はじめに
初めまして,大学院でコンピュータサイエンスを専攻しているchanjagaです.
友人がPDFファイルのOCR化を必要としていたため,試しにPythonを使って実装してみました.
OCRとは,簡単に言うと画像データのテキスト部分を認識し,文字データに変換する機能のことです.
実行環境
今回はGoogle Colaboratoryを使ってPythonを実行します.
https://colab.research.google.com/?hl=ja
準備
Pythonを実行する前に以下をGoogle Colaboratoryで実行し,必要なパッケージをインストールします.
!apt-get install -qq tesseract-ocr
!apt-get install -qq libtesseract-dev
!apt-get install -qq poppler-utils
!apt-get install -qq tesseract-ocr-jpn
!pip install -q pytesseract
!pip install -q pdf2image
サンプルコード
以下は今回作成した,OCR化のサンプルコードです.
import pytesseract
from pdf2image import convert_from_path
from PIL import Image
# PDFファイルのパス
pdf_path = "日本語.pdf"
# PDFを画像に変換
images = convert_from_path(pdf_path)
text = ""
# 各ページの画像に対してOCRを実行
for image in images:
# 画像を一時的に保存してOCRを実行
image_path = "temp_image.jpg"
image.save(image_path)
# OCRを実行してテキストを取得
page_text = pytesseract.image_to_string(Image.open(image_path), lang='jpn') # 言語データに合わせて指定
# テキストを結合
text += page_text
# テキストを表示
print(text)
このコードは与えられたPDFファイルを画像データに変換してOCR化し,結果の文字データを表示するプログラムです.
上から10行目のpdf_pathにプログラムに与えるPDFファイルのパスを代入します.
pdf_path = "日本語.pdf"
また,このプログラムは日本語のテキストが書かれた画像データをOCR化対象としています.
テキストが日本語以外の場合
OCR化する画像データのテキストが日本語以外の場合,準備で挙げたprepare.txtの4行目末尾に記述されたjpn(言語コード)を変更し,パッケージを再インストールします.
言語コード:
https://tesseract-ocr.github.io/tessdoc/Data-Files-in-different-versions.html
!apt-get install -qq tesseract-ocr-eng
併せて,OCR.pyの下から7行目の変数langに代入する言語コードを変更します.
page_text = pytesseract.image_to_string(Image.open(image_path), lang='eng')
実行結果
プログラムに与えるPDFファイル↓
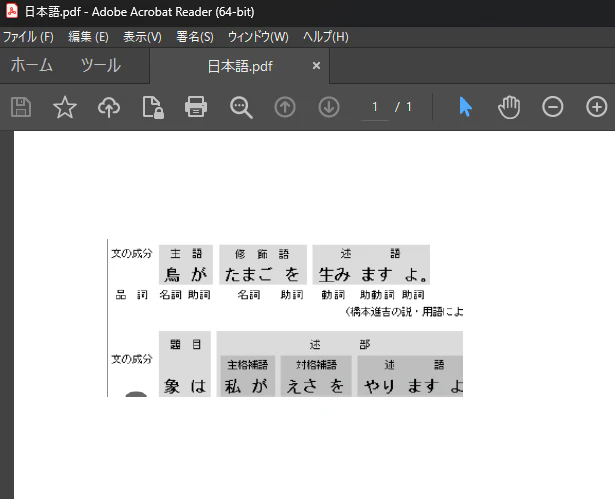
画像引用元:https://ja.wikipedia.org/wiki/%E6%97%A5%E6%9C%AC%E8%AA%9E
OCR実行結果↓

文字の大きさや配置が統一されていればもっと精度が上がるのかもしれません.
おわりに
今回は,PDFファイルを画像データに変換してOCR化するPythonプログラムを作成しました.今後もPythonや他の言語を使って遊んでみたいと思います.