概要
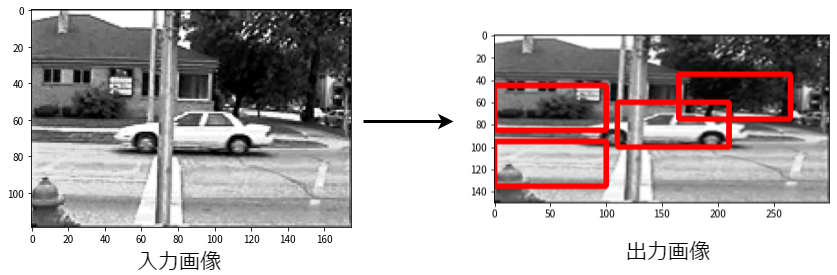
物体検出を勉強したアウトプットとしてHOG(Histgrams of Oriented Gradients)特徴量とSVM(Support Vector Machine)を用いた自動車の検出を行いました. 前回投稿した記事「Xceptionを転移学習させてセーラームーンのキャラを分類する」では1枚の画像につき, 1人のセーラー戦士を予測しました. この記事では1枚の画像に含まれる複数の自動車を検出することを目的とします. つまり, 次に示すような入力画像から出力画像に示すような自動車の位置を予測します. なお, 今回作成したプログラムはGitHubに置いてあります.

実行環境
Windows10 Anaconda 環境
CPU AMD Ryzen 5 3600
メモリ 16GB
GPU NVIDIA GeForce RTX 2060
Python 3.8.5
Numpy 1.19.5
scikit-learn 0.23.2
scikit-image 0.18.2
tqdm 4.56.0
OpenCV2 4.5.1
使用したデータと手法
自動車の検出に使用したデータと手法について説明します.
データ
データはUIUC Image Database for Car Detection を使用します. Downloadからデータを取得できるはずですが, タイムアウトが発生して取得できなかったためこちらから取得しました.
処理の流れ
物体検出の処理は次に示す3つの手順で行います. バウンディングボックスは概要の出力画像で示した赤い四角形のことです. このうち, 1の物体候補領域の提案をスライディングウィンドウ法, 2の物体らしさを計算をHOG特徴量とSVM, 3のバウンディングボックスの重複処理をIoUとNon-Maximum Suppressionという手法を用いて行います.
- 物体候補領域の提案
- 得られた候補を画像認識して認識対象の物体らしさを計算する.
- 同一物体が複数のバウンディングボックスで検出されないように処理する.
スライディングウィンドウ法
手書き数字認識やセーラー戦士の分類は1枚の画像からクラスを予測するために, 画像1枚をCNNに入力し出力としてどのクラスに属するかという情報を得る処理を行いました. しかし, 今回の自動車の検出の場合, 1枚の画像の中に複数の自動車が含まれている場合や, そもそも自動車が含まれていない場合があります. また自動車が複数台含まれている場合はその位置を予測しなければいけません. このため, 画像1枚を分割して, 分割した画像それぞれについて画像認識を適用します.
この画像を分割する方法の中で最も単純な手法がスライディングウィンドウ法です. スライディングウィンドウ法では, 一定の決まった領域を1pixelずつずらして物体候補領域を提案します. このため高さH, 横幅Wの画像にスライディングウィンドウ法を適用すると物体候補領域の数はおおよそHxWになります. さらに提案する候補領域のアスペクト比やスケールを考慮すると物体候補領域の数は膨大になります. このため, 物体らしさを計算は計算量の少ない高速な分類器を採用する必要があります. 今回は高速な分類器としてHOG特徴量とSVMの組み合わせを使用しました.スライディングウィンドウ法の説明は原田達也先生の画像認識という本がわかりやすかったです.
HOG特徴量
HOG(Histgrams of Oriented Gradients)特徴量は局所領域(cell)の画素値の勾配方向をヒストグラムで表したものです.
