はじめに
GCPの認定資格の一つであるProfessional Data Engineer取得を勉強中に「AI Platform」なるもの存在を知りました。
何が便利なのかを知りたいと思い、チュートリアルを一通りやってみた話です。
以前はCloud ML Engineというサービスだったのですが、一昨年か昨年あたりAI Platformに統合されたようです。
AI Platformとは?
大規模な機械学習モデルをトレーニングし、トレーニング済みモデルをクラウドでホストし、モデルを使用して新しいデータについて予測することが可能となる
公式ドキュメントによると機械学習ワークフローの多くをサポートしてくれるようです。下記の図はAI Platformがサポートする機械学習ワークフローを示しています。(公式ドキュメントからの抜粋です。

GCPにはAI系のサービスがいくつかあります。AutoML系サービスはコーディングしないで機械学習を使えるのが特徴です。データを準備して、学習の際にデータを指定してあげることでモデルを生成することができるといった感じです。

それに対し、AI Platformでは上記のMLワークフローみて分かる通り、データを準備した後に自分でコーディングする過程が入ります。自らコーディングすることでAutoMLに実装されていないモデル構築やモデルのチューニングが可能になります。

今回はこのAI Platformを使い方を学んでいこうと思います。
準備
インスタンスの立ち上げ
AI Platformを手軽に利用する機能として「AI Platform Notebooks」があります。この機能を利用するとComputeEngine上でJupyterLabが使える状態になります。
GCPコンソールの「AI Platform」を開きます。ノートブックに移動して新しいインスタンスをクリックすると、いくつかの環境が提示されます。
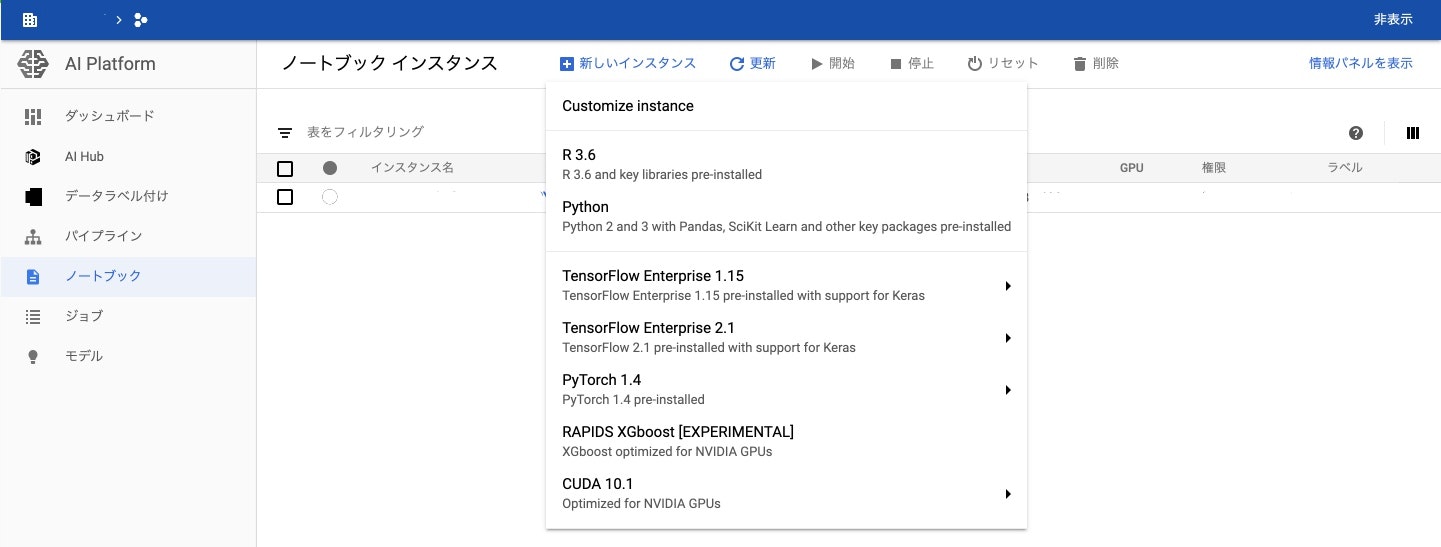
今回は「Customize instance」を選択します。その他の環境は記載されている内容があらかじめ用意されているのですが、リージョン・ゾーン・サブネットワークのみしか指定することできません。
「Customize instance」ではComputeEngineと同様の設定ができる他、DLフレームワークやGPUを選択することが可能になります。特にサービスアカウントを指定したいのでCustomizeでインスタンスを構築します。(ネットワークはパブリックインターネットに接続できる環境に立ち上げました。Firewallルールは22,8080が特定のIPから利用できるように設定しておきます。)インスタンスが立ち上がると同時にJupterLabが利用可能になります。
SSHトンネルの構築
インスタンスが立ち上がったら、ローカルのブラウザでJupyterLabにアクセスできるようにします。下記コマンドを実行します。
gcloud compute ssh --zone $ZONE $INSTANCE_NAME --project $PROJECT_NAME -- -L 8080:localhost:8080
gcloud comupute sshは指定インスタンスにSSHするコマンドです。これプラス-- -L 8080:localhost:8080を追加することでローカルホストへの命令を指定インスタンスに送るためのSSHトンネルを構築することができます。
http://localhost:8080/lab へブラウザからアクセスすると下記の画面が表示されます。
これでAI Platform Notebookのインスタンス(JupterLab)へのアクセスができました。
Cloud MLEngine チュートリアル
では、実際にAI Platformで何ができるかをチュートリアルをとおしてみていきたいと思います。
/tutorial/cloud-ml-engine/Training and prediction with scikit-learn.ipynbに開きます。これはscikit-learnの学習と予測をAI Platformの機能を利用して行うチュートリアルになります。
環境準備
まず、インスタンスが所属するプロジェクトのComputeEngineとMLのAPIが有効にします。
次にMLで扱うデータやモデルを格納するためのCloudStorageのバケットを作成します

