別のデータセットを適用してみる
前回の記事でSegmentation Models on Pytorchのサンプルコードを動かしてみました.
このモデルをほかの問題に適用するにあたり,データセットについて把握してみたくなったので,日本放射線技術学会 画像部会が提供しているデータセットMINIJSRT_DATABASEを入力データとして試してみました.
MINIJSRT_DATABASE
このデータセットは,医療用画像に関する深層学習の研究用に用意されたものであり,レントゲン写真とそれを臓器別にラベル化したいくつかの例について提供されています.
ここではその中のsegmentation02,胸部X線画像の肺野領域抽出データを用いてみます.
このデータは,肺のX線画像に対して肺野領域:255,心臓:85,肺野外:170,体外:0とした255画素値によってラベル化されており,学習用のデータ199枚と評価用の画像48枚で構成されています.
画像ファイル名は,現画像がcase001.bmp,それに相当するラベル画像がcase001_label.pngとなっており,すべての画像サイズは256×256になっています.
ここでは,学習用データ199枚を訓練データ150枚,検証データ49枚と分割してモデルを学習させ,評価用の48枚で評価する,というようなことをしてみます.
画像の前処理
まず,現画像をorg_,ラベル化画像をlabel_,また訓練,検証,評価用データにそれぞれtrain, val, testという名前を付けてフォルダを構成し,画像を保存しておきます.
また,前回使用したコードにおいては,元画像とラベル画像のファイル名は一緒になっている必要があります(dataset関数を変えればなんとかなるのか??).加えて,ラベル値についても,0, 1, 2という番号になっているので,これに沿うようにラベル化画像を以下のように前処理することにしました.
def preconvert(y_train,y_train2):
filelist = sorted(glob(y_train+'/*.png'))
for file in filelist:
mask = cv2.imread(file)
mask[mask==255] = 1 # 肺野領域 lung
mask[mask==85] = 2 # 心臓 heart
mask[mask==170] = 3 # 体 body
t1 = file.split('\\')[-1]
t2 = t1.split('_')[0]
fname = t2+'.bmp'
cv2.imwrite(y_train2+'/'+fname, mask)
前処理したファイルは,例えば訓練ラベル画像であればlabel_train2というフォルダに保存します.
これに合わせてデータセット内のラベル名を0:outside,1:lung,2:heart,3:bodyと対応するように以下のように変更します.
CLASSES = ['outside', 'lung', 'heart', 'body']
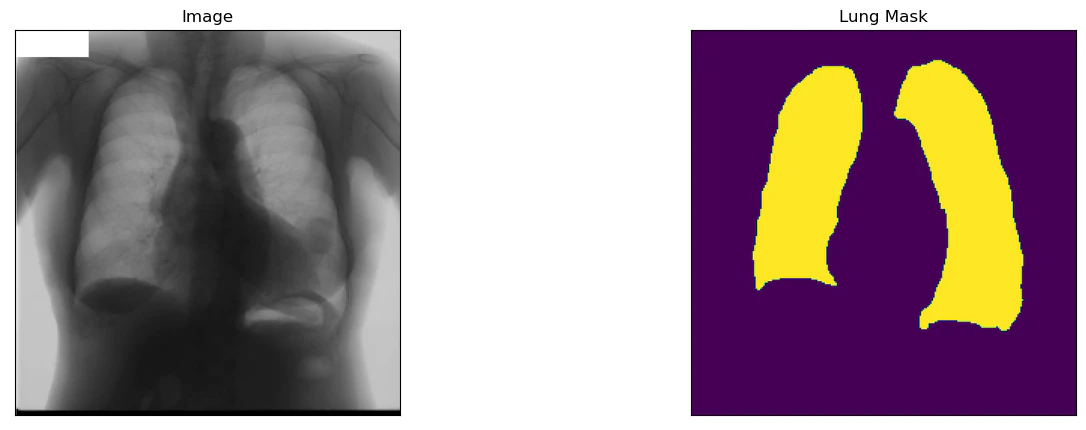
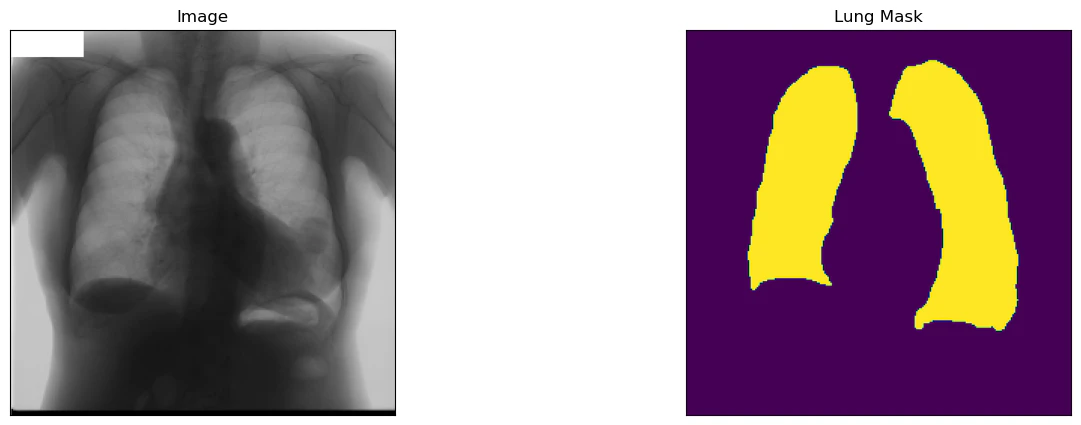
解析対象のラベルを肺(lung)に指定すると以下のような画像が確認できます.
