はじめに
Unicode - 恩恵と厄介事 で、軽く触れた Shift_JIS(シフトJIS、SJIS) と CP932 について、少し詳しくまとめてみようと思います。
参考情報
下記情報を参考にさせて頂きました。
- とほほの文字コード入門
- 小形克宏の「文字の海、ビットの舟」――文字コードが私たちに問いかけるもの
- Shift_JIS と Windows-31J (MS932) の違いを整理してみよう
- IBM 拡張文字・NEC 選定 IBM 拡張文字・NEC 特殊文字 - Mr.XRAY
Shift_JIS
まずは、標準規格に基づく情報として整理します。
JIS X 0208
Shift_JIS は、JIS X 0208 の付属書で「シフト符号化表現」という名称で定義されています。
符号化文字集合 - JIS X 0201、JIS X 0208 を、SI/SO(シフトイン/シフトアウト)などの文字種切り替え制御コードを用いることなく、使い勝手良く配置した文字符号化方式が Shift_JIS です。
Shift_JIS では、JIS X 0208 は2バイトコード、JIS X 0201 は1バイトコードで表現されます。
ビットマップで等幅フォントが一般的だった時代、JIS X 0208 フォントサイズは正方形で、JIS X 0201 - ASCII/カタカナは漢字に対して横幅が半分にデザインされていました。
この横幅の比率から、JIS X 0208 を全角、JIS X 0201 を半角と呼んでいました。
また、全角を 2、半角を 1 とした値の指標を「文字幅」として利用していました。
Shift_JIS は、下記関係が成り立つので、日本語処理として使い勝手が良い文字符号化方式となっています。
文字列のバイト長 = 文字幅
JIS X 0213
JIS X 0208(非漢字、第一水準漢字、第二水準漢字)収録文字不足の解消を目的として、JIS X 0212(補助漢字)を制定しましたが、Shift_JIS では符号化方式の制約により JIS X 0212 は利用できませんでした。
パーソナルユースで絶大な地位を占めていた Windows (Shift_JIS ベースの CP932)で利用できないこともあり、JIS X 0212 は、広く利用されることはありませんでした。
JIS X 0212 は、UNIX系で利用されていた文字符号化方式 EUC で、下記のように利用されています。
- JIS X 0201 - ASCII は、1バイトコード
- JIX X 0208 は、2バイトコード
- JIS X 0201 - カタカナは、冒頭に制御文字 SS2(0x8E)を付与して2バイトコード
- JIS X 0212 は、冒頭に制御文字 SS3(0x8F)を付与して3バイトコード
SI/SO は、文字種切り替えシーケンスでしたが、SS(シングルシフト)は、直後1文字にのみ有効な切り替えコードとなっています。
そこで、Shift_JIS を念頭に置いて、収録文字の拡大をはかった規格が JIS X 0213 です。
JIS X 0213 は、JIS X 0208 に対して、非漢字、第三水準漢字、第四水準漢字を追加し、Shift_JIS-2004 として利用可能とした規格となっています。
このような目的があるので、JIS X 02013 は、符号化文字集合であることに加えて、文字符号化方式 - Shift_JIS-2004 を規定しています。
JIS X 0213 では、CP932 互換性についての多少の配慮もしています。
CP932 では、ベンダー拡張文字(システム外字)として下記が搭載されていました。
- 8740-879E NEC特殊文字
- ED40-EEFC NEC認定IBM拡張文字
- FA40-FCFC IBM拡張文字
JIS X 0213 で追加する非漢字で、「NEC特殊文字」に存在する文字は、CP932 と同一コードにマッピングを行いました。
しかし、JIS X 0213 - 第三水準漢字と「NEC認定IBM拡張文字」、JIS X 0213 - 第四水準漢字と「IBM拡張文字」はコード空間が重複するので、Shift_JIS-2004 では「NEC認定IBM拡張文字」「IBM拡張文字」が利用できなくなります。
当時、大きな話題となった JIS X 0213 ですが、下記理由で、Shift_JIS-2004 としては、広く利用されることはありませんでした。
- Unicode という存在があり、今更、Shift_JIS で利用文字を拡張する必要性が乏しい
- CP932 との完全互換がとれていない
- 過去の JIS X 0208 で自由領域とされていたコード空間を利用した、ユーザ定義文字(ユーザ外字)が利用不可となる
符号化文字集合 JIS X 0213 で定義されている一部の文字について、JIS X 0208-1990 定義文字から、字形変更がされています。
フォントファイルとしては、この字形変更に対応した JIS X 0213 準拠が進みました。
標準フォントファイルを JIS X 0213 準拠としたベンダーは、互換性維持のため JIS X 0208-1990 定義字形としたフォントファイルを、JIS90 対応フォントファイルとして提供していました。
CP932
Microsoft 標準キャラクタセット CP932(MS932, Windows-31J)について記載します。
歴史
Shift_JIS と Windows-31J (MS932) の違いを整理してみよう で、わかりやすい図を用いて、歴史が説明されています。
1993年にマイクロソフトは Windows 3.1 をリリースするにあたり、独自にコンピュータメーカが CP932 を拡張する事を禁じ、当時コンピュータの大きなシェアを持っていた NEC と IBM が独自拡張した CP932 を統合することにし、この統合した CP932 を Windows の標準日本語コードとすることにしたのです。
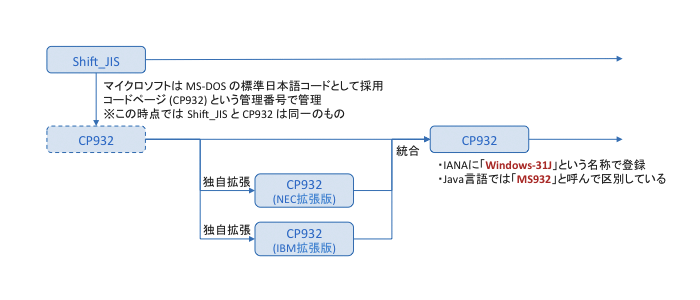
拡張文字
CP932では、Shift_JIS コード空間の下記エリアに、ベンダー拡張文字が標準搭載されています。
- 8740-879E NEC特殊文字
- ED40-EEFC NEC認定IBM拡張文字
- FA40-FCFC IBM拡張文字
ベンダー拡張文字として、NEC、IBM 双方に対する互換性を配慮したため、「NEC特殊文字 / NEC認定IBM拡張文字」と「IBM拡張文字」では、同一文字が異なるコードに重複配置されています。
例えば「髙 - U+9AD9」は、「IBM拡張文字 - FBFC」「NEC認定IBM拡張文字 - EEE0」に存在します。
Windows で、CP932 ベンダー拡張文字に該当する Unicode を CP932 に変換した場合、基本的には、「NEC特殊文字」に含まれる文字は該当文字コード、それ以外は「IBM拡張文字」の該当文字コードに変換されます。
上記文面で「基本的には」という文言が存在する理由は、「≒」「≡」などの文字が「NEC特殊文字」に存在しますが、これらの文字は JIS X 0208-1983 で追加されているので、Unicode から CP932 に変換すると、JIS X 0208 側の該当文字コードに変換されるためです。
先ほどの「髙 - U+9AD9」を、CP932 → Unicode → CP932 変換した結果を記載します。
- 「NEC認定IBM拡張文字 - EEE0」→「U+9AD9」→「IBM拡張文字 - FBFC」
- 「IBM拡張文字 - FBFC」→「U+9AD9」→「IBM拡張文字 - FBFC」
元号合字
「NEC特殊文字」に、本来なら漢字2文字で表現される元号を、漢字1文字だけで表せる合字(合成文字)として、「㍾」「㍽」「㍼」「㍻」が用意されていました。
Windows 用の日本の新元号対応更新プログラムについて - KB4469068 で新元号の合字「㋿」を Windows 標準フォントに追加しましたが、追加された合字は Unicode のみ使用可で、CP932 にはマッピングされませんでした。

