はじめに
モデルの学習を効率的に進めるために必要な、「パディング」 と 「ミニバッチ構築」 。
読み飛ばし気味だったため、一度立ち止まってメモを残します。
padding(パディング)とは?
パディングが必要な理由
機械学習モデル、特にディープラーニングモデルは、基本的に同じ形のデータがズラッと並んだものを入力として受け取ります。例えるなら、工場で大量生産するために、ベルトコンベアに乗せる部品の形が全て同じである必要があるようなイメージです。
しかし、私たちが扱うデータは、必ずしもいつも同じ形をしているとは限りません。
- 自然言語処理(NLP): 文章の長さはバラバラですよね。「今日は晴れです」という短い文もあれば、「先日、アニメを一気見しました。その中でも、シュタインズゲートは最高で...」のように長い文もあります。
- 音声データ: 音声の長さも様々です。短い単語の発話もあれば、長い会話の録音データもあります。
- 画像データ: 画像のサイズ(解像度)も、撮影するカメラや設定によって異なります。
- 時系列データ: 株価データやWebサイトのアクセス数など、データの長さが一定とは限りません。
これらのバラバラな形のデータを、そのままモデルに放り込んでも、うまく処理できません。そこで登場するのが 「padding(パディング)」 です。
パディングって何?
パディングとは、ミニバッチに含まれるデータたちの形状(主に長さやサイズ)を揃えるために行う処理のこと。具体的には、短いデータに対して、特定の値(通常はゼロや特別なトークン)を付け足して、長いデータと同じ長さに揃えます。
パディングの具体例を見て直感的に掴む
1. 自然言語処理(NLP)でのパディング
例えば、以下のようなトークン化された3つの文章があったとします。
["I love AI", "Deep learning", "Transformers are powerful"]
これをトークンIDに変換すると(架空のIDです):
[[1, 2, 3], # "I love AI"
[4, 5], # "Deep learning"
[6, 7, 8, 9]] # "Transformers are powerful"
このままでは、長さが揃っていませんね。
そこで、一番長い文章("Transformers are powerful"、長さ4)に合わせて、短い文章に 0 をパディングとして追加します。
[[1, 2, 3, 0],
[4, 5, 0, 0],
[6, 7, 8, 9]]
これで、全ての文章が長さ4に揃いました!
このようにパディングすることで、モデルはミニバッチ内の文章をまとめて効率的に処理できるようになります。
2. 時系列データでのパディング
時系列データでも考え方は同じです。長さが異なる時系列データを、一番長い系列に合わせてゼロ埋めします。
例えば、以下のような3つの時系列データがあったとします。
[[0.5, 0.6, 0.7],
[0.2, 0.3],
[0.9, 1.0, 1.1, 1.2]]
一番長い系列(長さ4)に合わせてパディングすると:
[[0.5, 0.6, 0.7, 0.0],
[0.2, 0.3, 0.0, 0.0],
[0.9, 1.0, 1.1, 1.2]]
これで、RNN(Recurrent Neural Network)やTransformerなどのモデルで、これらの時系列データをまとめて処理できるようになります。
3. 画像データでのパディング
画像データの場合は、サイズを揃えるためにパディングを行います。
例えば、以下の異なるサイズの画像があったとします。
(28, 28)(32, 32)(30, 30)
一番大きいサイズ (32, 32) に合わせて、小さい画像にゼロパディングを適用します。
-
(28, 28)→ 周囲にゼロを加えて(32, 32) -
(30, 30)→ 上下左右に1ピクセルずつゼロをパディングして(32, 32)
このようにすることで、異なるサイズの画像をまとめてミニバッチとして扱うことが可能になります。
パディングの種類
パディングには、いくつかの種類があります。
-
ゼロパディング (Zero Padding)
一番一般的なパディング方法です。足りない部分に 0 を埋めます。
先程の例で使ったのもゼロパディングですね。 -
特殊トークンパディング
主にNLPで使われます。[PAD]のような特別なトークンをパディングとして使用します。
モデルはこの[PAD]トークンを学習時に無視するように設計することが多いです。 -
リピートパディング (Repeat Padding)
時系列データなどで使われることがあります。データの最後の値を繰り返して埋めます。 -
マスキングパディング (Masking Padding)
Transformerモデルなどでよく使われます。
パディングした部分にマスクをかけ、モデルがパディング部分を無視するようにします。
パディングとマスキング
パディングは、ミニバッチ処理を行う上で欠かせないテクニックです。特に、長さやサイズの異なるデータを扱う場合には必須となります。そして、パディングを行う際には、マスキングも検討することが重要です。
特にTransformerモデルなどを使う場合は、マスキングを適切に行うことで、モデルの性能を最大限に引き出すことができます。ちなみに、Transformerでは、Self-Attentionの計算時にマスクを利用することで、パディング部分の情報が計算に影響を与えないようにしています。
ミニバッチ構築とは?
