前回で導入手順をまとめたので、今回は実際の使い方をまとめ。
基礎用語概要
基本的にPentaho Data Integration(PDI)でできることは、色々なデータ(データソースや型)を入力・統合し変換して出力すること(ETL)であり、データの可視化(グラフ化等)もできる。
いろいろと用語があるので、必要最低限を簡単にまとめておく。
- ストリーム
- PDIでは基本的にデータを入力してそれを次々に加工していく(ETL:Extract Transform Load)。このデータのフローのこと。
- ステップ
- データを扱う最小の単位。入力(Extract)だったり、変換(Transform)だったり、出力(Load)だったり。PDI上の操作としては、「デザイン」タブのメニューから実行したいETL動作を選択してメインエリアに配置する。
- ホップ
- データのフローを表す。ステップ間をホップでつないでデータを受け渡してストリームを構成する。PDI上の操作としては、メインエリアのアイコン同士を[Shift]+マウスドラッグで繋ぐ、出力側アイコンを選択しておいてデザインからダブルクリックでメインエリアに配置する等複数の方法がある(Windows等で3つボタンマウスを使用していれば、真ん中ボタンのドラッグでも可)。
- データ変換
- PDIで作成するファイルの種類というと語弊があるが、Wordでいう文書。ストリームが主役。
- ジョブ