HOG特徴量の計算方法について説明します. まず, 注目画素$I(x,y)$について$x$方向の微分$I_x$と, $y$方向の微分$I_y$を次に示す式で計算します.
$$I_x = I(x+1,y)-I(x,y)$$
$$I_x = I(x,y+1)-I(x,y)$$
$I_x$,$I_y$から勾配(傾き)の強さを表す勾配強度$|I|$と勾配の角度を表す勾配方向$\theta$を計算します.
$$|I|=\sqrt{I_x^2 + I_y^2}$$
$$\theta = \tan^{-1}\frac{I_y}{I_x}$$
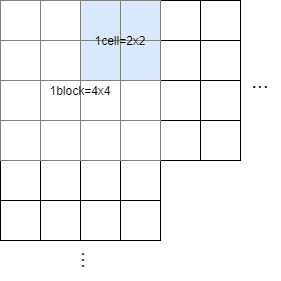
次にヒストグラムを作成するために勾配方向$\theta$を量子化します. 量子化は0°~180°を20°ずつに分ける操作です. 例えば36.2°を量子化すると40°になります. そしてcellという単位ごとに勾配強度$|I|$で重みづけした勾配方向ヒストグラムを計算します. さらにcellよりも大きいblockという単位ごとにヒストグラムを正規化します. 1blockの勾配方向ヒストグラムの総和$H$, 正規化前の$i$番目のblockヒストグラム$h(i)$とすると正規化後の$i$番目のヒストグラム$h'(i)$は次にように計算できます. mはcellのサイズ, Nは勾配方向の数, $\epsilon=1$です.
$$h'(i)=\frac{h(i)}{H}$$
$$H=\sqrt{\sum_{k=1}^{m^2\times N}h(k)^2+\epsilon}$$
例えば次の画像の場合, m=2, Nは0°~180°を20°ずつに分けているためN=9になります.
SVM
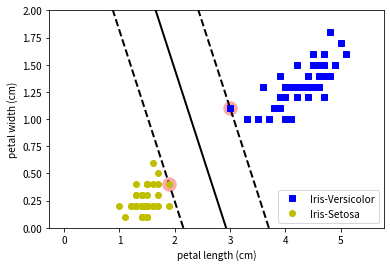
SVM(Support Vector Machine)は教師あり学習の手法の1つで, 主に分類問題に使用されます. 例としてアヤメという花の分類を考えます. 今, アヤメのpetal length(花弁の長さ)とpetal width(花弁の幅)の2つのデータから, アヤメのクラスがVersicolorかSetosaのどちらなのかを分類したいとします. SVMの分類の考え方は2つのクラスを分ける識別面を求めることです. 識別面を求めるために, 2つのクラスの間にできる直線の距離(マージンと呼ぶ)を最大化する学習を行います. 下の図では中央を通る直線が識別面, 2本の破線の距離がマージンです.
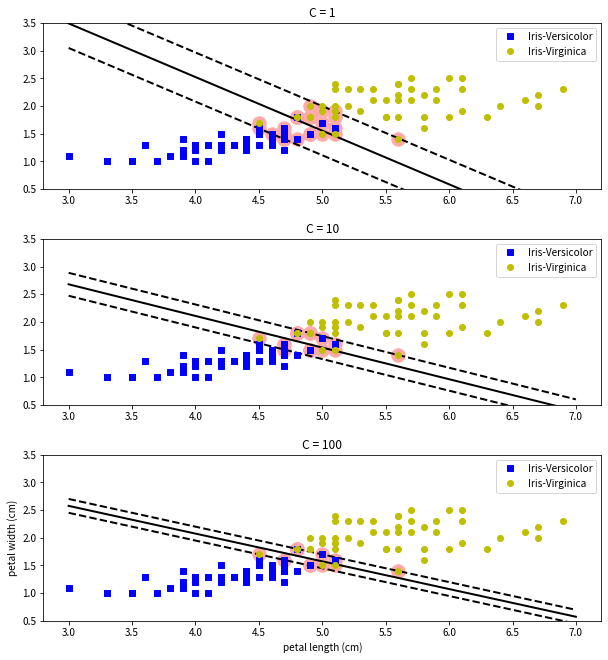
上記の例では識別面によってクラスを完全に分類すること(線形分離可能)ができましたが, 2つのクラスに重なっている部分がある場合は識別面を引くことができません(線形分離不可能). そこで識別面をまたぐデータあることを許すマージン違反を導入します. 下の例ではVersicolorとVirginicaの2つのアヤメの分類問題をSVMで解いています. VersicolorとVirginicaのデータは重なっている部分があるため, そのままでは識別面を許すことができません. そこでマージン違反を導入しています. 下の図では, 反対側の識別面に入ることを許す数Cとして複数のSVM学習器を生成して, パラメータCの違いによる識別面の違いを比較しています. なお, マージン違反を許さない分類をハードマージン分類, 許す分類をソフトマージン分類といいます.
