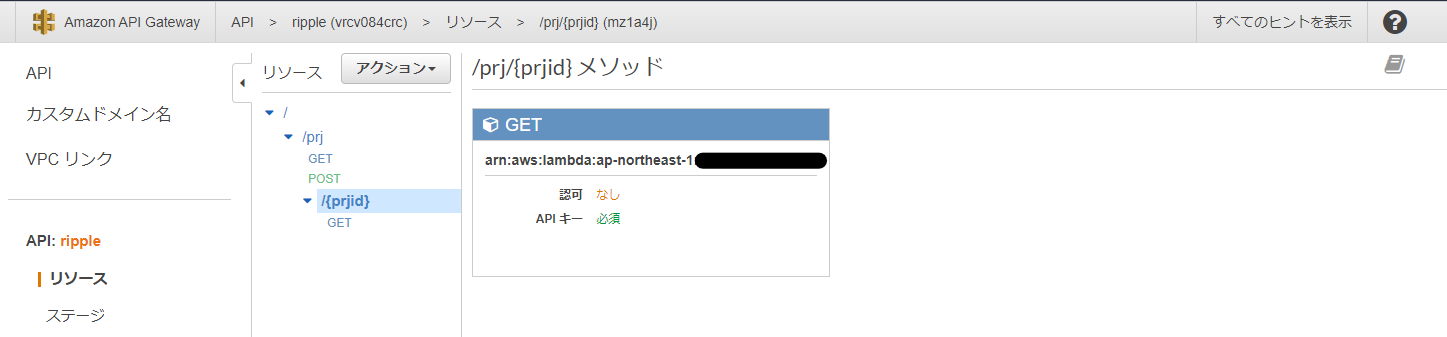
/prj(prjリソース)をクリックするとprjリソースに設定されているメソッドの一覧が表示されます。
GET /prjは、prj一覧の取得処理
POST /prjは、新規prjの登録処理
に対応しています。
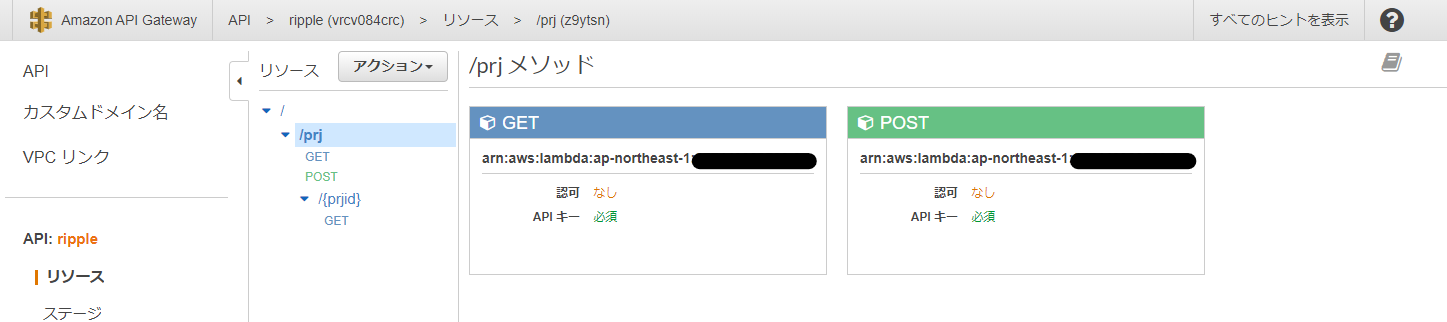
同様に、/{prjid}(/prj/{prjid}リソース)をクリックすると、このリソースに設定されているメソッドの一覧が表示されます。
GET /prj/{prjid}は、prjidで指定される特定のプロジェクト1件を取得する処理
に対応しています。
現状、ripple APIには3種類の処理が登録されていることが確認できました。
次は、それぞれの処理の内容についてさらに細かく見ていきたいと思います。
GET /prj
/prjリソースのGETをクリックすると、メソッド内の処理フローが表示されます。
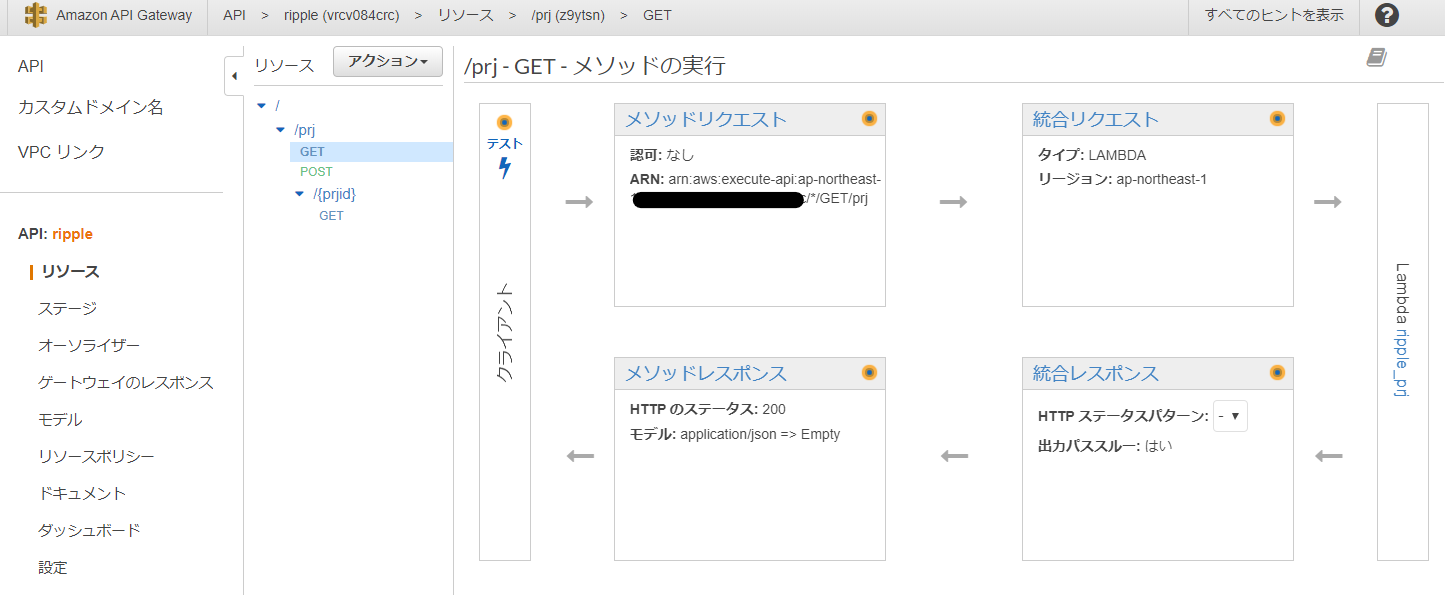
API Gatewayの処理は、下記の流れで行われます。
クライアント(今回でいえば、Heroku上のFlaskアプリ)
→メソッドリクエスト(API Gatewayがクライアントから受け取るパラメータの設定等を行う)