チュートリアル用のディレクトリと__init__.pyも生成します。この__init__.pyはMLアプリケーションをAI Platformの学習機能を使用する時に使用します。

学習アプリケーションパッケージの作成
今回はcensus_trainingディレクトリの中に__init__.pyとtrain.pyに作成してアプリケーションパッケージとします。まずはコードの全体像が下記になります。
import argparse
import pickle
import pandas as pd
from google.cloud import storage
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectKBest
from sklearn.pipeline import FeatureUnion
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import LabelBinarizer
parser = argparse.ArgumentParser()
parser.add_argument("--bucket-name", help="The bucket name", required=True)
arguments, unknown = parser.parse_known_args()
bucket_name = arguments.bucket_name
COLUMNS = (
'age',
'workclass',
'fnlwgt',
'education',
'education-num',
'marital-status',
'occupation',
'relationship',
'race',
'sex',
'capital-gain',
'capital-loss',
'hours-per-week',
'native-country',
'income-level'
)
CATEGORICAL_COLUMNS = (
'workclass',
'education',
'marital-status',
'occupation',
'relationship',
'race',
'sex',
'native-country'
)
storage_client = storage.Client()
public_bucket = storage_client.bucket('cloud-samples-data')
blob = public_bucket.blob('ml-engine/sklearn/census_data/adult.data')
blob.download_to_filename('adult.data')
with open("./adult.data", "r") as train_data:
raw_training_data = pd.read_csv(train_data, header=None, names=COLUMNS)
for col in CATEGORICAL_COLUMNS:
raw_training_data[col] = raw_training_data[col].apply(lambda x: str(x).strip())
train_features = raw_training_data.drop("income-level", axis=1).values.tolist()
train_labels = (raw_training_data["income-level"] == " >50K").values.tolist()
categorical_pipelines = []
for i, col in enumerate(COLUMNS[:-1]):
if col in CATEGORICAL_COLUMNS:
scores = [0] * len(COLUMNS[:-1])
scores[i] = 1
skb = SelectKBest(k=1)
skb.scores_ = scores
lbn = LabelBinarizer()
r = skb.transform(train_features)
lbn.fit(r)
categorical_pipelines.append(
(
'categorical-{}'.format(i),
Pipeline([
('SKB-{}'.format(i), skb),
('LBN-{}'.format(i), lbn)])
)
)
skb = SelectKBest(k=6)
skb.scores_ = [1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0]
categorical_pipelines.append(("numerical", skb))
preprocess = FeatureUnion(categorical_pipelines)
classifier = RandomForestClassifier()
classifier.fit(preprocess.transform(train_features), train_labels)
pipeline = Pipeline([("union", preprocess), ("classifier", classifier)])
model_filename = "model.pkl"
with open(model_filename, "wb") as model_file:
pickle.dump(pipeline, model_file)
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(model_filename)
blob.upload_from_filename(model_filename)
引数受け取り
最終的にgcloudコマンドで学習を実行させます、その時にスクリプトに渡す引数をtrain.pyで定義します。ここではバケット名を必須の引数にします。
parser = argparse.ArgumentParser()
parser.add_argument("--bucket-name", help="The bucket name", required=True)
arguments, unknown = parser.parse_known_args()
bucket_name = arguments.bucket_name
学習データの準備
今回使う学習データはGoogleが公開しているCloudStorageに格納してあるデータを利用します。このデータは国税調査所得データセットらそしくある条件下で抽出された人物データが格納されています。
https://cloud.google.com/ml-engine/docs/scikit/training-scikit-learn?hl=ja#about-data
39, State-gov, 77516, Bachelors, 13, Never-married, Adm-clerical, Not-in-family, White, Male, 2174, 0, 40, United-States, <=50K
50, Self-emp-not-inc, 83311, Bachelors, 13, Married-civ-spouse, Exec-managerial, Husband, White, Male, 0, 0, 13, United-States, <=50K
google-cloudパッケージ内のCloudStorageを操作するモジュールをインポートしています。storage_clientによってCloudStorageに接続できる状態にします。
公開バケット名(cloud-samples-data)およびファイルパス(ml-engine/sklearn/census_data/adult.data)を指定してダウンロードします。
