本記事は ICLR2019をよむアドベントカレンダー Advent Calendar 2018 の22日の記事です。
🧙 of Wikipedia: Knowledge-Powered Conversational agents というタイトルの論文を読んだので紹介します。ちなみに🧙には Wizard が入ります。Wizard of Wikipedia です。私が勝手に絵文字にしたわけじゃなくて、元論文がそうなっています ![]()
気になる採否ですが、 Poster で accept されたようです ![]()
間違いや補足などあれば気軽にコメントいただけると助かります ![]()
忙しい人のためのサマリー
知識 (knowledge) をうまく使えるような chatbot に関する研究。
open domain な対話において、知識を扱うような chatbot の研究が少ないのはそれに関するタスクやデータがないから、という仮説から、 Wikipedia のデータを基にして「知識を取り扱う対話」のデータセット、及びベンチマークを作成した。
また、知識を取り入れた対話応答のためのモデルを設計 (Transformer Memory Network) し、いくつかの既存モデルと合わせて実験、提案したベンチマーク、及び人手による評価を行った。
モデル自体も新しいものだが、新たなデータセットとベンチマークの作成によりこの分野の発展が期待できる点が特に評価されている。
目次
次の順に説明する。
- 背景・関連研究
- データセットとタスク: Wizard of Wikipedia
- 提案手法: Transformer Memory Network
- 実験
背景・関連研究
本研究は open domain での対話タスクを取り扱っている。
open domain の対話とは、二人の話者が特定のトピックに依らず、自由に会話をするようなタスクを言う。よく対比として上げられるのはタスク指向型の対話で、例えばレストランの予約など、特定の目的のもとで行われる対話がある。
これを実現するには、次のような機能が求められると著者らは主張している。
- 言語を理解する
- 記憶を保持する
- 知識を活用する
- (上記を組み合わせて)発話を生成する
ところが、現在主流となっている対話のためのアーキテクチャである sequence to sequence なモデル (相手の発話を受け取って、応答となる発話を生成するようなモデル, Seq2Seq [1] や Transformer [2] など)は、記憶の保持や知識の活用に関する能力がまだ十分ではない。
これらのモデルは入力を基になんらかの演算を施して出力を生成するだけなので、モデルに保存されるのはせいぜい重みに含まれている情報であることから、尤もと言える。
対話における記憶や知識の活用についての研究が進んでいない1つの要因として、著者らは、知識を問うような open domain な対話のデータセット、及びベンチマークが存在しないことを挙げている。実際に、対話のタスクはあるものの、明示的に知識を利用しないものが多い。例えば、 Open-Subtitles [3], Persona-Chat [4] などは、記憶のようなものを扱うものの過去の対話を基にしており、知識のような長期的な記憶は扱っていない。
open domain な対話という制限を離れると、いくつか類似研究は存在する。
タスク指向型の対話においては、データベースにAPIでアクセスをするなど、知識を活用する前提のデータセットがいくつか存在している。また SQuAD などの QA 系のタスクは、応答を生成しないものの知識を使うことが必要になってくる点で似ていると言える。
最も近い研究エリアとしては、知識を活用した被タスク指向の分野にあたる。Memory Network を使うもの、知識を構造化して条件として使うもの、非構造的なテキストをそのまま使うものなど色々分類があるが、マルチターンでかつ open domain な対話を取り扱うようなモデルは本研究が初めて。
データセットとタスク: Wizard of Wikipedia
ここでは、データセットの作り方とベンチマークとなるタスクについて述べる。ここがメインっぽいので少し詳しめに書いた。
設定
open domain でかつ知識を使った対話を定義する。本研究では、下記に述べるような条件で人と人の会話をデータセットで収集し、モデルを構築して Wizard (後述)を置き換えることを考えている。
- 二人の話者が雑談をする
- 片方が最初のトピックを選ぶ
- トピックは途中で変わっても良い
更に本タスクでは、二人の話者は対等ではなくそれぞれ役割があり、一人は Apprentice 、もう一人は Wizard と分ける。
Apprentice
- Wizard と自由に話す
- 好奇心旺盛で学習欲が強い
- 興味のあるトピックについて楽しく議論を深めたい
Wizard
- 「好奇心旺盛そうな人と会ったので、何かについて議論したいと考えている」という設定
- 相手にある話題についての情報を伝えることが目的
- 会話の各ターンで会話に関連のある Wikipadia のページにアクセスできる(後述)
- 得た情報を基に次の返答を考える
会話の流れ
- どちらかが Topic を選択して話しかける。
- wizard がメッセージを受け取ったら、関連する知識が表示される(後述)。関連する文章を選択する。