- これもPDIで作成できる文書の種類。こちらはその名の通りなにがしかの処理を定義しておいて、Pentaho-Serverなどにスケジュール実行させたりする。
ステップ逆引き
やりたいことからどんなステップを使えば良いかまとめ(随時更新)。
指定したデータフィールド(固定値)をレコード生成する
「入力」ー「データグリッド」
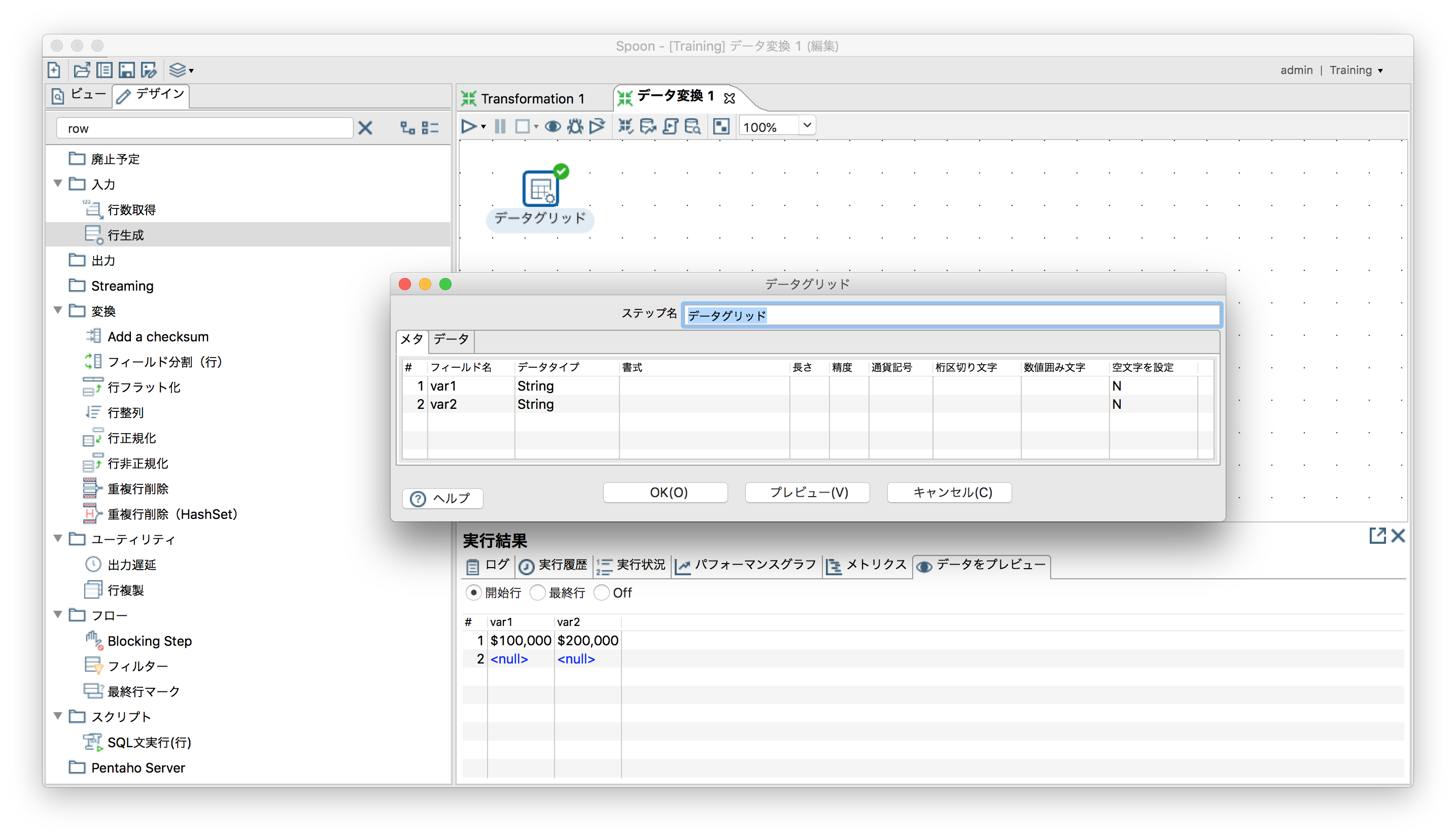
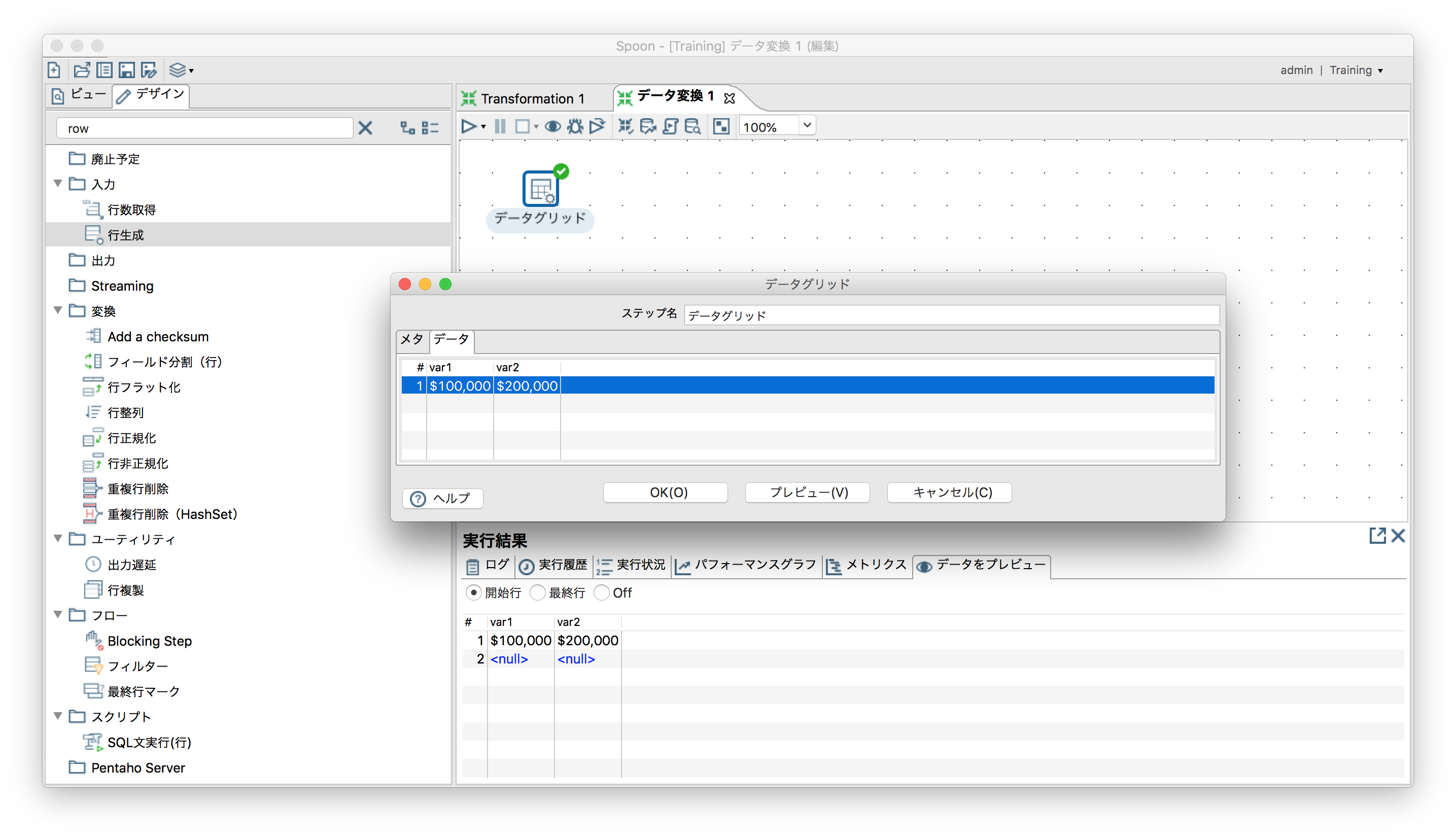
データは1レコードずつ任意の値を指定可能。
指定したデータフィールド(固定値)を指定レコード数生成する
「入力」ー「行生成」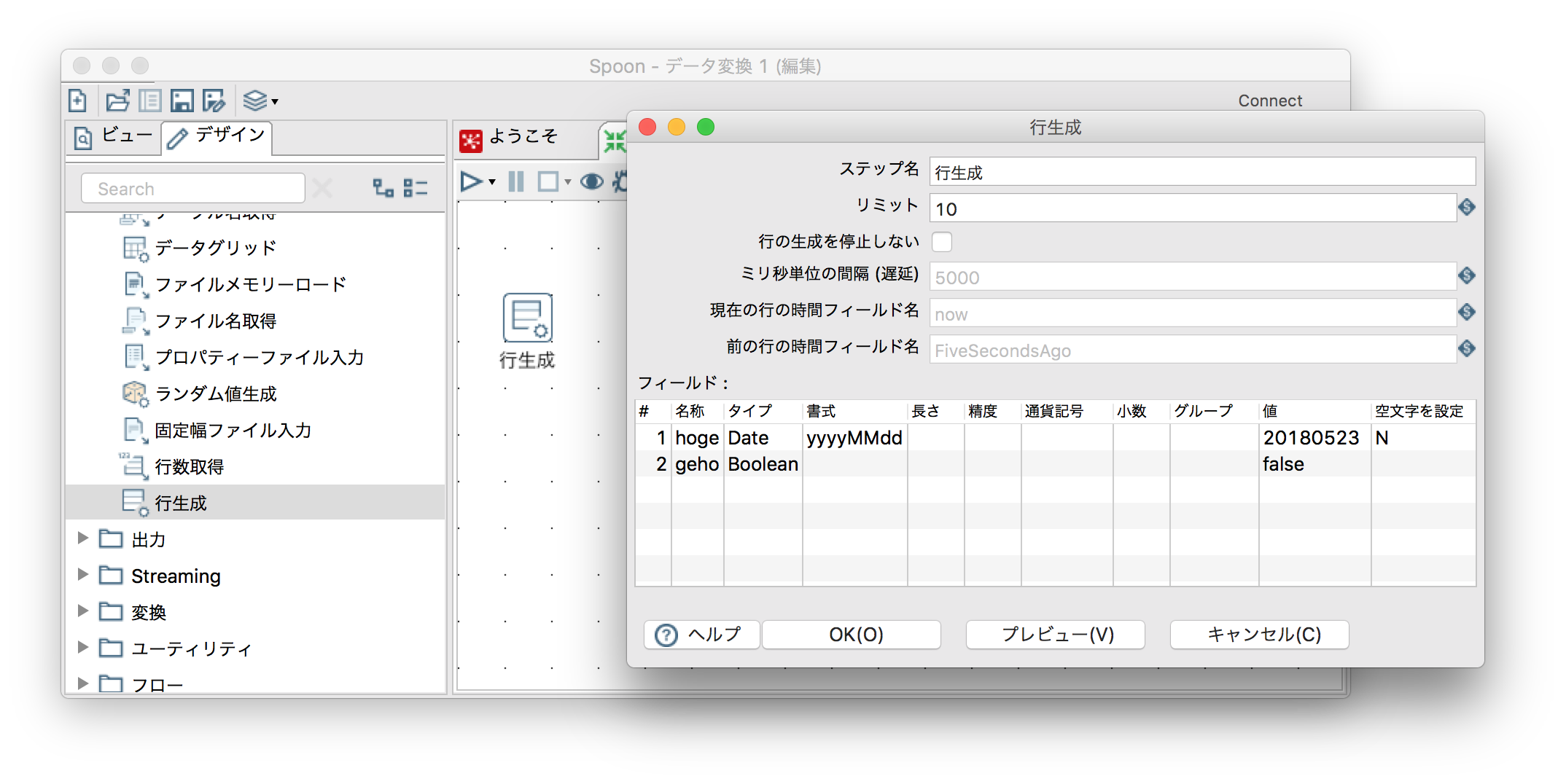
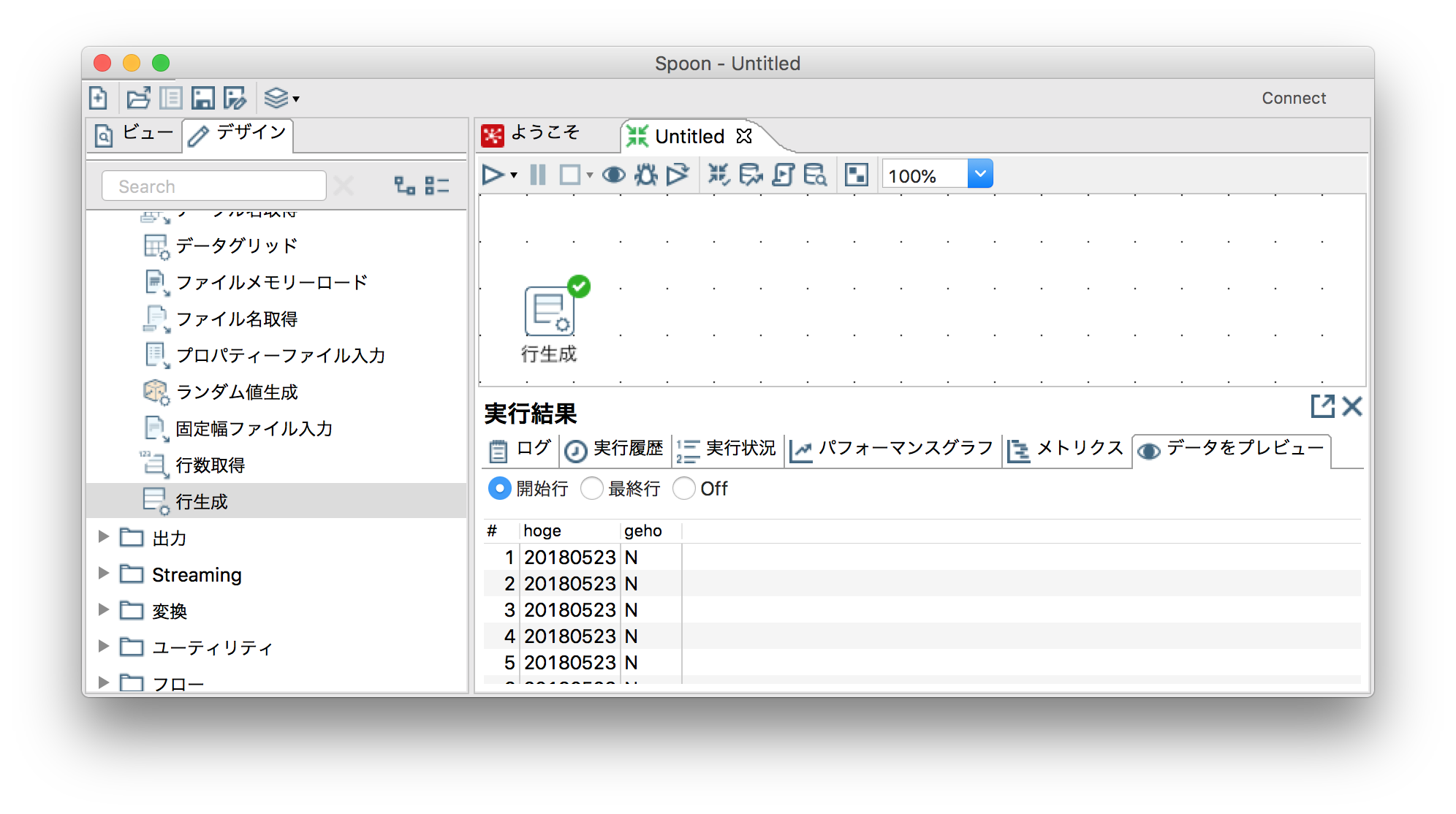
データ型を変換する
「変換」ー「選択/名前変更」(のメタ情報)
例として文字列"$100,000"と"$200,000"をそれぞれInteger型に変換して足し算(Integer変換できていること確認)
- 「入力」ー「データグリッド」でvar1およびvar2を生成


- 「変換」ー「選択/名前変更」
 var1, var2ともデータタイプに「Integer」、書式に「$#,###」を指定する。
var1, var2ともデータタイプに「Integer」、書式に「$#,###」を指定する。
