前回からの続きで、今回はヒープ容量を最適化してみます。
前提
前回の記事と同じ環境を使用します。
ゴールとアプローチ
- スループット最大化を目指しつつ、一方でGC実行時間を最小化する
- 最適なGCポリシーを選択する
- 最適なヒープ容量を探る
GCポリシーの選択
GCアルゴリズム
GCのアルゴリズムには以下の4つがあり、JVMベンダにより多少の違い(方言)やラージオブジェクトの扱いの違いはあるものの、GCポリシーは基本的にこれらのアルゴリズムの組み合わせです。
- マーク・スウィープGC
- マークフェーズで「いきている」オブジェクトをマークし、スウィープフェーズでマークされていないオブジェクトを削除(スウィープ)する。
- コンパクション
- マーク・スウィープすると、メモリの断片化が発生する。断片化したメモリ領域を再編成(オブジェクトをヒープ内に整列)する。
- コピーGC
- ヒープをFROM領域とTO領域に分けて管理する。アプリケーションがオブジェクトを生成するとFROM領域からメモリを確保する。FROMの空きが少なくなったらコピーGCで「いきている」オブジェクトをでTO領域に整列して移す。移し終わったらFROMとTO領域を反転する。
- 世代別GC
- ヒープをNEW(Nursey)とOLD(Tenured)に分ける。アプリケーションがオブジェクトを生成するとNEW領域からメモリを確保する。NEW領域がいっぱいになったらスウィープしつつ一定回数以上「いきている」オブジェクトをOLDへ移す。
WASのGCポリシー
- Optimize for Throughput(optthruput)
- マークとスウィープを毎回のGCで実行し、解放領域が少ない場合はコンパクションも実行する。
- Optimize for Pause Time(optavgpause)
- 基本はマーク・スウィープ・コンパクションの組み合わせだが、マークを頻繁にやっておく(コンカレントフェーズ)ことでGCの実行時間(=アプリケーションの停止時間)を短くする。CPUに余裕がある場合に有利。
- Generation Concurrent(gencon)
- デフォルト設定。ヒープはNurseyとTenured領域に分かれる。Nursey領域はさらにAllocate(FROM)とSurvivor(TO)領域に分けられ、AllocateがいっぱいになるとコピーGC(Scavenger Collection)が行われる。Tenured領域自体はOptimize for Pause Timeの方式でコンカレントフェーズにマーク、領域がいっぱいになったらスウィープ、解放されなかったらコンパクションとなる。
- Balanced(balanced)
- 4GB以上のヒープ容量があり、Scavenger Collectionに時間がかかるようならこの方式にする。ヒープが少ないと逆効果(空き容量に余裕がある前提の構造になっている)。さらにCPUコア数が多い環境で有利。領域をブロック(最大ヒープサイズ/1024の2の倍数)に区切ってAllocate、コピー等のGCを適宜で行う。
というわけなので、今回はスループット優先、停止時間優先、世代数の3つでスループットがどう変わるか確認するとします。サイズは最大、初期値とも256 MBとします。
※WASの開発者版は合計2 GBメモリ内のライセンス制約あり
verboseGCログのモニタリング
まずは冗長GCログを有効化してファイル出力させます。IBM JVMではXML形式で出力し、GCMVという専用の可視化ツールをEclipseプラグインとして提供しています。素直にこれを使います。
ヒープの健全性クライテリア
一般的には以下の項目を確認します。
- 当たり前だがOutOfMemoryErrorにならないこと
- かといってJVMで使用可能なメモリ容量を超えてページングさせてしまってもダメ(一般的には使用可能なメモリの80%ほどを指定)
- 単位時間あたりのGC実行時間が13%以内
- GC後の空き領域が6割以上(85%以上になるならもう少し小さくしても構わない)
- GCの間隔が長すぎない(数分程度)
- GCの実行時間が長すぎない(3秒以上は長い)
実測
負荷をかけないと意味がないので、同時アクセス数=60にして、若干待ちが発生する状況下で30分間負荷をかけ、GCの様子を確認します。スループットはJMeterのレポートから取得します。
スループット優先
GC時間優先