adult.dataのCATEGORICAL_COLUMNSは文字列が格納されているカラムです。しかし上記のデータを見てわかる通り、文字列の先頭に半角スペースが入っているのでこれをstrip()で削除しています。
最後の2行で学習データと正解ラベルのリストを作成しています。
from google.cloud import storage
import pandas as pd
storage_client = storage.Client()
public_bucket = storage_client.bucket('cloud-samples-data')
blob = public_bucket.blob('ml-engine/sklearn/census_data/adult.data')
blob.download_to_filename('adult.data')
with open("./adult.data", "r") as train_data:
raw_training_data = pd.read_csv(train_data, header=None, names=COLUMNS)
for col in CATEGORICAL_COLUMNS:
raw_training_data[col] = raw_training_data[col].apply(lambda x: str(x).strip())
train_features = raw_training_data.drop("income-level", axis=1).values.tolist()
train_labels = (raw_training_data["income-level"] == " >50K").values.tolist()
特徴量生成
用意した学習データを特徴量に変換します。各行が何やっているかの説明は割愛しますが、つまるところCATEGORICAL_COLUMNSをワンホットベクトルに変換しているようです。数値のカラムについては該当カラムを抽出するのみとなっています。categorical_pipelinesでデータ変換フロー定義し、FeatureUnionで定義したデータ変換フローを実行しています。
categorical_pipelines = []
for i, col in enumerate(COLUMNS[:-1]):
if col in CATEGORICAL_COLUMNS:
scores = [0] * len(COLUMNS[:-1])
scores[i] = 1
skb = SelectKBest(k=1)
skb.scores_ = scores
lbn = LabelBinarizer()
r = skb.transform(train_features)
lbn.fit(r)
categorical_pipelines.append(
(
'categorical-{}'.format(i),
Pipeline([
('SKB-{}'.format(i), skb),
('LBN-{}'.format(i), lbn)])
)
)
skb = SelectKBest(k=6)
skb.scores_ = [1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0]
categorical_pipelines.append(("numerical", skb))
preprocess = FeatureUnion(categorical_pipelines)
変換フローの簡易説明
最初のカテゴリカラムと数値カラムの変換フローを定義して実行したpreprocessが下記になります。
['0' '0' '0' '0' '0' '0' '0' '1' '0' '39' '77516' '13' '2174' '0' '40']
['0' '0' '0' '0' '0' '0' '1' '0' '0' '50' '83311' '13' '0' '0' '13']
上記の生データが下記になります。
# 最初のカテゴリカラムおよび数値カラムを抽出
39, State-gov, 77516, 13, 2174, 0, 40,
50, Self-emp-not-inc, 83311, 13, 0, 0, 13
最初のカテゴリカラムの全要素を抽出したものが下記になります。
['?' 'Federal-gov' 'Local-gov' 'Never-worked' 'Private' 'Self-emp-inc'
'Self-emp-not-inc' 'State-gov' 'Without-pay']
1行目の生データのカテゴリカラムの値はState-govであり、これは全要素中8番目の要素になっています。なので、変換後の特徴量ベクトルでは0と1で構成された値の中で8番目が1となっています。同様に2行目はSelf-emp-not-incであり、全要素中7番目の要素のため、変換後の特徴量ベクトルの0と1で構成された値の中で7番目が1になっています。こんな感じで全てのカテゴリカラムについて全要素を抽出して、該当要素を1にしているようです。
モデル生成
この部分はわかりやすく、ランダムフォレストのクラスをインスタンス化してclassifier.fit()で学習を実行しています。Pipeline()で特徴量と学習済みモデルをパイプラインで定義してmodel.pklというファイル名に出力しています。
これらを指定したCloudStorageバケットに格納しています。
classifier = RandomForestClassifier()
classifier.fit(preprocess.transform(train_features), train_labels)
pipeline = Pipeline([("union", preprocess), ("classifier", classifier)])
model_filename = "model.pkl"
with open(model_filename, "wb") as model_file:
pickle.dump(pipeline, model_file)
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(model_filename)
blob.upload_from_filename(model_filename)
学習ジョブの実行
学習ジョブ名を指定します。その後、実際に学習ジョブを送信するコマンドを実行します。
-
--job-dir:学習のアウトプットを格納するCloudStorageディレクトリパス -
--package-path:学習関連のスクリプトをパッケージ化したディレクトリパス -
--module-name:モジュール名(特に命名規則ないようです) -
--runtime-version:学習に必要なライブラリのバージョン(最新は1.14.0のようです)
- https://cloud.google.com/ml-engine/docs/runtime-version-list?hl=ja
-
--scale-tier:学習に使用するインスタンスタイプを指定できる
- BASIC, BASIC-GPU, BASIC-TPU, CUSTOM, PREMIUM-1, STANDARD-1
-
--stream-logs:Loggingに学習実行中がストリームで出力 -
--region:学習を実行するリージョン - 公式ドキュメントによると東京リージョンはAI-Platformの学習は対応していないようですが、チュートリアルのリージョンを
asia-northeast1に変更しても実行できました - https://cloud.google.com/ml-engine/docs/regions?hl=ja#%E3%82%A2%E3%82%B8%E3%82%A2%E5%A4%AA%E5%B9%B3%E6%B4%8B