- 「変換」ー「計算」
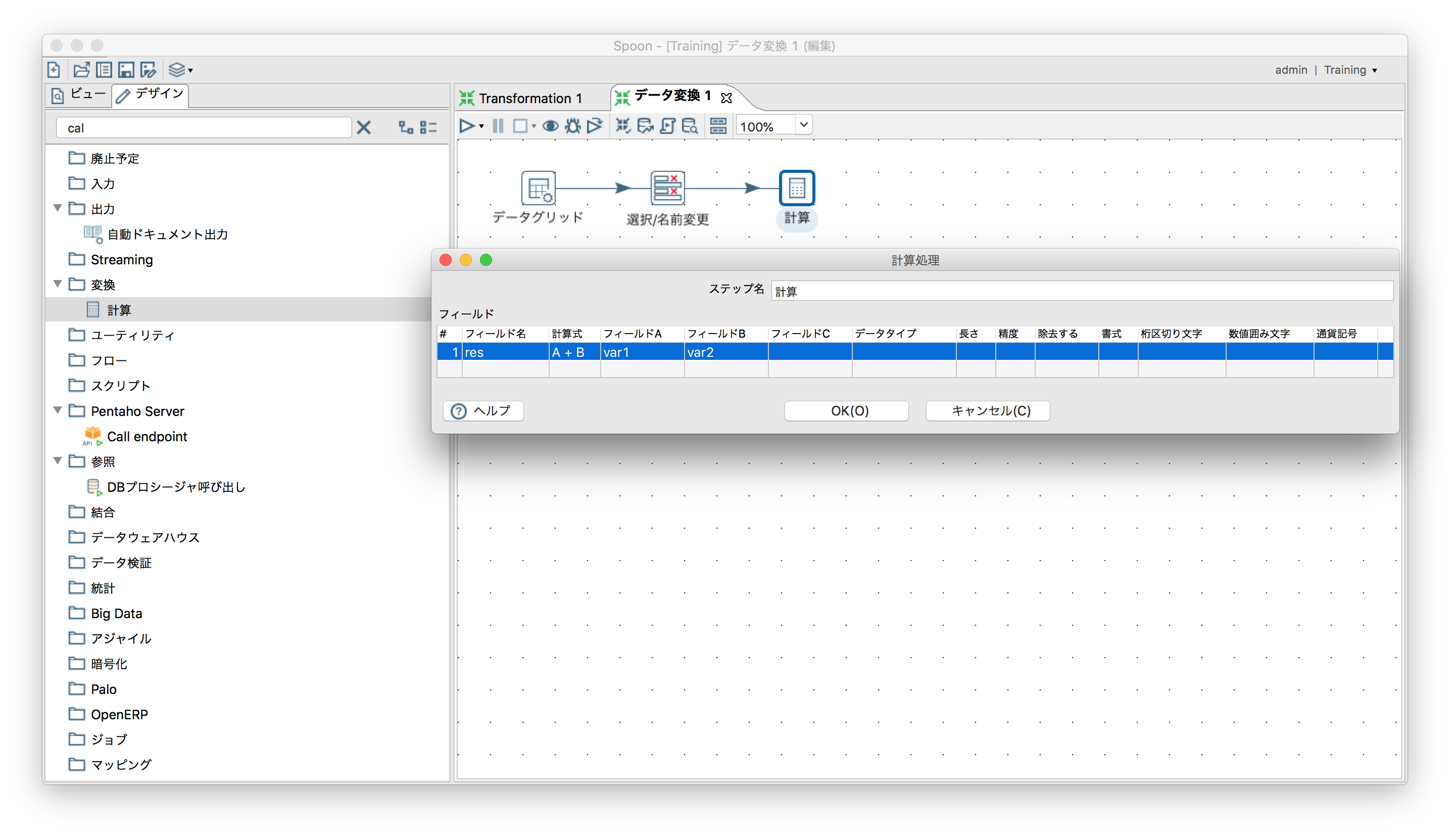 出力フィールド名に任意の名称、計算式に「A + B」、フィールドAおよびBにそれぞれvar1, var2を指定。
出力フィールド名に任意の名称、計算式に「A + B」、フィールドAおよびBにそれぞれvar1, var2を指定。
- 実行結果
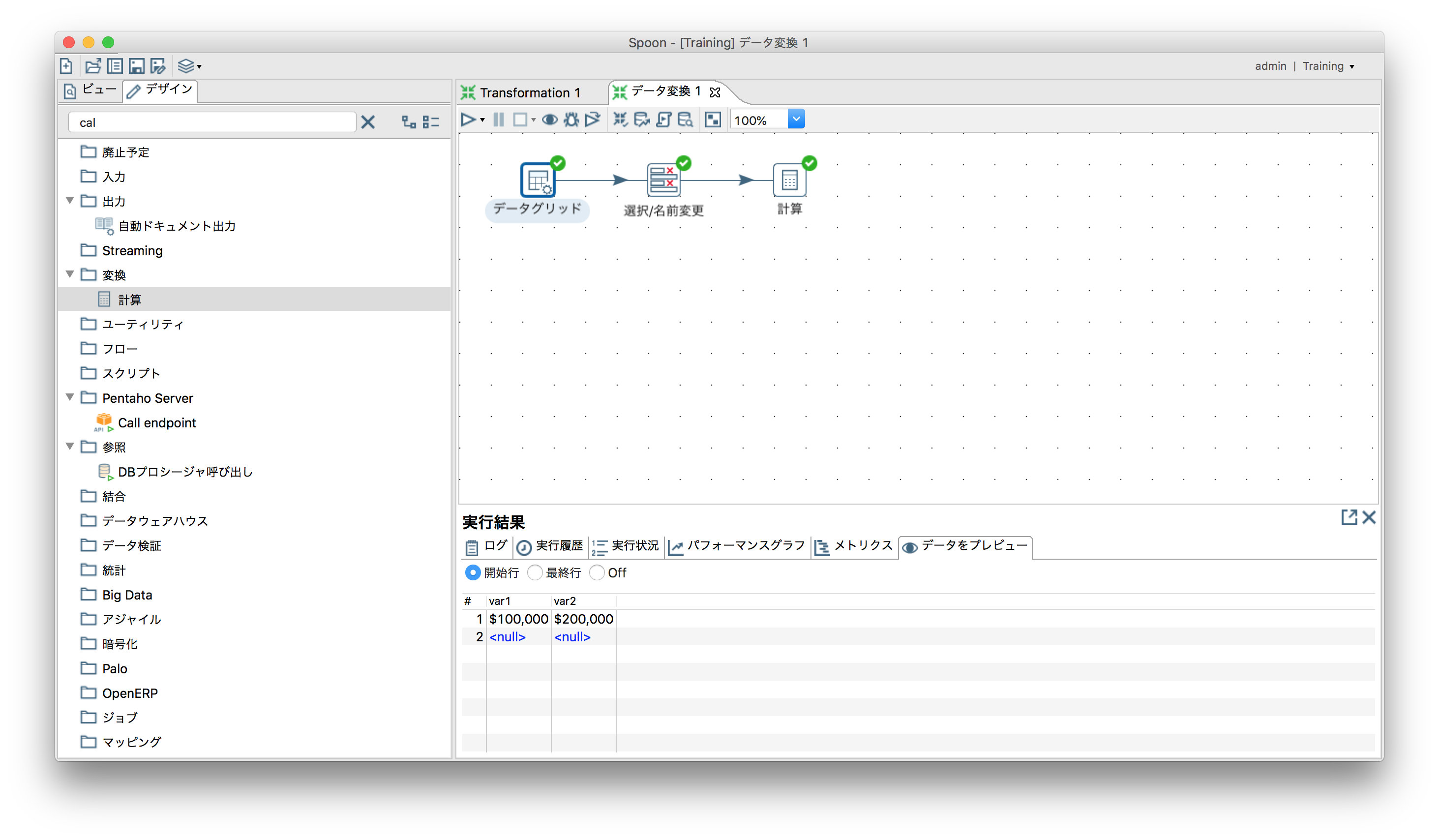
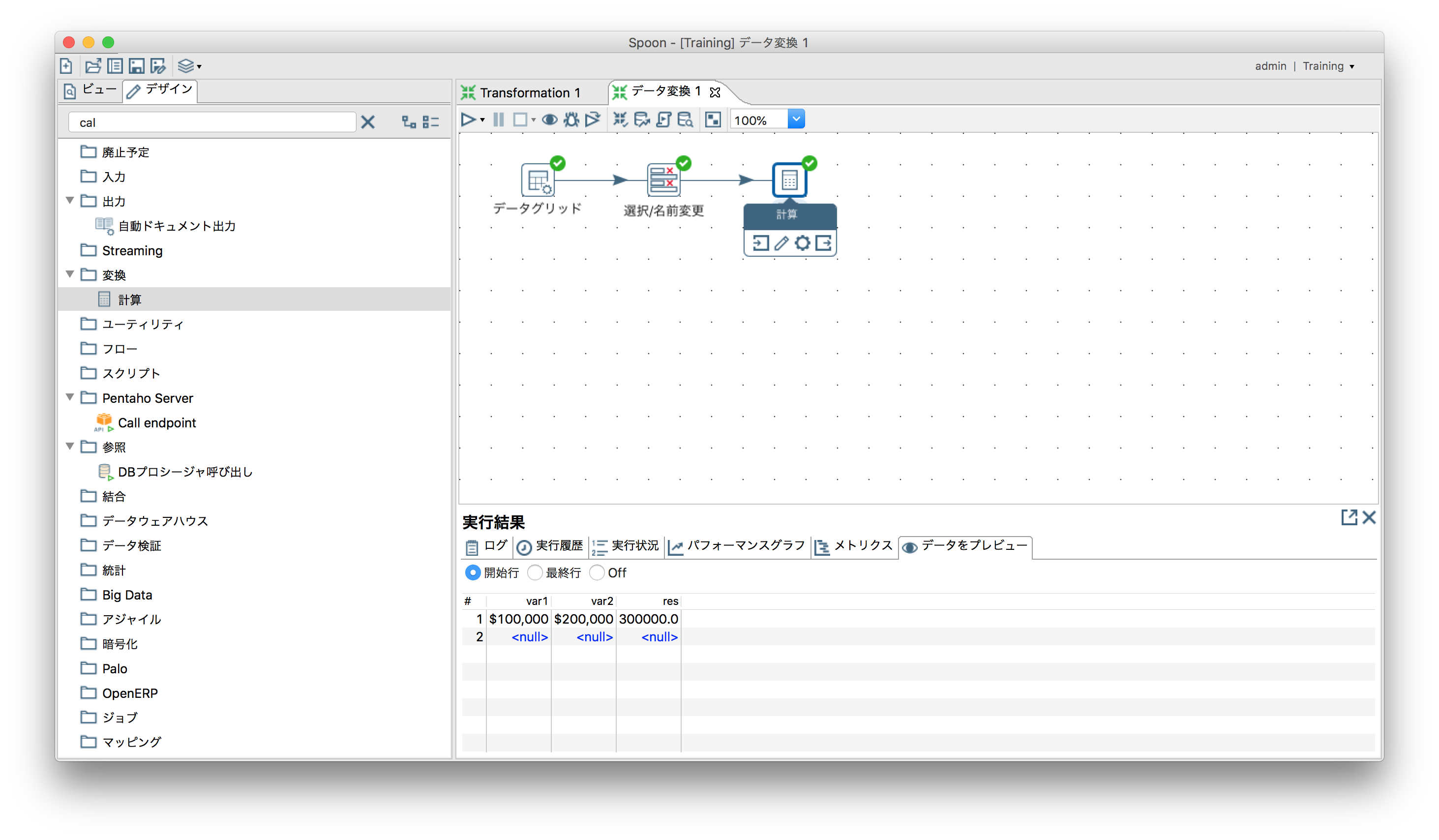
resに"300,000"が計算されている。
正規表現で一致パターンのみ抽出する
「スクリプト」ー「正規表現」
例として日付文字列「YYYY/MM/DD HH:MM:SS.mm」から日付の「DD」のみを取り出す場合
- 「入力」ー「システムデータ」でシステム日付を"var"として生成

- 正規表現
 結果フィールドは正規表現にマッチしたらTrue(Y)、しなかったらFalse(N)が入る。キャプチャして値を新規フィールドに入れるには、「キャプチャグループにフィールドを作成」にチェックし、フィールドを定義する。キャプチャする正規表現は、一般的な後方参照表現である`(pattern)`となる(参照する部分をカッコで囲む)。