画像サイズの指定
get_training_augmentation内にあるheightやwidthといった値を256に設定しておきます.
他のデータも試したところ,結局,heightとwidth,どちらが画像の縦横に対応しているのかいまいちわからない..ここがおかしいと結果のところの画像がおかしくなるので注意.
データ拡張
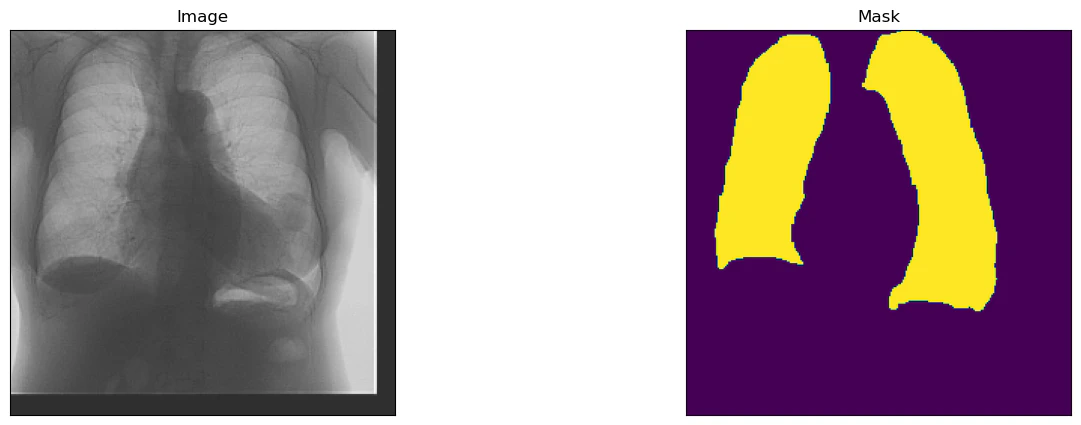
albumentationで動的に拡張される画像は以下のような感じ.



モデルの学習と結果
モデルやエンコーダとして以下を指定してみます.
model = DeeplabV3+
Encoder = efficientnet-b0
Encoder_weight = imagenet
ENCODER = "efficientnet-b0"
ENCODER_WEIGHTS = 'imagenet'
CLASSES = ['lung']
ACTIVATION = 'sigmoid' # could be None for logits or 'softmax2d' for multiclass segmentation
DEVICE = 'cuda'
#DEVICE = 'cpu'
# create segmentation model with pretrained encoder
model = smp.DeepLabV3Plus(
encoder_name=ENCODER,
encoder_weights=ENCODER_WEIGHTS,
classes=len(CLASSES),
activation=ACTIVATION,
)
preprocessing_fn = smp.encoders.get_preprocessing_fn(ENCODER, ENCODER_WEIGHTS)
epoch数を40として学習させてみます.20回ほどでIoU値がだいたい0.9あたりに収束していく感じになりました.