- wizard は選んだ文章を基に発話を構成し、返答する。
- 会話が5ターン続くまで上記を繰り返す。
これらの設定で、1,431 のトピック (それぞれが Wikipadia の1記事に対応している)を使ってクラウドワーカーによるデータを収集した。Wizard は下記のような UI で対話を行う。

図1: Wizard から見た画面例, Appendix A.1 from Wizard of Wikipedia: Knowledge-Powered Conversational Agents
知識の検索
Wizard にターンが回ってくるたびに関連する Wikipedia ページが表示される、という流れになっているが、それには Wikipadia ページから過去の会話に関連する記事を検索する手順が必要になる。
著者らは、この点はモデルの改善できる点だとしつつ、(ベンチマークとして使うために?)データセット収集時は、Open-SQuAD のデータセットなどで使われている標準的な手法([5]など)にしたいとのこと。
過去の2つの会話でそれぞれ上位7件、トピックについての記事が1件の合計15件を取ってきて、Wizard に表示する。
知識の選択と返答の生成
Wizard は、与えられた15件の Wikipedia 記事の中から、返答を作成する際に最も関連のある文章を1つだけクリックして選ばせた。このデータにより、QA 系タスクのようなアプローチで、評価時にどれくらい正しく知識を活用できたかを測ることが出来るようになる。
最終的なデータセット
- 22,311 個の対話 (201,999 ターン)
- 166,787 個を training set
- 17,715 個を validation set
- 17,497 個を test set
- test set は、training set にあるトピックとないトピックで Test Seen と Test Unseen として半々に分けた
提案手法: Transformer Memory Network
上述した Wizard of Wikipedia のフローにおいて、 Wizard を置き換えるモデルを考える。著者らは、 Transformer [2] と Memory Network [6] を組み合わせたモデルを提案した。なお、知識検索の部分は、データ収集時と同じ標準的な情報検索のテクニックを使っているとのこと。
モデル概要
いくつか派生で種類があるため後に列挙するが、基本となる Encoder 部分は同様。
- 会話のコンテキスト $ x_1, ..., x_t $ ($x_1$ はトピック名) を Transformer でエンコードする (※ ここの入れ方は書かれていないが、全てのコンテキストを concat している??)
- メモリー(知識)の全ての文章を別々に会話のものと同じ Transformer でエンコードする
- エンコードした会話コンテキストを、メモリー(知識)のそれぞれに対して dot-product attention を適用する
- これによって出来た表現を Decoder にわたす
下記図の左側半分に当たる。
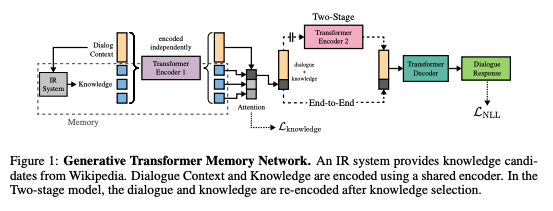
図2: Figure 1 from 'Wizard of Wikipedia: Knowledge-Powered Conversational Agents'
得られた入力と知識の表現の使い方から Decoder までで、いくつか派生手法を提案している。
Retrieval Model
予め返答の選択肢が用意されており、その中から一つを選ぶ。返答の選択肢は、データセットで正解にあたるものと、他の対話に使われた返答をランダムでピックアップしている。
知識と対話のコンテキストをエンコードしたものを $\mathrm { rep } _ { \mathrm { LHS } }$, 別の Transformer で返答の候補をエンコードしたものを $\mathrm { rep } _ { \mathrm { RHS } }$ とすると、次の式で返答を選ぶ。
\ell = \underset { i \in \{ 1 , \ldots , L \} } { \arg \max } \frac { \operatorname { rep } _ { \mathrm { LHS } } \left( m _ { c _ { 1 } } , \cdots , m _ { c _ { K } } , x \right) } { \left\| \mathrm { rep } _ { \mathrm { LHS } } \left( m _ { c _ { 1 } } , \ldots , m _ { c _ { K } } , x \right) \right\| _ { 2 } } \cdot \frac { \mathrm { rep } _ { \mathrm { RHS } } \left( r _ { i } \right) } { \left\| \mathrm { rep } _ { \mathrm { RHS } } \left( r _ { i } \right) \right\| _ { 2 } }
ここで、$m_{c}$ はそれぞれのメモリ、 $x$ は対話コンテキスト、$r$ は返答の候補となっている。
※ 直感的には入力のエンコード結果と一番近いものを選んでいるだけ?