世代別

結果
GCポリシー
GCポリシーごとに結果をまとめると以下のようになりました。
| GC policy | throughput | cpu usage | gc time | gc interval |
|---|---|---|---|---|
| Throughput | 11.78 tr/sec | 79.01 % | 10.48 % | 470 ms |
| Pause | 11.41 tr/sec | 82.42 % | 10.27 % | 472 ms |
| Gencon | 11.94 tr/sec | 71.86 % | 2.24 % | 125 ms (New), 94452 ms (global) |
スループットの差はわずかですがGenconが最もよいです。さらに単位時間あたりのGC時間を見ると、2.24 %と圧倒的にGenconが有利となる結果でした。また、CPU使用率についても最も有利な結果となっています。この無意味なアプリケーションに関しては、Genconが最適なGCポリシーといってよいと考えられます。
ヒープサイズ
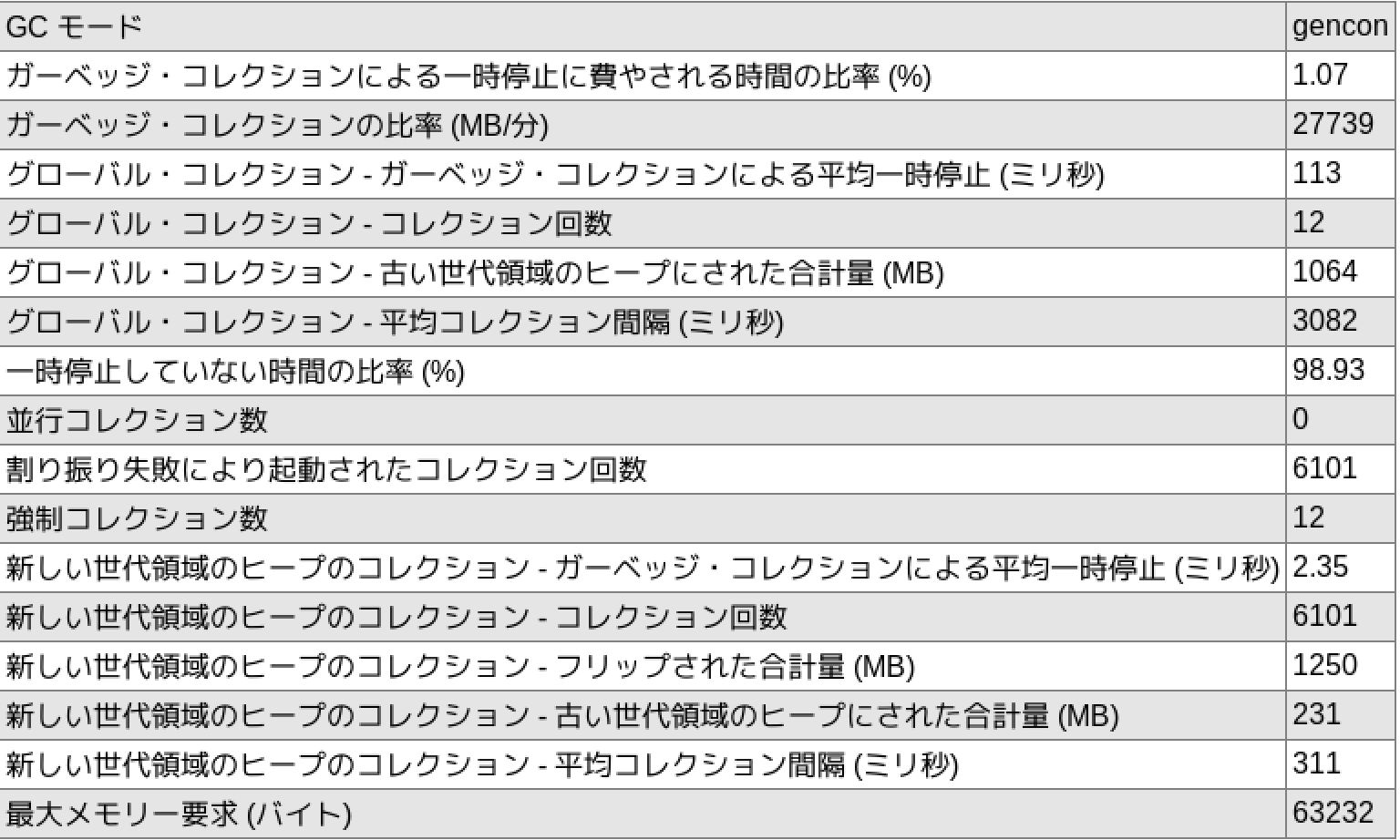
GenconでのヒープサイズのGCMVによるレポート結果(抜粋)です。


GC後の平均ヒープ使用率は50 %ですから、もう少しサイズ拡張してもよさそうです。
というわけで、ヒープサイズを640 MBまであげて再実測してみます。
| GC policy | throughput | cpu usage | gc time | gc interval |
|---|---|---|---|---|
| Gencon(256 MB) | 11.94 tr/sec | 71.86 % | 2.24 % | 125 ms (New), 94452 ms (global) |
| Gencon(640 MB) | 12.35 tr/sec | 72.19 % | 1.07 % | 311 ms (New), 3082 ms (global) |
スループットは約3 %向上しました。誤差というには顕著な違いです。CPU使用率はほぼ変わりませんが、単位時間あたりのGC時間(=アプリケーションの処理がストップしていた時間)が1.07 %と、割合でいえば半減しています。もちろん、単位時間あたりのGC時間だけでなく、レスポンスタイムのも気にしなくてはいけません。例えば、一人のユーザであっても、30秒待ってしまうとか、タイムアウトしてしまうとかがあるとお話になりませんので。JMeterのレポートを見る限りこの辺りもクリアしていました(むしろ最大レスポンスタイムも改善していました)。平均値に注目しすぎると忘れがちな、外れ値の持つ意味はしっかり吟味しなければいけません。
New領域のGC間隔が3倍程度まで伸びたものの、長すぎることはなさそうです。GC後の空きも平均で70 %でした。
そして、256 MBのときには1分半間隔だったグローバルGCも3秒間隔まで落ちています。頻度が少し高いのが気になりますが、停止時間のメトリクスのがより重要なので、やはりこのアプリケーションに関してはヒープサイズ640 MBのが256 MBのときよりもよいと判断して良さそうです。
これ以上ヒープサイズを増やしてもスループット向上は見込めないと想定されます。どこまでなら向上するのかさらにチューニングするか悩ましいところではありますが、、、
というわけで、GCMVを使ってヒープの最適化を試みてみました、というお話でした。
参考
参照サイト
GCMV結果イメージ(抜粋)
Throughput

Pause Time

Gencon(256 MB)

Gencon(640 MB)