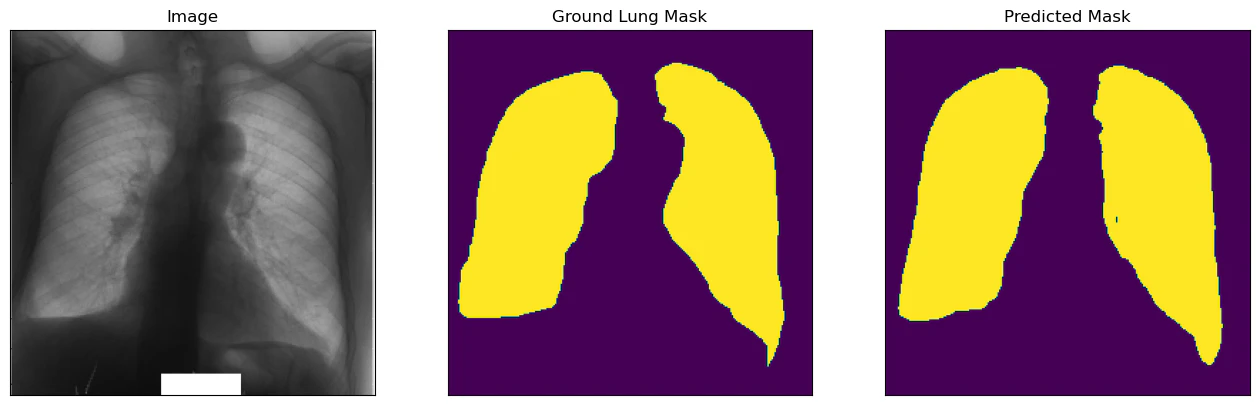
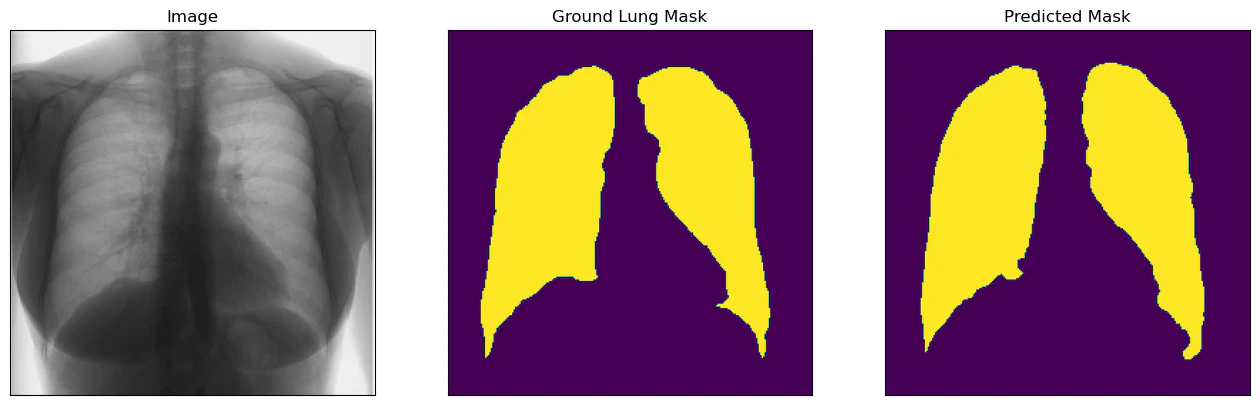
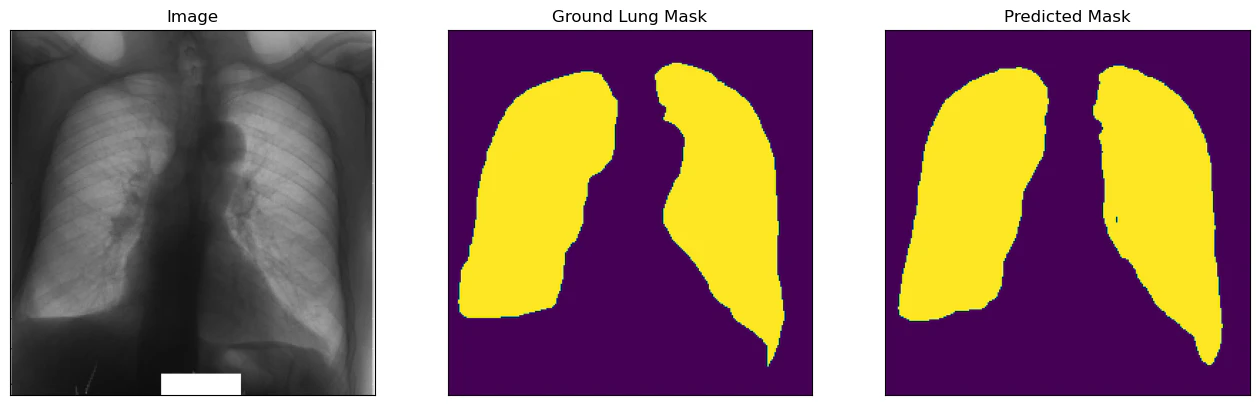
ベストモデルを評価用データに適用すると,IoUが0.915程度となり,よく予測できている結果となっています.下記,得られた画像ですが,多少の違いはありますが,おおよその形や場所はとらえられていると思います.