→統合リクエスト(API Gatewayが後続のLambdaへ渡すパラメータの設定を行う)
→Lambda
→統合レスポンス(API GatewayがLambdaから受け取るパラメータの設定を行う)
→メソッドレスポンス(API Gatewayがクライアントに返すパラメータの設定を行う)
→クライアント(API Gatewayの処理結果を受け取る)
GET /prjで設定している部分は、メソッドリクエストと統合リクエストの2カ所です。
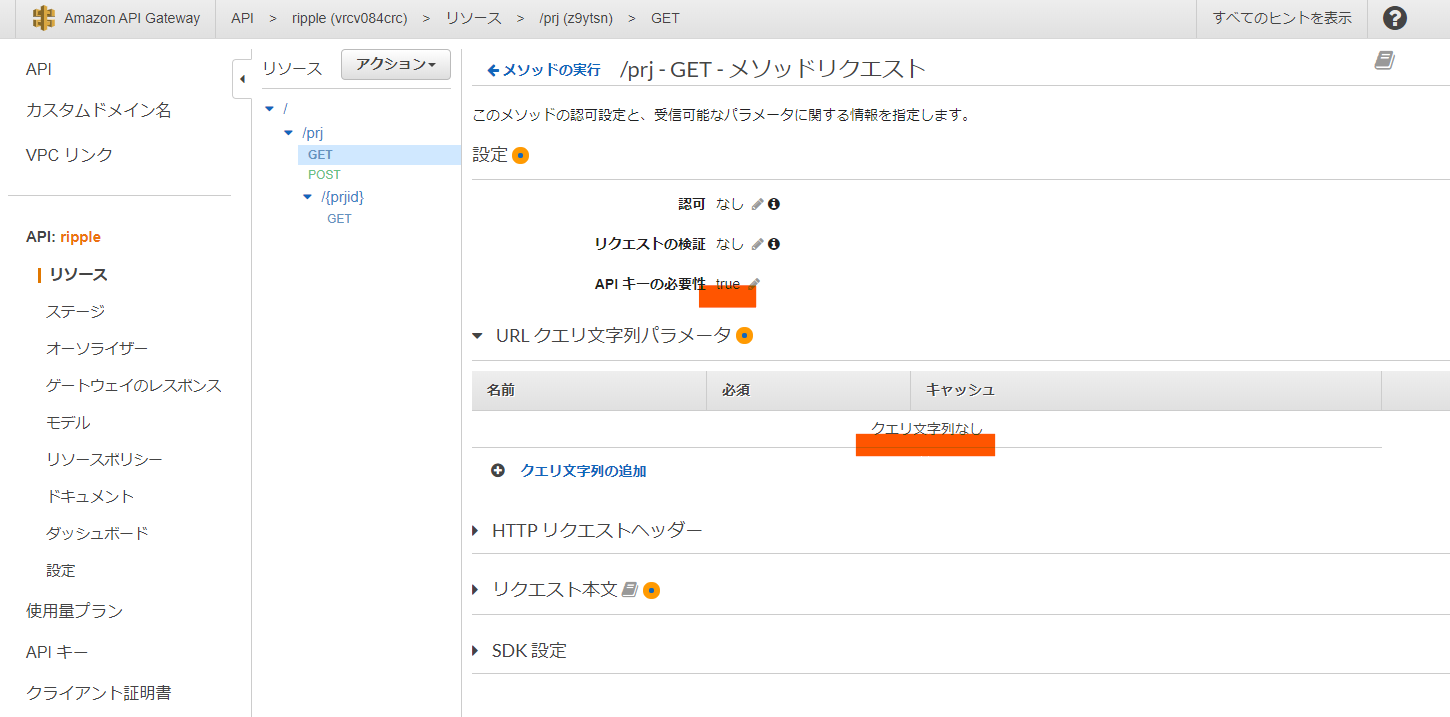
GET /prj メソッドリクエスト
APIキーの必要性をtrueに設定しています。
rippleではすべてのAPIでAPIキー必須としています。
今回APIキー必須としているのは、アクセス元をHeroku上のFlaskアプリのみに制限したいからです。
※なお、オーソライザーを設定すればさらに高度な認証処理を設定することもできますが、今回はそこまでの対応は不要なため、簡単に設定できるAPIキーのみとしています。
URLクエリ文字列パラメータは特に設定していません。
一般に、GETメソッドではhttps://my-api.com/prj?key1=value1&key2=value2のようにURLの末尾に?を付け、key=valueの形式でパラメータを渡すことができます。
