はじめに
研究でデータサイエンスやってるけど、研究室にデータ分析基盤的なのがない。
計算用のサーバーがいくつかあるからクラスタ組んで分散処理してみたいと思い、sparkをいじってみる。
pythonをいつも使っているからsparkのAPIをpythonで動かせるpysparkに挑戦。
体系的にまとまってる記事がないからいくつかに分けて書いてみる。
あと、物理マシンでクラスタ組む点もかなり試行錯誤したから書き残しておきたい。
ゴール
とりあえず、分散処理をさせることを目的とする。
1. pysparkを動かす
2. クラスタを組む
3. standaloneモードで分散処理をする
4. jupyter notebookでpysparkする
ゴール① pysparkを動かす
まず、一番重要なpysparkを動かせるようにする。
これは色々記事があるから楽勝。
環境
今後、分散環境にしたときmasterとして機能させる。windows上のVMで動かす。
* OS:Windows
* VertualMachineOS:Ubuntu
* python:3.6.0
* pyenv:1.1.5
* spark:2.2.0
* private netoworkに接続されていることが前提
手順
jdkのインストール
$ sudo apt-get install -y openjdk-8-jdk
sparkのインストール
spark2.2.0のhadoopのバージョンは2.7なので以下のURLでwget。
解凍したフォルダを/usr/local/にsparkという名前で移動する。
このフォルダ移動はのちのちクラスタ組んだ時にクラスタ側とディレクトリ構成が一致している必要があるため、重要。
$ wget http://ftp.riken.jp/net/apache/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