実行が終わるとAI-Platformのジョブ画面に表示されます。
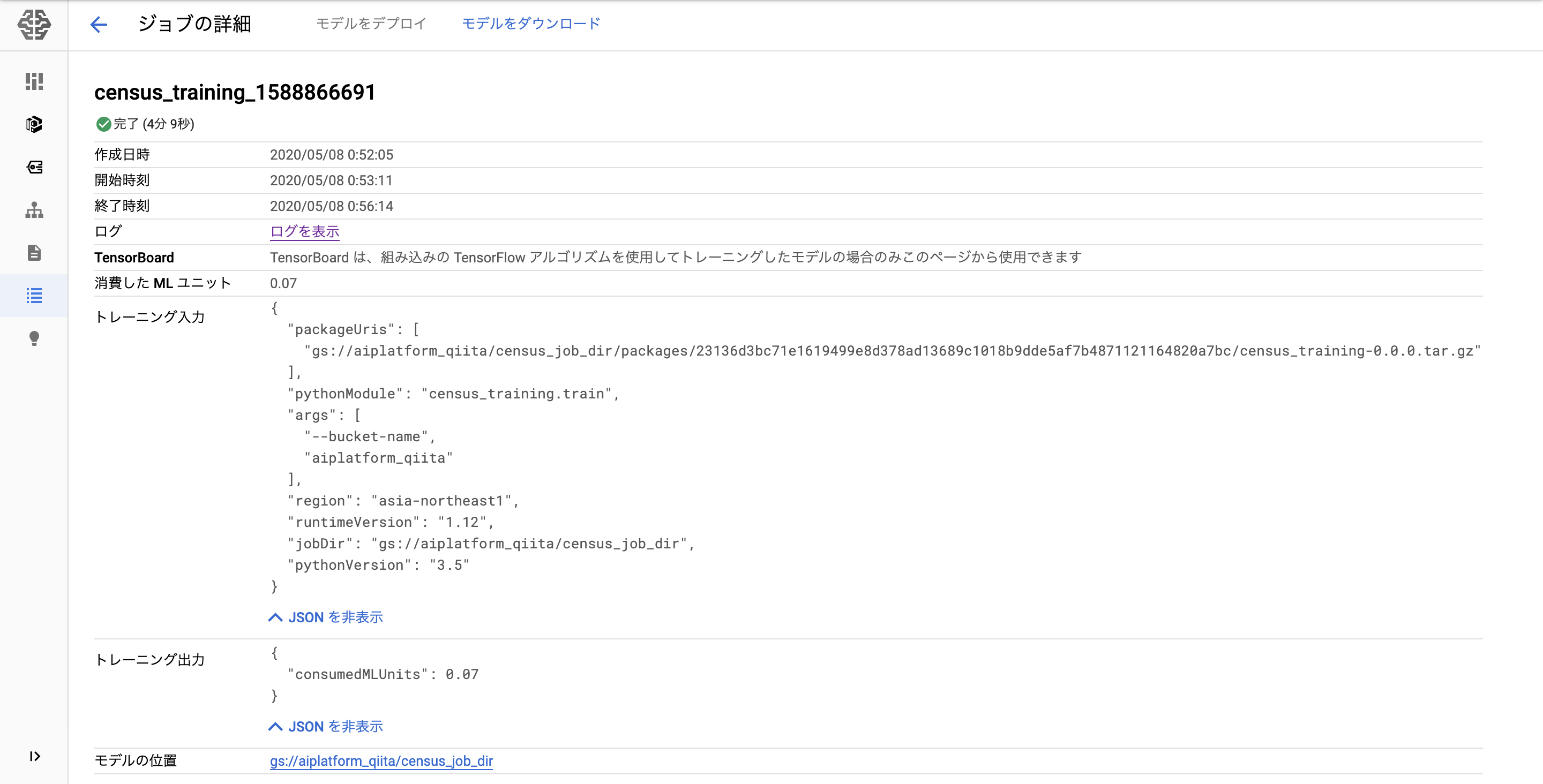
また、このチュートリアルではgcloud ml-engineコマンドを使っていますが、今はgcloud ai-platformコマンドが推奨されているようです。
モデル保存
この後、クラウド上でモデルをホストするために学習したモデルをAI-Platgorm上に保存します。
モデルという枠組み作って、そこにバージョンとしてモデルの実体を保存するイメージでしょうか。