結果フィールドは正規表現にマッチしたらTrue(Y)、しなかったらFalse(N)が入る。キャプチャして値を新規フィールドに入れるには、「キャプチャグループにフィールドを作成」にチェックし、フィールドを定義する。キャプチャする正規表現は、一般的な後方参照表現である`(pattern)`となる(参照する部分をカッコで囲む)。
- 実行結果

 resultに「Y」、dayに「25」が入った。
resultに「Y」、dayに「25」が入った。
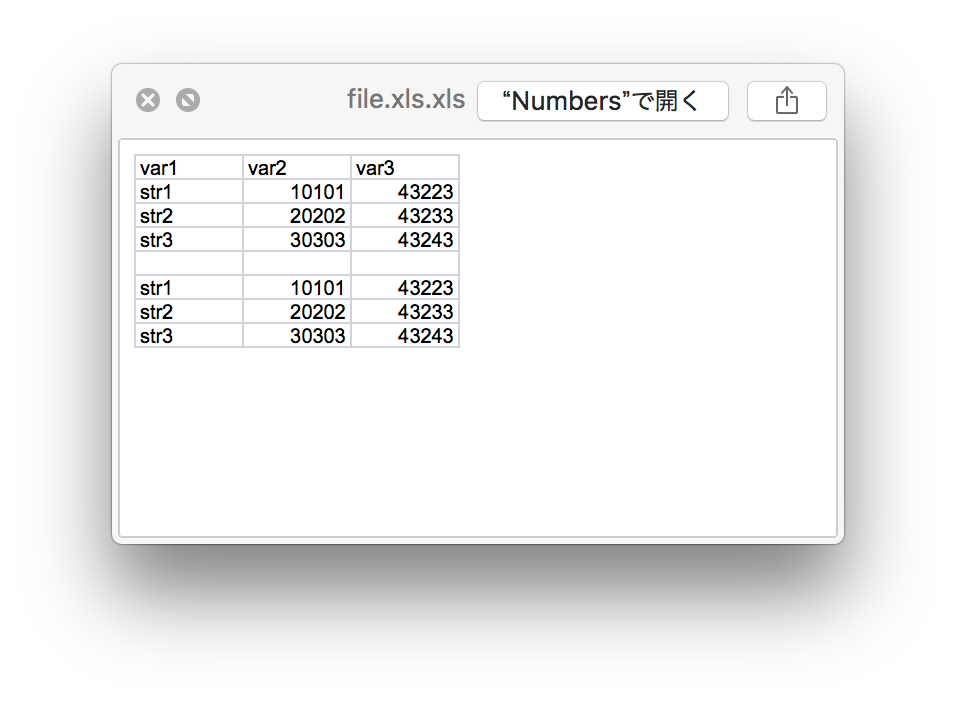
テキストの繰返しデータを行列データへ変換する
「変換」ー「行フラット化」
わかりづらい表題だが、例えば以下のようなデータを行列データへ変換する。
var1: var1 value1
var2: var2 value1
var3: var3 value1
var1: var1 value2
var2: var2 value2
var3: var3 value2
これを、
| var1 | var2 | var3 |
|---|---|---|
| var1 value1 | var2 value1 | var3 value1 |
| var1 value2 | var2 value2 | var3 value2 |
こうする。
-
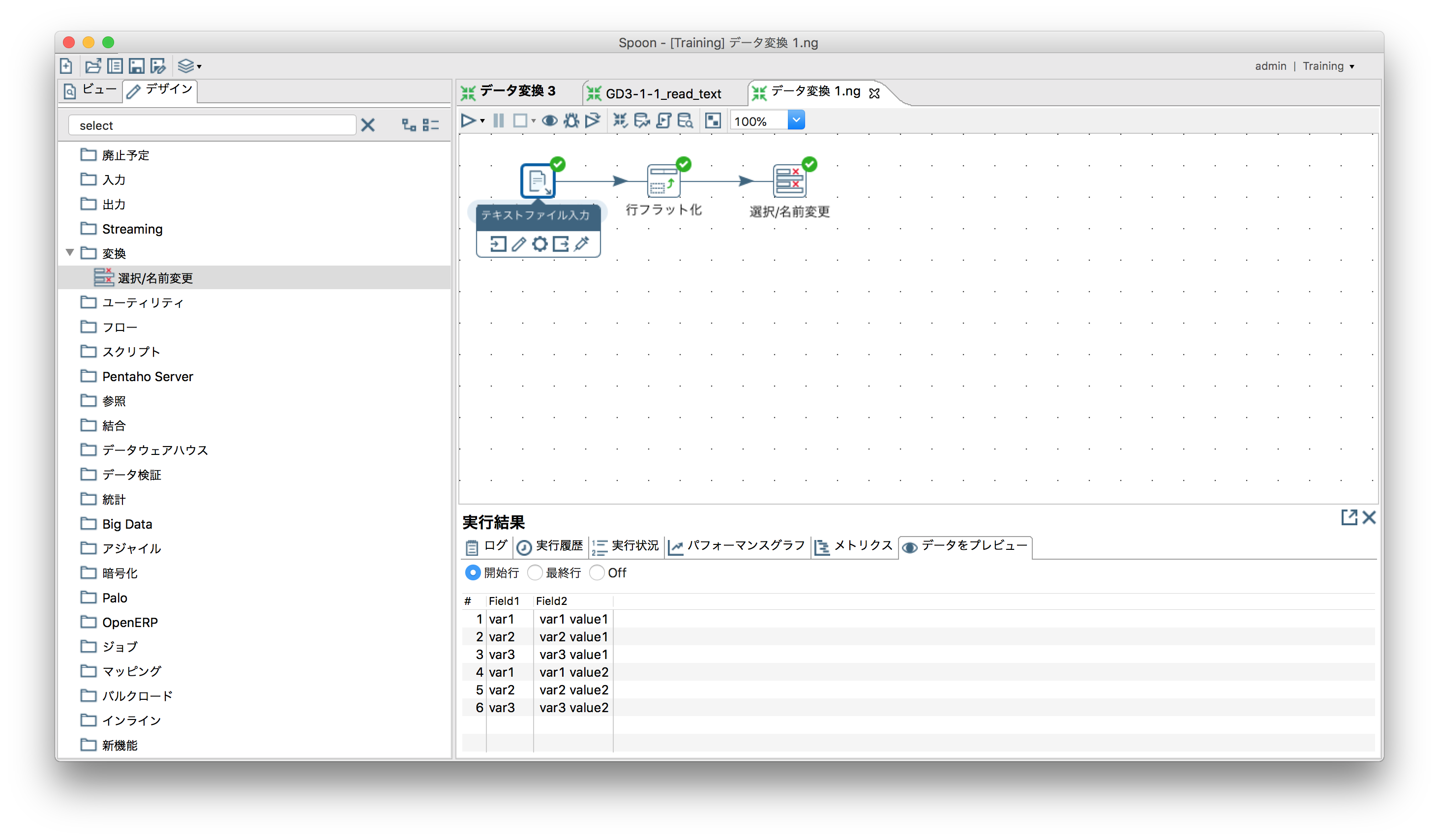
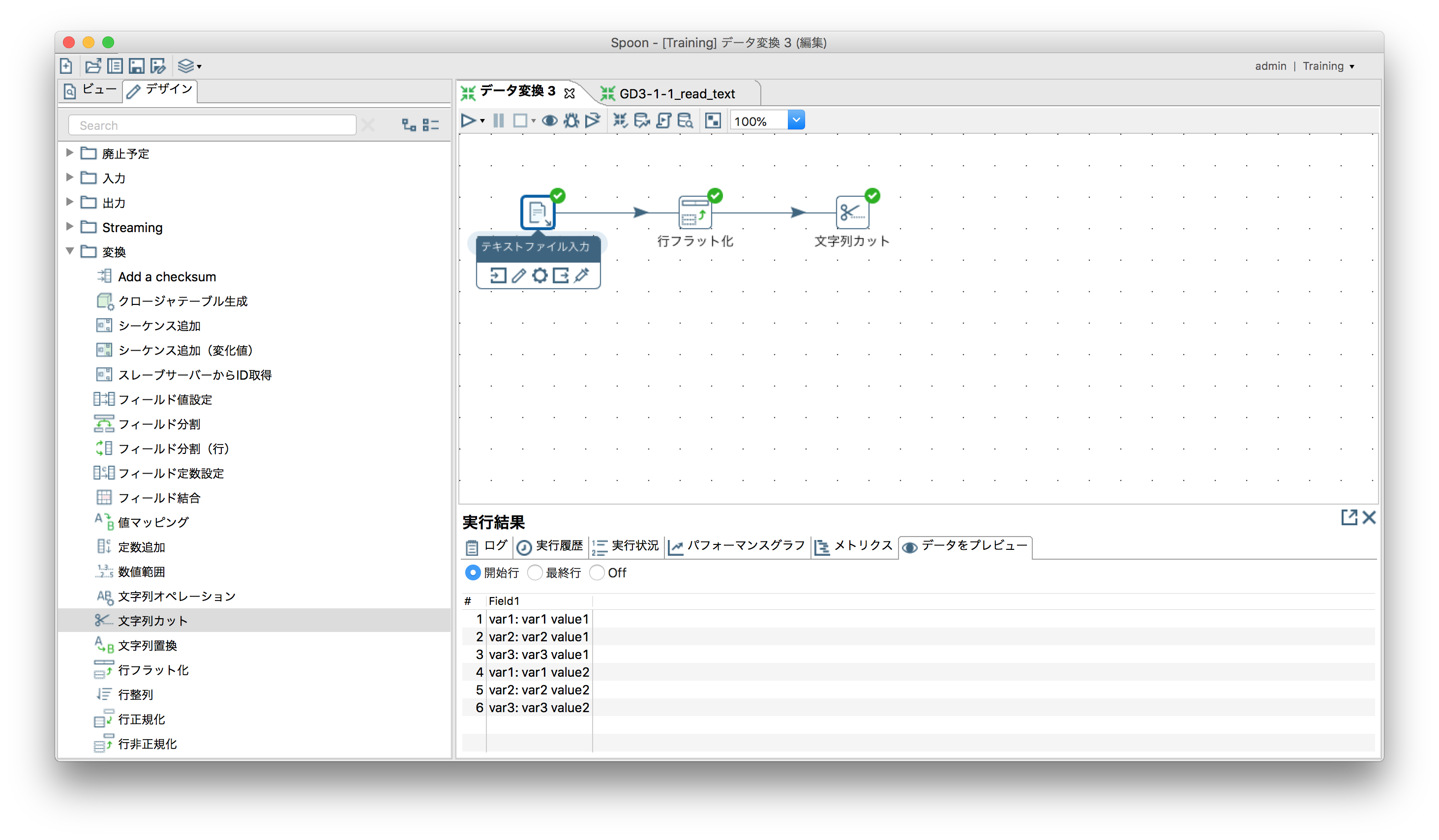
テキストファイルを読込む
-