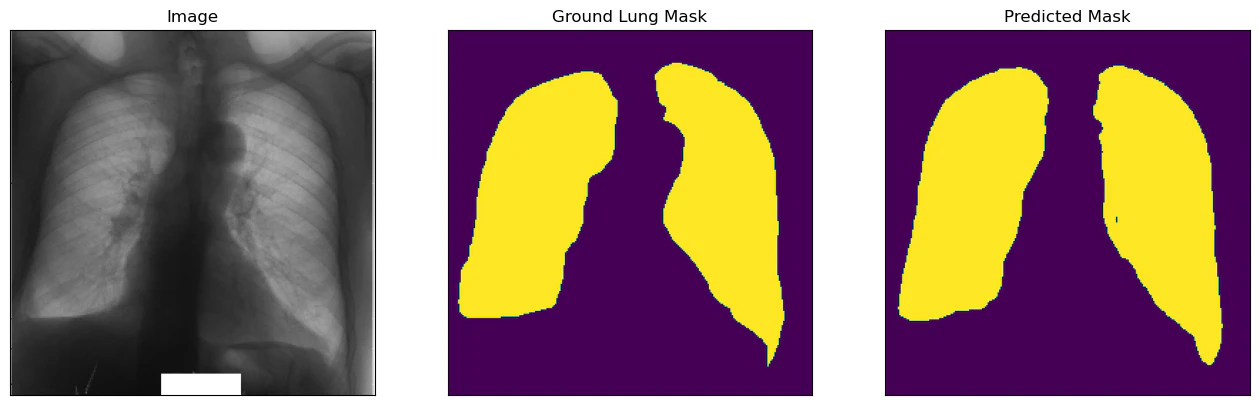
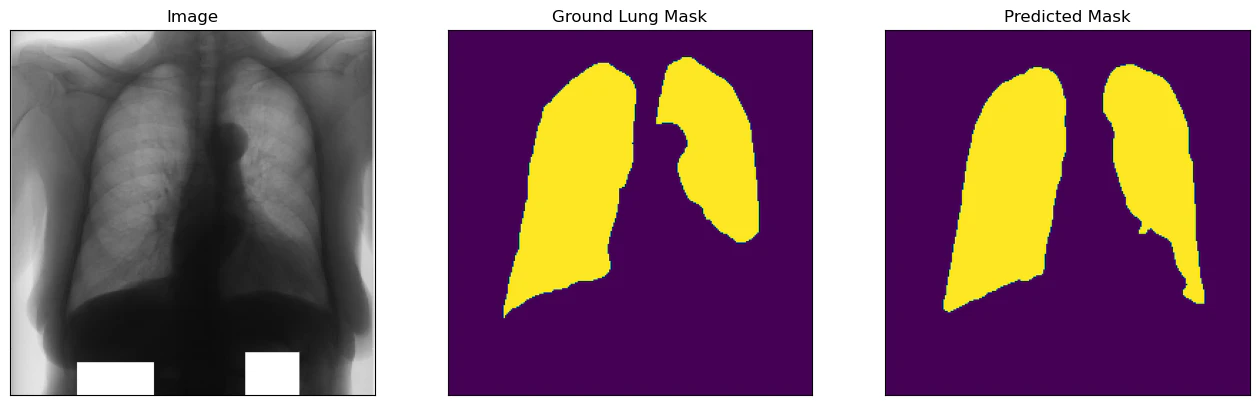
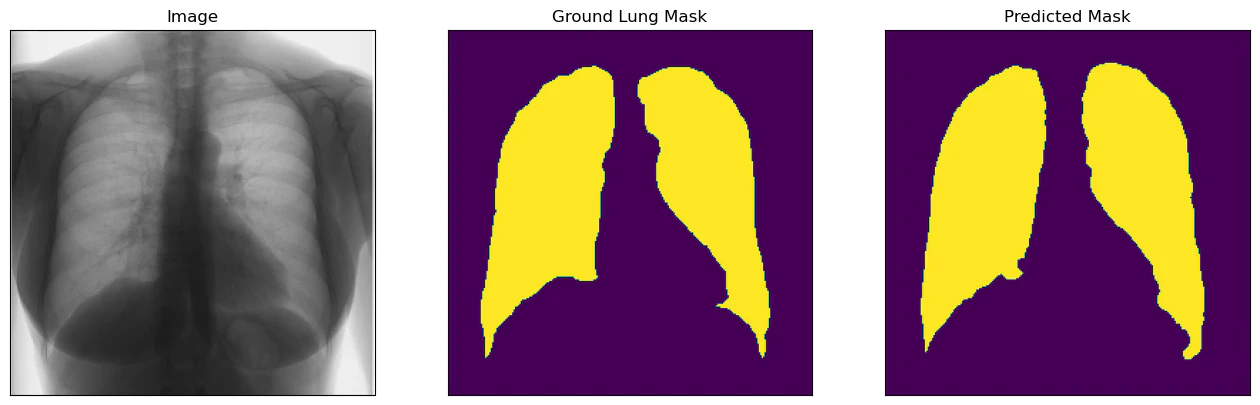
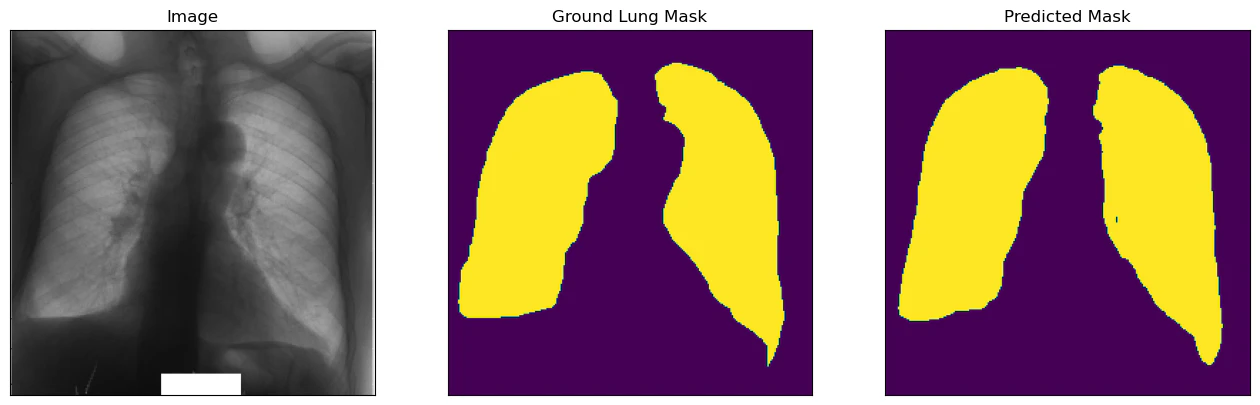
おわりに
とりあえず,コードの中身の詳しいところは置いといて,別データセットでも動くことを確認してみました.
