はじめに
AWS Glueは、抽出、変換、ロード(ETL)サービスで、Amazonのホスト型Webサービスの一部として利用できます。
様々なデータストアにあるデータを簡単に接続し、必要に応じてデータを編集、クリーンアップし、AWSで提供されているストアにデータロード。統一されたビューを表示できるようにすることを目的としています。
GlueはJDBCによるデータアクセスをサポートしており、現時点でサポートされるデータベースは、Postgres、MySQL、Redshift、Auroraですが、ここにDataDirect JDBC コネクタを使うとより多くのデータソースへのアクセスを実現できます。
この記事では、AWS GlueよりSalesforceデータへのアクセスを試みます。
DataDirect Salesforce JDBCドライバーのダウンロード
1.DataDirect Salesforce JDBCドライバーをダウンロードします。
2.JARを実行してインストします。ターミナルで以下のコマンドを実行するか、もしくはJARのダブルクリックですね。
java -jar PROGRESS_DATADIRECT_JDBC_SF_ALL.jar
3.インタラクティブなJAVAインストーラーが起動されるので、DataDirect Salesforce JDBCドライバーをそのままインストします。
ちなみにSalesforce用JDBCドライバーだけでなく、その他多数のドライバーも同じフォルダにインストールされているので、1ドライバーでいろいろ試せます。
DataDirect SalesforceドライバーのAmazon S3へのアップロード
1.DataDirect JDBCドライバーのインスト先に、DataDirect Salesforce JDBCドライバーのファイル(sforce.jar)が存在することを確認します。
2.Salesforce JDBCのJARファイルをAmazon S3にアップロードします。
Amazon Glueジョブの作成
1.ブラウザからAWS Glueコンソールへアクセスし、「ETL」の「Job」にある「Add Job」ボタンをクリックし、新規ジョブを作成します。以下のような画面が表示されます。
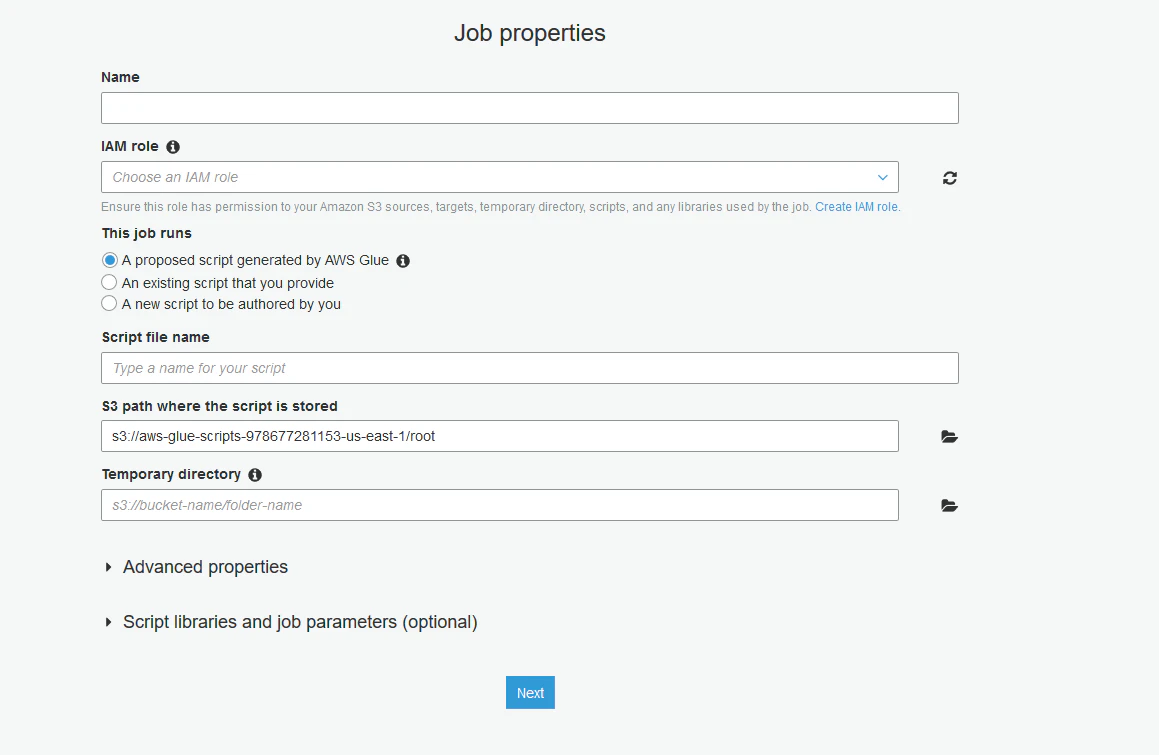
2.ジョブ名を入力し、ジョブで使用するAmazon S3のソースやターゲット、一時ディレクトリ、スクリプト、ライブラリなどへのアクセス権限を付与するために「IAM role」を選択もしくは作成します。JDBCドライバーは既に持っていて、その格納先はAmazon S3であることから、この記事ではS3へアクセスする必要があります。
3.「This job runs」で「A new script to be authored by you」を選択してください。
4.スクリプトのファイル名を入力し、S3内のGlueジョブ用の一時ディレクトリを選択します。
5.「Script Libraries and job parameters (optional)」(スクリプトのライブラリとジョブのパラメーター(オプション))を開いて、「Dependent Jars path」(依存するJARのパス)でS3内のsforce.jarファイルを選択してください。設定した内容は以下のようになっているはずです。
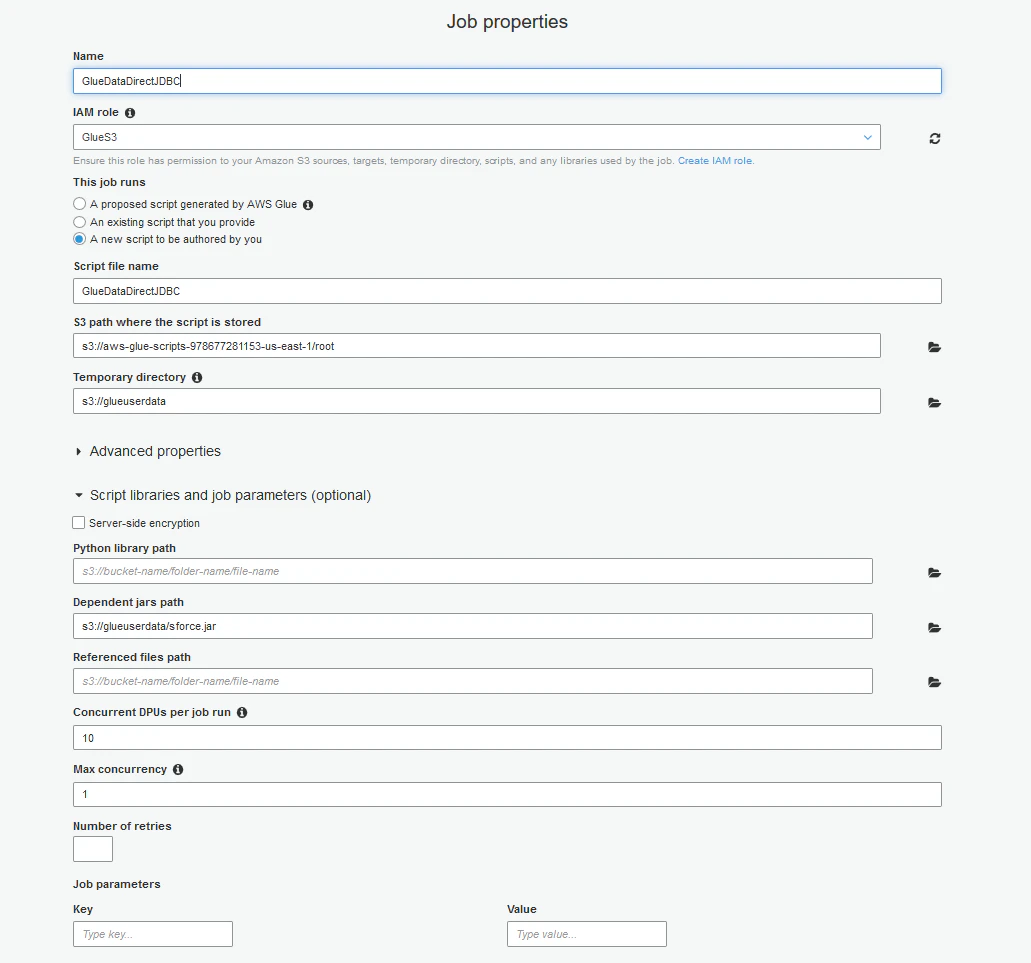