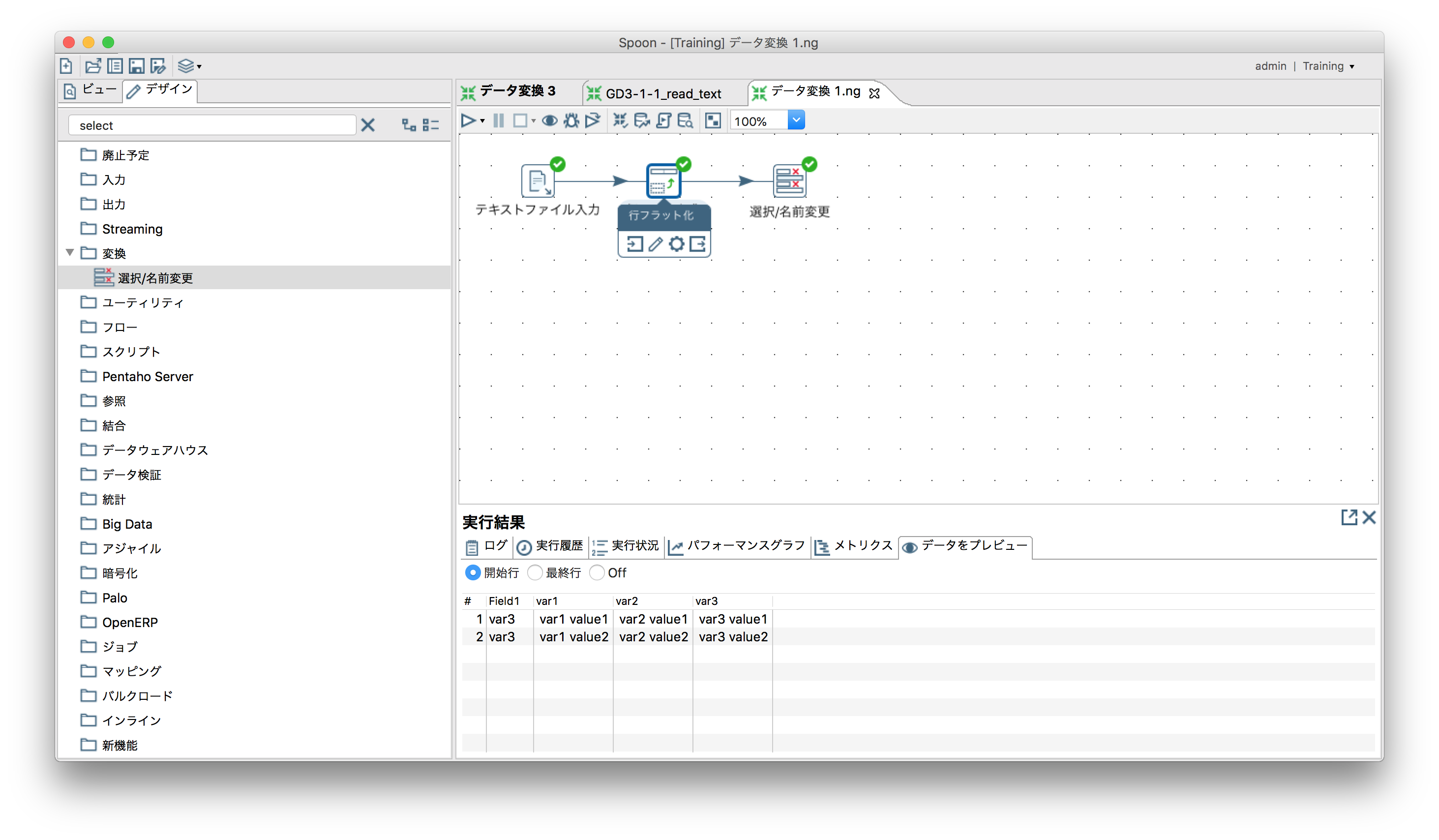
行のフラット化
Field2をvar1,var2,var3としてフラット化。

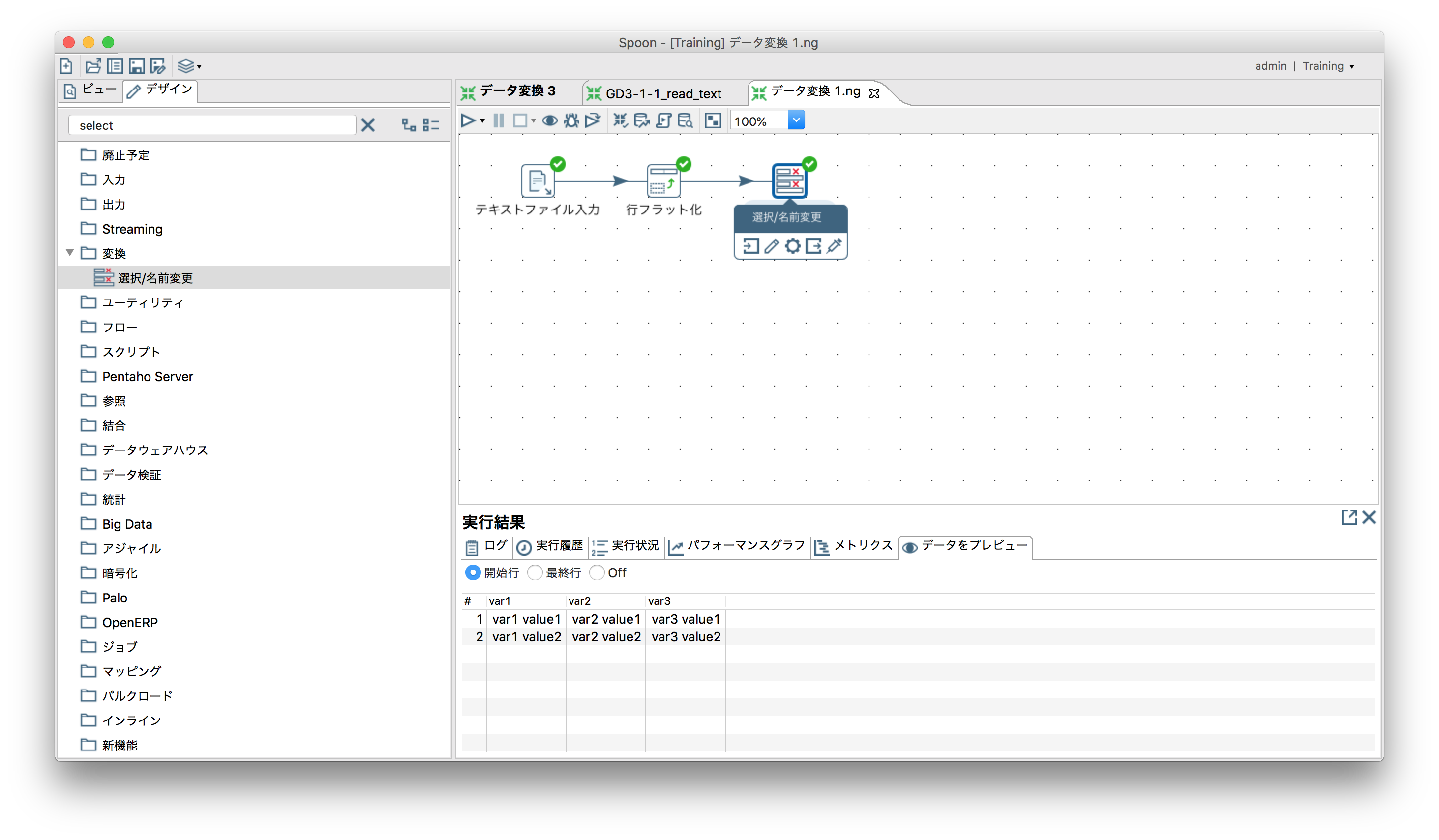
- Field1が残るので「変換」ー「選択/名前変更」で除外。

- 実行結果
または、次のように一旦テキストファイルを1フィールドで読込んで加工する。
- テキストファイルを1フィールドで読込む
 実際はカンマ区切りだがフィールド区切り文字をタブ文字等にして1フィールドで出力させる。
実際はカンマ区切りだがフィールド区切り文字をタブ文字等にして1フィールドで出力させる。

-
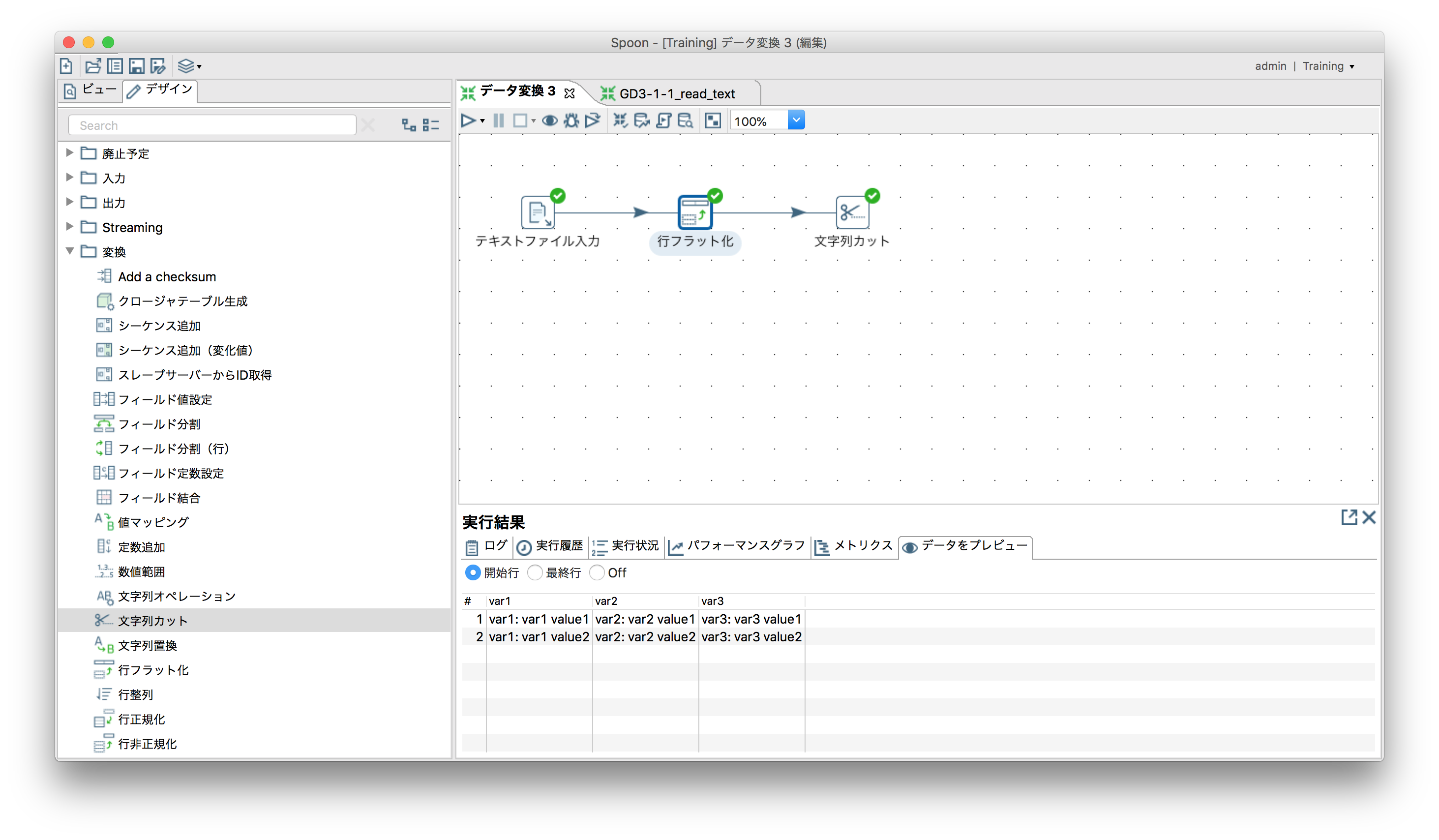
行のフラット化
Field1をvar1,var2,var3としてフラット化。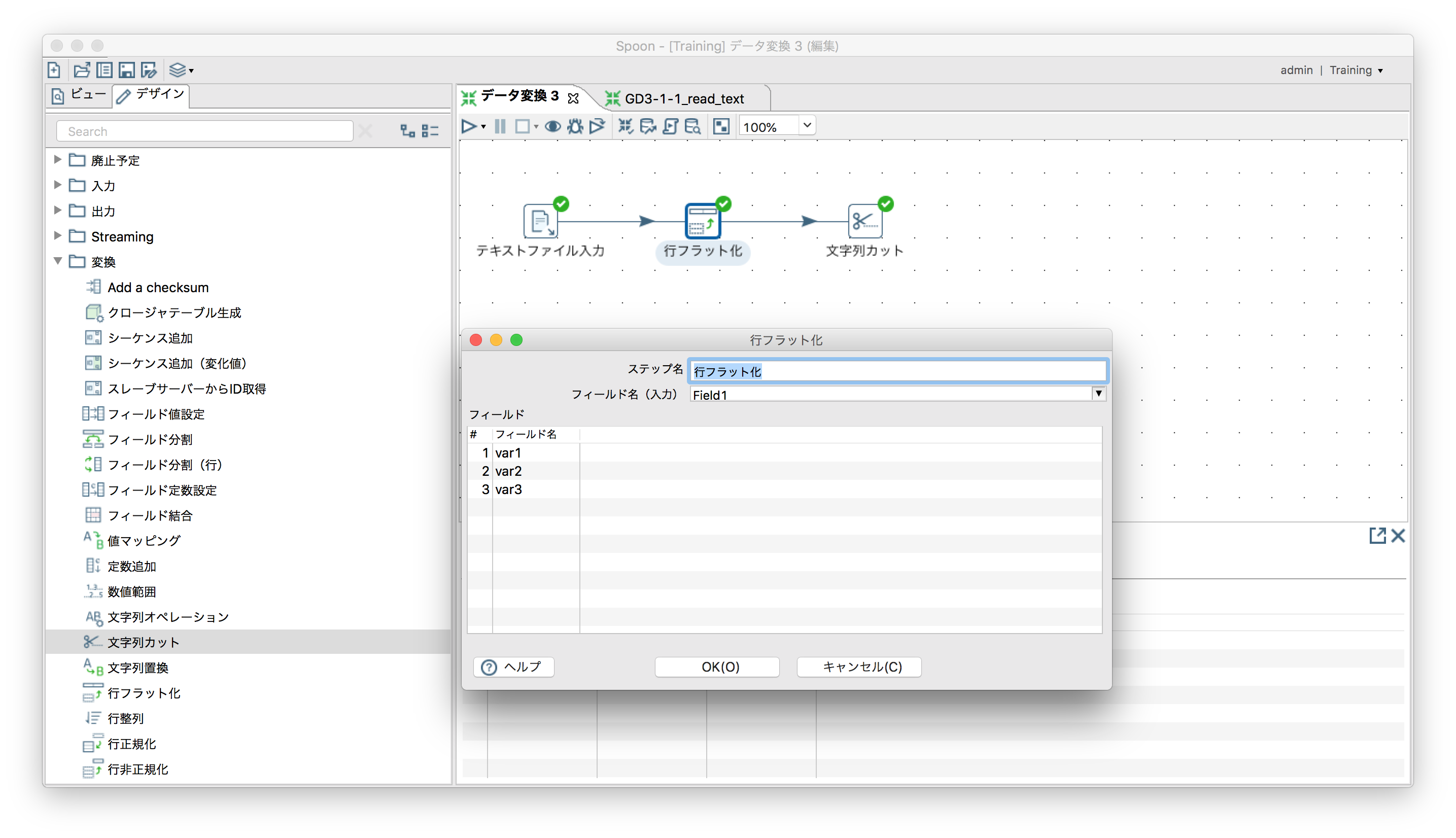
-
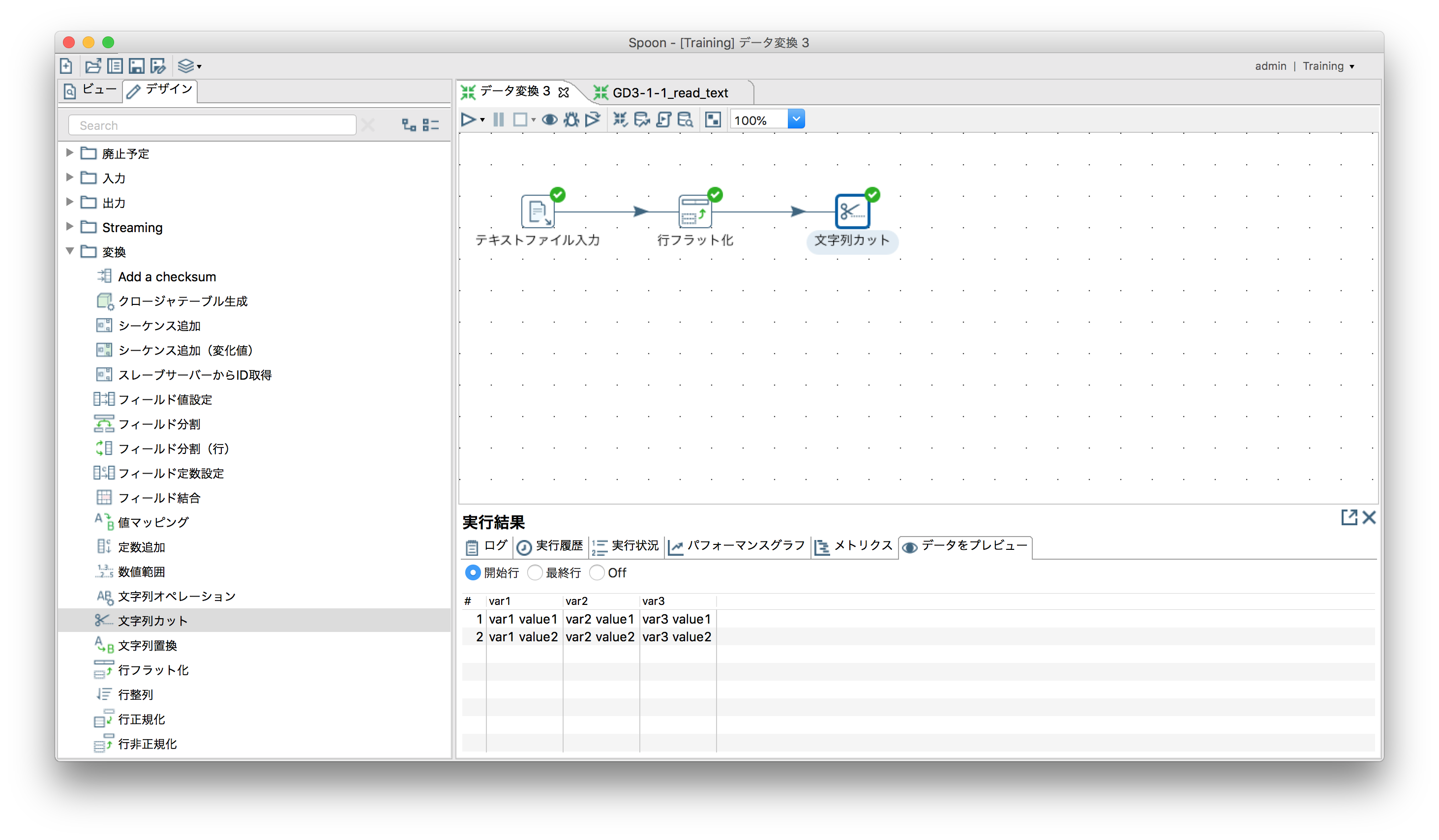
余計な文字をカット
 先頭の"var[1-3]: "6文字はデータとして不要なので、カットする。文字列カットは終点も固定値で指定しないといけないようなので、ここに入力したよりも長いデータが入るとデータが切れてしまう。。。あまり美しくないが今の所はこれでよしとする。