※ あまり現実的でない設定に感じたため、Retrieval Model についての実験結果の詳解は割愛した。
Generative Model End-to-End version
これまでの対話と知識を与えて、end to end に返答を生成する。
最終的な発話の negative log likelihood による loss $ \mathcal {L}_ {NLL} $ だけでなく、知識選択部分にも人が選んだ知識を正しく選択できているかを評価する loss $ \mathcal {L}_{knowledge} $ を足した。
Generative Model Two-stage version
知識を選択するまでと、知識と過去の対話を基に返答を生成するところでモデルを2つに分け、それぞれでトレーニングする。
最初のモデルで使用する知識は候補から1つだけ選ぶため、この精度がクリティカルになってくる。
知識が間違っていたときに大きく返答が間違わないように、一定確率で知識を無くす Knowledge Dropout (K.D.) も取り入れた。
実験
上述したモデルをいくつかの実験でテストした。一部紹介する。
Full Task: Dialogue With Knowledge
Predicted Knowledge (knowledge を自身で推定する)と、 Gold Knowledge (正解の知識を与える)の2つの条件で、フルタスクの実験を行った。指標は perplexity と F値。
表1: Generative model の実験結果, Table 4 from Wizard of Wikipedia: Knowledge-Powered Conversational Agents
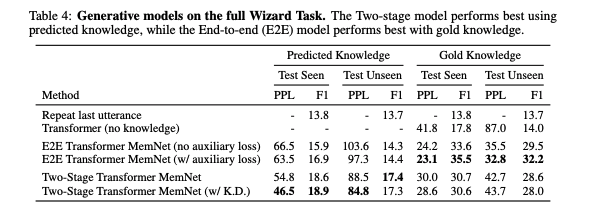
当たり前だが、通常の Transformer よりよい結果となっている。
Predicted Knowledge については、Two-stage モデルの方が良い結果になった。知識選択のために学習したモデルがうまく活きていると言えるだろう。逆に、 Gold Knowledge では E2E モデルの方が良い結果となった。E2Eモデルの方が、得られた知識を返答に活用できている、と推測できる。
Human Evaluation
さて、 training set に対する指標による評価は向上が見られるが、人による評価だとどうだろう。
本実験では、クラウドワーカー(Apprentice)と各モデル(Wizard)で会話をしてもらい、「どのくらい会話が気に入ったか」を1-5段階で回答してもらい、それをもってモデルを評価した。結果は下記。
表2: 人手による評価結果, Table 5 from Wizard of Wikipedia: Knowledge-Powered Conversational Agents
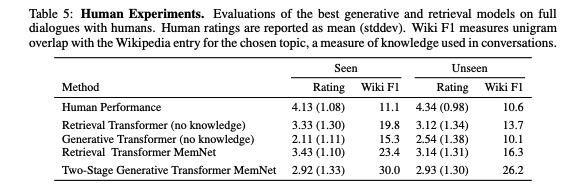
考察としては色々書かれているが、人による対話(表2の一番上)にはまだまだ差があることが分かる。
コメント
知識を使った対話モデルのフレームワークとしては、非常に有用に思えた。提案モデルもアイディア自体は組み合わせではあるが、新しい手法を使っておりベースラインとして良さげなものに見える。別モジュールから取ってきたメモリーを attention するだけ、というのも簡単でわかりやすい。
下記の点などいくつか説明が少なくてわからないところがあるが、コードとデータセットは公開予定とのことなので読めば分かることを期待したい。
- 会話コンテキストの入れ方 (コンテキストは $x_1, .., x_t$ の $t$ 件あるはずだが、$x$ だけになっている)
- E2Eモデルの実験時は Gold Knowledge をどう入れているのか
- 他のモデルでの Human Evaluation の結果が書かれていない
またデータセットなどが公開されたら実装などもトライしたいところだが、知識検索の部分も必要になってくるのがめんどくさいところ。
chatbot 開発に携わる身としては、最初に言及されているような知識と記憶の問題は open domain な対話においてまさにそのとおりだと感じるので、この分野の研究が進むことを期待したい。
参考
- Sequence to Sequence Learning with Neural Networks, arXiv:1409.3215
- Attention Is All You Need, arXiv:1706.03762
- A Neural Conversational Model, arXiv:1506.05869
- Personalizing Dialogue Agents: I have a dog, do you have pets too?, arXiv:1801.07243
- Reading Wikipedia to Answer Open-Domain Questions, arXiv:1704.00051
- End-To-End Memory Networks, arXiv:1503.08895