Kaggle Advent Calendar 2020 の1日目の記事です ![]() (u++さんいつもありがとうございます!)
(u++さんいつもありがとうございます!)
まとめ
この記事では、自分の Github リポジトリ上のコードを Kaggle Datasets にアップロードする工程を CI で自動化し、Code Competition で楽に使えるようにした方法について書きました。
その過程で他の方法などについても調べたため、分かる範囲でまとめています。
この Kaggle Datasets の使い方はルール的にグレーですので、ご利用は自己責任で、もしくは最後にあるように最終サブミットでは使わないなど工夫をお願いします。
背景
Kaggle 上で開催されるコンペには Code Competition というものがあり、このタイプのコンペでは推論結果を提出するために Kaggle Notebook を通じて推論・提出ファイルの作成(ルールによっては学習も)を行う必要があります。
詳細は Kaggle の Competition Format にもありますが、Kaggle Notebook 経由でサブミットさせることで、計算資源や外部データなどについて参加者に一様な制限を課すことができるのがメリットとなっています。
基本的には便利でよいのですが、実際に参加して次のデメリットを感じました。
- 提出コードを Kaggle Notebook 上にまとめる必要があり、Notebook が非常に長くなる
- オレオレライブラリやコードが手元にある場合はいちいち Notebook 上にコピペが必要になる
- Notebook に移す過程でローカルで作ってたコードに微修正が必要になる
これらの対策について調べ、次の3つの方法がありそうでした。
- utility script を使って自分のコードをアップロード
- 自分のコードを base64 などに encode し、Notebook 上にコピペして、Notebook 上で decode する
- 自分の Github リポジトリを Kaggle Datasets にまるごとあげて、Notebook から使う
本記事では 3 について、毎回上げるのが面倒で CI で自動化したのでそれについて書きます。最後に1,2についても紹介します。
Kaggle Datasets へのアップロード
テンプレートリポジトリ と Circle CI 設定 を置いておきます。
ローカルのファイルを Kaggle Datasets にあげる
まずは動作確認のためローカルからコードをアップロードできるようにします。
もうできるよって方や Kaggle API の使い方はわかるよって方は飛ばしちゃって大丈夫です。
ローカルから Kaggle Datasets に何かを上げるには Kaggle API を使います。Kaggle API についての詳細は Kaggle/kaggle-api もしくは公式ドキュメント を参照してください。
まず、Kaggle Datasets 用のメタデータを作成します。アップロードしたいものが含まれているパスを指定して次のコマンドを叩きます。
$ kaggle datasets init -p /path/to/dataset
結果、指定したパスに dataset-metadata.json というファイルができているかと思います。私の場合は次のような内容でした。
{
"title": "INSERT_TITLE_HERE",
"id": "kentaronakanishi/INSERT_SLUG_HERE",
"licenses": [
{
"name": "CC0-1.0"
}
]
}
この title と id のユーザID以下の部分を適当な名前に変えます。今回は KAGGLE_ADVENT_CALENDAR という名前にしてみました。なにかファイルがないとアップロードできないいので適当なファイルを追加し、次のコマンドで Kaggle Datasets を作成します。
$ echo "This is an exmaple datasets for Kaggle Advent Calendar 2020" > /path/to/dataset/README.md
$ kaggle datasets create -p /path/to/dataset
するとこんな感じで Kaggle Datasets が作成できます。
データを加えて更新する場合は versions コマンドを使います。先程の README に Advent Calendar の URL を足しておきましょう。
$ echo "https://qiita.com/advent-calendar/2020/kaggle" >> /path/to/dataset/README.md
$ kaggle datasets version -p /path/to/dataset -m "update readme"
上手く行けば、Kaggle Datasets にも反映されます。

CI からリポジトリ全体を Kaggle Datasets にあげる
今回の環境では CircleCI を使ってますが、任意の環境でCI側でコマンド実行できるならなんでも問題ないと思います。
次のような手順で行います。今回は、master ブランチにコミットが積まれたタイミングで走るようにしています。
- リポジトリ内に圧縮したリポジトリを入れる用のディレクトリを用意する (kaggle_datasets_git)
- そのディレクトリで Kaggle Datasets を作っておく (上記ローカルのファイルを〜を参照)
-
CI の configで次の処理を行うよう記述する
- 依存ライブラリをインストール (kaggle cli など)
- 自分のリポジトリをまるごと zip で圧縮し作成したディレクトリに保存
- kaggle api を使って圧縮したファイルをアップロード
詳細は .circleci/config.yml を見てください。下記は私の環境での該当の処理のところだけ切り出したものです。
kaggle:
docker:
- image: circleci/python:3.8.6
working_directory: ~/repo
steps:
- checkout
- restore_cache:
keys:
- dependencies-{{ checksum "poetry.lock" }}-{{ checksum ".circleci/config.yml" }}
- run:
name: install dependencies # 依存ライブラリをインストール (kaggle cli など)
command: |
poetry install
- run:
name: zip source # 自分のリポジトリをまるごと zip で圧縮し作成したディレクトリに保存
command: |
zip -r ./kaggle_datasets_git/mykaggle.zip ./mykaggle
- run:
name: upload to kaggle dataset # kaggle api を使って圧縮したファイルをアップロード
command: |
poetry run kaggle datasets version -p ./kaggle_datasets_git -m $CIRCLE_SHA1 -d
このように設定することで、例えば PR を master ブランチにマージするたびに Kaggle Datasets を最新の状態にする、などを自動で行うことができます。
あとはこの Datasets を Kaggle Notebook 側で追加し、Notebook 上で次のように追加した Datasets のパスを登録してあげれば、ローカルのように参照しながら使うことができます。
import sys
sys.path.append('/kaggle/input/{YOUR_DATASET_NAME}/')
これ、やってもいいの?