先頭の"var[1-3]: "6文字はデータとして不要なので、カットする。文字列カットは終点も固定値で指定しないといけないようなので、ここに入力したよりも長いデータが入るとデータが切れてしまう。。。あまり美しくないが今の所はこれでよしとする。
- 実行結果
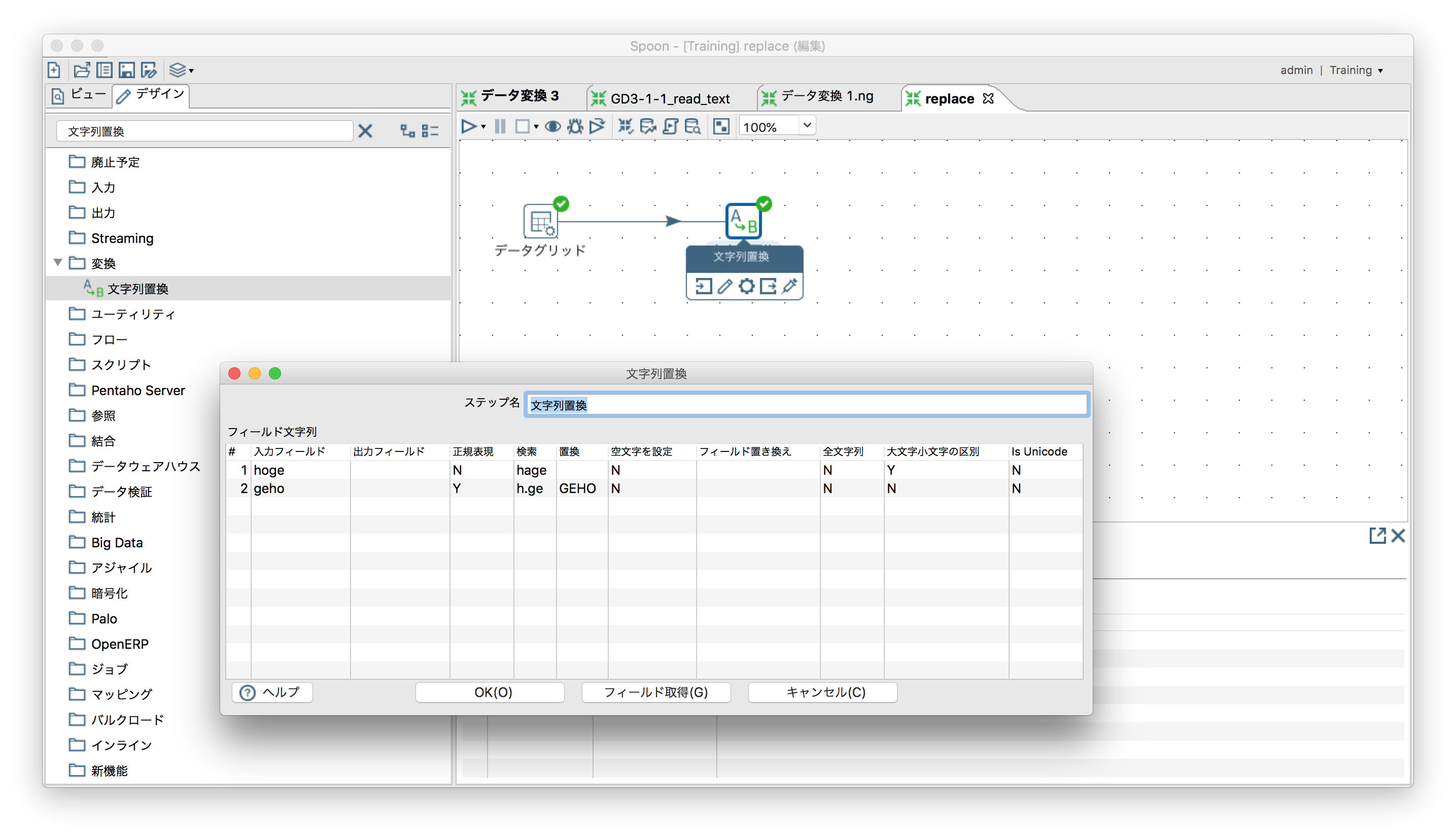
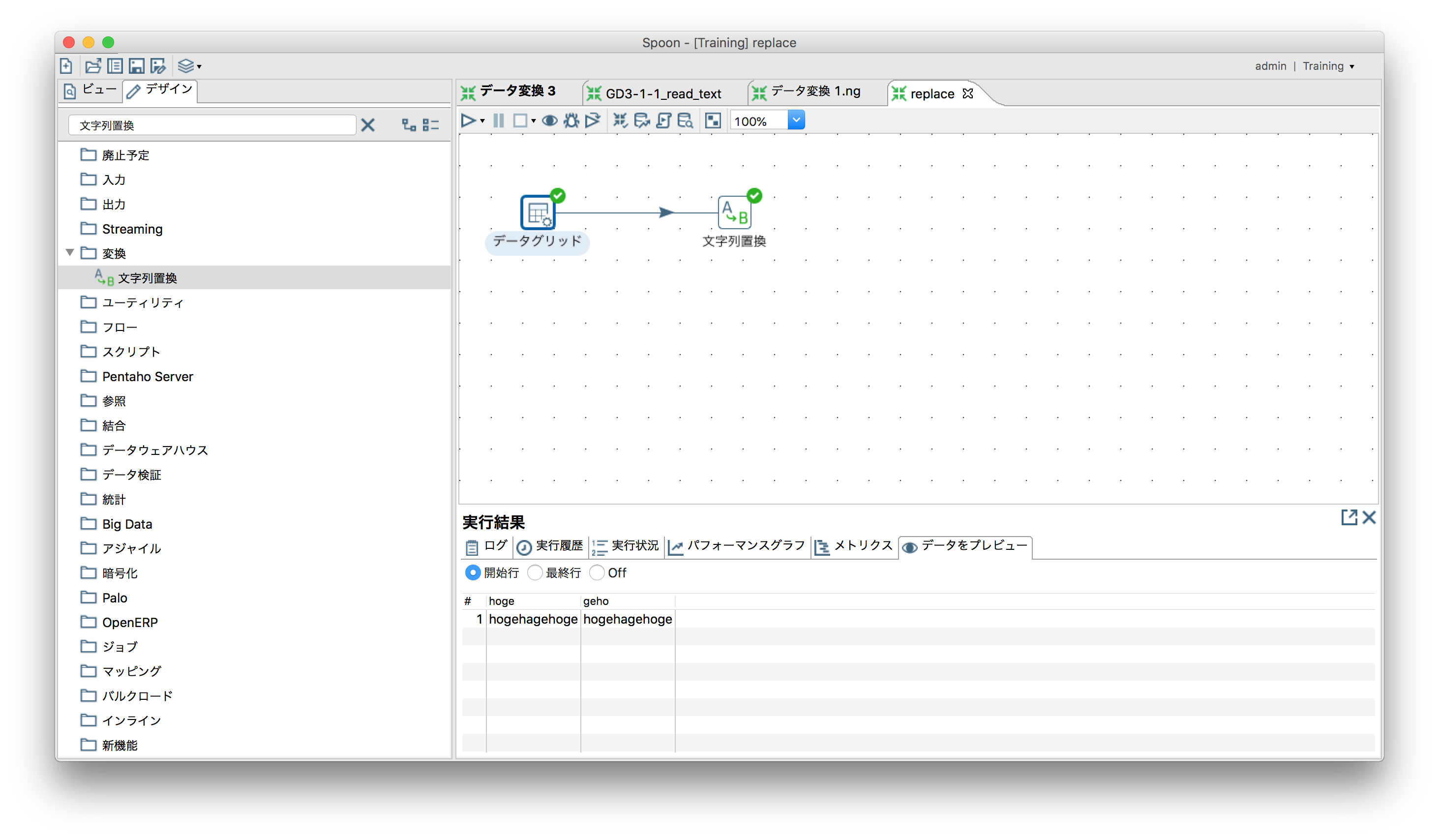
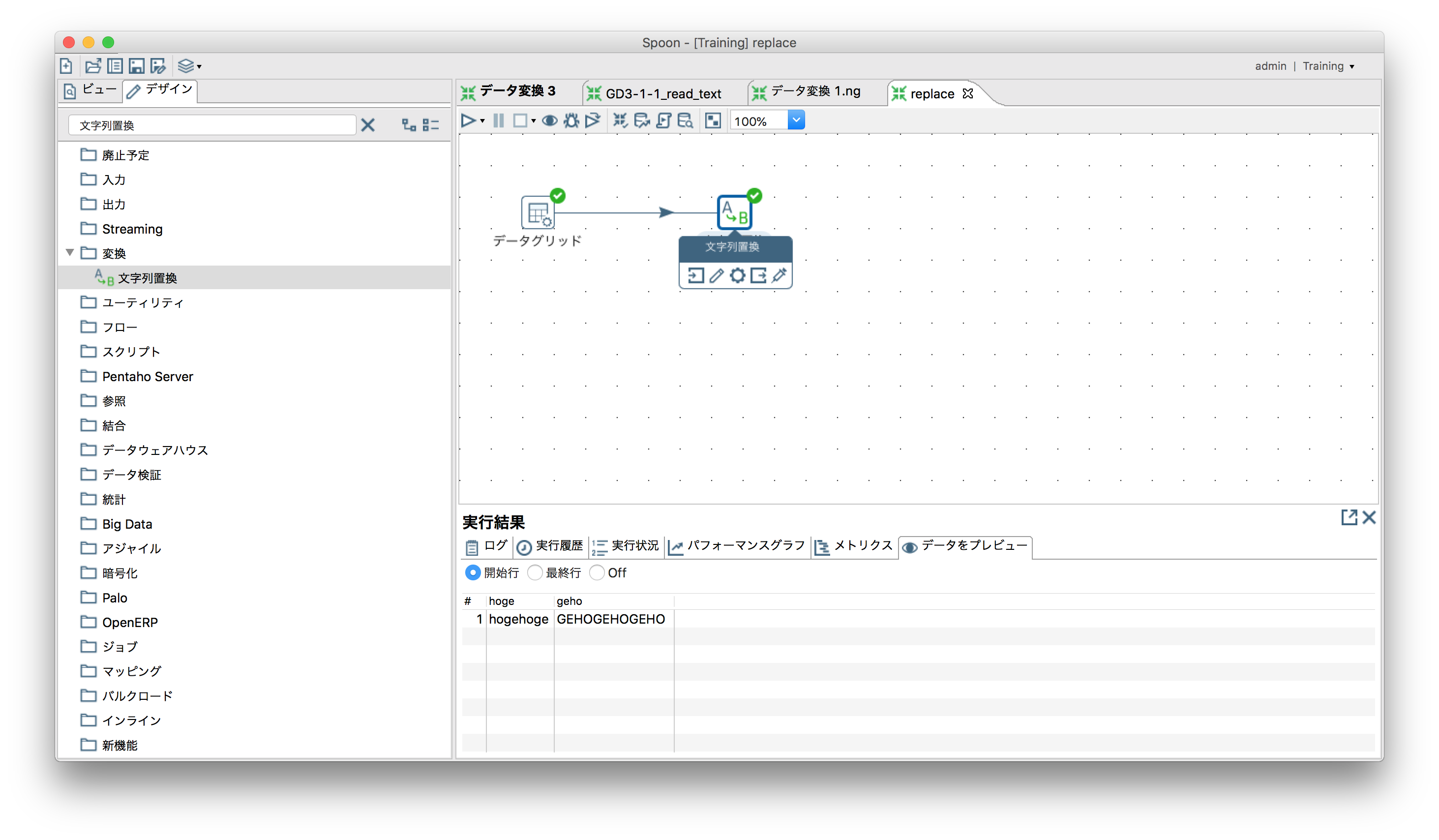
文字列置換
「変換」ー「文字列置換」(正規表現も使用可能)
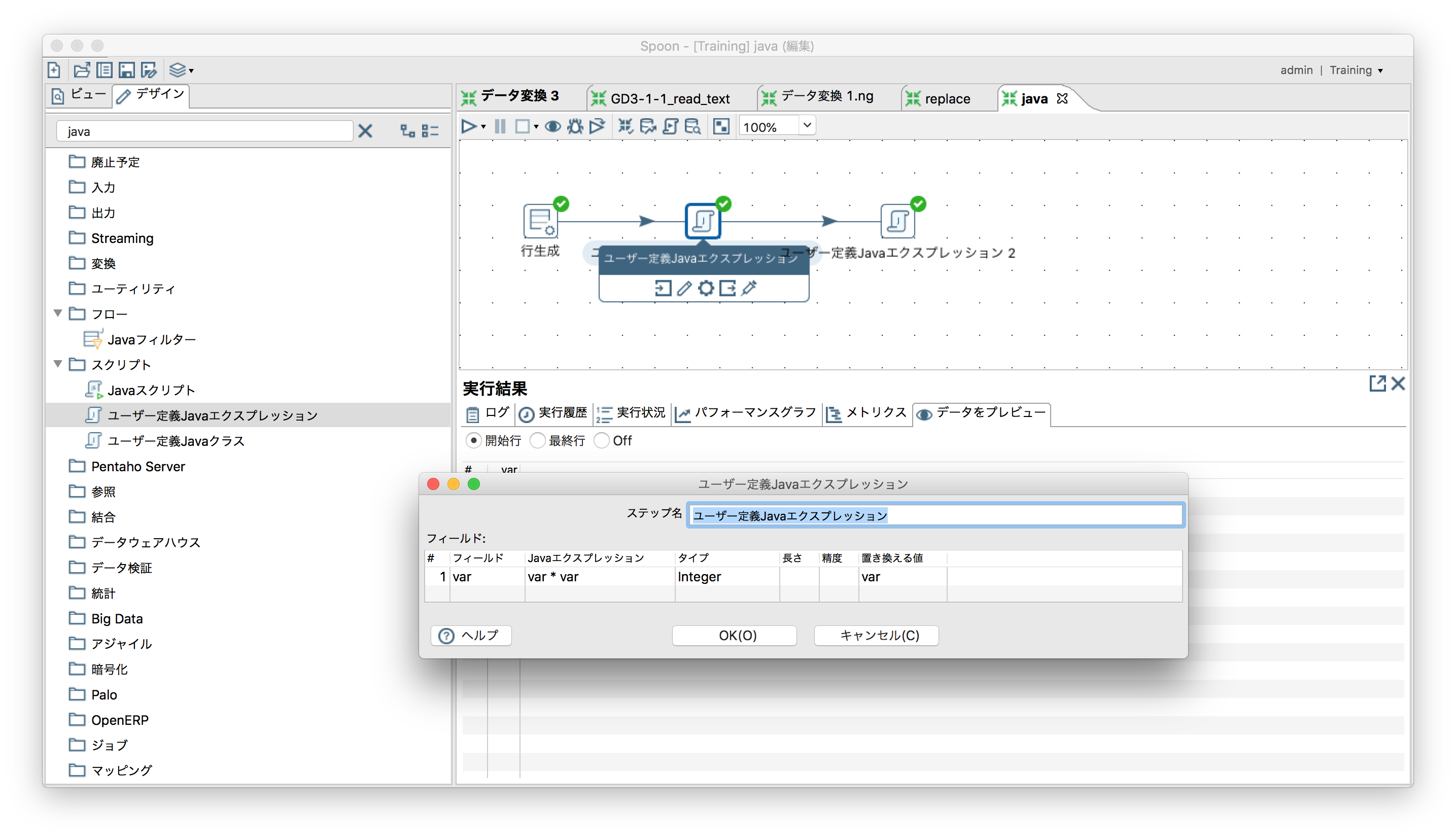
Javaのワンライナーでデータを加工
「スクリプト」ー「ユーザー定義Javaエクスプレッション」
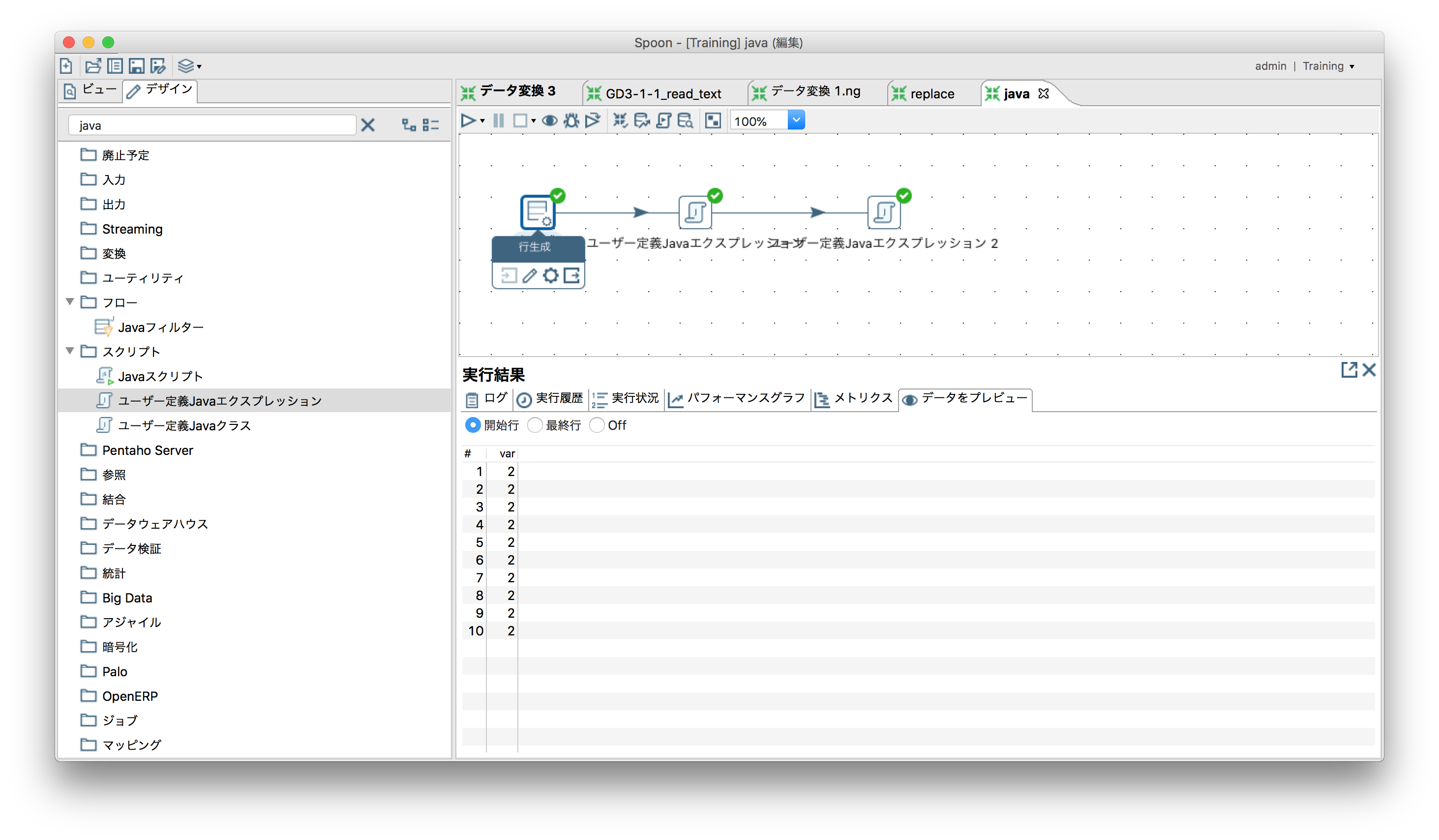
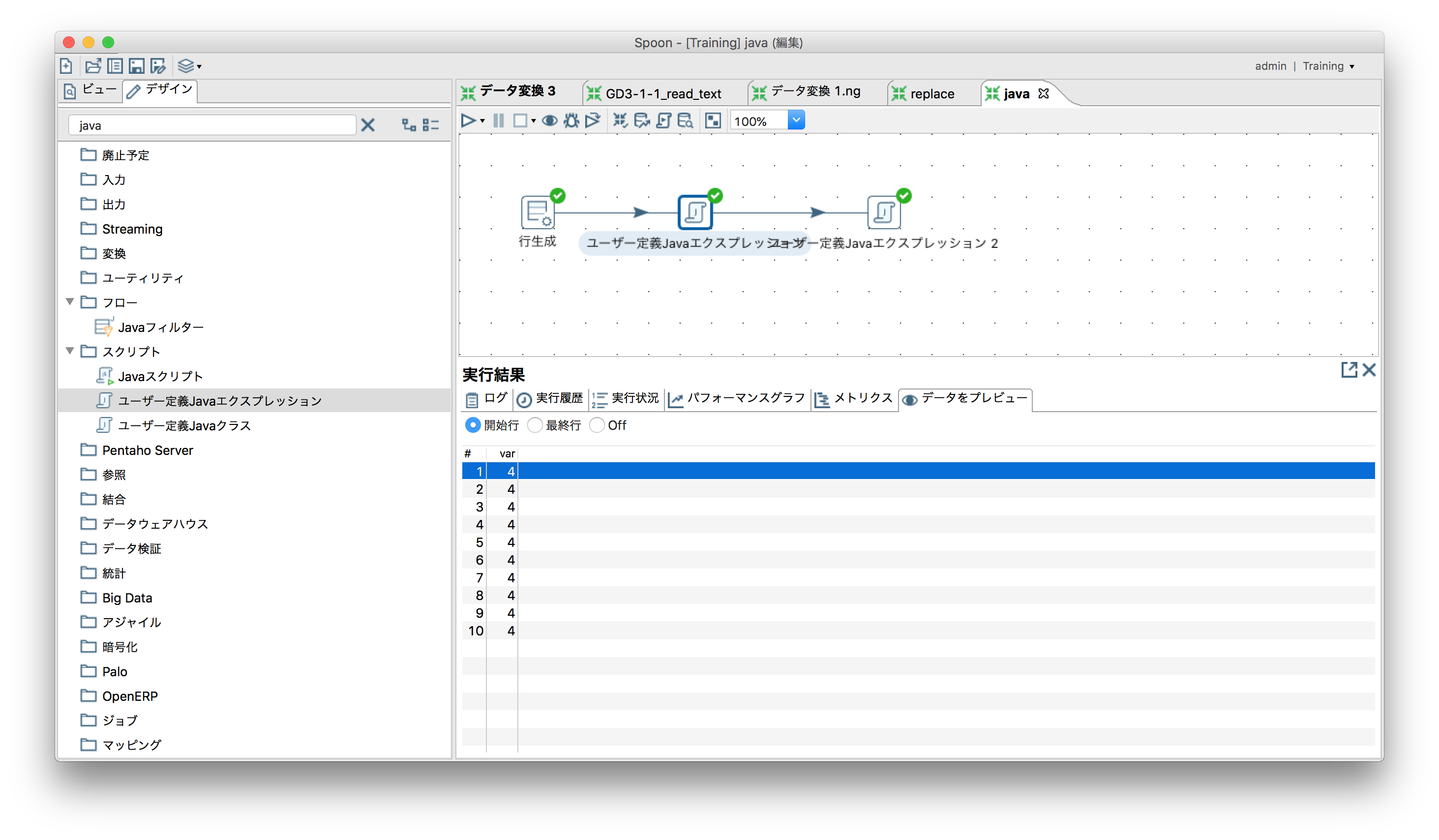
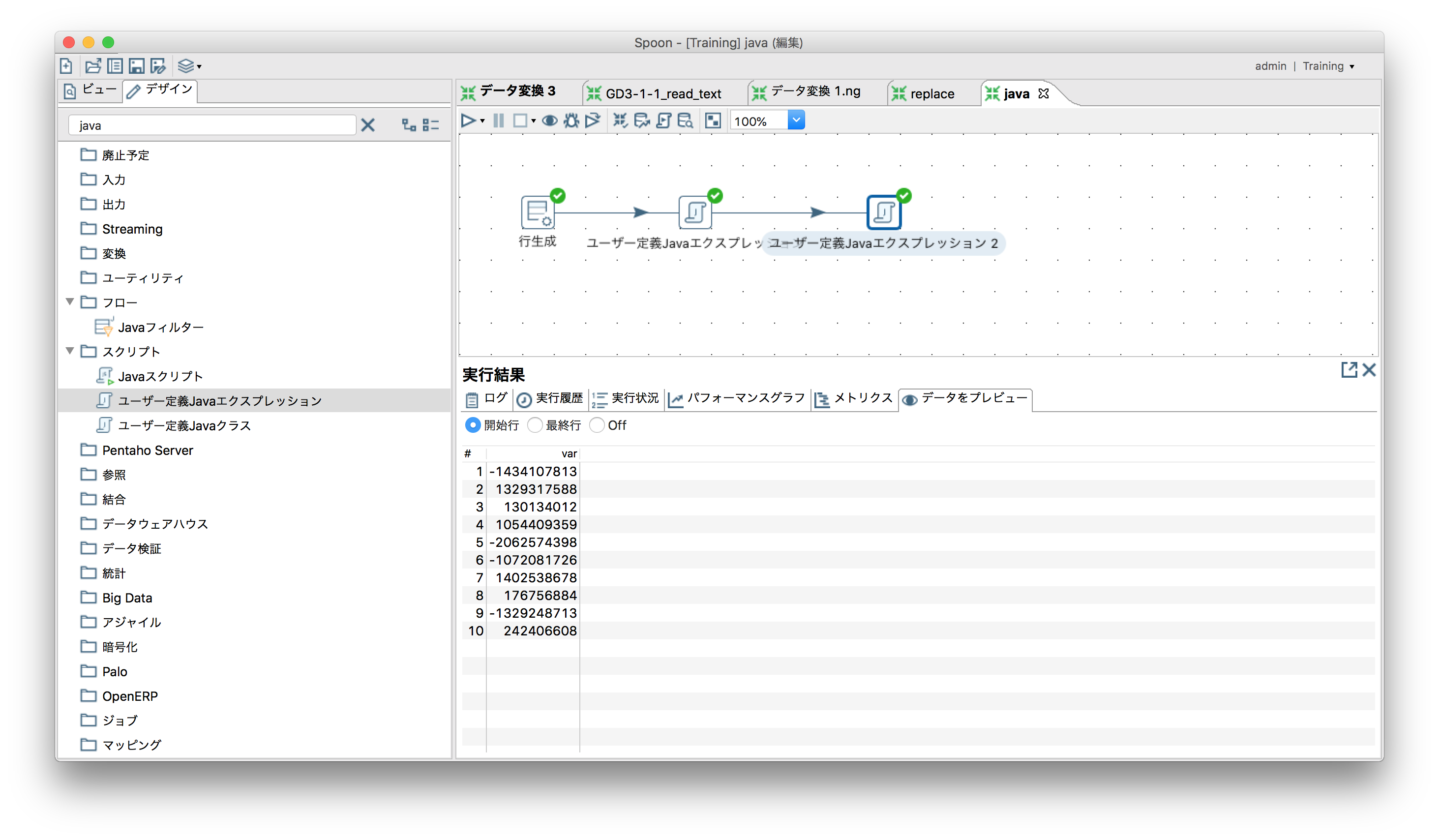
データをつなげる
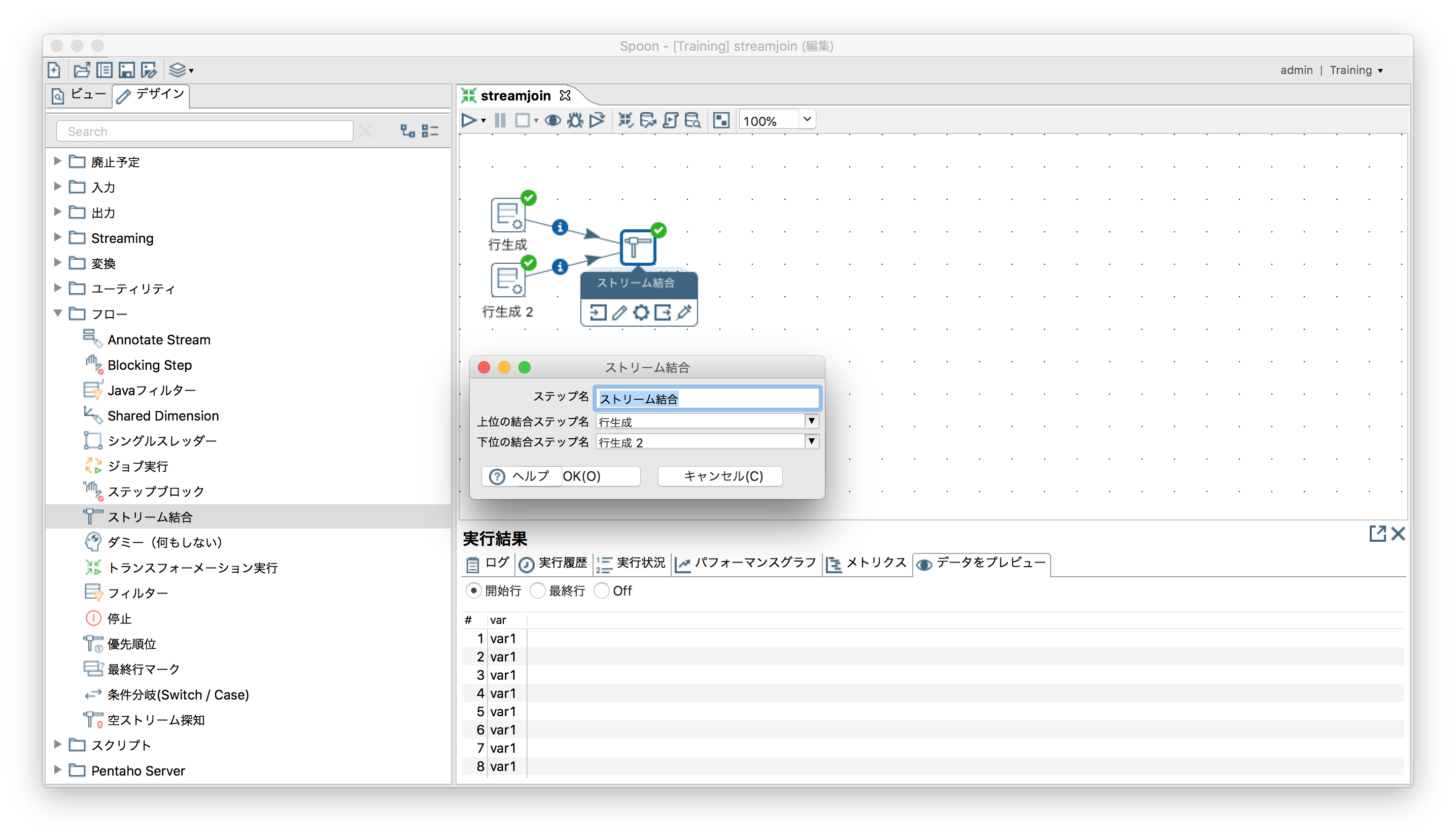
「フロー」ー「ストリーム結合」
Excelに出力
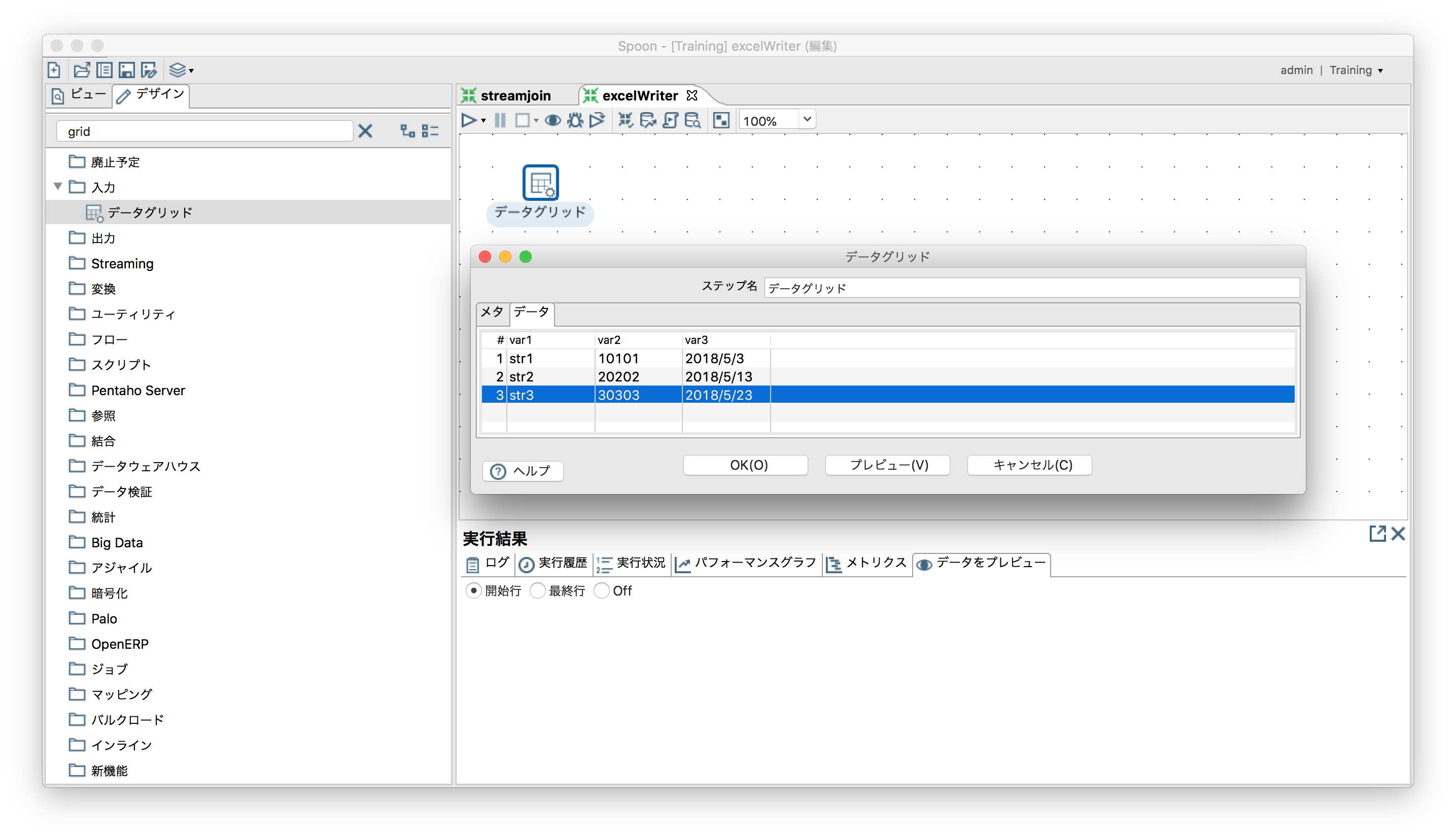
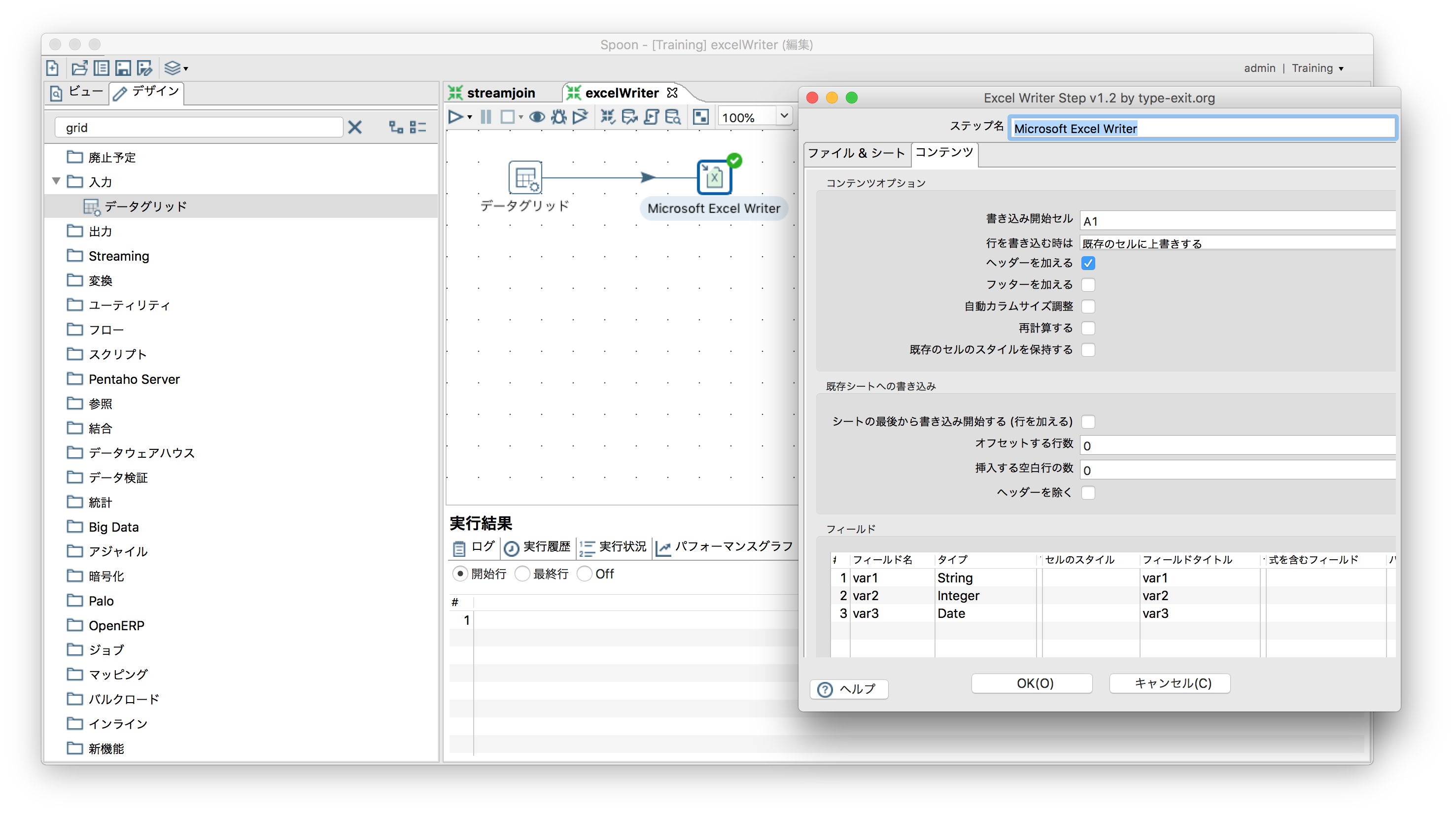