$ tar zxvf spark-2.2.0-bin-hadoop2.7.tgz
$ sudo mv spark-2.2.0-bin-hadoop2.7 /usr/local/
$ sudo ln -s /usr/local/spark-2.2.0-bin-hadoop2.7 /usr/local/spark
パスを通す。以下を.bashrcに記載してsource。
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
pysparkの起動
pysparkが$SPARK_HOME/binの直下にあるため、
$ pyspark
で起動できればおっけい。
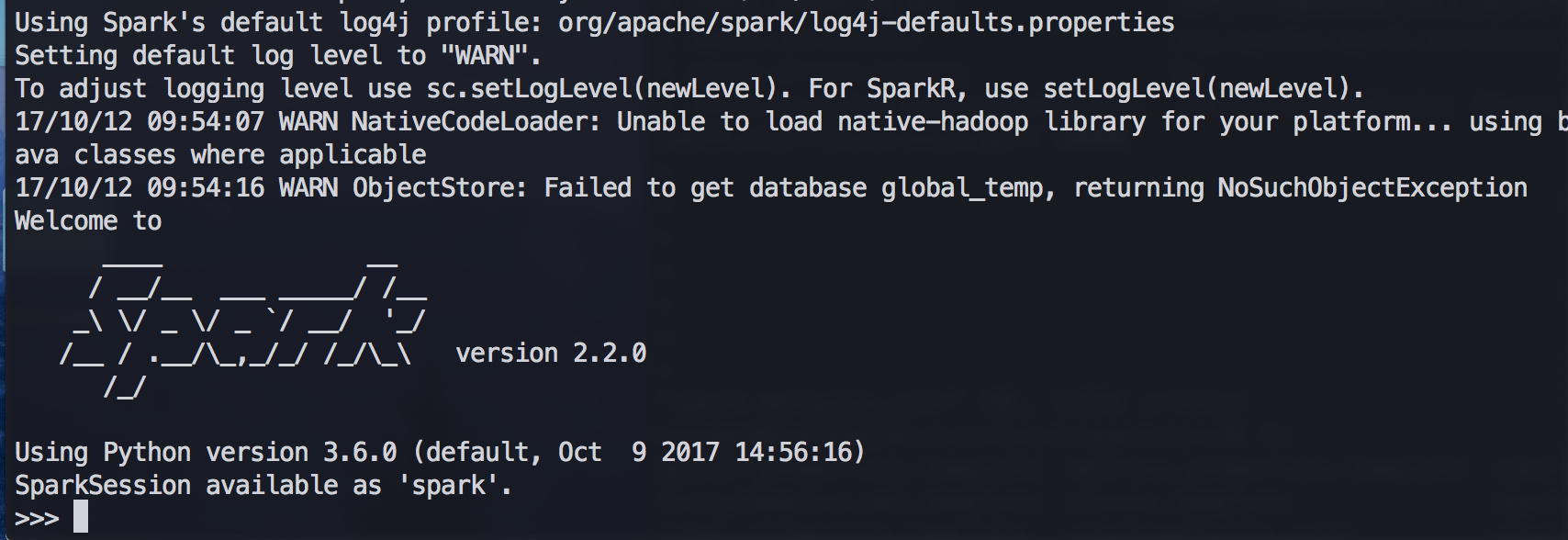
sparkではSparkContextというドライバプログラムがsparkにアクセスするためのオブジェクトが提供されている。インタラクティブシェルで操作する場合、自動的に生成される。
そのため、上記のコマンドでpysparkを起動して、
>>> sc
でエラーがでなければちゃんと起動できている。
pythonバージョン
もしかすると、起動したpysparkで使用されているpythonのバージョンが2系の場合がある。
これはシステムのデフォルトのpythonでpysparkが起動してしまうからである。
クラスタを組む場合、pythonのバージョンが一致している必要があるため、python3.6でpysparkを起動しなくてはならない。
自分はpyenvで3.6をインストールしてpysparkで使われるpythonのバージョンを変更した。
このサイトがわかりやすい。
UbuntuでPythonの開発環境を整える
ゴール② クラスタを組む
環境
クラスタの中で作業するノードをslave(worker)と呼ぶ。
dockerで環境導入するため、OSなどはdockerが使えれば良い。