ミニバッチ構築が必要な理由
ディープラーニングモデルの学習は、大量のデータを使って行われます。
しかし、全てのデータを一度にモデルに入力して学習させる(バッチ学習) のは、計算資源的にも時間的にも非効率です。
そこで、訓練データを小さなグループに分割し、グループごとに学習を行う 「ミニバッチ学習」 が一般的に用いられます。効率的に訓練するために、ミニバッチに分割し、それをモデルに入力する処理がミニバッチ構築です。
なぜミニバッチ学習が良いの?3つの学習方法を比較
- バッチ学習: 全データを一括で学習し、モデルを更新する方法
- ミニバッチ学習: データを小さなバッチに分けて学習し、モデルを段階的に更新する方法
- オンライン学習: データを1つずつ(または極小バッチで)順次学習し、リアルタイムでモデルを更新する方法
| 学習方法 | メリット | デメリット |
|---|---|---|
| バッチ学習 | 勾配更新が安定、収束がスムーズ | メモリ消費が大きい、計算が重い、学習に時間がかかる |
| ミニバッチ学習 | 計算負荷とメモリ消費のバランスが良い、勾配に適度なノイズがあり最適化が早い | バッチサイズというハイパーパラメータの調整が必要 |
| オンライン学習 (逐次学習) | 学習をすぐに始められる、最新データを即時反映 | 勾配のノイズが大きく不安定、収束が遅い、局所最適解に陥りやすい |
このように、ミニバッチ学習は、計算効率 と 学習の安定性 のバランスが取れており、良いとこ取りな学習方法です。
ミニバッチ構築のステップ(データ準備からモデル入力まで)
ミニバッチ構築は、以下の手順で行います。
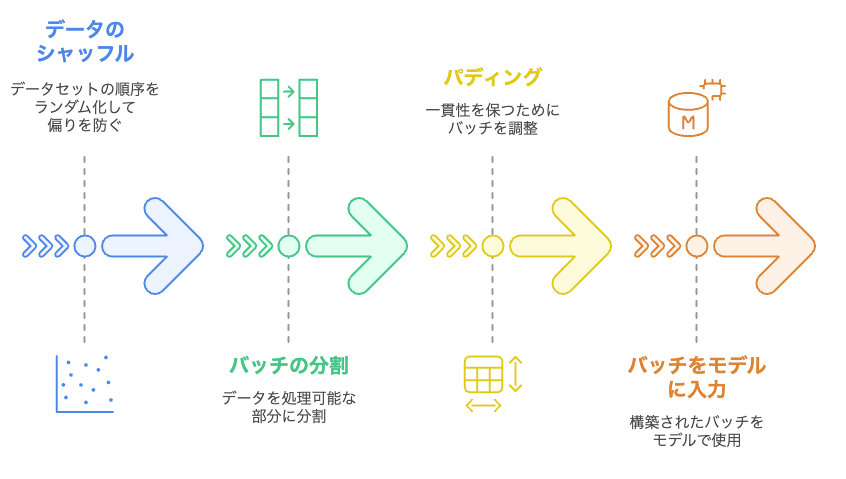
(1) データのシャッフル
- まず最初に、データをシャッフル します。
- データが特定の順番で並んでいると、学習が偏ってしまう可能性があるためです。
- 例えば、猫の画像ばかり学習した後に犬の画像ばかり学習すると、モデルが猫に特化してしまったり、犬の学習が遅れてしまうことがあります。
- データをシャッフルすることで、毎回異なるデータの組み合わせで学習できるようになり、学習の偏りを防ぎ、汎化性能を高めることができます。
(2) バッチの分割
- シャッフルされた訓練データを、バッチサイズ と呼ばれる一定のサイズに分割します。
- バッチサイズは、32, 64, 128, 256などがよく使われます。
- 例えば、データ数が1000個、バッチサイズを32とした場合、
1000 ÷ 32 = 31 あまり 8となり、31個のバッチと、端数として8個のデータが残ります。
- 例えば、データ数が1000個、バッチサイズを32とした場合、
この端数データ(最後のバッチ)の処理方法は主に3つあります。
-
ドロップ (Drop Last):端数のバッチを捨てる。
drop_last=Trueと設定することで実装できます。 -
パディング (Padding):端数のバッチにパディングを追加してバッチサイズを揃える
padding=Trueと設定することで実装できます。 -
使用 (そのまま):端数のバッチもそのまま学習に利用 する。
drop_last=Falseがデフォルト設定です。
(3) パディング(必要な場合)
NLPや時系列データなど、データによって長さが異なる場合は、ここでパディングを行い、バッチ内のデータの長さを統一します。
(4) バッチをモデルに入力
作成したミニバッチを順番にモデルに入力し、学習を行います。各ミニバッチごとに、以下の一連の流れを繰り返します。
- 順伝播 (Forward Pass):入力データから予測値を計算
- 損失関数計算:予測値と正解ラベルから損失(誤差)を計算
- 誤差逆伝播 (Backward Pass):損失に基づいてモデルのパラメータの勾配を計算
-
パラメータ更新:勾配に基づいてモデルのパラメータを更新

transformersライブラリでミニバッチ構築!DataCollatorWithPaddingを活用
Hugging Faceのtransformersライブラリを使うと、DataCollatorWithPaddingを利用してミニバッチ構築を簡単に行うことができます。
DataCollatorWithPaddingは、ミニバッチの構築、パディングの自動適用、トークナイザーに基づく動的パディングを自動で行ってくれる便利なツールです。
from transformers import AutoTokenizer, DataCollatorWithPadding
from torch.utils.data import DataLoader
# ① トークナイザーのロード
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# ② サンプルのテキストデータ
texts = [
"I love machine learning.",
"Transformers are powerful models.",
"Hugging Face provides great NLP tools."