実際のプログラムでは線形なSVMではなく非線形なSVMを使用しています. また線形分離を行うためにカーネルというものを導入しています. 非線形SVMやカーネルの話は「scikit-learnとTensorFlowによる実践機械学習」で勉強しました.
IoU
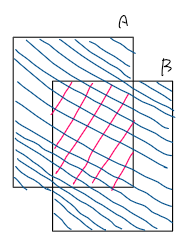
IoU(Intersection over Union)は物体検出の評価指標の1つで, 2枚の画像の重なりの割合を表します. 下の図のようにA, Bの2枚の画像があるときIoUは次のように計算できます. $A \cap B$は図のピンク色の部分, $A \cup B$は図の青色の部分を表します. IoUが大きいほど画像の重なり部分が多くなります.
$$IoU = \frac{A \cap B}{A \cup B}$$
Non-Maximum Suppression
Non-Maximum Suppressionは同じクラスとして認識された重なっている領域を1つにまとめるアルゴリズムです. このアルゴリズムはSVMが予測したバウンディングボックスにのそれぞれについてIoUを計算し, あるしきい値以上のバウンディングボックスを除外することに使用します. スライディングウィンドウ法を用いると同じクラスとして認識された重なっているバウンディングボックスが大量に現れるため, この処理を行います.
プログラムと実行結果
実装の流れは次の通りです.
- 訓練用の画像を読み込んでHOG特徴量を計算する.
- HOG特徴量から, 画像に自動車が含まれるかどうかを分類するSVMを訓練する.
- スライディングウィンドウ法を用いて画像を分類し, 分割した画像のそれぞれに次の処理を行う.
3.1 分割した画像のHOG特徴量を計算する.
3.2 SVMを用いて分割した画像に自動車が含まれているか予測する.
3.3 自動車が含まれていれば, その画像のバウンディングボックス(分割したときの左上の座標と幅, 高さ)を保存する. - スライディングウィンドウ法で得られたバウンディングボックスのリストにNon-Maximum Suppressionを適用して重なっているバウンディングボックスを除外する.
- 画像とバウンディングボックスを描画する.
ライブラリ読み込み
作成したプログラムについて説明する. まず, 必要なライブラリを読み込む. tqdmはfor文のループ状況を可視化するライブラリである.
import numpy as np
import matplotlib.pyplot as plt
import cv2
from tqdm import tqdm_notebook as tqdm # for文のループ状態の可視化
画像読み込みとHOG特徴量の計算
訓練用の画像を読み込んでHOG特徴量を計算する. 画像の読み込みとHOG特徴量の計算はload_data関数で行っている. データセットには正例(自動車が含まれている画像)と負例(自動車が含まれていない画像)が含まれているから両方についてload_data関数を実行している. なお, 正例の画像はすべて1台の自動車が写っている画像であることに注意する必要がある. SVMが予測するのはあくまで1台の自動車が画像中に含まれているかどうかである.