今回は、GET /prjの処理がprjの一覧取得であるため、パラメータの設定は不要でした。
統合リクエスト
今回、後続処理をLambdaで実装しているため、
統合タイプ:Lambda
Lambda関数:ripple_prj
を設定しています。(ripple_prjの実装は後述)
Lambdaに渡すパラメータの設定を行うため、マッピングテンプレートを定義をしています。
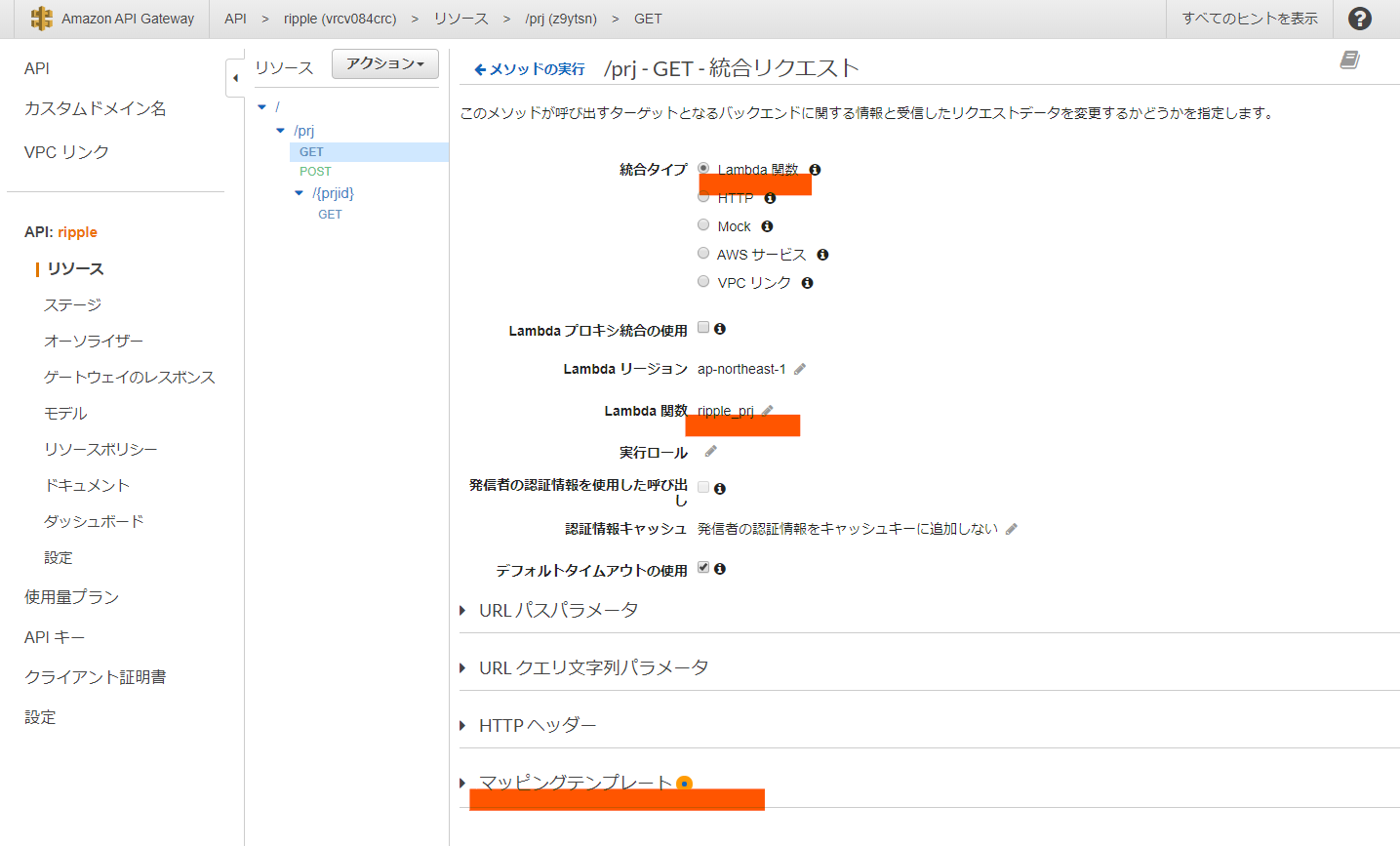
マッピングテンプレートの内容は下記のとおりです。
methodというパラメータに固定文字列`"search"を設定しています。
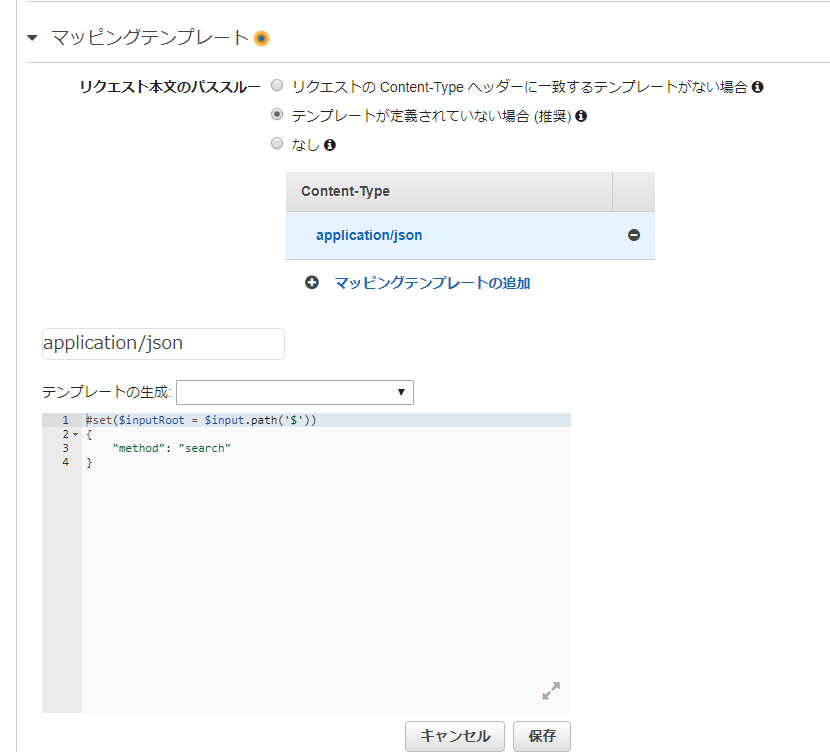
POST /prj
後日追記予定。
- メソッドリクエストの設定内容
- APIキー認証必須
- 統合リクエストの設定内容
- 統合タイプ:Lambda
- Lambda関数:ripple_prj
- マッピングテンプレート:下記参照
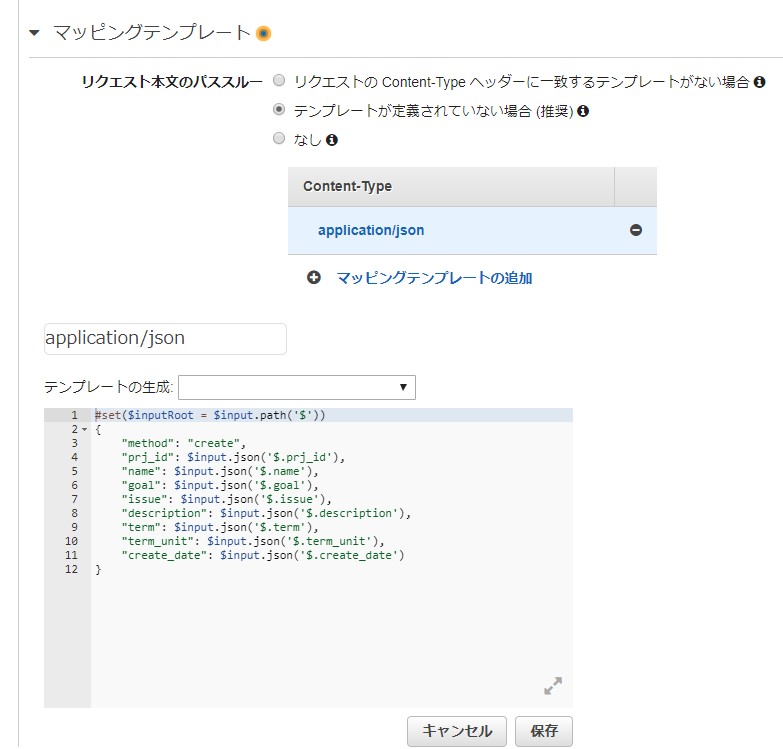
GET /prj/{prjid}
後日追記予定。
- メソッドリクエストの設定内容
- APIキー認証必須
- リクエストパス:prjid
- 統合リクエストの設定内容