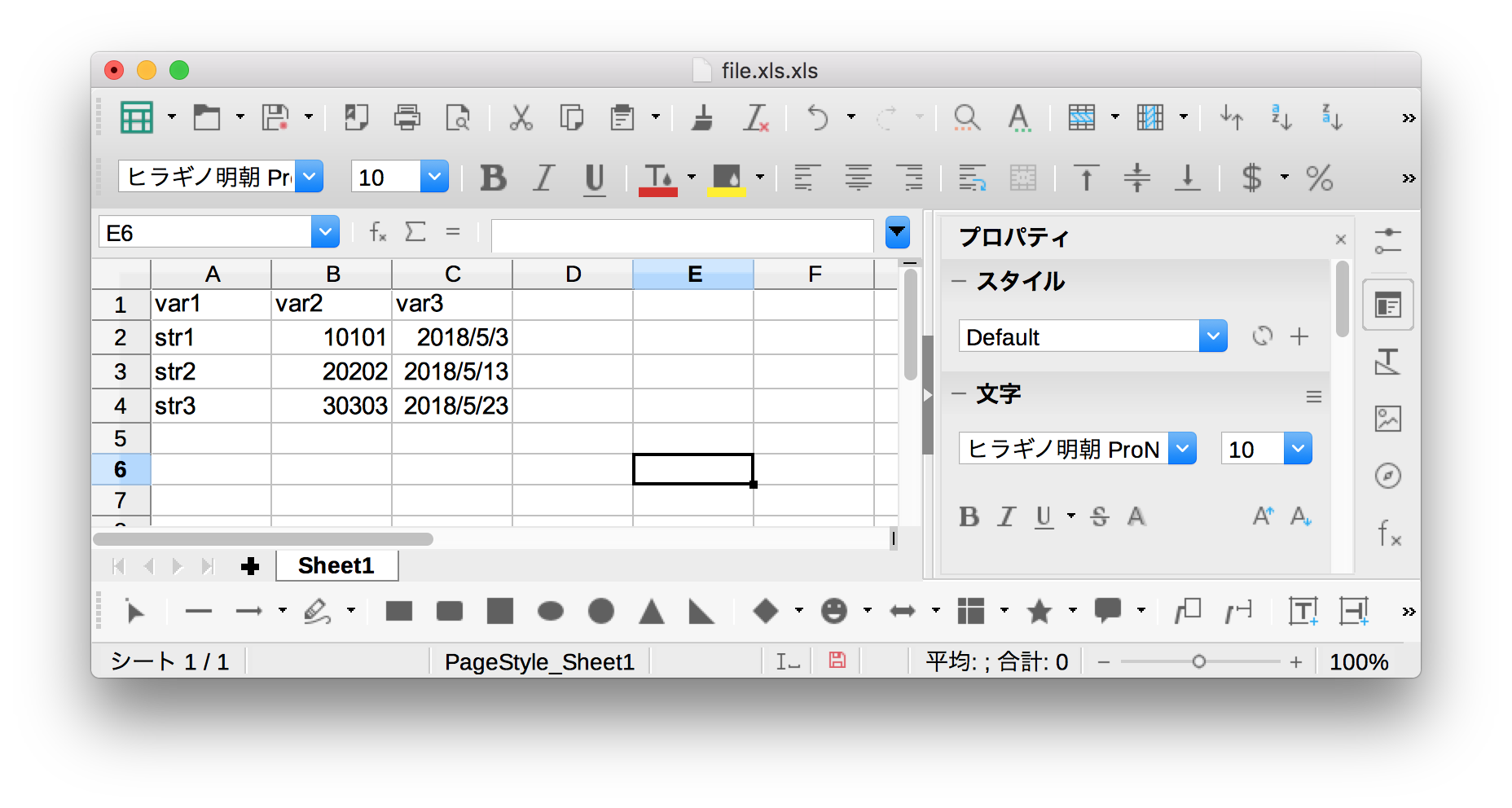
「出力」ー「Microsoft Excel Writer」
ステップ(処理)の同期を取る
「フロー」ー「ステップブロック」
特に同一ファイルへの入出力は自動でロックしてくれないため、指定のステップが終了するまで待つステップを入れる。
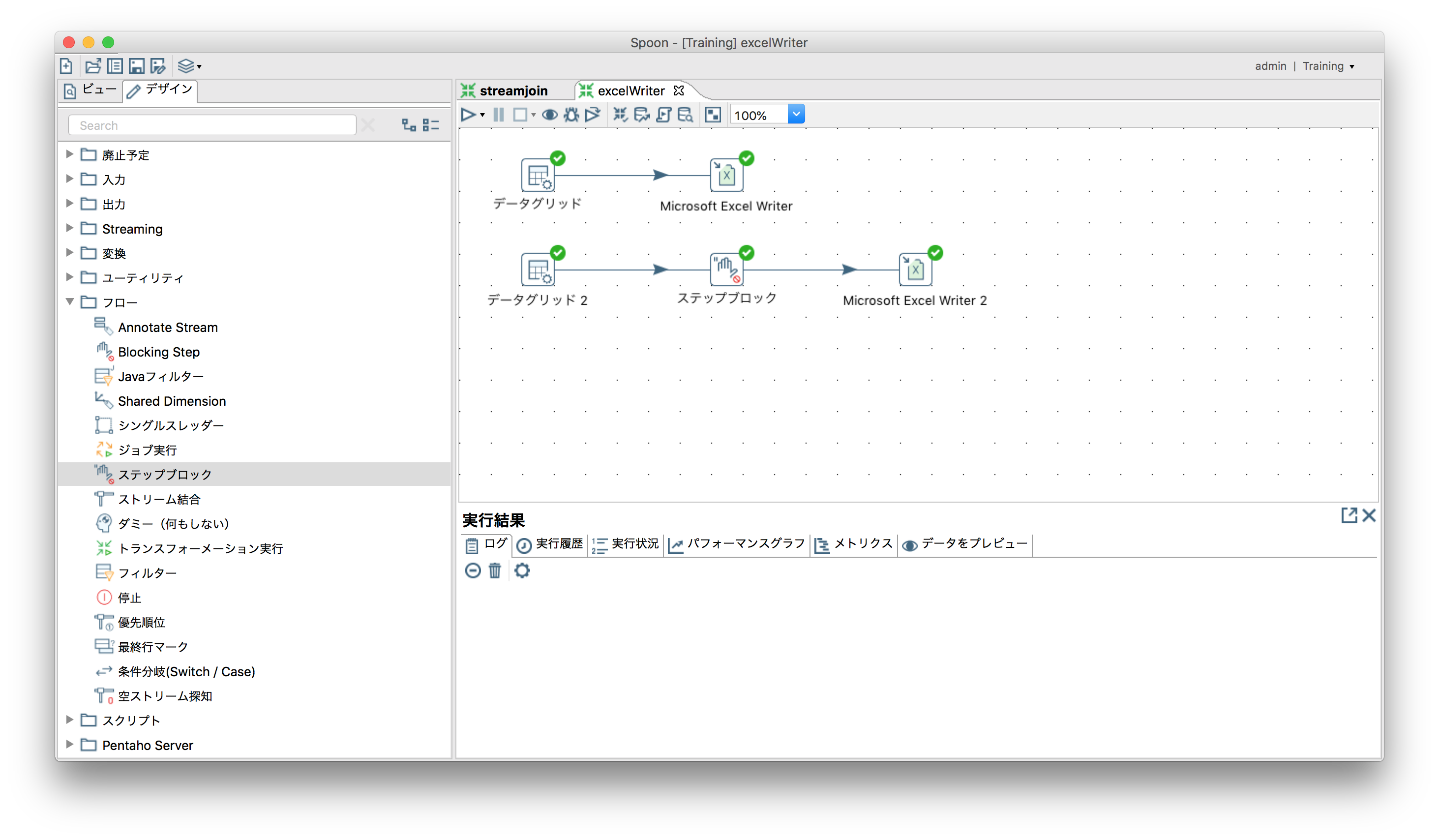
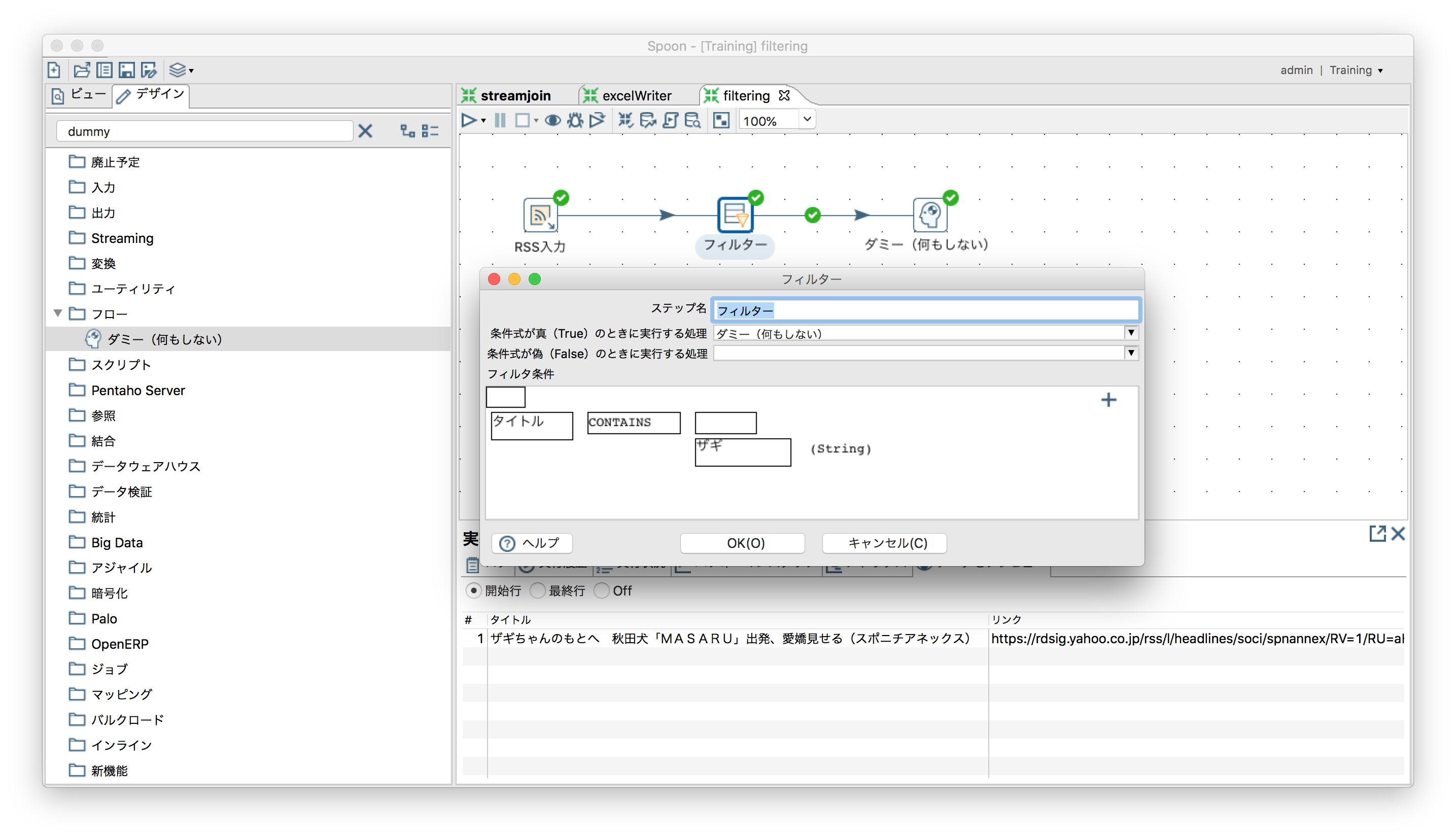
特定の条件を満たすレコード以外を除去する(データのフィルタリング)
「フロー」ー「フィルター」
DBからデータ取得
「入力」ー「テーブル入力」
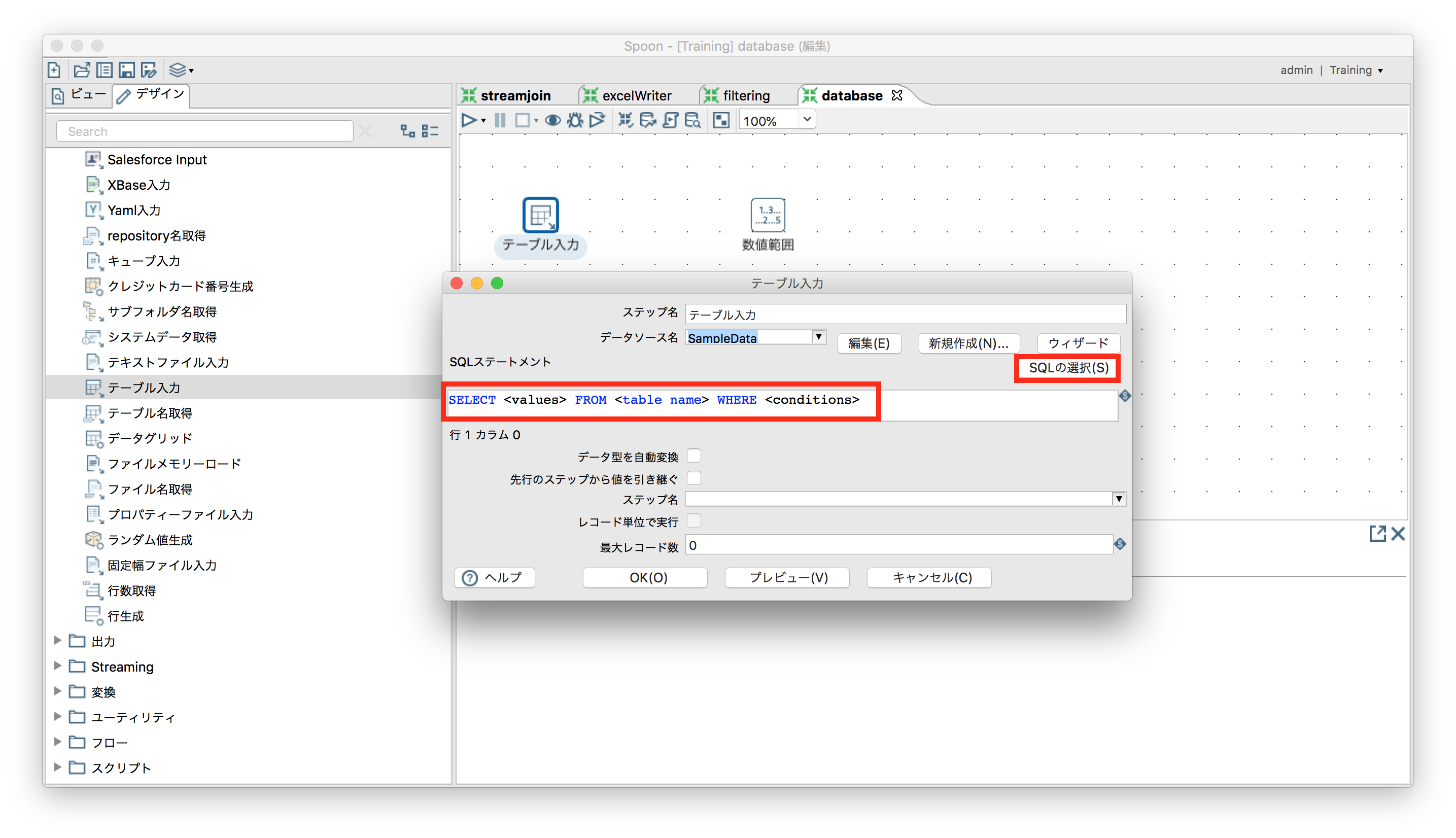
SQL文を自分で書ける。「SQLの選択」から対象テーブルをGUIで選択可能。
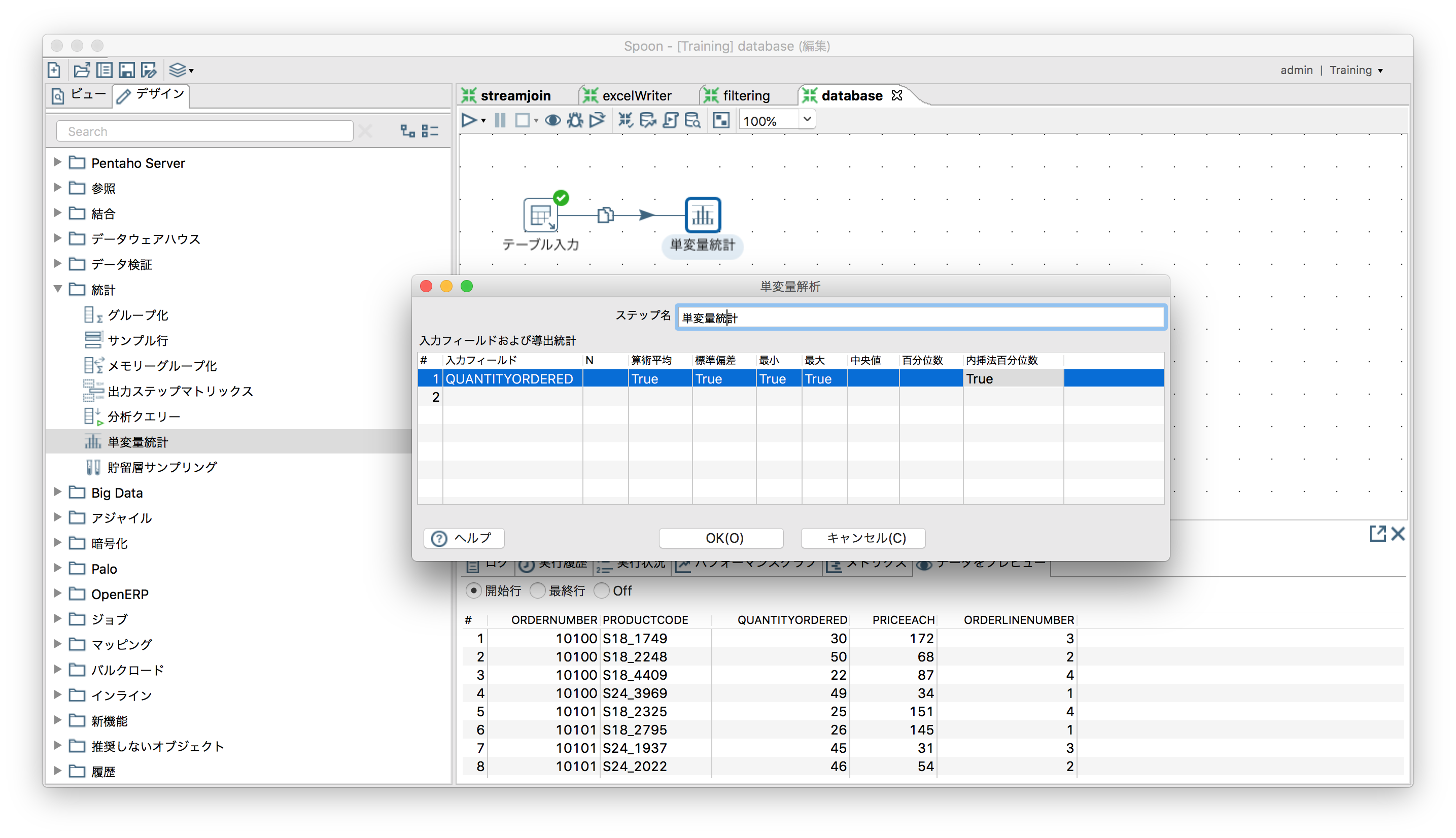
統計分析値の算出
「統計」ー「単変量統計」
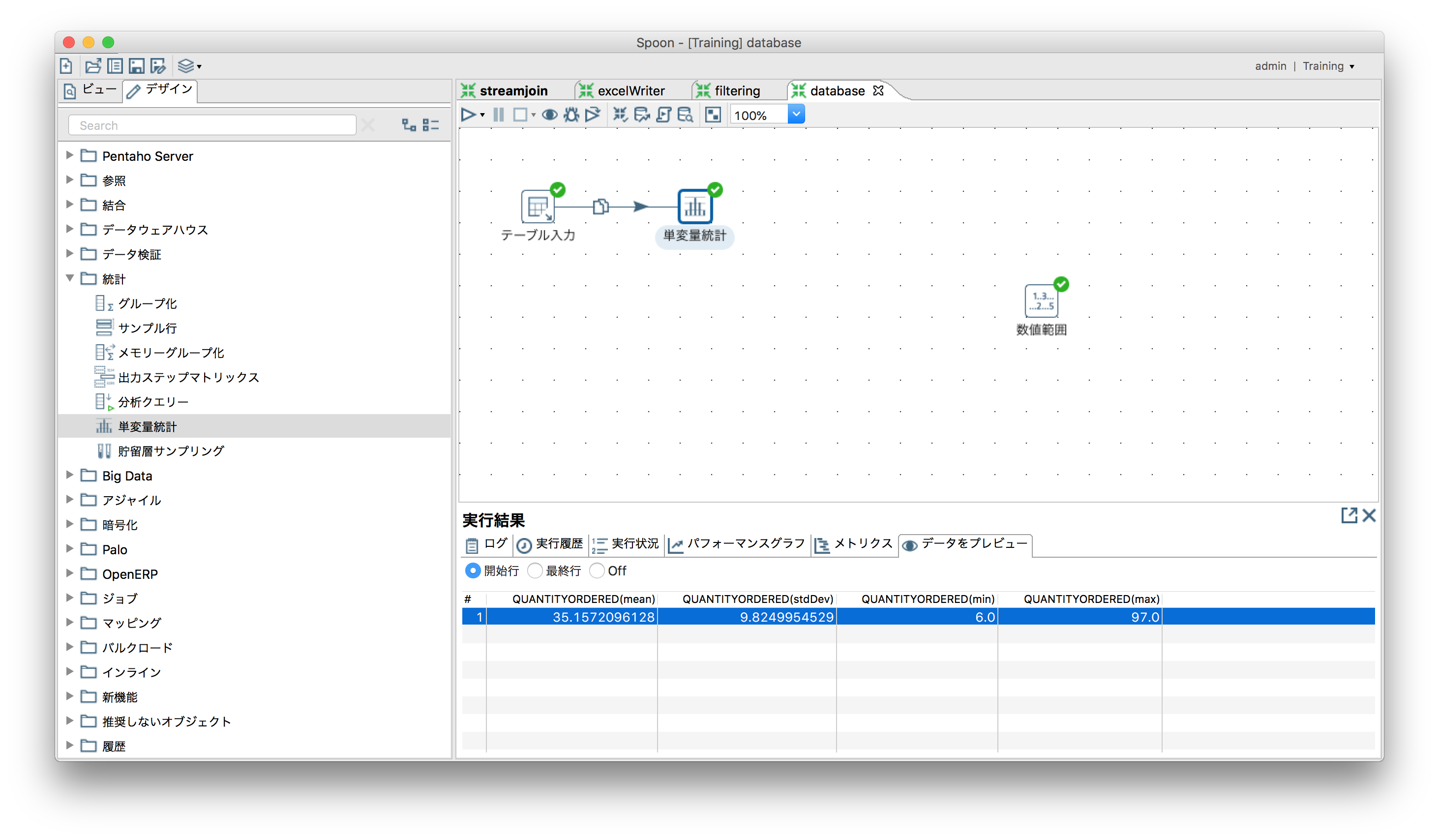
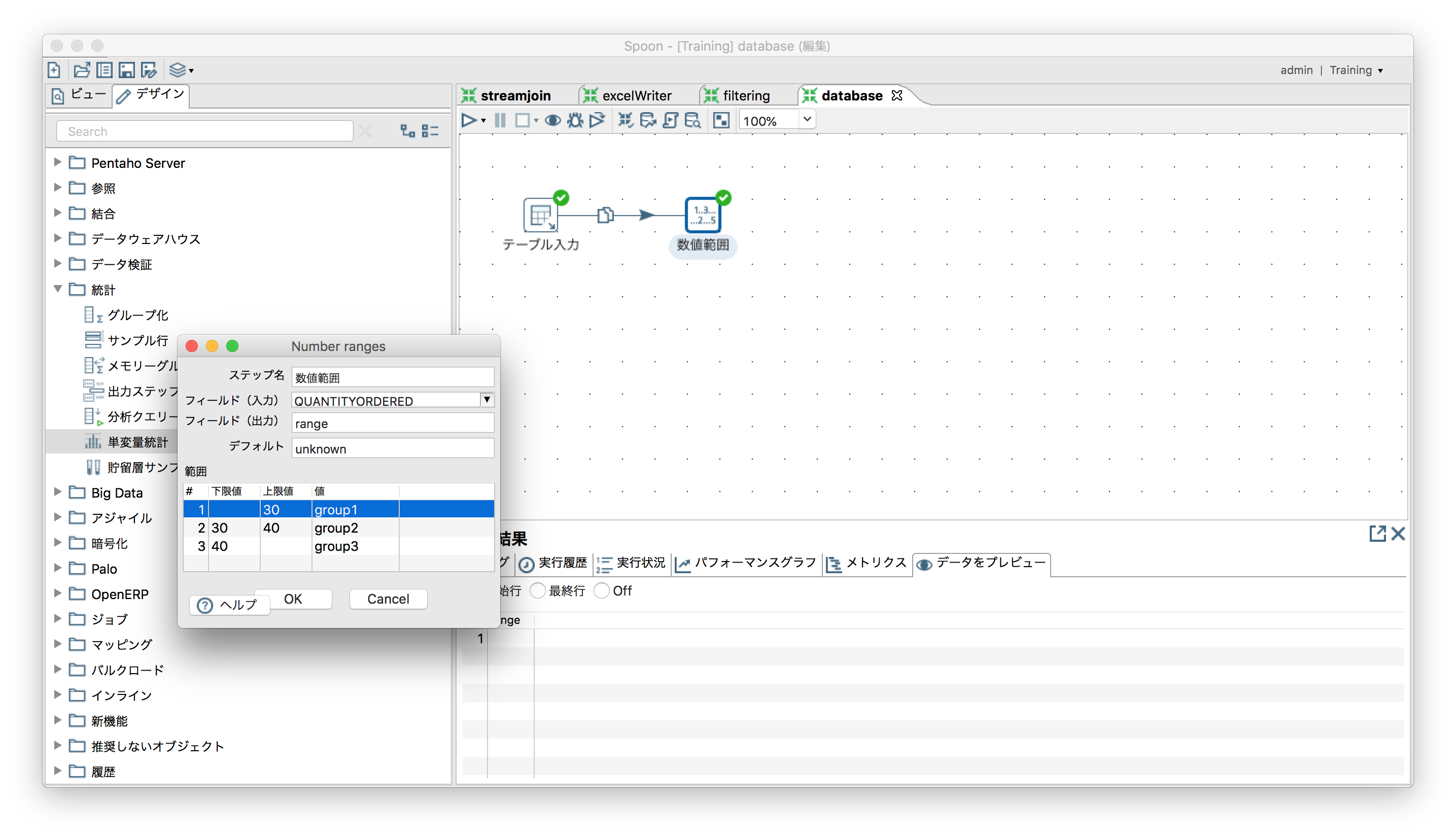
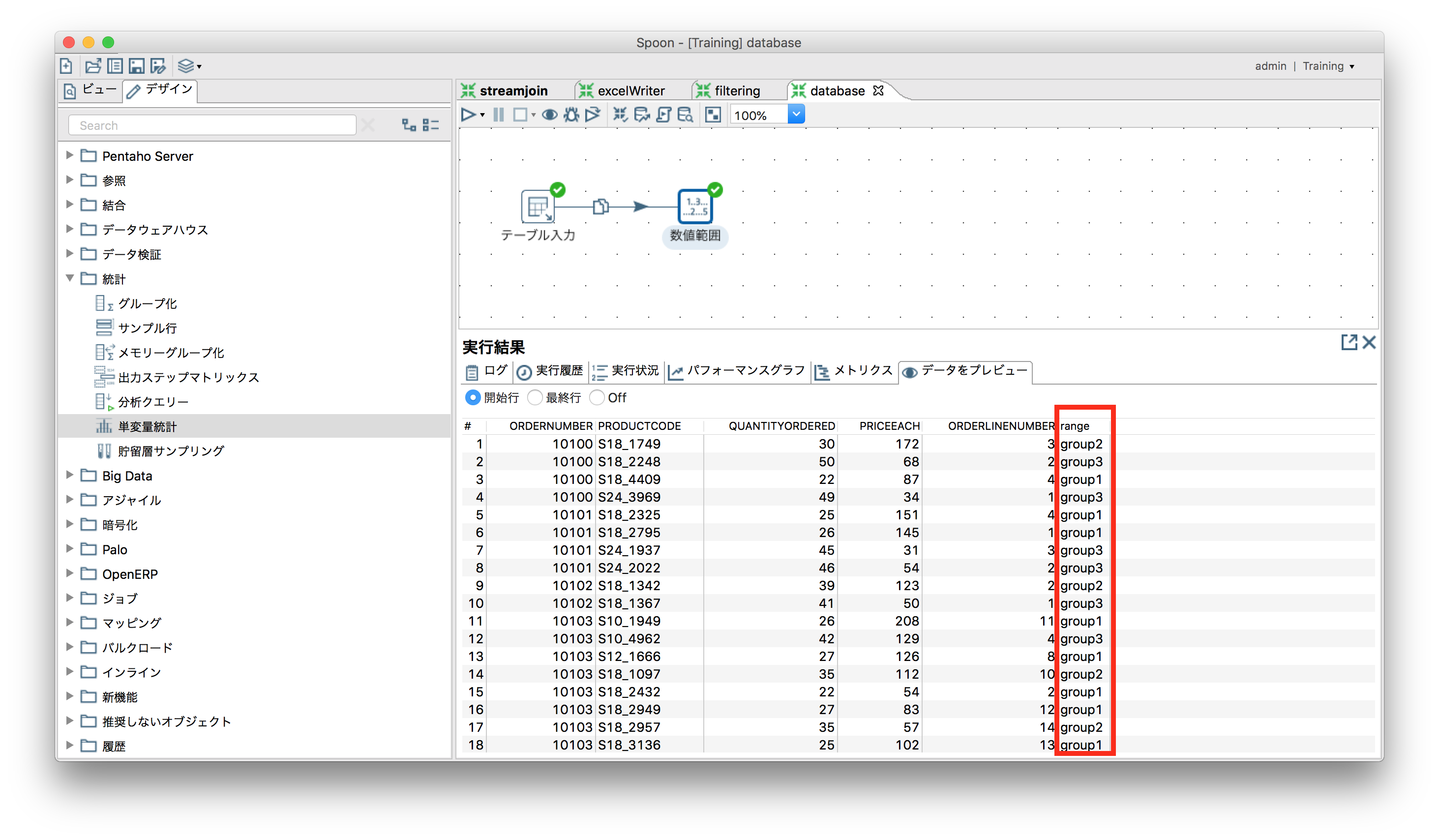
数値の範囲で出力値を分ける
「変換」ー「数値範囲」