そのうち,データセットの作成から解析までまとめられれば..
以下実行したjupyternotebookのコードなどです.
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import numpy as np
import cv2
import matplotlib.pyplot as plt
from glob import glob
DATA_DIR = './segmentation/'
x_train_dir = os.path.join(DATA_DIR, 'org_train')
z_train_dir = os.path.join(DATA_DIR, 'label_train')
x_valid_dir = os.path.join(DATA_DIR, 'org_val')
z_valid_dir = os.path.join(DATA_DIR, 'label_val')
x_test_dir = os.path.join(DATA_DIR, 'org_test')
z_test_dir = os.path.join(DATA_DIR, 'label_test')
def preconvert(y_train,y_train2):
filelist = sorted(glob(y_train+'/*.png'))
for file in filelist:
mask = cv2.imread(file)
mask[mask==255] = 1 # 肺野領域 lung
mask[mask==85] = 2 # 心臓 heart
mask[mask==170] = 3 # 体 body
t1 = file.split('\\')[-1]
t2 = t1.split('_')[0]
fname = t2+'.bmp'
cv2.imwrite(y_train2+'/'+fname, mask)
y_train_dir = os.path.join(DATA_DIR, 'label_train2')
y_valid_dir = os.path.join(DATA_DIR, 'label_val2')
y_test_dir = os.path.join(DATA_DIR, 'label_test2')
preconvert(z_train_dir,y_train_dir)
preconvert(z_valid_dir,y_valid_dir)
preconvert(z_test_dir,y_test_dir)
# helper function for data visualization
def visualize(**images):
"""PLot images in one row."""
n = len(images)
plt.figure(figsize=(16, 5))
for i, (name, image) in enumerate(images.items()):
plt.subplot(1, n, i + 1)
plt.xticks([])
plt.yticks([])
plt.title(' '.join(name.split('_')).title())
plt.imshow(image)
plt.show()
from torch.utils.data import DataLoader
from torch.utils.data import Dataset as BaseDataset
class Dataset(BaseDataset):
"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.
Args:
images_dir (str): path to images folder
masks_dir (str): path to segmentation masks folder
class_values (list): values of classes to extract from segmentation mask
augmentation (albumentations.Compose): data transfromation pipeline
(e.g. flip, scale, etc.)
preprocessing (albumentations.Compose): data preprocessing
(e.g. noralization, shape manipulation, etc.)
"""
CLASSES = ['outside', 'lung', 'heart', 'body']
def __init__(
self,
images_dir,
masks_dir,
classes=None,
augmentation=None,
preprocessing=None,
):
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
# convert str names to class values on masks
self.class_values = [self.CLASSES.index(cls.lower()) for cls in classes]
self.augmentation = augmentation
self.preprocessing = preprocessing
def __getitem__(self, i):
# read data
image = cv2.imread(self.images_fps[i])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mask = cv2.imread(self.masks_fps[i], 0)
# extract certain classes from mask (e.g. cars)
masks = [(mask == v) for v in self.class_values]
mask = np.stack(masks, axis=-1).astype('float')
# apply augmentations
if self.augmentation:
sample = self.augmentation(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
# apply preprocessing
if self.preprocessing:
sample = self.preprocessing(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
return image, mask
def __len__(self):
return len(self.ids)
# Lets look at data we have
dataset = Dataset(x_train_dir, y_train_dir, classes=['lung'])
image, mask = dataset[1] # get some sample
visualize(
image=image,
lung_mask=mask.squeeze(),
)
import albumentations as albu
def get_training_augmentation():
train_transform = [
albu.HorizontalFlip(p=0.5),
albu.ShiftScaleRotate(scale_limit=0.5, rotate_limit=0, shift_limit=0.1, p=1, border_mode=0),
# albu.PadIfNeeded(min_height=320, min_width=320, always_apply=True, border_mode=0),
# albu.RandomCrop(height=320, width=320, always_apply=True),
albu.PadIfNeeded(min_height=256, min_width=256, always_apply=True, border_mode=0),
albu.RandomCrop(height=256, width=256, always_apply=True),
# albu.IAAAdditiveGaussianNoise(p=0.2),
# albu.IAAPerspective(p=0.5),
albu.GaussNoise(p=0.2),
albu.Perspective(p=0.5),
albu.OneOf(
[
albu.CLAHE(p=1),
albu.RandomBrightnessContrast(p=1),