バージョンの追加
試しに上記の[14][17]を再度実行すると、バージョンの追加ができていました。
学習データやパラメータを調整し、学習を行い、バージョン生成でモデルを格納するというサイクルが回せそうです。

予測モデルのクラウドホスト
いよいよ生成したモデルをクラウド上でホストして予測します。その前の準備として入力データを用意します。

ここで勘違いが発覚。自分のイメージでは生成したモデルをサーバーでホストしてAPIチックに予測結果を得られるかと思ったら、モデルを保存した時点でサーバーレスのAPIとしての準備ができているようです。
ひとまず用意されたセルを実行してみるとエラーがでました。引数の渡した方が変わっているようなので注意してください。

この実行結果が下記になります。ここでは年間の収入が$50,000以上だと予測された場合にはTrueがそうでない場合はFalseが出力されます。入力データが10件だったので、10個の出力得られます。

また、--versionを指定しないと上記のモデル一覧の(デフォルト)と書かれているモデルが採用されます。これを特定のバージョンを指定する場合は、下記コマンドを実行します。

以上がAI Platformを利用したMLワークフローでした。
終わりに
AI Platform気になってはいたけど、実際に触ってみるまで何をやってくれるリソースかわかりませんでしたが、チュートリアルを一通りやったことでなんとなくですが使い方がわかりました。
分散環境でトレーニングが可能な点やモデルを保存するだけですぐにオンラインで結果を得られる点は魅力的だと感じました。しかし、分散環境で学習させるための学習タスクのパッケージ化が慣れるまで難しいそうだとも思いました。特にPipelineを使ったデータ処理やモデル生成ワークフローの統合など。
また、JupyterLabを使った開発環境がすぐに作れるのは便利でした。CloudDatalabも似たようなサービスなので差異がどこにあるかはちょっと調べてみたいですね。
次はTensorflowのAI Platform環境を利用したデータ準備・データ加工・学習・予測をさわってみたいと思います!
参考
Google AI Platform - Cloud ML Engineを初心者が動かして理解(前半)
Google AI Platform - Cloud ML Engineを初心者が動かして理解(後編)