- 統合タイプ:Lambda
- Lambda関数:ripple_prj
- マッピングテンプレート:下記参照
Lambda
ripple_rpjというLambda関数を作成しています。
- ランタイム:Python 3.8
- ハンドラ:lambda_function.lambda_handler(デフォルト)
- コード;下記。
import boto3
dynamodb = boto3.resource('dynamodb') #使うリソースを選んでおく
table_name = "ripple_prj" #テーブル名
dynamotable = dynamodb.Table(table_name)
def get(event):
if "prj_id" not in event:
return event
primary_key = {"prj_id": event["prj_id"]} #テーブル名
res = dynamotable.get_item(Key=primary_key) #指定したprymaryで検索して結果を取得
item = res["Item"] #要素を指定してないので全部
return item
def search(event):
response = dynamotable.scan()
items = response['Items']
return items
def create(event):
print(event)
response = dynamotable.put_item(
Item={
'prj_id': event['prj_id'],
'name': event['name'],
'goal': event['goal'],
'issue': event['issue'],
'description': event['description'],
'term': event['term'],
'term_unit': event['term_unit'],
'create_date': event['create_date'],
}
)
return response
def lambda_handler(event, context):
print(event)
return eval(event['method'])(event)
実装のポイント
- 下記のようにして、1つのLambda関数で、API Gatewayからのいろいろな呼び出しに対応する
- API Gatewayから渡されるパラメータはeventの中に入っている。
- eventの中のmethodパラメータに処理に応じた固定文字列を設定する
- Lambda側ではmethodパラメータの文字列に応じて、処理を呼び分ける
- 具体的には
eval(event['method'])(event)の部分。
- 具体的には
APIに新たなメソッドを追加する場合の変更手順
現状、prjの参照と登録しかないため、prjの更新処理を実装してみましょう。
DynamoDB
既存のテーブル・項目に対する変更はないので、作業無し
API Gateway
prjリソースに対するputメソッドを新規追加します。
後日追記予定。
Lambda
受け取ったprj情報で、既存のprj情報を上書き更新する処理を書き、保存する
後日追記予定
API Gatewayのデプロイ
すべて完了したらテストして、OKだったらデプロイする。
デプロイすると変更が公開されて、Flaskアプリから新しいメソッドを呼び出せるようになる。
後日追記予定
Flask側の対応
API呼び出し処理を追加する。
今回のやり方だと、同時にプロジェクトページを開いていた人が複数いて、
それぞれ更新した場合に、先に更新した人のデータが後の人に上書きされて消えてしまうことになる。
プロジェクト名やゴールなど、1つしか保持できない項目は後勝ちでいいが、
タイムラインのように複数の値を持てる項目では後の人が登録する際に、最新のDynamoDB状態を参照してマージする必要がある。
その辺を考慮したロジック実装を行う。
後日追記予定。