albu.RandomGamma(p=1),
],
p=0.9,
),
albu.OneOf(
[
# albu.IAASharpen(p=1),
albu.Sharpen(p=1),
albu.Blur(blur_limit=3, p=1),
albu.MotionBlur(blur_limit=3, p=1),
],
p=0.9,
),
albu.OneOf(
[
albu.RandomBrightnessContrast(p=1),
albu.HueSaturationValue(p=1),
],
p=0.9,
),
]
return albu.Compose(train_transform)
def get_validation_augmentation():
"""Add paddings to make image shape divisible by 32"""
test_transform = [
albu.PadIfNeeded(256, 256)
# albu.PadIfNeeded(384, 480)
]
return albu.Compose(test_transform)
def to_tensor(x, **kwargs):
return x.transpose(2, 0, 1).astype('float32')
def get_preprocessing(preprocessing_fn):
"""Construct preprocessing transform
Args:
preprocessing_fn (callbale): data normalization function
(can be specific for each pretrained neural network)
Return:
transform: albumentations.Compose
"""
_transform = [
albu.Lambda(image=preprocessing_fn),
albu.Lambda(image=to_tensor, mask=to_tensor),
]
return albu.Compose(_transform)
#### Visualize resulted augmented images and masks
augmented_dataset = Dataset(
x_train_dir,
y_train_dir,
augmentation=get_training_augmentation(),
classes=['lung'],
)
# same image with different random transforms
for i in range(3):
image, mask = augmented_dataset[1]
visualize(image=image, mask=mask.squeeze(-1))


import torch
import numpy as np
import segmentation_models_pytorch as smp
import segmentation_models_pytorch.utils.metrics
#ENCODER = 'se_resnext50_32x4d'
#ENCODER = 'resnext50_32x4d'
ENCODER = "efficientnet-b0"
ENCODER_WEIGHTS = 'imagenet'
CLASSES = ['lung']
ACTIVATION = 'sigmoid' # could be None for logits or 'softmax2d' for multiclass segmentation
DEVICE = 'cuda'
#DEVICE = 'cpu'
# create segmentation model with pretrained encoder
#model = smp.FPN(
model = smp.DeepLabV3Plus(
encoder_name=ENCODER,
encoder_weights=ENCODER_WEIGHTS,
classes=len(CLASSES),
activation=ACTIVATION,
)
preprocessing_fn = smp.encoders.get_preprocessing_fn(ENCODER, ENCODER_WEIGHTS)
Downloading: "https://github.com/lukemelas/EfficientNet-PyTorch/releases/download/1.0/efficientnet-b0-355c32eb.pth" to C:\Users\DPR2024-1/.cache\torch\hub\checkpoints\efficientnet-b0-355c32eb.pth
100%|?????????????????????????????????????????????????????????????????????????????| 20.4M/20.4M [00:01<00:00, 11.7MB/s]
train_dataset = Dataset(
x_train_dir,
y_train_dir,
augmentation=get_training_augmentation(),
preprocessing=get_preprocessing(preprocessing_fn),
classes=CLASSES,
)
valid_dataset = Dataset(
x_valid_dir,
y_valid_dir,
augmentation=get_validation_augmentation(),
preprocessing=get_preprocessing(preprocessing_fn),
classes=CLASSES,
)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True, num_workers=0)
valid_loader = DataLoader(valid_dataset, batch_size=1, shuffle=False, num_workers=0)
# Dice/F1 score - https://en.wikipedia.org/wiki/S%C3%B8rensen%E2%80%93Dice_coefficient
# IoU/Jaccard score - https://en.wikipedia.org/wiki/Jaccard_index
loss = smp.utils.losses.DiceLoss()
metrics = [
smp.utils.metrics.IoU(threshold=0.5),
]
optimizer = torch.optim.Adam([
dict(params=model.parameters(), lr=0.0001),
])
# create epoch runners
# it is a simple loop of iterating over dataloader`s samples
train_epoch = smp.utils.train.TrainEpoch(
model,
loss=loss,
metrics=metrics,
optimizer=optimizer,
device=DEVICE,
verbose=True,
)
valid_epoch = smp.utils.train.ValidEpoch(
model,
loss=loss,
metrics=metrics,
device=DEVICE,
verbose=True,
)
# train model for 40 epochs
max_score = 0
for i in range(0, 40):
print('\nEpoch: {}'.format(i))
train_logs = train_epoch.run(train_loader)
valid_logs = valid_epoch.run(valid_loader)
# do something (save model, change lr, etc.)
if max_score < valid_logs['iou_score']:
max_score = valid_logs['iou_score']
torch.save(model, './best_model.pth')
print('Model saved!')
if i == 25:
optimizer.param_groups[0]['lr'] = 1e-5
print('Decrease decoder learning rate to 1e-5!')