6.「Next」ボタンをクリックすると、ジョブで必要になる可能性がある接続を追加するか否かを問われるGlueのダイアログが表示されます。この記事では接続は必要ありませんが、例えばRedShiftやSQL Server、Oracleなど他のDBを使用する場合は、当該データソースへの接続をGlue内に作成することができます。作成した接続はこのダイアログに表示されます。
7.「Next」をクリックして設定をレビューします。「Finish」をクリックするとジョブが作成されます。
8.作成したジョブのPythonスクリプトを記述するエディターが表示されます。DataDirect JDBCドライバーを使ってSalesforceからデータを抽出し、S3もしくはその他の格納先に書き込むためのカスタムPythonコードをここに記述します。
9.このコードサンプルを参照頂けば、どのようにDataDirect JDBCドライバーでSalesforceからデータを抽出し、S3へCSV形式で書き込めば良いか分かると思います。最後にジョブを保存します。
コードサンプル
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
## Read Data from Salesforce using DataDirect JDBC driver in to DataFrame
source_df = spark.read.format("jdbc").option("url","jdbc:datadirect:sforce://login.salesforce.com;SecurityToken=<token>").option("dbtable", "SFORCE.OPPORTUNITY").option("driver", "com.ddtek.jdbc.sforce.SForceDriver").option("user", "user@mail.com").option("password", "pass123").load()
job.init(args['JOB_NAME'], args)
## Convert DataFrames to AWS Glue's DynamicFrames Object
dynamic_dframe = DynamicFrame.fromDF(source_df, glueContext, "dynamic_df")
## Write Dynamic Frames to S3 in CSV format. You can write it to any rds/redshift, by using the connection that you have defined previously in Glue
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dynamic_dframe, connection_type = "s3", connection_options = {"path": "s3://glueuserdata"}, format = "csv", transformation_ctx = "datasink4")
job.commit()
Glueジョブの実行
1.「Run Job」をクリックし、ジョブを開始します。ステータスの確認は、前画面に戻り、作成したジョブを選択します。
2.ジョブが正常に実行されると、DataDirect Salesforce JDBCドライバー経由で取得したデータがCSVファイルに保存されているはずです。
おしまい