IME
現時点の IME 候補一覧では、Shift_JIS(CP932 拡張文字を除く)にマッピングできない文字について、[環境依存] と明記されます。

Windows で表示/印刷可能な CP932 拡張文字も[環境依存]と表記される理由は、個別デバイス利用フォントファイルなどで、CP932 拡張文字に対応していない可能性があるためと思われます。
C# での振舞い
Windows では、基本的に Shift_JIS = CP932 として扱います。
Unicode と CP932 との相互変換は、下記手法などで実施できます。
// .NET では、エンコード Shift_JIS が未登録なので。
// 下記コメントを外して、プロバイダ登録を実施する必要があります
// Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
string hoge = "123ABC";
// Unicode → CP932
var bytes = Encoding.GetEncoding("Shift_JIS").GetBytes(hoge);
// CP932 → Unicode
var fuga = Encoding.GetEncoding("Shift_JIS").GetString(bytes);
Unicode には、CP932 にマッピングできない文字が含まれていて、マッピングできない文字を CP932 に変換すると「? - 3F」になってしまいます。
例として、下記表に記載した文字を用いた Unicode を CP932 変換をしてみます。

string hoge = "1Ⅰ⑴";
var bytes = Encoding.GetEncoding("Shift_JIS").GetBytes(hoge);
// → 0x82 0x50 0x87 0x54 0x3F
- 「U+FF11」は、CP932「8250」に変換(JIS X 0208 文字)
- 「U+2160」は、CP932「8754」に変換(CP932 拡張文字)
- 「U+2474」は、CP932に該当する文字がないので「3F」に変換
JavaScript での振舞い
JavaScript ライブラリを用いた文字コード変換で、Shift_JIS、CP932 を明確に区別しているか否かは、各ライブラリ仕様に依存します。
Node.js の iconv-lite については、https://github.com/ashtuchkin/iconv-lite/blob/v0.4.19/encodings/dbcs-data.js#L41-L56 を見ると cp932 や windows31j は shiftjis のエイリアスという扱いになっています。
(shiftjis = cp932 = windows31j で CP932拡張文字を含む)
var iconv = require('iconv-lite');
var hoge = "123ABC";
// Unicode → CP932
var data = iconv.encode(hoge, 'cp932');
// CP932 → Unicode
var fuga = iconv.decode(data, 'cp932');