Epoch: 0
train: 100%|???????????????????????????????????| 19/19 [00:06<00:00, 3.02it/s, dice_loss - 0.4983, iou_score - 0.4861]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 26.72it/s, dice_loss - 0.5645, iou_score - 0.6058]
Model saved!
Epoch: 1
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 6.83it/s, dice_loss - 0.3317, iou_score - 0.6202]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 41.27it/s, dice_loss - 0.3682, iou_score - 0.5534]
Epoch: 2
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.43it/s, dice_loss - 0.2705, iou_score - 0.6674]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 42.62it/s, dice_loss - 0.3033, iou_score - 0.5871]
Epoch: 3
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.66it/s, dice_loss - 0.2228, iou_score - 0.7259]
valid: 100%|????????????????????????????????????| 49/49 [00:01<00:00, 40.75it/s, dice_loss - 0.2332, iou_score - 0.695]
Model saved!
Epoch: 4
train: 100%|????????????????????????????????????| 19/19 [00:02<00:00, 7.28it/s, dice_loss - 0.217, iou_score - 0.7269]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 45.47it/s, dice_loss - 0.1965, iou_score - 0.7631]
Model saved!
Epoch: 5
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.37it/s, dice_loss - 0.1804, iou_score - 0.7722]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 42.89it/s, dice_loss - 0.1705, iou_score - 0.8003]
Model saved!
Epoch: 6
train: 100%|????????????????????????????????????| 19/19 [00:02<00:00, 6.96it/s, dice_loss - 0.1817, iou_score - 0.762]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 44.69it/s, dice_loss - 0.1581, iou_score - 0.7968]
Epoch: 7
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.67it/s, dice_loss - 0.1594, iou_score - 0.7904]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 43.80it/s, dice_loss - 0.1404, iou_score - 0.8269]
Model saved!
Epoch: 8
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.24it/s, dice_loss - 0.1351, iou_score - 0.8219]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 47.55it/s, dice_loss - 0.1307, iou_score - 0.8289]
Model saved!
Epoch: 9
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.28it/s, dice_loss - 0.1382, iou_score - 0.8132]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 46.84it/s, dice_loss - 0.1271, iou_score - 0.8266]
Epoch: 10
train: 100%|?????????????????????????????????????| 19/19 [00:02<00:00, 7.13it/s, dice_loss - 0.1148, iou_score - 0.84]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 44.43it/s, dice_loss - 0.1149, iou_score - 0.8412]
Model saved!
Epoch: 11
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.40it/s, dice_loss - 0.1281, iou_score - 0.8277]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 46.82it/s, dice_loss - 0.1121, iou_score - 0.8484]
Model saved!
Epoch: 12
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.04it/s, dice_loss - 0.1199, iou_score - 0.8386]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 44.80it/s, dice_loss - 0.1002, iou_score - 0.8685]
Model saved!
Epoch: 13
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.38it/s, dice_loss - 0.1103, iou_score - 0.8489]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 45.86it/s, dice_loss - 0.09113, iou_score - 0.8796]
Model saved!
Epoch: 14
train: 100%|????????????????????????????????????| 19/19 [00:02<00:00, 6.77it/s, dice_loss - 0.107, iou_score - 0.8547]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 46.63it/s, dice_loss - 0.08707, iou_score - 0.8853]
Model saved!
Epoch: 15
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.58it/s, dice_loss - 0.08679, iou_score - 0.8812]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 44.10it/s, dice_loss - 0.08072, iou_score - 0.8919]
Model saved!
Epoch: 16
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 6.85it/s, dice_loss - 0.1027, iou_score - 0.8601]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 46.48it/s, dice_loss - 0.0907, iou_score - 0.8734]
Epoch: 17
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.77it/s, dice_loss - 0.0833, iou_score - 0.8849]
valid: 100%|????????????????????????????????????| 49/49 [00:01<00:00, 46.31it/s, dice_loss - 0.0731, iou_score - 0.902]
Model saved!
Epoch: 18
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.45it/s, dice_loss - 0.09193, iou_score - 0.8716]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 45.55it/s, dice_loss - 0.07133, iou_score - 0.9039]
Model saved!
Epoch: 19
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.16it/s, dice_loss - 0.07678, iou_score - 0.8931]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 47.60it/s, dice_loss - 0.0689, iou_score - 0.9081]
Model saved!
Epoch: 20
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.43it/s, dice_loss - 0.07842, iou_score - 0.8865]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 45.47it/s, dice_loss - 0.06751, iou_score - 0.9058]
Epoch: 21
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.05it/s, dice_loss - 0.07605, iou_score - 0.8939]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 46.25it/s, dice_loss - 0.06596, iou_score - 0.909]
Model saved!
Epoch: 22
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.31it/s, dice_loss - 0.07148, iou_score - 0.8963]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 46.20it/s, dice_loss - 0.06089, iou_score - 0.9154]
Model saved!