多くの Code Competition では、external datasets の利用は (1) 誰でも自由に利用できるよう公開されている、(2) 特定の Discussion スレッドに書く、の2点を満たせば使用できるというルールになっています。
今回のリポジトリのアップロードも同じ話であれば公開してスレッドに書く必要が出てきそうですが、自分のコードが全部入ってる場合は実質ソリューション公開になってしまい、それはできません。
そのため、ルール的にはグレーな方法だと思います。
ルール的にはグレーと言うかダメじゃないの?と思われる方もいるかもしれませんが、よくある「自分で学習したモデルのパラメータを Kaggle Datasets として追加して使う」方法も多くのコンペ・参加者によって使われていますが、ルールとしては明文化されていないケースが多く、上記のルールに倣うならNGということになってしまいます。
(Private Sharing やら External Datasets の定義やら、グレーなルール多くて辛い)
とはいえルールにはない方法なので、いつ怒られるかわかりません。私は次のようにしています。
- コンペ中は基本的にこれを使い、なるべくローカル環境と同じコードでサブミット
- コンペの最終サブミットは、必要なモジュールを全てコピペした Notebook を作ってそれでサブミット
最終サブミットには結局色々なコピペが必要になり面倒ですが、トライアンドエラーを繰り返すタイミングではローカルのコードをもとに実験できるので、そこそこ楽になります。
(なお、これやってもいいの? をKaggle のフォーラムで一度質問したことがありますが、返信は付きませんでした...)
補足 (1, 2 の方法について)
最初に触れた次の2つの方法も少し説明します。
1. utility script を使って自分のコードをアップロード
Utility Script は Kaggle で用意されている公式の機能です。
特定のスクリプトをモジュールとして Notebook に追加することができます。
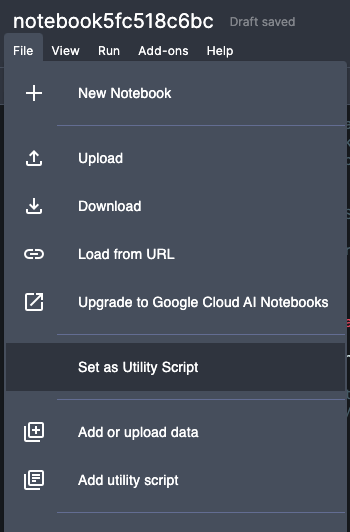
新規で Notebook を Script で作成し、次の画像のように File から Set as Utility Script を選ぶことで Utility Script として登録されます。
逆に Notebook からは、 Add utility script を選択することで登録された Utility Script から好きなもの追加できます。
Kaggle が提供する方法なので安心ですが、ローカルと同様の構成にできない、依存関係が複雑になる、などめちゃくちゃ使いづらいのでオススメはしません。
私は当初これで10個以上の Utility Script を作って Notebook に追加していたのですが、複雑になるだけでなく追加・削除の度に Notebook のセッションが切れまくってまともに動きませんでした... (今はもう少しマシかと思いますが)
2. 自分のコードを base64 などに encode し、Notebook 上にコピペして、Notebook 上で decode する
imet-2019-submission の Notebook で紹介されている方法です。全ファイルを base64 にエンコードしたものを Notebook 上でデコードしてファイルにして保存します。
Kaggle Datasets を経由せずに直接外部ファイルを読み込んでいます。黒魔術チックなので個人的には Datasets 使う方がオススメです。
以上です。