master同様、private networkに接続されていることが前提。
一応、自分が作った環境は以下。
- OS:Ubuntu
- core:12
- memory:64G
docker:1.12.6
-
spark-master0(masterノード)
- ip:192.100.0.1
spark-slave1(slaveノード)
spark-slave2(slaveノード)
sparkの環境導入
物理マシンでクラスタを組むときに、OSがバラバラだったので手っ取り早く同じ環境を作りたいと思いdockerを使う。
dockerhubからこのイメージをもってくる。
jupyter/pyspark-notebook
これには、python3.6使えるようになっていてsparkも動かせるようになっている。
$ docker pull jupyter/pyspark-notebook
これで、イメージができて以下のコマンドでrunする。
$ docker run -d --name spark-slave1 --user root --net=host jupyter/pyspark-notebook
オプションの説明
* --name spark-slave1
コンテナに名前をつける。
今回は2つのslaveノードを生成するため、spark-slave1,spark-slave2と名付けた。
* --user root
ログインするユーザーを指定する、このユーザーでないとsudo権限がないためややこしい。
* --net=host
これがとても重要。sparkでクラスタを組んで分散処理させると、いくつかの処理でランダムにポートを開放させて行う。そのため-pによるポートフォワーディングでは対応できない。これによって、コンテナのネットワークはhostと同じになる。そのため、hostのIPアドレスでポートが使えるようになる。
クラスタを構成する