Epoch: 23
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.62it/s, dice_loss - 0.07272, iou_score - 0.8939]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 41.80it/s, dice_loss - 0.05923, iou_score - 0.9169]
Model saved!
Epoch: 24
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.00it/s, dice_loss - 0.06553, iou_score - 0.9045]
valid: 100%|???????????????????????????????????| 49/49 [00:01<00:00, 47.95it/s, dice_loss - 0.05851, iou_score - 0.915]
Epoch: 25
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.47it/s, dice_loss - 0.06288, iou_score - 0.907]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 47.76it/s, dice_loss - 0.05897, iou_score - 0.9138]
Decrease decoder learning rate to 1e-5!
Epoch: 26
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.57it/s, dice_loss - 0.06728, iou_score - 0.9023]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 43.38it/s, dice_loss - 0.05677, iou_score - 0.9183]
Model saved!
Epoch: 27
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 6.76it/s, dice_loss - 0.06383, iou_score - 0.9074]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 46.72it/s, dice_loss - 0.05645, iou_score - 0.9195]
Model saved!
Epoch: 28
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.47it/s, dice_loss - 0.06364, iou_score - 0.906]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 45.82it/s, dice_loss - 0.05615, iou_score - 0.9187]
Epoch: 29
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.43it/s, dice_loss - 0.07399, iou_score - 0.891]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 44.97it/s, dice_loss - 0.05633, iou_score - 0.9193]
Epoch: 30
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.09it/s, dice_loss - 0.06355, iou_score - 0.9083]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 47.39it/s, dice_loss - 0.05672, iou_score - 0.9191]
Epoch: 31
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.46it/s, dice_loss - 0.06698, iou_score - 0.9004]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 47.31it/s, dice_loss - 0.05632, iou_score - 0.9184]
Epoch: 32
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.13it/s, dice_loss - 0.0665, iou_score - 0.9033]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 43.64it/s, dice_loss - 0.05604, iou_score - 0.9189]
Epoch: 33
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.18it/s, dice_loss - 0.0672, iou_score - 0.9018]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 44.89it/s, dice_loss - 0.05631, iou_score - 0.9194]
Epoch: 34
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.51it/s, dice_loss - 0.06213, iou_score - 0.9095]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 45.98it/s, dice_loss - 0.05644, iou_score - 0.9196]
Model saved!
Epoch: 35
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.54it/s, dice_loss - 0.06038, iou_score - 0.9106]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 45.62it/s, dice_loss - 0.05577, iou_score - 0.9192]
Epoch: 36
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.40it/s, dice_loss - 0.06269, iou_score - 0.9077]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 45.22it/s, dice_loss - 0.05533, iou_score - 0.9196]
Model saved!
Epoch: 37
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 7.21it/s, dice_loss - 0.07079, iou_score - 0.8968]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 43.24it/s, dice_loss - 0.05541, iou_score - 0.9205]
Model saved!
Epoch: 38
train: 100%|??????????????????????????????????| 19/19 [00:02<00:00, 6.95it/s, dice_loss - 0.06027, iou_score - 0.9101]
valid: 100%|??????????????????????????????????| 49/49 [00:01<00:00, 43.99it/s, dice_loss - 0.05482, iou_score - 0.9207]
Model saved!
Epoch: 39
train: 100%|???????????????????????????????????| 19/19 [00:02<00:00, 7.22it/s, dice_loss - 0.06975, iou_score - 0.899]
valid: 100%|????????????????????????????????????| 49/49 [00:01<00:00, 43.72it/s, dice_loss - 0.05544, iou_score - 0.92]
# load best saved checkpoint
best_model = torch.load('./best_model.pth')
# create test dataset
test_dataset = Dataset(
x_test_dir,
y_test_dir,
augmentation=get_validation_augmentation(),
preprocessing=get_preprocessing(preprocessing_fn),
classes=CLASSES,
)
test_dataloader = DataLoader(test_dataset)
# evaluate model on test set
test_epoch = smp.utils.train.ValidEpoch(
model=best_model,
loss=loss,
metrics=metrics,
device=DEVICE,
)
logs = test_epoch.run(test_dataloader)
valid: 100%|??????????????????????????????????| 48/48 [00:01<00:00, 26.79it/s, dice_loss - 0.05801, iou_score - 0.9153]
# test dataset without transformations for image visualization
test_dataset_vis = Dataset(
x_test_dir, y_test_dir,
classes=CLASSES,
)
for i in range(5):
n = np.random.choice(len(test_dataset))
image_vis = test_dataset_vis[n][0].astype('uint8')
image, gt_mask = test_dataset[n]
gt_mask = gt_mask.squeeze()
x_tensor = torch.from_numpy(image).to(DEVICE).unsqueeze(0)
pr_mask = best_model.predict(x_tensor)
pr_mask = (pr_mask.squeeze().cpu().numpy().round())
visualize(
image=image_vis,
ground_lung_mask=gt_mask,
predicted_mask=pr_mask
)