はじめに
機械学習モデルに入力するデータの移り変わりを検出する「データドリフト」について、実際にどのように検知できるのかアウトプットのイメージを確認したかったため、実行してみました。
さまざまなPythonライブラリがありますが、見た目が気に入ったEvidentlyを使ってみることに!
データドリフト検知のライブラリの比較10選
| ライブラリ名 | 特徴・用途 | GitHubスター数 | 最新更新日 |
|---|---|---|---|
| Evidently | データドリフト、ターゲットドリフト、モデルパフォーマンスを簡単に可視化。オープンソースで使いやすい。 | ⭐️ 5,200 | 2024年10月 |
| Alibi Detect | 機械学習モデルの異常検知とデータドリフト検知に特化。多様な手法をサポート。 | ⭐️ 2,200 | 2024年5月 |
| River | ストリーミング機械学習用のライブラリで、データドリフト検知機能を持つ。 | ⭐️ 5,000 | 2024年9月 |
| PyCaret | 機械学習のプロセスを簡素化するライブラリで、データドリフト検知機能も含まれる。 | ⭐️ 8,900 | 2024年8月 |
| Amazon SageMaker Model Monitor | AWS環境でのモデル監視とデータドリフト検知を行うためのツール。 | N/A | 継続的 |
| Azure ML Data Drift Detector | Azure環境でデータドリフトを監視するためのツール。 | N/A | 継続的 |
| Great Expectations | データ品質と期待値管理に特化したライブラリで、ドリフト検知機能も提供。 | ⭐️ 9,900 | 2024年10月 |
| Deequ | データ品質管理用のライブラリで、データドリフト検知機能がある。 | ⭐️ 3,300 | 2024年10月 |
| NannyML | 機械学習モデルのデータドリフトおよびモデルドリフトの詳細な分析を提供。簡単な設定と豊富な可視化ツールを備える。 | ⭐️ 1,900 | 2024年9月 |
| Deepchecks | モデルの検査とデータの検証を行うためのライブラリで、データドリフト検知機能も提供。多様なテストとレポート機能。 | ⭐️ 3,600 | 2024年2月 |
これらのライブラリは、それぞれ異なる特徴や用途を持ち、特定のニーズに応じて選択するのが良さそうです。例えば、Evidentlyは視覚的なレポート生成が得意であり、Alibi Detectは異常検知に特化していたりします。また、AWSやAzureなどのクラウドサービスに統合されたツールもあり、企業環境での利用は、実はこちらの方が進んでいたりも。
データドリフトは機械学習モデルのパフォーマンスに大きな影響を与えるため、これらのライブラリを活用して定期的に監視し、必要に応じてモデルの再学習や調整を行うことが重要。
色々ある中で、見た目が気に入ったEvidentlyを使ってみることに。