今回、上のやり方で2台の物理マシンにそれぞれslaveノードを生成した。
クラスタの組み方は手動と自動の2通りがあるが、今回は手動で行う。
まず、その①で生成したmasterノードでstart-master.shを実行する。
sudo /usr/local/spark/sbin/start-master.sh
これで以下の7077番ポートでmasterとして起動できる。
そしてmasterで起動すると、8080番ポートで管理画面を見ることできる。
http://$(master_node_IP):8080
次に、slaveノードとして動かすコンテナにログインしてstart-slave.shを実行する。
$ sudo /usr/local/spark/sbin/start-slave.sh spark://192.100.0.1:7077
spark://192.100.0.1はmasterのIPアドレス。
slaveがちゃんと起動できるとmasterの管理画面でクラスタに参加するのが確認できる。
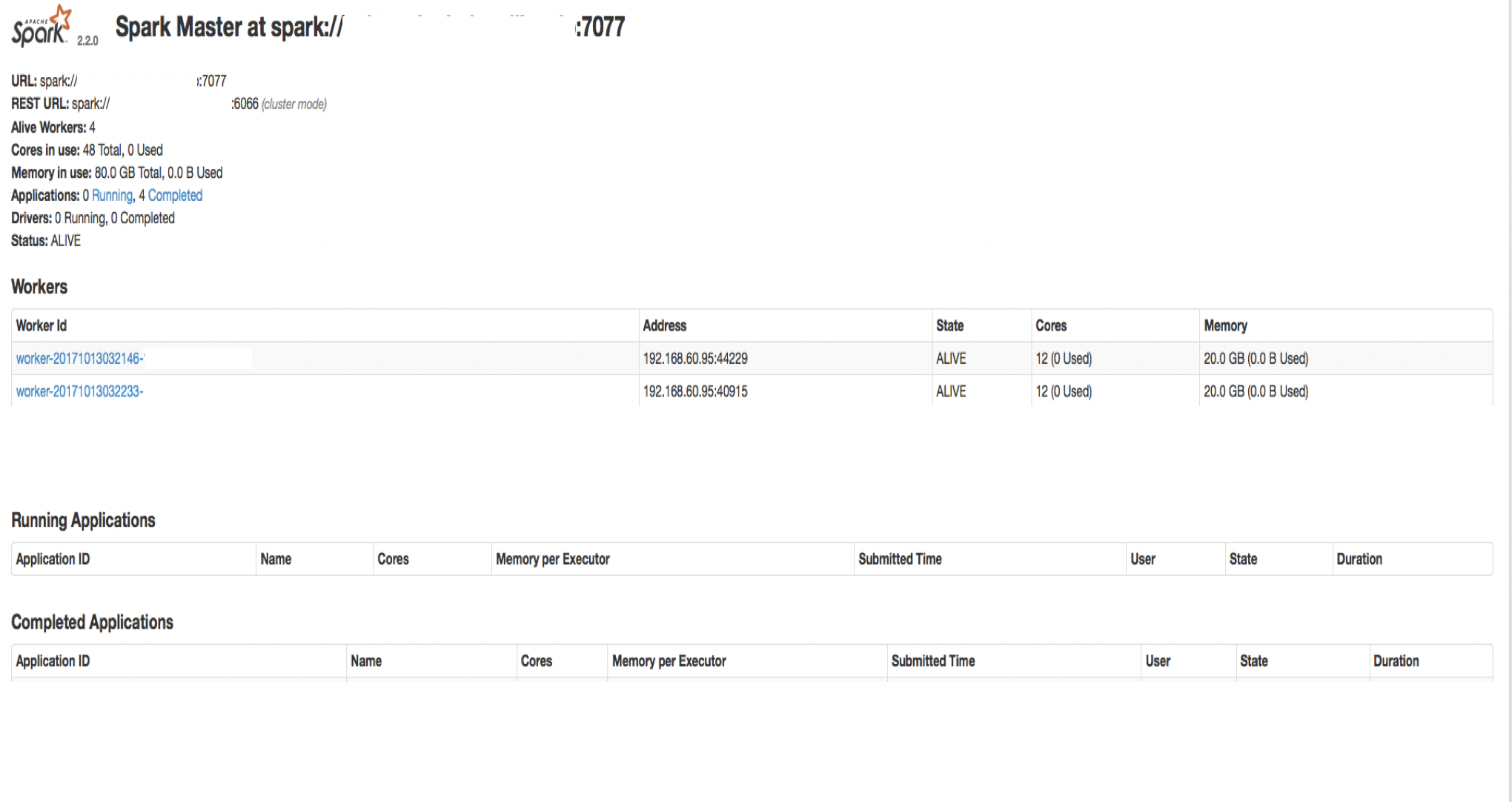
デフォルトだとslaveのcore数はマシンの最大数で、Memoryは1024mだった気がする。
slaveもmasterと同様に作業管理画面を8081番ポートでみれる。
http://$(slave_node_IP):8081
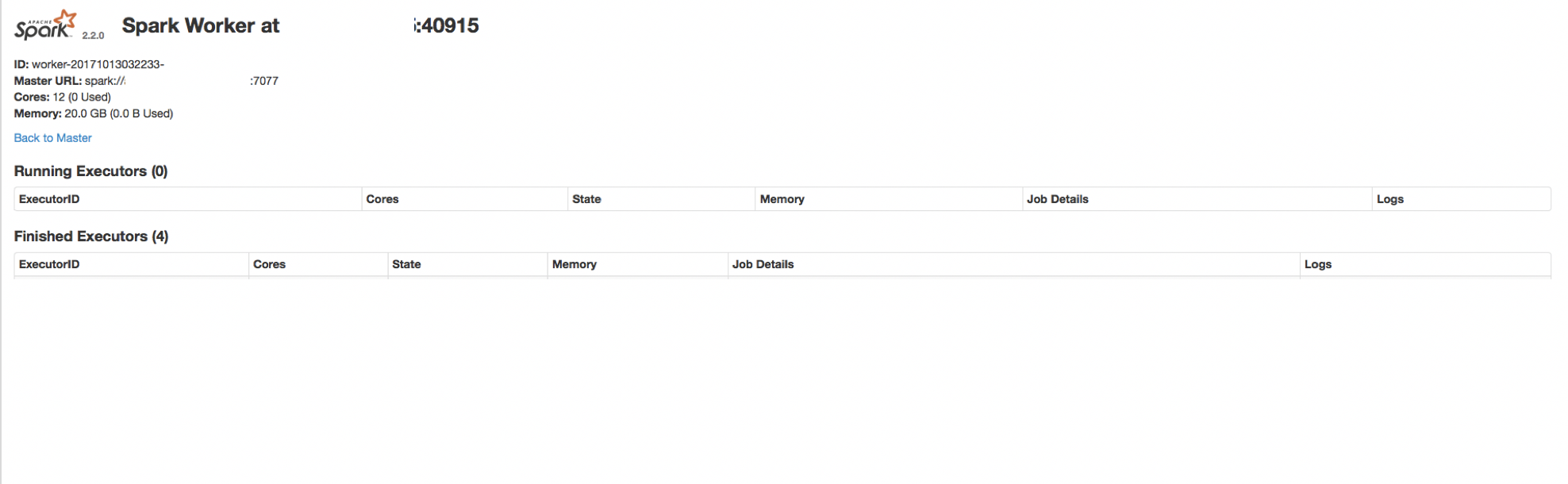
ちなみに40915というのはslaveノードの作業ポート。
slaveを起動するたびにランダムに開放される。
ゴール③ 分散処理を行う
とは言っても、もう特にすることはない。
standaloneモードで起動
http://$(master_node_IP):8080でmasterが起動できていて、http://(slave_node_IP):8081でslaveが起動できていて、masterの管理画面にslaveがクラスタに参加している状態で以下のコマンドをたたく。