SampleDataの"ORDERDETAILS"から取得した"QUANTITYORDERED(x)"を使ってグルーピング。
| group1 | group2 | group3 |
|---|---|---|
| $x<30$ | $30<x, x<40$ | $40<x$ |
ソートする
「変換」ー「行整列」
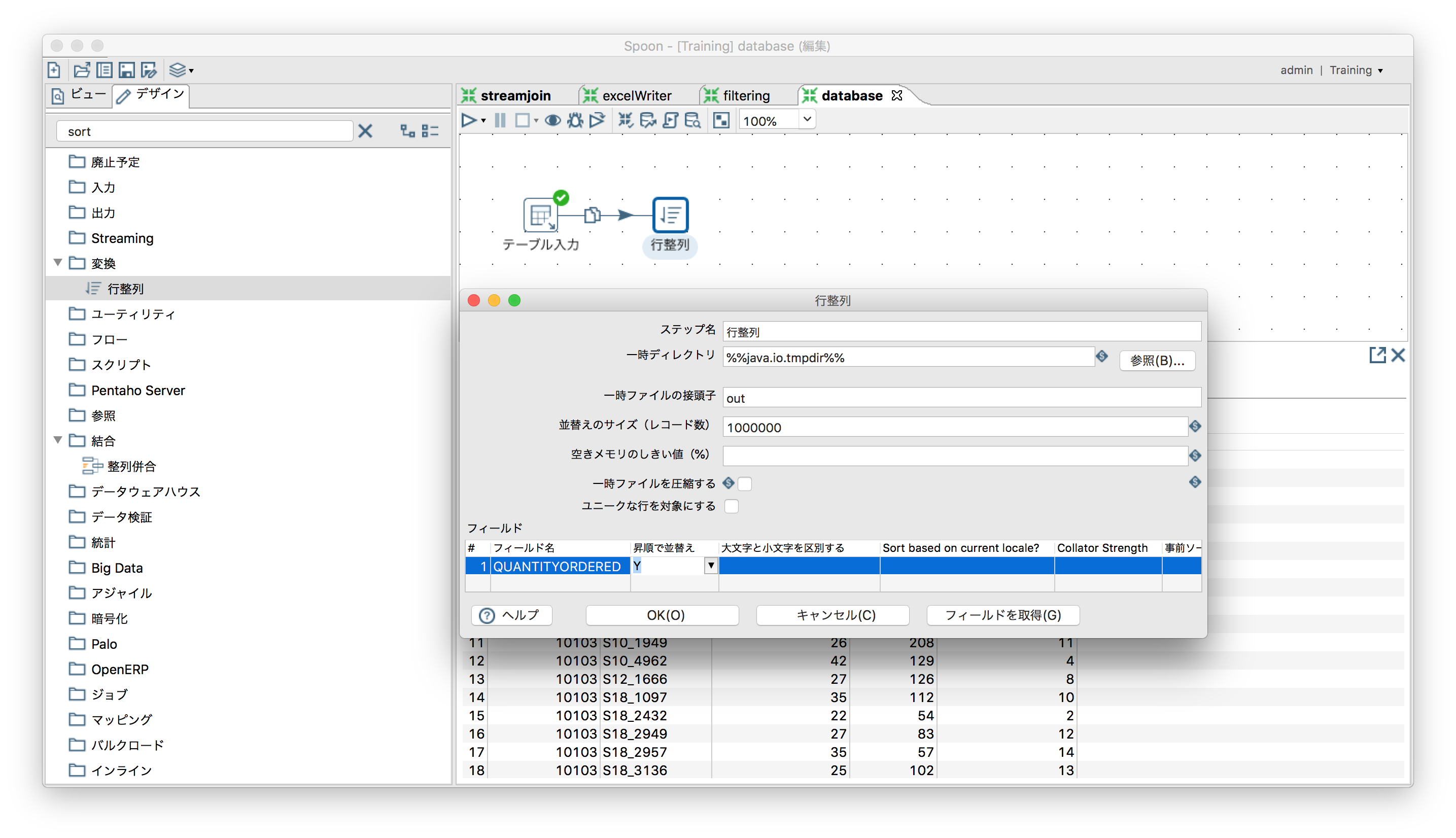
※DBから取得するデータならORDER BY句をつける方が効率的
複数データ行にまたがった計算(値の参照)
「統計」ー「分析クエリ」
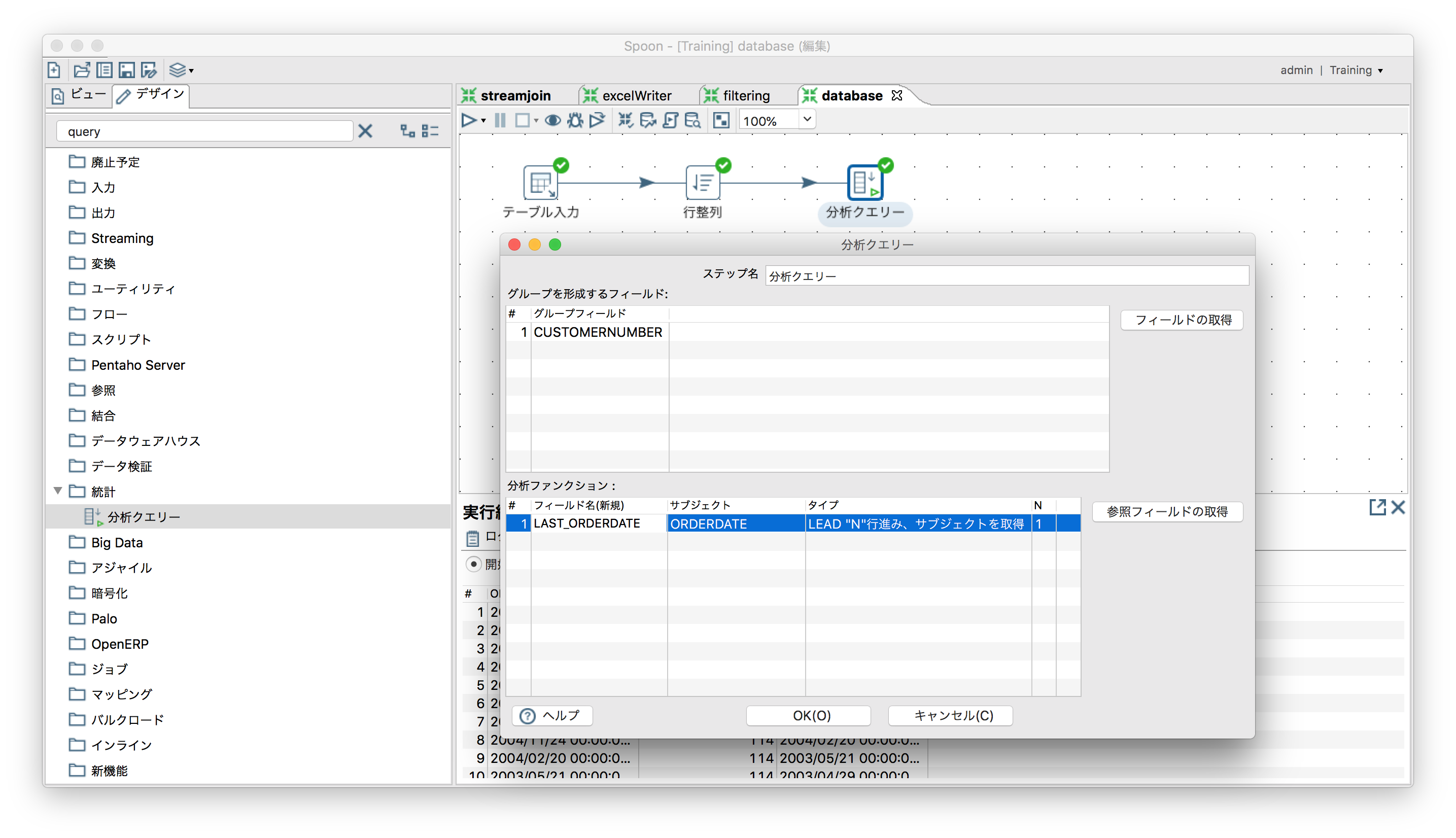
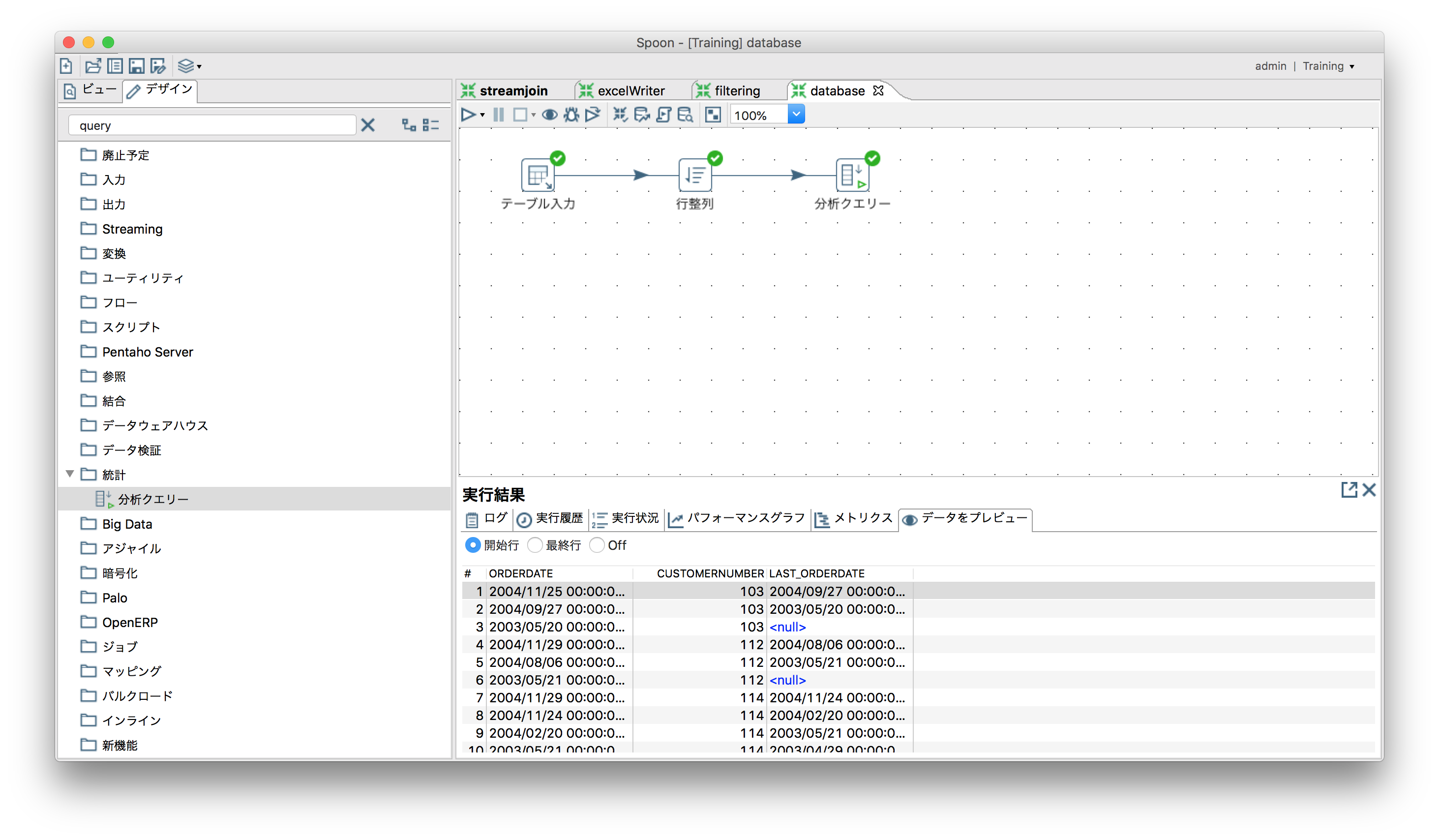
ORDERSテーブルからCUSTOMERNUMBERとORDERDATEを取得してソート。各行にLAST_ORDERDATEフィールド(1つ後ろのレコードのORDERDATE)をセット。
条件によってステップを分岐させる
「フロー」ー「条件分岐(Switch / Case)」
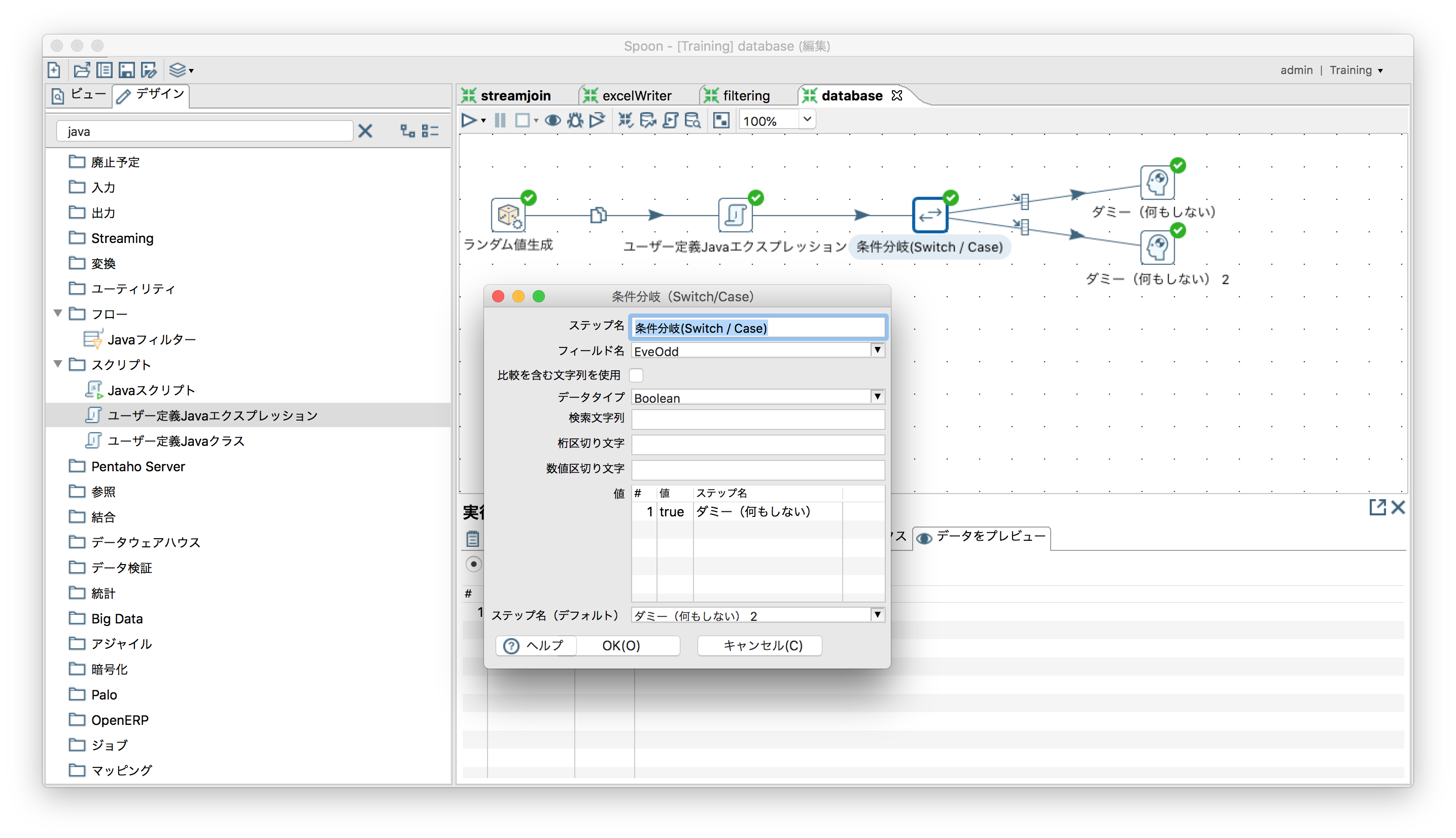
乱数を生成し、ユーザー定義Javaエクスプレッションで生成された乱数が偶数ならtrue、奇数ならfalseをEvenOddフィールドに出力(num % 2 == 0 ? tree : false)、偶数ならダミーステップ、奇数ならダミー2ステップへ。