Evidentlyの概要
まずは公式ドキュメントを確認。 Evidentlyは、データとML駆動システムを評価、テスト、監視するのに役立つツールです。
データ監視
Evidentlyは、テキスト、表形式データ、埋め込みのデータ品質とデータドリフトを監視できます。オープンソースのPythonライブラリとEvidently Cloudプラットフォームの両方で利用可能です。
オープンソースのPythonライブラリ
- 20m+ダウンロードされており、データ、ML、LLM駆動システムを評価、テスト、監視するのに役立ちます。
Evidently Cloudプラットフォーム
- 高度な機能、コラボレーション、サポートを提供します。
機能とアーキテクチャ
Evidentlyは、実験から本番までのMLベースシステムの品質を評価および追跡するのに役立ちます。100以上の既製の評価ライブラリを提供し、モジュール式のアーキテクチャを持つため、複雑なインストールなしでアドホックチェックが可能です。
3つのインターフェース
- レポート: 視覚的なレポートで評価メトリックスの要約を確認し、テストスイートで条件付きチェックを実行し、モニタリングダッシュボードで結果を時系列でプロットできます。
- テストスイート: 計算されたメトリックスが定義された条件を満たすかどうかを検証します。各テストは合格または不合格の結果を返します。
- モニタリングダッシュボード: MLシステムのパフォーマンスを時系列で視覚化し、問題を検出するのに役立ちます。
データ品質の評価
Evidentlyは、表形式データ、テキストデータ、埋め込みデータの品質を評価できます。
- 表形式データの品質: 欠損値、重複、空の行または列、最小-最大範囲、新しいカテゴリ値、相関の変化など。
- テキスト記述子: テキストの長さ、語彙外の単語、特殊記号のシェア、正規表現のマッチ。
- データ分布ドリフト: モデル予測、数値およびカテゴリ型特徴、テキストデータ、または埋め込みの分布を比較するための統計テストと距離メトリック。
分類、回帰、ランキング、およびLLM出力の品質評価
- 分類品質: 予測精度、精度、再現率、ROC AUC、混同行列、クラス分離品質、分類バイアス。
- 回帰品質: MAE、ME、RMSE、誤差分布、誤差正規性、グループごとおよび特徴ごとの誤差バイアス。
- ランキングと推奨: NDCG、MAP、MRR、ヒット率、推奨の偶然性、新しさ、多様性、人気バイアス。
- LLM出力品質: 毒性、感情を検出し、検索関連性を評価するなど、外部モデルとLLMを使用したモデルベースのスコアリング。
以下に、Google Colab環境でEvidentlyを実行する手順をまとめました。
実際にEvidentlyを実行してみる
以下の手順に従って、Google Colabの環境でEvidentlyを利用してデータの安定性テストとデータドリフトのレポートを作成します。
1. パッケージのインストール