$ /usr/local/spark/bin/pyspark --master spark://(master_node_IP):7077 --packages org.apache.hadoop:hadoop-aws:2.7.0
- --master
masterのIPを指定。 - --packages
hasoopのバージョンを指定したパッケージを指定。
それで、こんなlogが出れば成功。
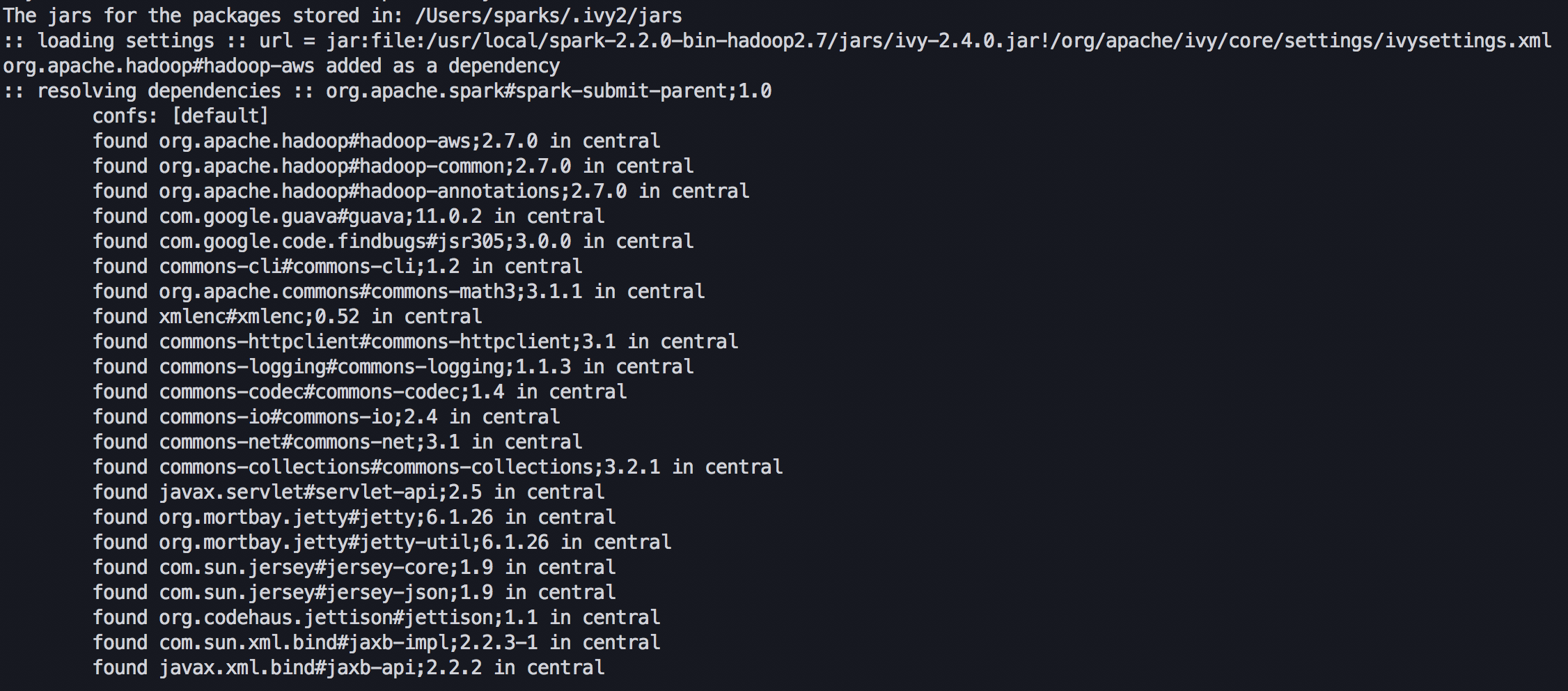
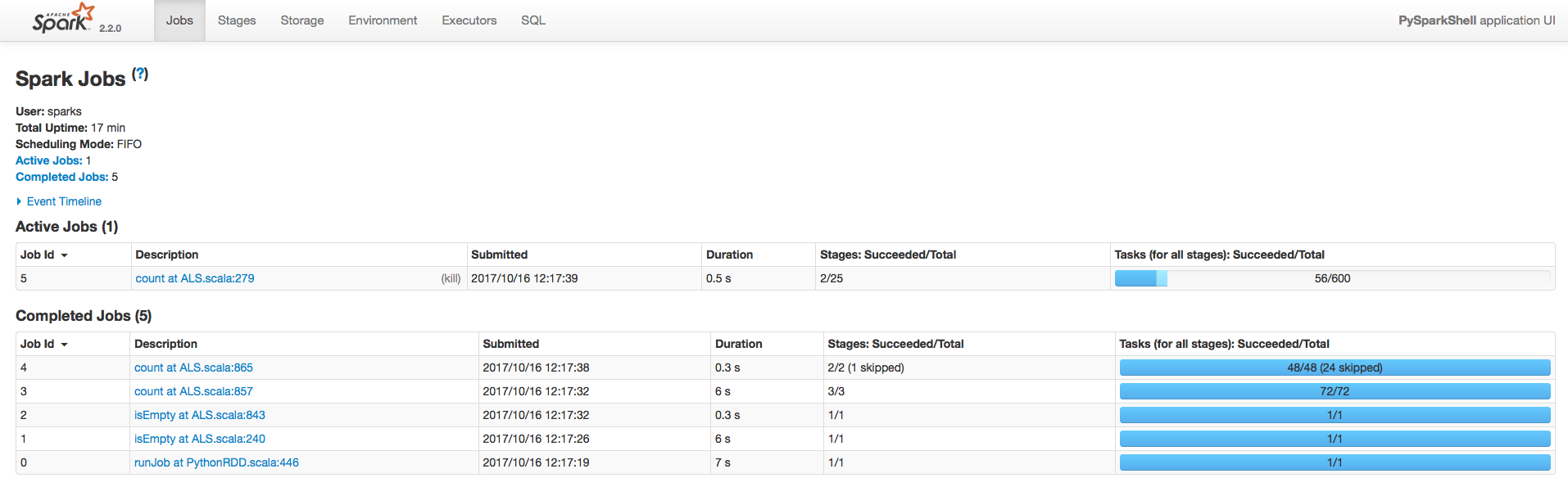
これでstandaloneモードでpysparkを起動できて、http://$(master_node_IP):4040でsparkのプロセス管理画面が観れる。

ちなみに上のタグは、
- Jobs:1実行プロセスの進行具合を表示
- Stages:Jobsが複数のstageで構成されている場合、1stageの進行具合を表示
- Storages:pysparkでRDDを永続化したときに対象データがどれだけキャッシュされているかを表示
- Enviroment:pysparkの環境情報
アプリケーションの実行
上のコマンドを実行すると、http://$(master_node_IP):8080の管理画面にアプリケーションが登録される。
登録されたアプリケーションでpysparkのactionを実行すると、http://$(master_node_IP):4040にプロセスの進行具合が表示される。
pysparkAPIの使い方はこれにまとまっている。
Spark API チートシート
slaveがちゃんと動作してるのを確認するには、http://$(slave_node_IP):8081でRunning Executerのlogsのstderrでエラーがでないでlogが表示されているかをみればいい。