from skimage.feature import hog
def load_data(path,negpos,iter_num):
"""車の画像データを読み込む関数
Args:
path : 画像のパス
negpos : 正例(True)か負例(False)か
iter_num : ループ回数
"""
WINDOW_W = 100
WINDOW_H = 40
hogValueList = [] # HOG特徴量ベクトルのリスト
labelList = [] # negative or positive
if negpos: # Trueのとき
np = "pos-"
label = "positive"
else:
np = "neg-"
label = "negative"
for i in tqdm(range(iter_num+1)):
fname = path+np+str(i)+".pgm"
img = cv2.imread(fname) # 画像取得
# 画像を平面化
img2d = img[:,:,0] # 画像を3次元から1次元(グレースケールに変換)
img2d = img2d[0:WINDOW_H,0:WINDOW_W] # 画像サイズを統一する
# 画像からHOG特徴量を計算
# orientations : ヒストグラムのビンの数
# pixels_per_cell : セルの数
# cells_per_block : 1ブロックあたりのセルの数
hogValue = hog(img2d, block_norm='L2',orientations=9, pixels_per_cell=(6,6),cells_per_block=(3,3))
hogValueList.append(hogValue)
# ラベル代入
labelList.append(label)
return hogValueList,labelList
train_path = "./Data/TrainImages/"
test_path = "./Data/TestImages/"
POS_FILE_NUM = 549
NEG_FILE_NUM = 499
posHogValueList,posLabelList = load_data(train_path,True,POS_FILE_NUM) # positive train data
negHogValueList,negLabelList = load_data(train_path,False,NEG_FILE_NUM) # negative train data
HogValueList = posHogValueList+negHogValueList
LabelList = posLabelList+negLabelList
訓練データの例

SVMの訓練
画像の読み込みとHOG特徴量の計算ができたからSVMの訓練を行う. SVMの訓練はグリッドサーチで最良のカーネルとその係数, マージン違反の係数Cを探索している. また訓練したモデルをmodel.pickleというファイル名で保存している. 実行結果から訓練したSVMの交差検証のスコアが0.99であることがわかる.
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
import pickle
params_grid = [ # グリッドサーチのパラメータを定義
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'kernel': ['rbf'], 'gamma': [0.001, 0.0001]},
{'C': [1, 10, 100, 1000], 'kernel': ['poly'], 'degree': [2, 3, 4], 'gamma': [0.001, 0.0001]},
{'C': [1, 10, 100, 1000], 'kernel': ['sigmoid'], 'gamma': [0.001, 0.0001]}
]
model = SVC()
search = GridSearchCV(model,params_grid,cv=5,n_jobs=-1)
search.fit(HogValueList,LabelList) # グリッドサーチ実行
print(search.best_params_) # 最良のモデルのパラメータを表示
print(search.best_score_) # 最良のモデルのスコアを表示
# モデルの保存
with open('model.pickle', mode='wb') as f:
pickle.dump(search,f,protocol=2)
実行結果
{'C': 10, 'gamma': 0.001, 'kernel': 'rbf'}
0.9885714285714287
IoU, Non-Maximun Suppressionを計算する関数の定義
SVMの訓練ができたからテスト画像を用いて検出を行う. 検出ではIoUとNon-Maximun Suppressionの計算が必要なため関数として定義しておく. 関数はこちらを参考にしました.
# IoUの計算
def iou(a, b):
"""IoUを計算する関数
Args:
a:(x,y,x+WIDTH,y+HEIGHT)
b:(x,y,x+WIDTH,y+HEIGHT)
"""
a_x1, a_y1, a_x2, a_y2 = a
b_x1, b_y1, b_x2, b_y2 = b
if a == b:
return 1.0
elif (
(a_x1 <= b_x1 and a_x2 > b_x1) or (a_x1 >= b_x1 and b_x2 > a_x1)
) and (
(a_y1 <= b_y1 and a_y2 > b_y1) or (a_y1 >= b_y1 and b_y2 > a_y1)
):
intersection = (min(a_x2, b_x2) - max(a_x1, b_x1)) * (min(a_y2, b_y2) - max(a_y1, b_y1))
union = (a_x2 - a_x1) * (a_y2 - a_y1) + (b_x2 - b_x1) * (b_y2 - b_y1) - intersection
return intersection / union
else:
return 0.0
# Non-Maximun Suppressionを計算
def nms(bboxes, scores, iou_threshold):
"""NMSを計算する関数
Args:
bboxes : Bounding box のリスト
scores : 再現率
iou_threshold : 閾値
"""
new_bboxes = []
while len(bboxes) > 0:
i = scores.index(max(scores))
bbox = bboxes.pop(i)
scores.pop(i)
deletes = []
for j, (bbox_j, score_j) in enumerate(zip(bboxes, scores)):
if iou(bbox, bbox_j) > iou_threshold:
deletes.append(j)
for j in deletes[::-1]:
bboxes.pop(j)
scores.pop(j)
new_bboxes.append(bbox)
return new_bboxes
検出の実行
IoUとNon-Maximun Suppressionの関数が定義できたら, スライディングウィンドウ法でテスト画像を分割して,SVMでバウンディングボックスの検出, Non-Maximun Suppressionで バウンディングボックスの重複を除去して自動車の検出を行ってみます. 検出する画像はtest-3.pgmです. indexの値を変えると別の画像で検出を行うことができます. また, スライディングウィンドウを1pixelずつではなく5pixelずつずらして計算を行っています. また, Non-Maximun Suppressionの閾値は0.3に設定しています.