]
# ③ テキストをトークナイズ(リスト形式)
tokenized_texts = [tokenizer(text, truncation=True) for text in texts]
# ④ DataCollatorWithPadding の準備(トークナイザーを渡す)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="pt")
# ⑤ DataLoader の作成(データ + コレータでバッチ化)
dataloader = DataLoader(tokenized_texts, batch_size=2, collate_fn=data_collator)
# ⑥ ミニバッチの取得と表示
for batch in dataloader:
print(batch)
break # 1バッチ目のみ表示
コードのポイント
-
tokenizerを用意(bert-base-uncasedなど)-
AutoTokenizer.from_pretrained()でトークナイザーをロードします。
-
-
tokenizer(text, truncation=True)でテキストをトークナイズ-
truncation=Trueにより長すぎるテキストを自動的にカットします。 - ここでは
paddingは指定せず、後のDataCollatorWithPaddingでパディング処理を行います。
-
-
DataCollatorWithPadding(tokenizer)を作成-
tokenizerを渡すことで、トークナイザーに基づいて自動でパディングを適用します。 -
return_tensors="pt"により PyTorch のテンソル形式で出力するように設定します。
-
-
DataLoaderにcollate_fn=data_collatorを設定-
DataLoader作成時に、collate_fn引数にDataCollatorWithPaddingオブジェクトを指定することで、バッチ作成時にDataCollatorWithPaddingが適用され、ミニバッチ内のデータ長が自動で統一されます。
-
出力例
{
'input_ids': tensor([[ 101, 1045, 2293, 3698, 4083, 102, 0, 0],
[ 101, 19081, 2024, 3928, 4275, 1012, 102, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0]])
}
出力例の解説
-
input_ids:-
[101, ... 102]は BERT の[CLS]トークンと[SEP]トークンのIDを表します。 -
0は パディングトークン を表します。短いシーケンスの後ろにパディングが追加されていることがわかります。
-
-
attention_mask:-
1は 実際のトークン を表します。 -
0は パディング部分 を表します。Attention機構でパディング部分を無視するために使用されます。
-
バッチサイズの選び方
バッチサイズは、モデルの学習に様々な影響を与える重要なハイパーパラメータです。
バッチサイズを大きくしたり小さくしたりすることで、学習の進み具合やモデルの性能が変わることがあります。
| バッチサイズ | メリット | デメリット |
|---|---|---|
| 小さい (例: 16, 32) | モデル更新頻度が多く、局所的な最適化に適応しやすい、少ないメモリで学習可能 | 計算効率が悪い、勾配のバラつきが大きく収束が遅い |
| 中くらい (例: 64, 128) | 安定した学習、メモリと計算効率のバランスが良い | 特に大きなデメリットはない |
| 大きい (例: 256, 512, 1024) | 計算効率が良い、並列処理しやすい、勾配が安定しやすい | メモリ消費が大きい、局所最適解に陥りやすい可能性、汎化性能が下がる可能性 |
バッチサイズの選び方の一般的なルール
- 小規模データセット: 32~128
- 大規模データセット (画像認識など): 256~1024
- GPUメモリに収まる範囲でできるだけ大きく
まずは色々なバッチサイズを試してみて、良い結果が得られるバッチサイズを探るのが良さそうです。
まとめ
パディングとミニバッチ構築はデータ準備の二本柱!
- パディング: 長さやサイズがバラバラなデータを揃えるテクニック
- ミニバッチ構築: 訓練データを効率的に学習させるためのテクニック
どちらも、機械学習モデルを効率的に学習させ、高い性能を引き出すためには欠かせない、データ準備 のための重要なテクニックです。
パッと聞かれた時の回答集は、
- padding(パディング)とは?データを揃えてミニバッチ処理をスムーズにする
- パディングが必要な理由は?データはいつも同じ形とは限らないから
- パディングって何?長さを揃えるもの
- ミニバッチ構築とは?効率的な学習の秘訣
- ミニバッチ構築が必要な理由は?効率と安定性を両立するため
- transformersライブラリでミニバッチ構築するのに何使う?DataCollatorWithPaddingを活用
- バッチサイズの選び方は?学習効率とメモリのバランスを考える