ゴール④ jupyterでpysparkを実行する
インタラクティブシェルでpysparkを扱うには少し面倒だから、jupyterで操作できるようにする。
jupyter入ってない場合は、pipなりanacondaなりでインストールする。
configファイルは初期状態だとtemplateしかないため、cpでspar-env.shを生成する。
$ cp /usr/local/spark/conf/spark-env.sh.template /usr/local/spark/conf/spark-env.sh
spark-env.shに以下を書き込む。
export PYSPARK_DRIVER_PYTHON=/$(jupyter_path)/jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
これを書き込むと、
$ /usr/local/spark/bin/pyspark --master spark://(master_node_IP):7077 --packages org.apache.hadoop:hadoop-aws:2.7.0
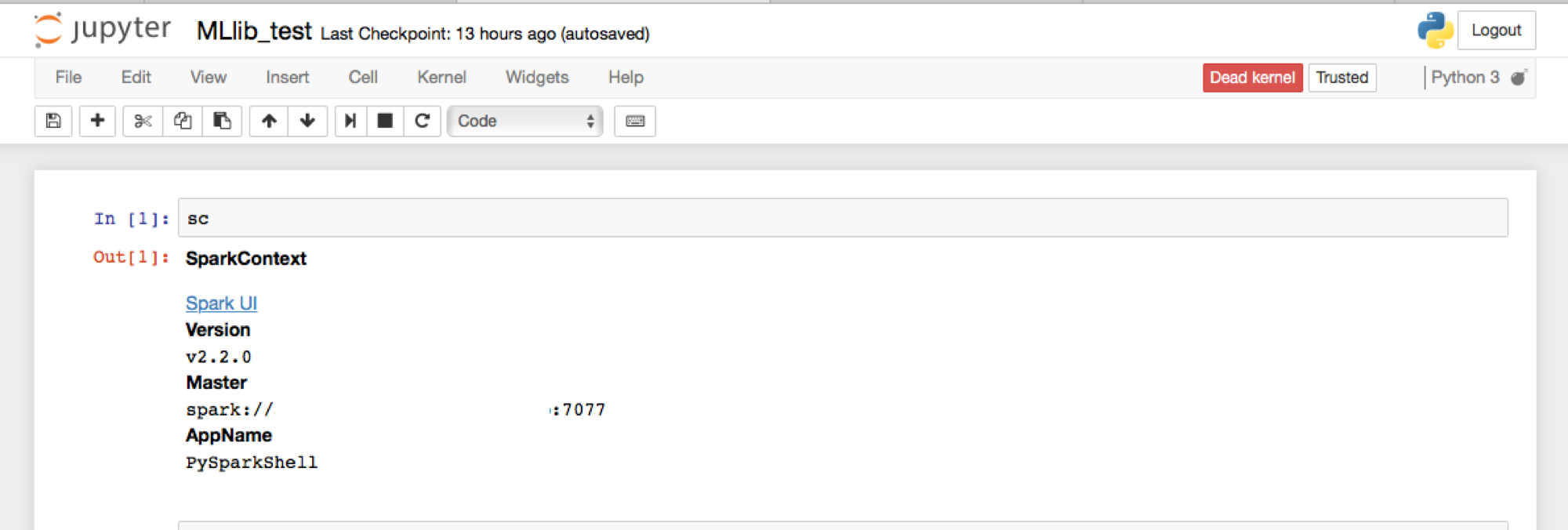
で起動した時に、jupyterで起動するようになる。scと打って、SparkContext情報が出力されればsparkAPIがつかえる。
おわりに
以上でpysparkをjupyterで動かして、分散処理を実行させることが実現できた。
とりあえず、動かせるがsparkはチューニングが大事になってくる。
重めの処理を何度も試して、slaveでエラーが出ていないかやプロセスの途中でtaskが失敗していないなか、してるならconfigファイルで値を調整して、、、などの試行錯誤が必要だと思う。
少しでもsparkの環境作りの参考になれば嬉しい。