# 検出するテストデータのインデックス
index = 3
# モデルのオープン
with open('model.pickle', mode='rb') as f:
detecter = pickle.load(f)
# スライディングウィンドウの大きさ
WINDOW_W = 100
WINDOW_H = 40
# 画像サイズ
IMG_W = 300
IMG_H = 150
# ステップサイズ
STEP_W = 5
STEP_H = 5
# 画像読み込み
path = test_path+"test-"+str(index)+".pgm"
test_img = cv2.imread(path)
test_img = test_img[:,:,0]
test_img = cv2.resize(test_img,(IMG_W,IMG_H))
# スライディングウィンドウ検出
detected_list = []
for x in range(0,IMG_W-WINDOW_W+1,STEP_W):
for y in range(0,IMG_H-WINDOW_H+1,STEP_H):
window = test_img[y:y+WINDOW_H,x:x+WINDOW_W] # ウィンドウ取得
hogValue = np.array(hog(window, block_norm='L2',orientations=9, pixels_per_cell=(6,6),cells_per_block=(3,3))) # HOG特徴量を計算
hogValue = hogValue.reshape(1,-1)
predict = detecter.predict(hogValue) # SVMによる予測
if predict=="positive": # 自動車が含まれているときバウンディングボックスをリストに追加
detected_list.append([x,y,x+WINDOW_W,y+WINDOW_H])
nms_detected_list = nms(detected_list,[1]*len(detected_list),0.3) # Non-Maximun Suppression処理
# 描画用にカラー画像を取得しなおす
show_img = cv2.imread(path)
show_img = cv2.resize(show_img,(IMG_W,IMG_H))
plt.figure(facecolor="white")
if len(nms_detected_list) > 0:
for rect in nms_detected_list:
cv2.rectangle(show_img, tuple(rect[0:2]), tuple(rect[2:4]), color=(0,0,255), thickness=3)
plt.imshow(cv2.cvtColor(show_img, cv2.COLOR_BGR2RGB))
plt.show()
実行結果
test-3.pgmの場合
test-79.pgmの場合
まとめ
test-3.pgmの場合はうまく自動車が2台検出できているが, test-79.pgmの場合は自動車以外の何かも検出している. 初めての物体検出だったが思ったよりも良い精度で検出することができた. 物体検出のアルゴリズムとして他にもR-CNN, YOLO, SSDといった有名なものがあるから機会があれば別のアルゴリズムでも自動車の検出を試してみたい. CNNの場合はライブラリや文献がたくさんあるが物体検出のライブラリや文献はCNNと比較すると少ないように感じた.
参考文献
原田達也, 画像認識
https://bookclub.kodansha.co.jp/product?item=0000147663
HoG特徴量の原理・計算式 | 西住工房
https://algorithm.joho.info/image-processing/hog-feature-value/
scikit-learnとTensorFlowによる実践機械学習
https://www.oreilly.co.jp/books/9784873118345/
scikit-learn, Keras, TensorFlowによる実践機械学習 第2版
https://www.oreilly.co.jp/books/9784873119281/
物体検出についての歴史まとめ(1)
https://qiita.com/mshinoda88/items/9770ee671ea27f2c81a9
け日記 物体検出で重なったバウンディングボックスを除去・集約するアルゴリズムのまとめ (NMS, Soft-NMS, NMW, WBF)
https://ohke.hateblo.jp/entry/2020/06/20/230000
くーろんログ HOG特徴量とSVMを使った自動車の検出
https://96n.hatenablog.com/entry/2016/01/23/100311