まず、Evidentlyのパッケージをインストールします。
!pip install evidently
2. ライブラリのインポート
次に、必要なライブラリをインポートします。
import pandas as pd
from sklearn import datasets
from evidently.test_suite import TestSuite
from evidently.test_preset import DataStabilityTestPreset
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
3. データセットの読み込み
sklearnのirisデータセットをデータフレームとして読み込みます。
# pandas DataFrameとしてデータを読み込み
iris_data = datasets.load_iris(as_frame=True)
iris_frame = iris_data.frame
4. データの安定性テスト
TestSuiteとDataStabilityTestPresetを使用して、データの安定性をテストします。
data_stability = TestSuite(tests=[
DataStabilityTestPreset(),
])
data_stability.run(current_data=iris_frame.iloc[:60], reference_data=iris_frame.iloc[60:], column_mapping=None)
data_stability
以下の様な結果が見れます。
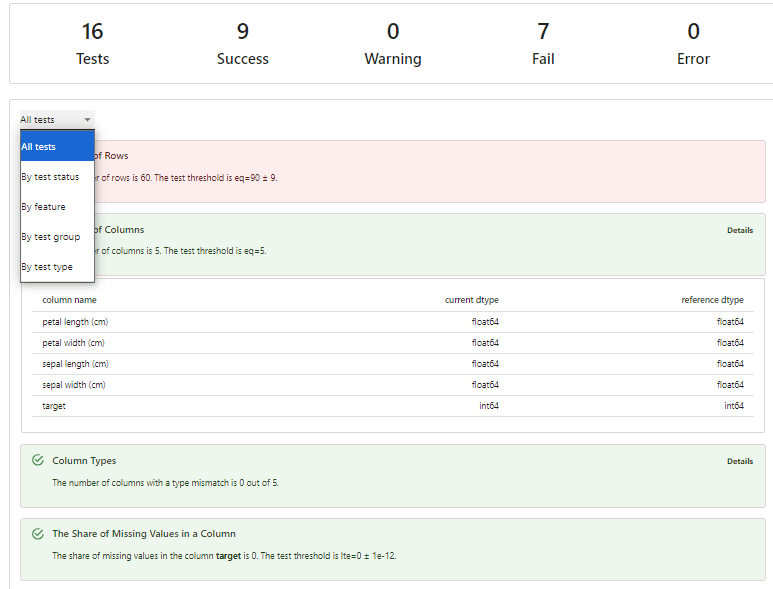
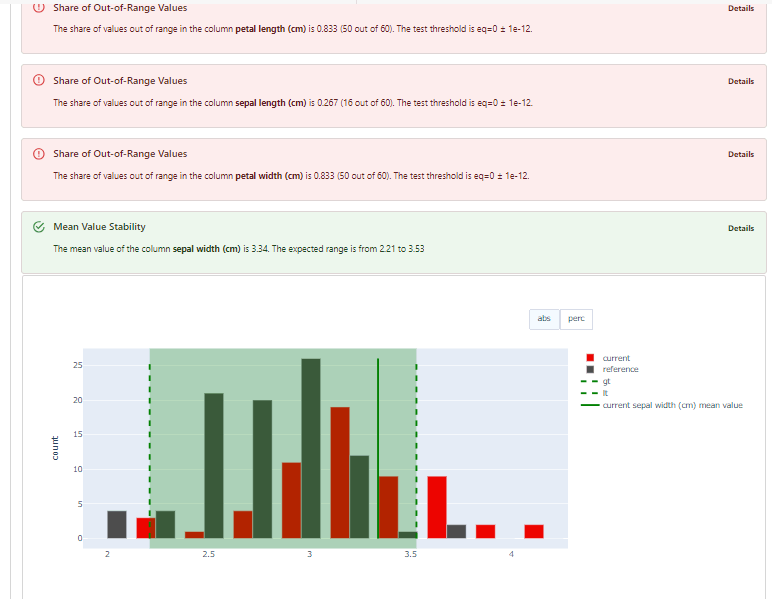
5. データドリフトのレポート作成
ReportとDataDriftPresetを使用して、データドリフトのレポートを作成します。
data_drift_report = Report(metrics=[
DataDriftPreset(),
])
data_drift_report.run(current_data=iris_frame.iloc[:60], reference_data=iris_frame.iloc[60:], column_mapping=None)
data_drift_report
以下のような結果が見れます。
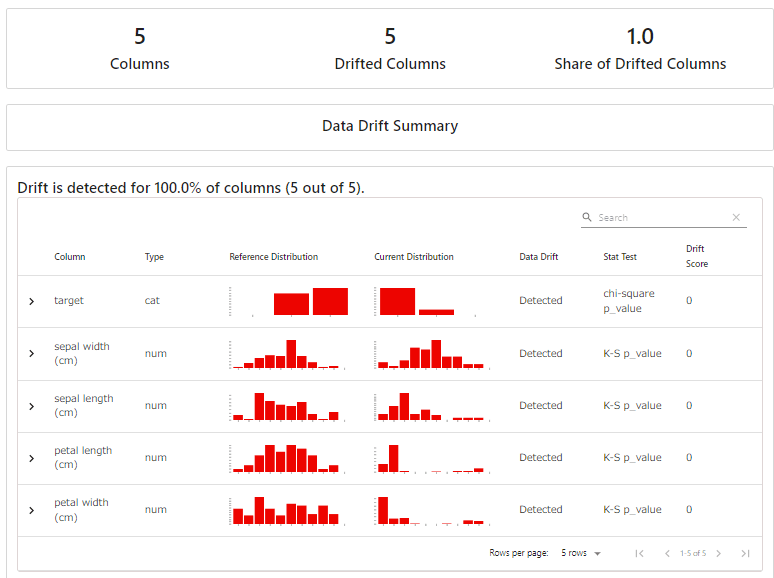
以上の手順で、Evidentlyを使用してデータの安定性テストとデータドリフトのレポートを作成することができました!
おわりに
実際にEvidentlyを使ってデータドリフトのレポートを作成してみたところ、非常にわかりやすいアウトプットを得ることができました。
他にもいろいろなライブラリがあるため、ユースケースに応じて適切な手法を選べるようになりたいと思います。